本教程使用的是Pyside6
1、安装PySide6模块
pip install pyside6安装完成之后,会有一个designer.exe可执行文件,打开之后,我们可以通过拖拉拽的方式来布局我们的界面。
designer.exe文件位置,一般位于当前虚拟环境下面的路径。
虚拟环境--->Lib--->site-packages-->PySide6--->designer.exe文件
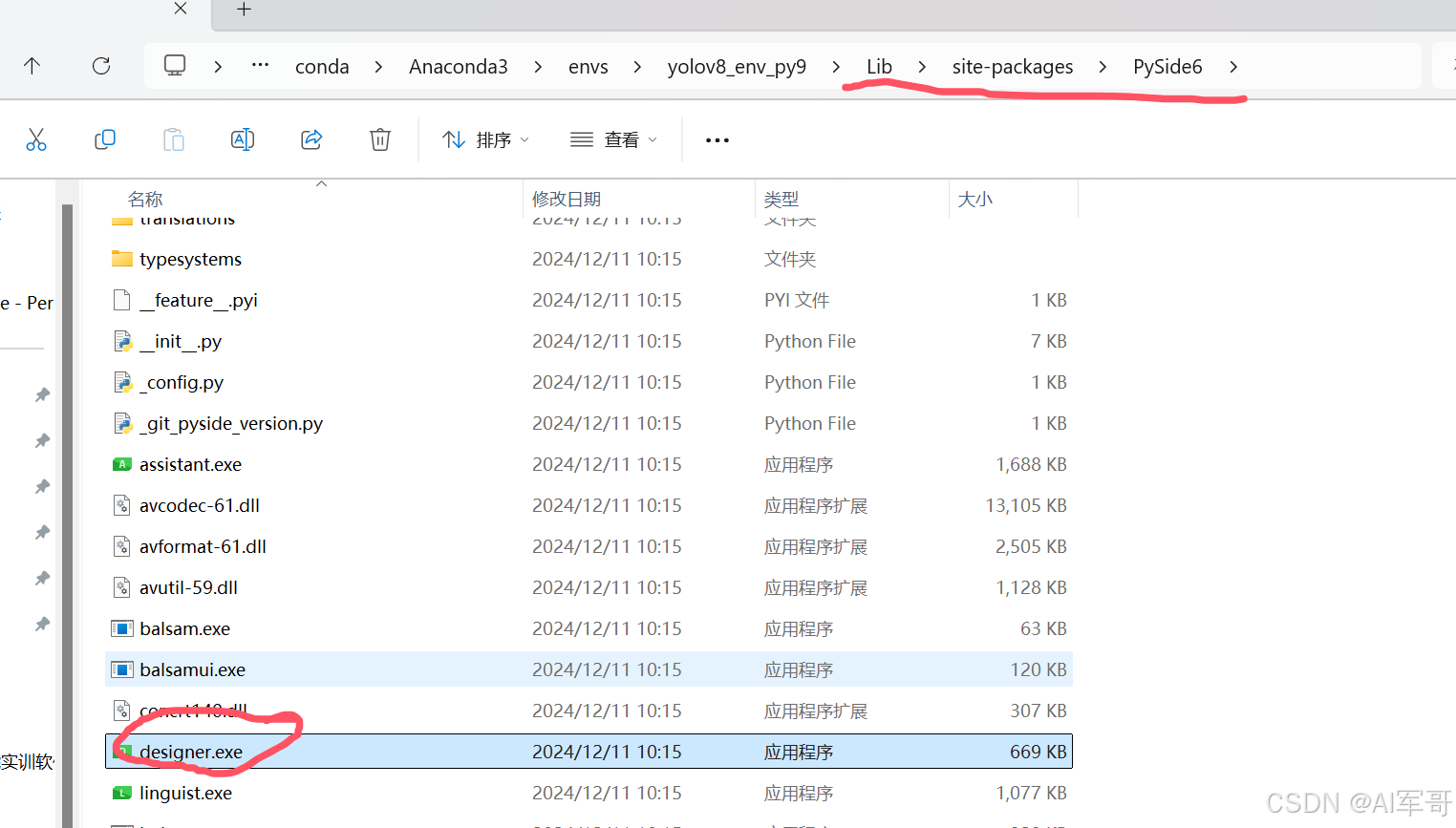
建议发送桌面快捷方式,便于下次查找起来更方便
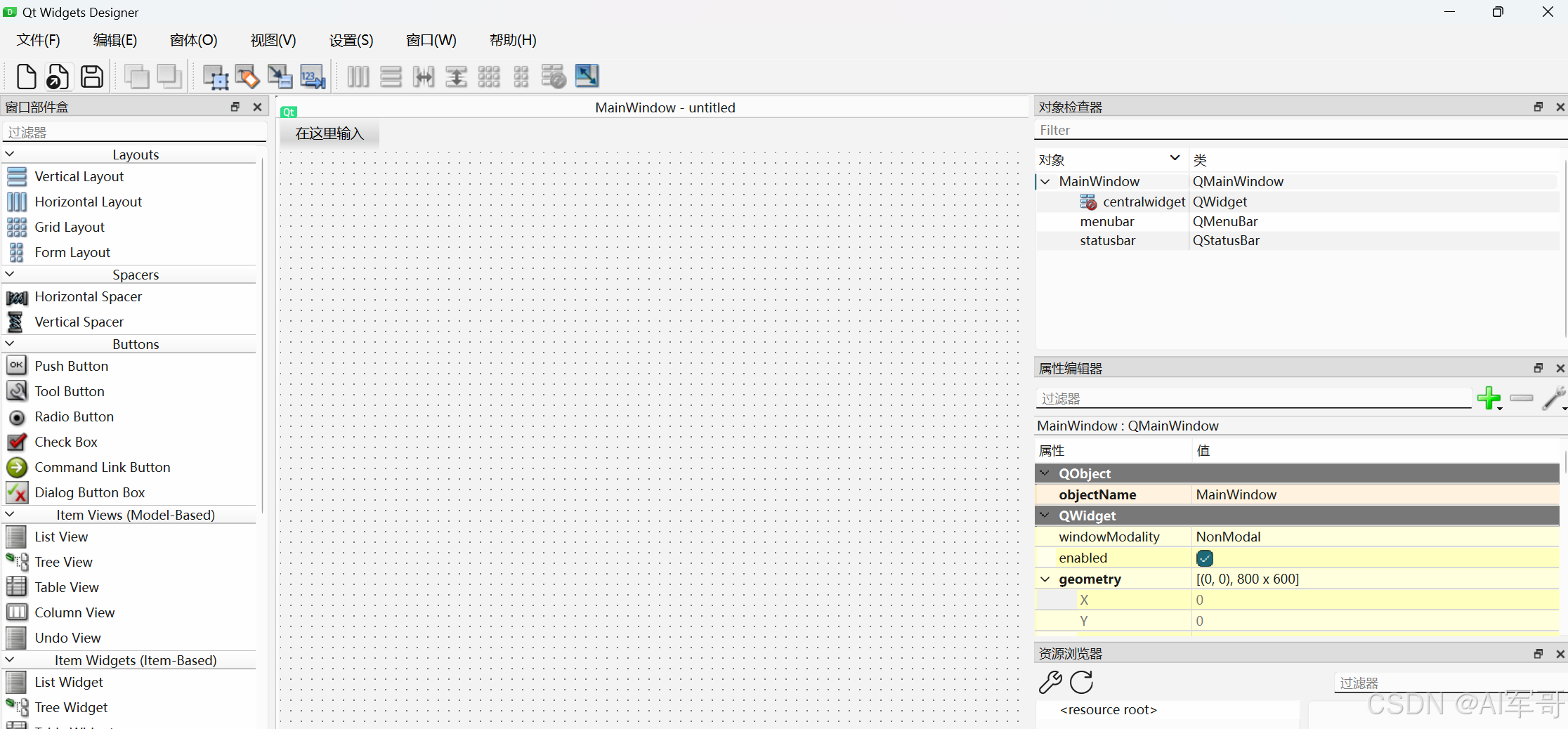
2、界面布局
主要使用的控件是:
QTabWiget 容器布局
Qlabel 图片和视频显示区域
QPushButton 按钮
Line 画线


使用背景色,主要是好区分哪一个组件,功能完成之后,可以再做调整
3、图片检测功能
需要用到的技术就是插槽和信号
将ui文件转换为python文件(这是第一步)
将生成好ui文件,导入到项目中,执行以下命令。
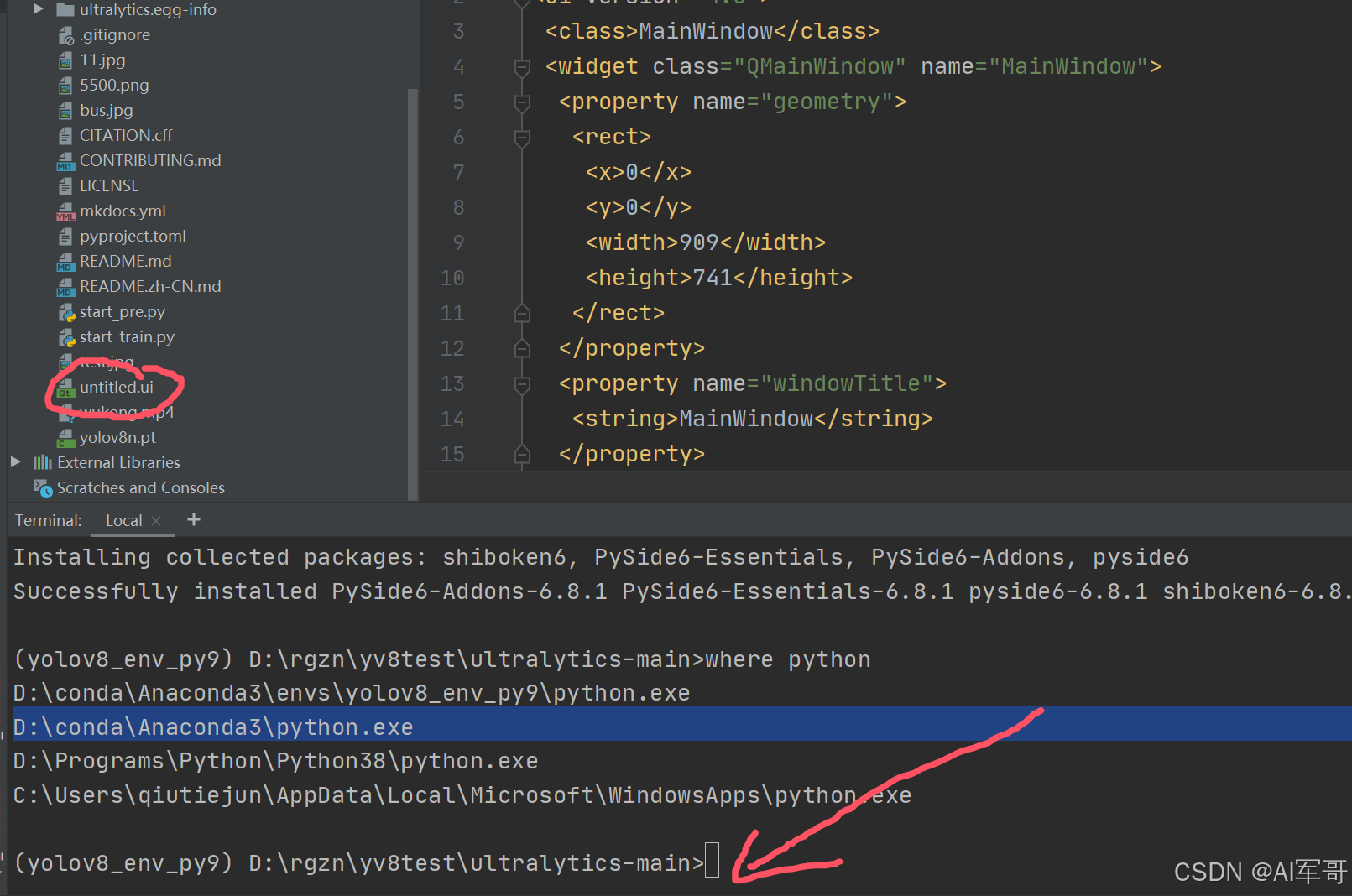

