基本信息
标题:MHAF-YOLO: Multi-Branch Heterogeneous Auxiliary Fusion YOLO for accurate object detection(MHAF-YOLO:用于精确目标检测的多分支异构辅助融合YOLO)
作者:Zhiqiang Yang, Qiu Guan, Zhongwen Yu, Xinli Xu, Haixia Long, Sheng Lian, Haigen Hu, Ying Tang
机构:主要来自中国高校研究团队
代码:https://github.com/yang-0201/MHAF-YOLO
摘要
由于路径聚合FPN(PAFPN)有效的多尺度特征融合能力,它已成为基于YOLO的检测器中广泛采用的组件。然而,PAFPN难以整合高级语义线索与低级空间细节,限制了其在现实世界应用中的性能,特别是在尺度变化显著的场景中。在本文中,我们提出了MHAF-YOLO,一种新颖的检测框架,其特点是一个多功能的颈部设计,称为多分支辅助FPN(MAFPN),它由两个关键模块组成:表层辅助融合(SAF)和高级辅助融合(AAF)。SAF通过融合浅层特征连接骨干网络和颈部,有效地以高保真度传递关键的低级空间信息。同时,AAF在颈部的更深层次整合多尺度特征信息,向输出层提供更丰富的梯度信息,并进一步增强模型的学习能力。为了补充MAFPN,我们引入了全局异构灵活核选择(GHFKS)机制和重参数化异构多尺度(RepHMS)模块以增强特征融合。RepHMS全局集成到网络中,利用GHFKS为各种特征层选择更大的卷积核,扩展垂直感受野并捕获跨空间层次的上下文信息。在局部,它通过在同一层内处理大核和小核来优化卷积,拓宽横向感受野并保留检测较小目标的关键细节。MHAF-YOLO的小型版本在COCO上实现了48.9%的AP,仅使用7.1M参数,相比YOLO11s减少了24.4%,同时性能提高了1.9%。此外,我们的模型在实例分割和旋转目标检测中均展示了卓越的性能和泛化能力。本工作的源代码可在:https://github.com/yang-0201/MHAF-YOLO 获取。