pyside6-uic project_ui.ui -o main.py基础UI界面,封装好的,大家可以使用(第二步,这里面调用上面生成好的main.py模块注意命名和引入)第四行代码
# -*- coding: utf-8 -*-
# Auther : qiutiejun
# Date : 2024/6/2 13:35
# File : main_project_ui.py
# 主界面,基础ui
import torch
import sys
from PySide6.QtWidgets import QApplication,QMainWindow,QFileDialog
from main import Ui_MainWindow
from PySide6.QtGui import QPixmap,QImage
class MainWindow(QMainWindow,Ui_MainWindow):
def __init__(self):
super(MainWindow, self).__init__()
self.setupUi(self)
if __name__ == '__main__':
app = QApplication(sys.argv)
window = MainWindow()
window.show()
app.exec()运行次模块,你会看到以下界面:
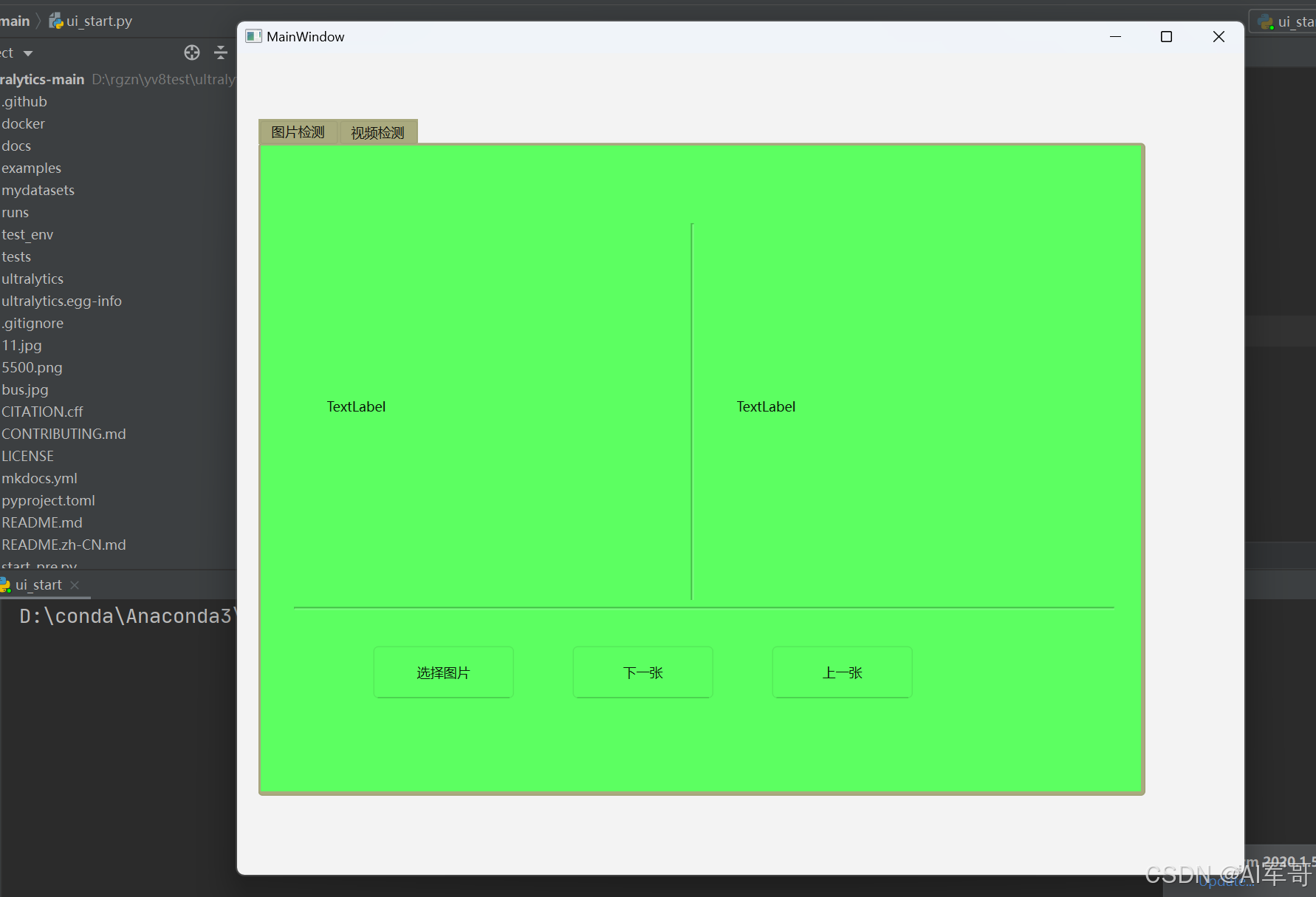
需要注意的几个地方:
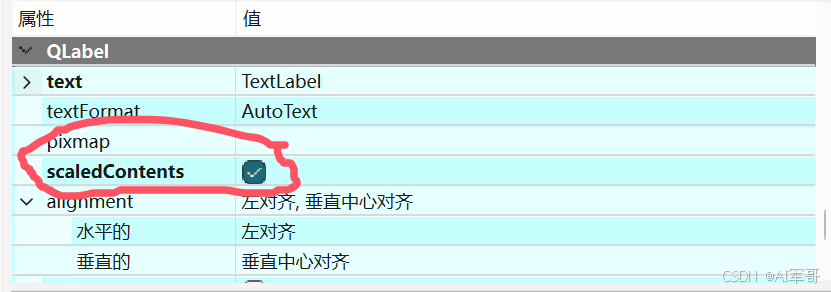
1、控价摆放好之后,一定要给控件进行重命名操作
2、对于显示图片的lable来说,需要勾选自适应的标识。
编码:
可参考官网:
https://docs.ultralytics.com/modes/predict/#__tabbed_1_2ps:需要大家有一点QT编码知识点,也不要求太多。只需要掌握插槽和信号这两个概念就行。
简单来讲就是,信号就是当有什么事件发生时,会触发的。比如常见的点击事件。插槽,就是信号接收器,当某一个信号发出后,我们需要做什么的应对处理。
代码如下:
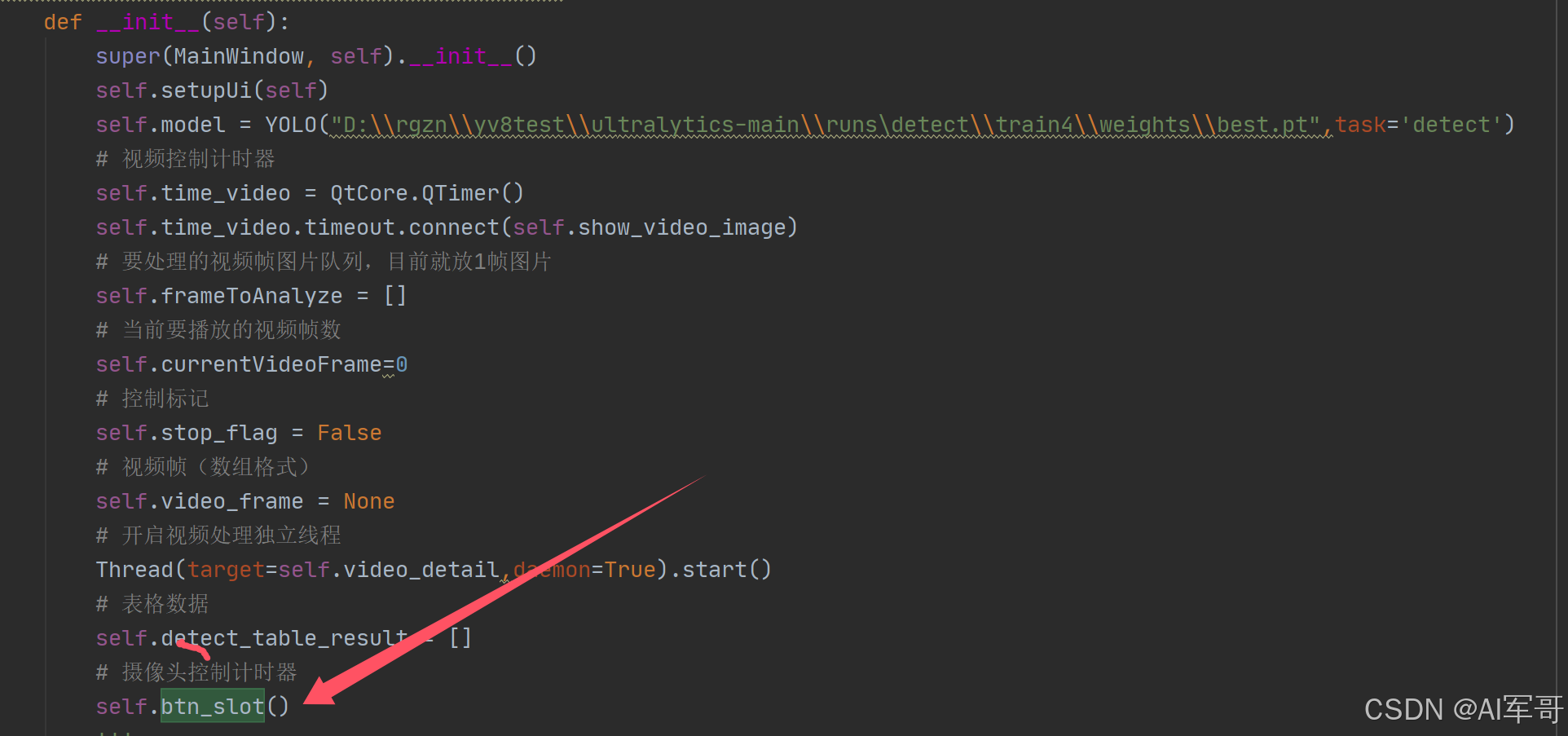
1、信号处理(点击选择图片是触发)
self.select_img.clicked.connect(self.detect_img_methods)我是把图片按钮和视频按钮的信号放置在一个方法中,在初始化的过程中就会调用
def btn_slot(self):
print("按钮触发事件")
self.select_img.clicked.connect(self.detect_img_methods)
self.select_video.clicked.connect(self.detect_video_methods)接下来就是处理信号信息的插槽,自己也是通过方法来处理的。
第一种方式:
# 检测图片按钮的功能
def detect_img_methods(self):
print("图片检测")
files = QFileDialog.getOpenFileName(dir='ui_information',filter='*.jpg')
print("路径",files)
if files[0]:
# 显示图片
self.old_img.setPixmap(QPixmap(files[0]))
# 获取文件名
file_info = QFileInfo(files[0])
# 获取文件名
file_name_only = file_info.fileName()
change_img = self.make_detect_image_name(files[0],file_name_only)
self.detect_img.setPixmap(QPixmap(change_img))
def make_detect_image_name(self,filepath,filename):
results = self.model.predict(source=filepath, show=False, save=True)
curr_path = os.getcwd()
result_path = ""
for result in results:
result_path = result.save_dir
return os.path.join(curr_path, result_path, filename)思路分析:
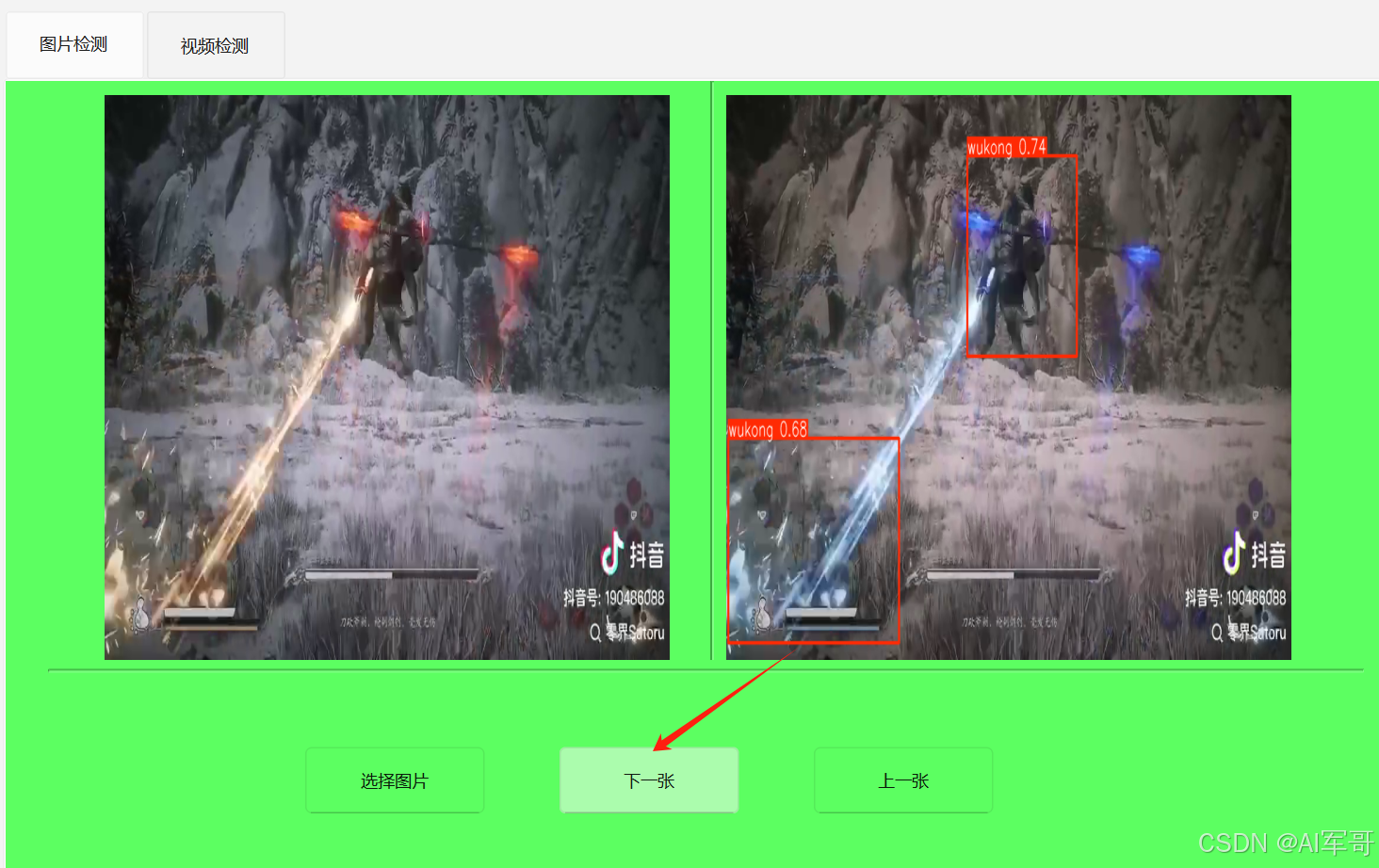
1、原始图片显示
QFileDialog.getOpenFileName() 方法可以获取文件的路径,返回值是一个元组,我们可以获取第一个元素,就是flies0,通过setPixmap将原始图片显示处理。
2、识别图片结果显示
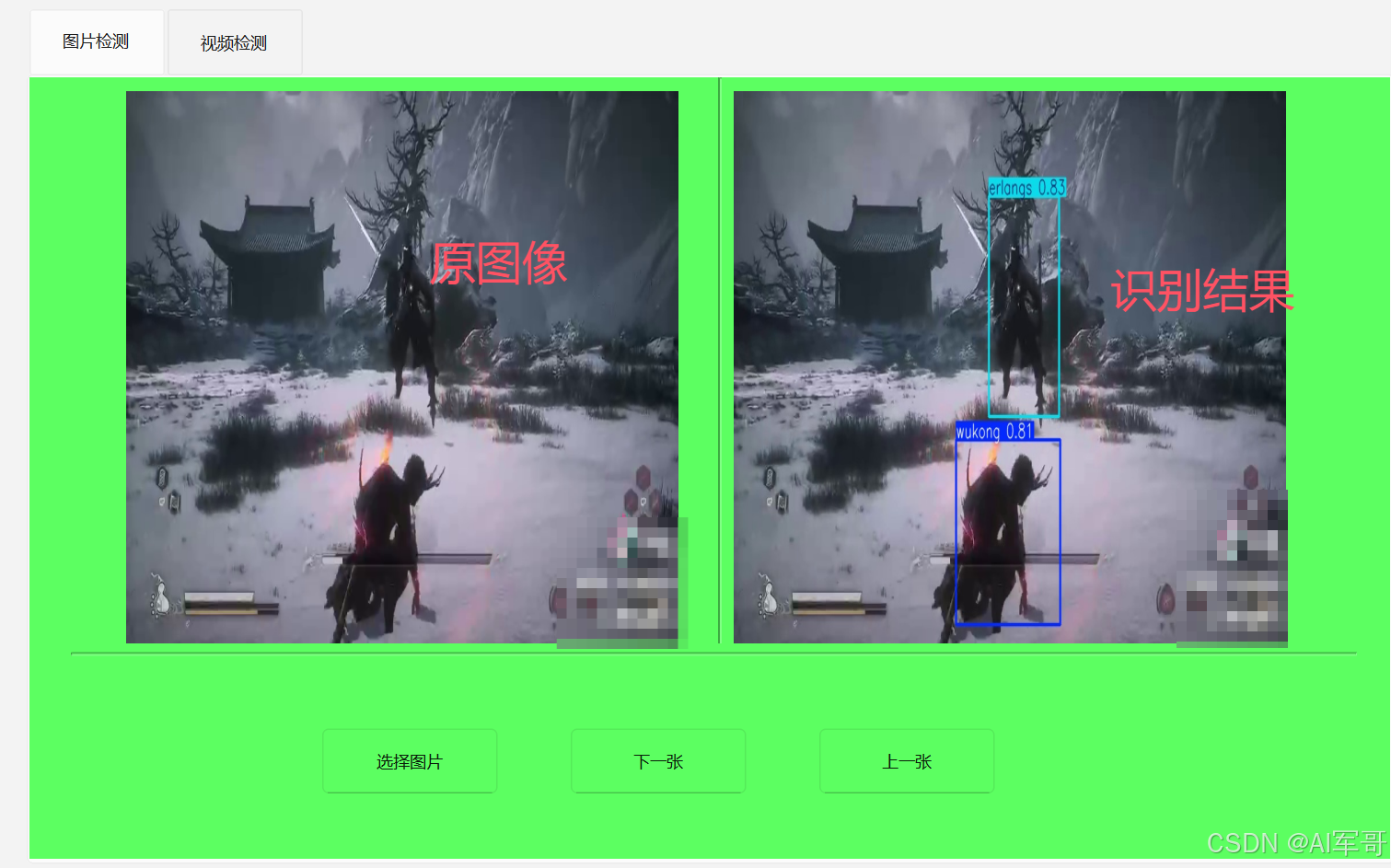
思路分析。通过调用model.predict()方法,每次运行成功之后,就会在runs/detect----->目录下面
predict存放识别结果的图片。 有了这个思路之后,我们只需要获取对应的路径,就能拿到识别图片。然后同样的方式显示处理。这里通过result.save_dir获取识别的结果路径,通过os来拼接完成的路径,最终图片就会显示处理。结果如下:
样式大家下去可以自行调整
弊端:需要准确到找到路径位置
第二种实现思路:
我们可以通过调用model(frame)来训练模型,会生成识别图像的向量数据,然后我们通过该方法,将对应的向量转换为图像,也可以做到以下效果。
核心代码如下:

4、下一张图片功能
思路分析:
获取当前目录的所有文件(图片),列表格式,获取选取到的图片对应的下标,下标+1往后移动一个,下标-1往前移动,对应的就是下一张或者上一张,需要增加最小值和最大的值判断。
代码如下(下):
初始化的代码
# 批量识别图片的下标
self.current_image_index = -1
# 存放所有的图片
self.all_images=[]
def next_img_methods(self):
if self.current_image_index ==-1:
print("请先选择图片")
QMessageBox.critical(None,"error","请先选择图片!")