关键词:目标检测,YOLO,多尺度特征融合,模型效率
1. 引言
近年来,已经开发了各种算法来实现高性能的实时目标检测。其中,一系列YOLO算法1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,从YOLOv1到YOLOv12,由于在速度和精度之间的权衡,发挥了越来越重要的作用。
特征金字塔网络(FPN)20利用自上而下的架构,用高级语义信息丰富低级特征,有效地生成多尺度特征图。基于FPN,路径聚合特征金字塔网络(PAFPN)21引入了自下而上的路径,允许来自较低层的精确定位信息更有效地向上传输。这种增强改进了特征金字塔的整体定位能力。此外,由于其直接高效的融合机制,PAFPN已在YOLO系列模型中得到广泛应用。在图1(a)中,层P2-P5表示骨干网络不同级别的输出信息。YOLO系列的颈部结构使用传统的PAFPN,它包含两条用于多尺度特征融合的主要路径。然而,我们发现PAFPN仍然存在两个显著的局限性。
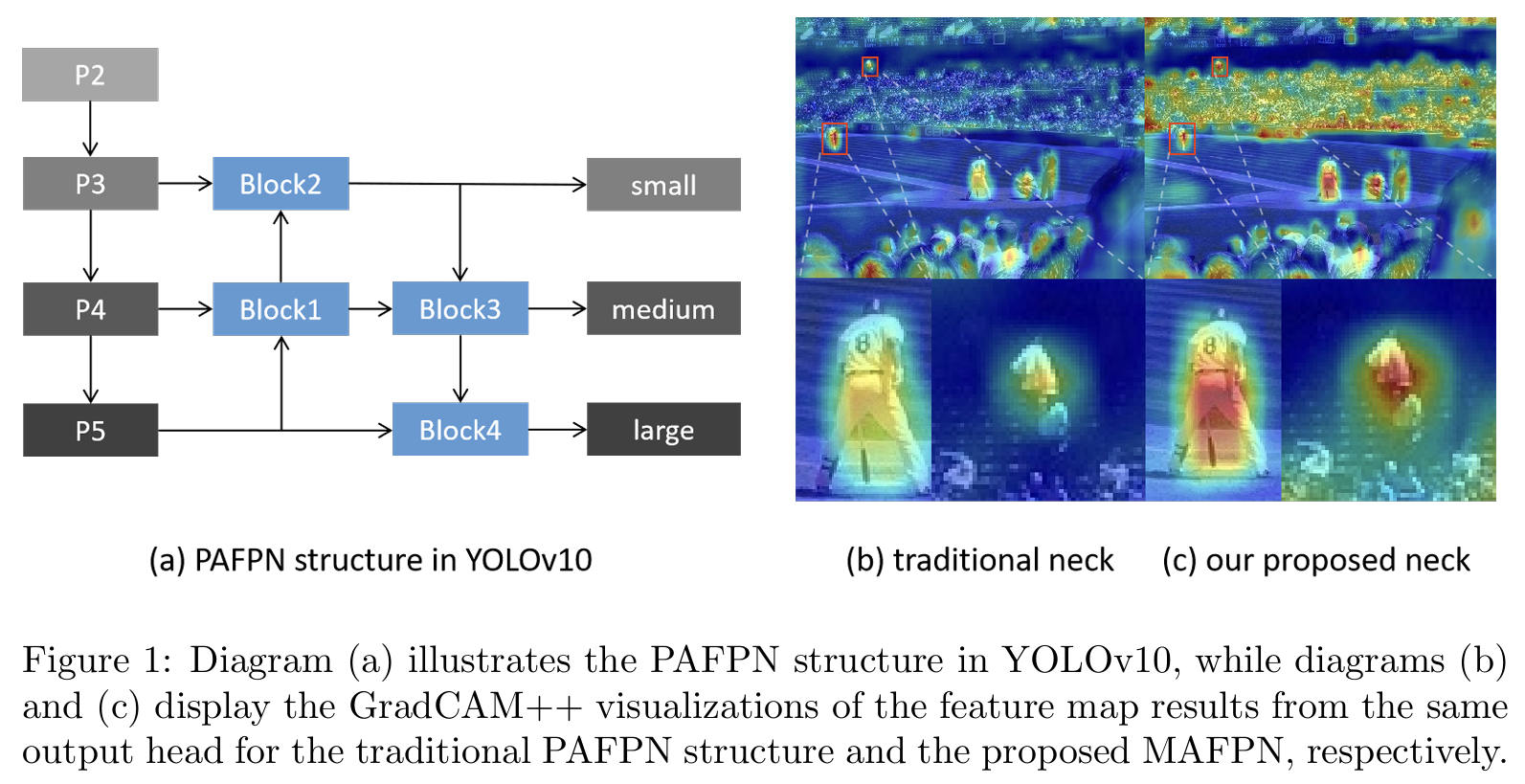
首先,PAFPN结构主要关注合并相似尺度的特征图,但在有效处理和整合来自不同分辨率层的多尺度信息方面表现不足。这种保守的特征融合方法可能会阻碍模型在各个级别之间的充分参与,可能导致深层中的详细信息丢失,并在每个尺度上产生过度简化的结果。例如,在PAFPN的Block1中,输入合并了上采样的P5层与相邻的P4层,忽略了P3层中存在的关键浅层、低级空间细节。同样,在Block2中,明显缺少与P2层的直接融合,这对于捕获小目标细节至关重要。这一不足在Block3和Block4中也很明显,限制了特征融合过程的整体有效性。