return
print('下一张图片')
# 识别结果
complox_path = os.path.join(self.root_path,self.all_images[self.current_image_index+1])
# 显示
self.old_img.setPixmap(QPixmap(complox_path))
results = self.model(complox_path)[0].plot()
# for result in results:
# print(result.orig_img)
change_img = conver2Qimage(results)
self.detect_img.setPixmap(QPixmap.fromImage(change_img))
# 增加1
self.current_image_index += 1
print('最大下标',self.current_image_index,len(self.all_images))
# 最大值
if self.current_image_index >= len(self.all_images)-1:
self.current_image_index = len(self.all_images)-25、上一张图片功能
思路分析:主要是想办法知道当前显示图片的下标,上一页减少下标,上一页增加下标。注意控制边界就行,代码和下一张图片功能类似。
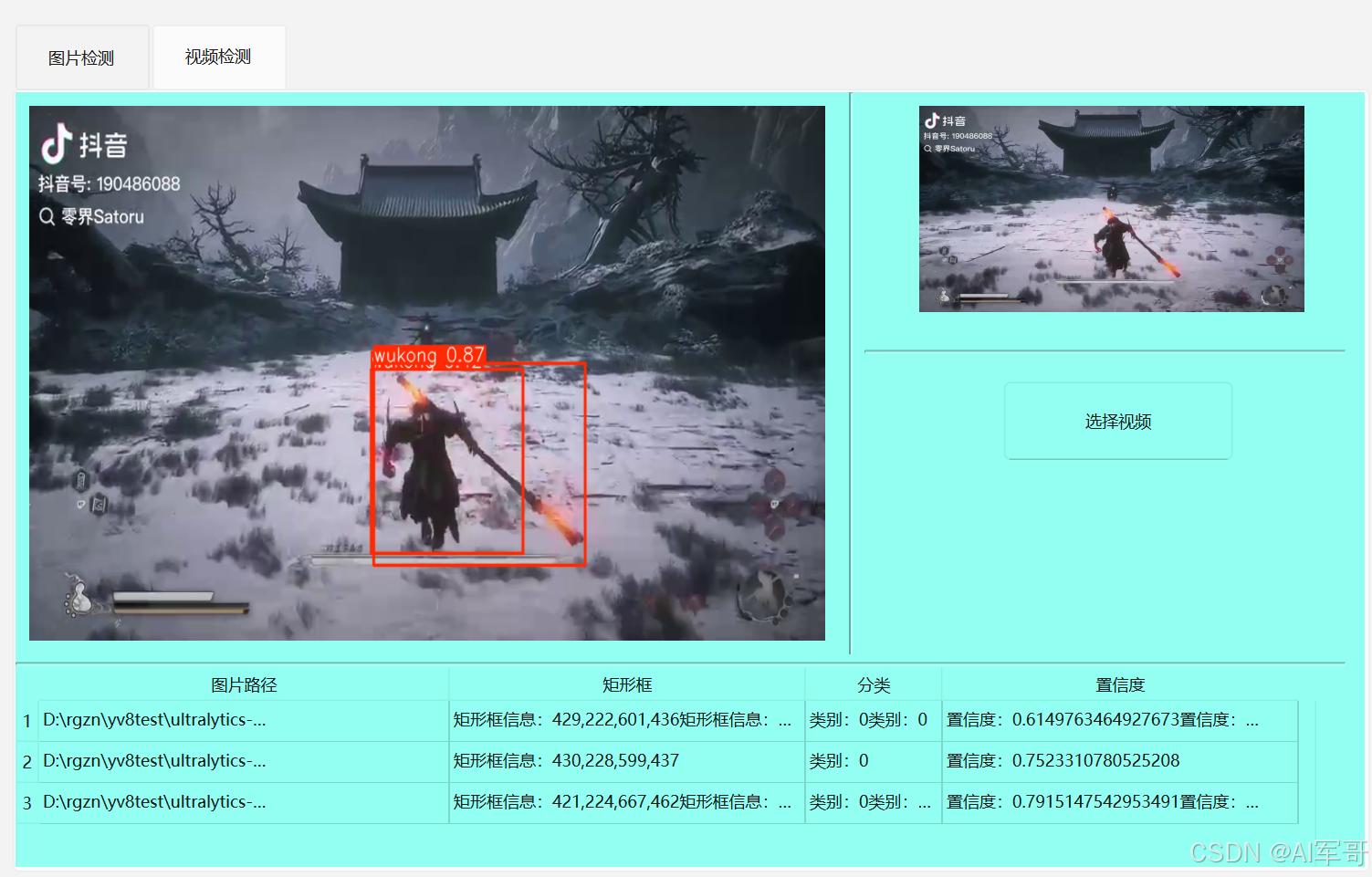
6、视频检测功能
思路分析:其实视频的每一帧就是一张图片,所以其实跟检测图片的功能类似,可以使用opencv解析视频获取每一张图片,然后就跟图片的检测逻辑差不多。
思路二:视频解析如果放在主线程中,会影响其他业务的操作,可以考虑放到线程中去检测视频。
放入主要代码作为参考:
# 开启视频处理独立线程
Thread(target=self.video_detail,daemon=True).start()
# 视频处理流程
def video_detail(self):
while True:
if not self.frameToAnalyze:
time.sleep(0.01)
continue
frame = self.frameToAnalyze.pop(0)
result = self.model(frame)[0].plot()
qimage = conver2Qimage(result)
if self.stop_flag==False:
self.detect_video.setPixmap(QPixmap.fromImage(qimage))
# 写入表格数据
self.detect_video_jianche_result(frame)
# 获取检测结果
self.show_table_data()
# 休眠0.3秒
time.sleep(0.3)
def display_origin_video_image(self,frame):
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
qImage = conver2Qimage(frame)
# 往显示视频的Label里 显示QImage
self.old_video.setPixmap(QPixmap.fromImage(qImage))
# 如果当前没有处理任务
if not self.frameToAnalyze:
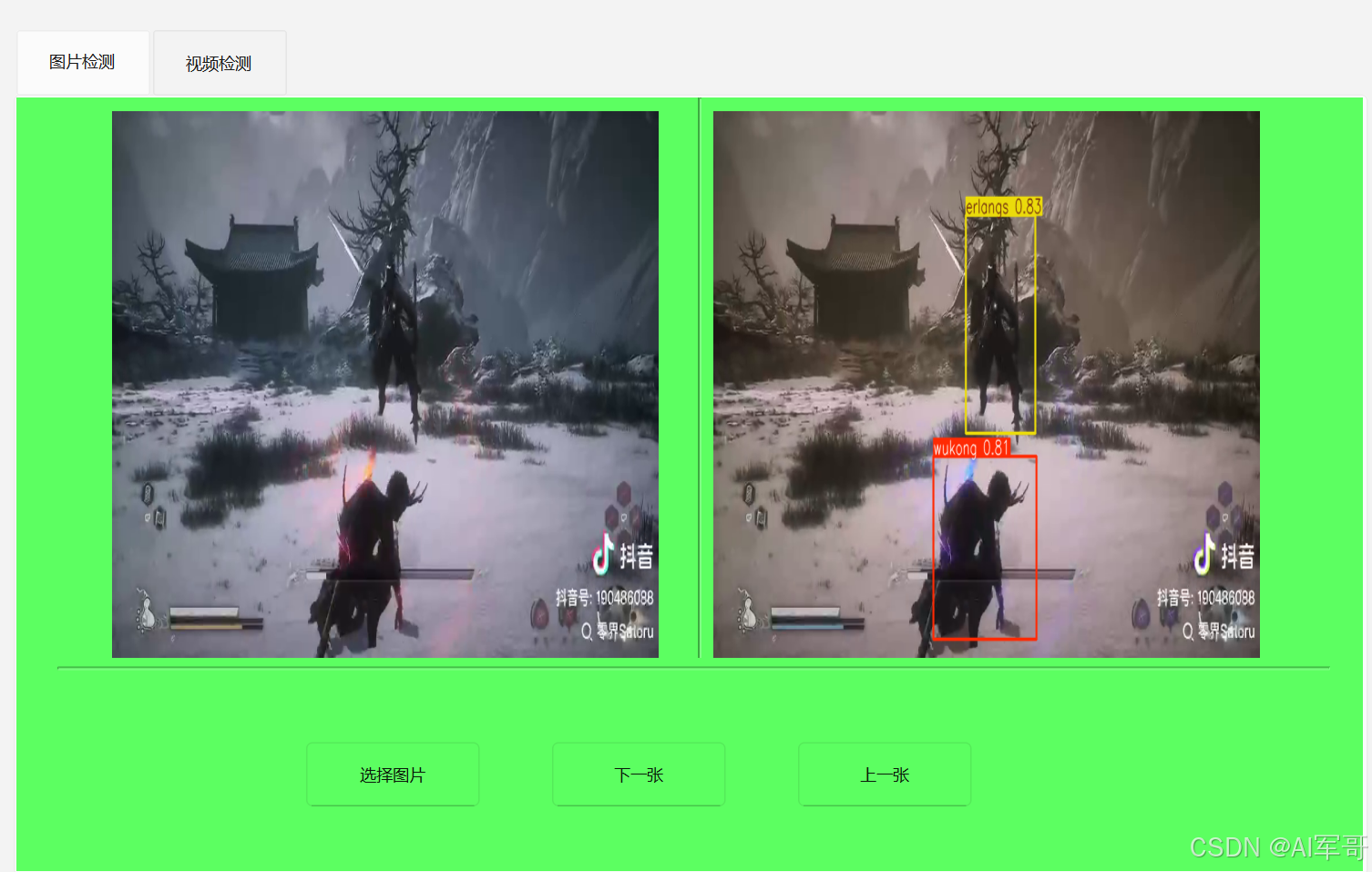
self.frameToAnalyze.append(frame)7、效果展示:
程序没什么难度,对于视频检测来说,不仅是实现功能,还需要考虑性能的问题
补充知识
修改TabWidget的选项样式,字体大小,放大选项

参考代码:
self.tabWidget.setStyleSheet("QTabBar::tab { font-size: 12px;width:100px;height:50px;}")