其次,小目标检测层的架构策略采用单一的自上而下路径和两个相关块进行设计。这种配置显著削弱了模型有效学习和表示小目标特征的能力,因为小目标检测层缺乏来自其他特征层的足够补充信息。更重要的是,PAFPN中的每个特征提取模块通常由改进的跨阶段部分网络(CSPNet)22和固定的3×33\times33×3卷积组成,这限制了网络的灵活性并限制了其捕获更大感受野的能力。在实际应用中,这些限制可能导致PAFPN在同时分布着不同尺度物体的场景或密集小物体场景中表现不佳。例如,在图1(b)和©中,使用PAFPN的YOLOv10模型对密集小人群显示出明显较低的激活水平,与本文提出的MAFPN相比。
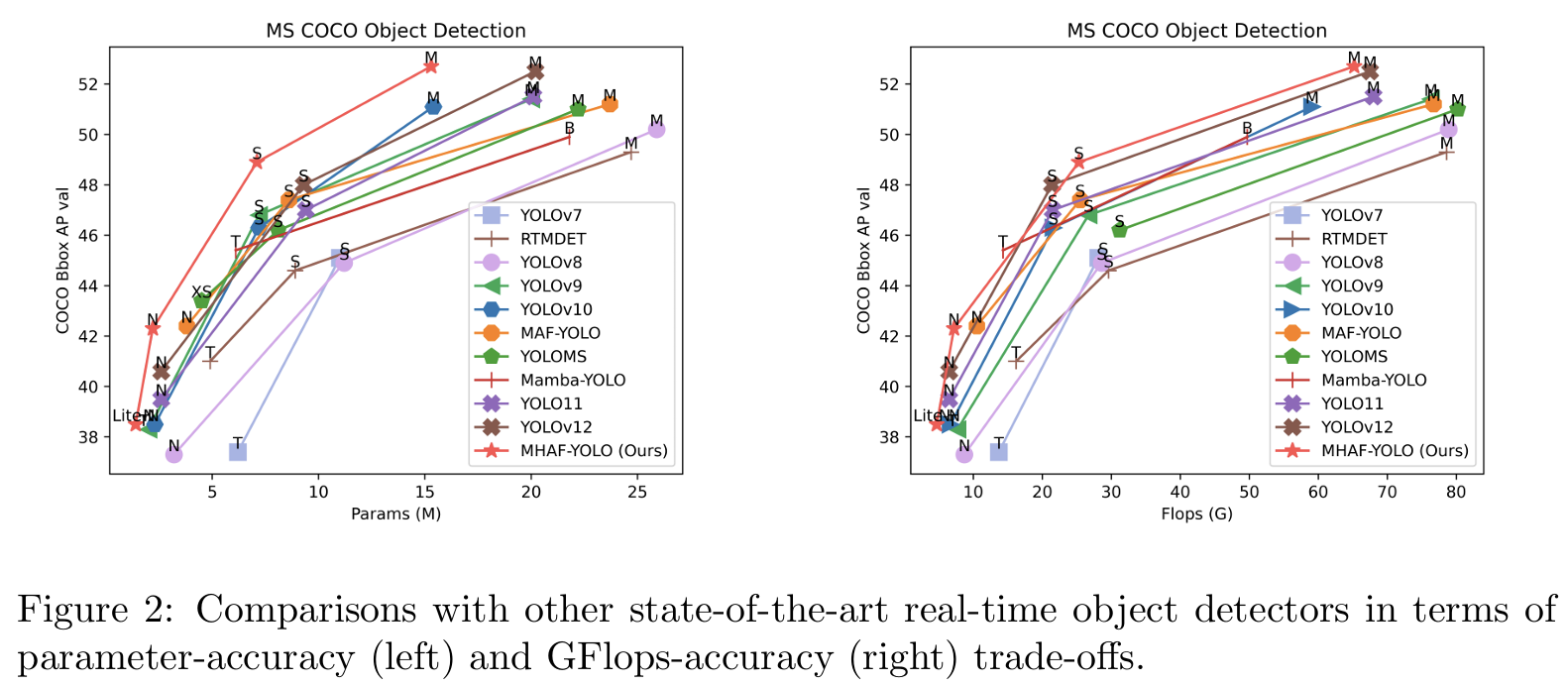
我们进行了大量实验来验证MHAF-YOLO的有效性,通过缩放模型大小,为各种应用场景提供lite-nano、nano、small和medium变体。如图2所示,MHAF-YOLO以更少的参数和更低的计算成本实现了最高的精度,超越了所有最先进的(SOTA)YOLO检测器。减少的计算负载在计算资源有限的设备上尤其有价值。本文的主要贡献总结如下:
· 我们提出了一种新的即插即用颈部,称为多分支辅助FPN(MAFPN),以实现更丰富的特征交互和融合。在MAFPN中,表层辅助融合(SAF)通过双向连接保持浅层骨干网络信息,增强网络检测小目标的能力。此外,高级辅助融合(AAF)通过多向连接丰富输出层的梯度信息。此外,MAFPN可以无缝集成到任何其他检测器中,以增强其多尺度表示能力。
· 我们设计了重参数化异构多尺度(RepHMS)模块,具有高参数利用率。该模块通过将大核卷积与几个小核卷积并行化,在不增加额外推理成本的情况下扩展感知范围,同时保留关于小物体的信息。RepHMS可以无缝集成到骨干网络或FPN中,增强任何网络的性能。
· 我们提出了一种全局异构灵活核选择(GHFKS)机制,它通过调整RepHMS中不同分辨率特征层的核大小,自适应地扩大整个网络的有效感受野。
具有极高参数利用率的多分支异构辅助融合YOLO(MHAF-YOLO)在COCO数据集的目标检测中实现了最先进的性能,超越了现有的实时目标检测器。此外,MHAF-YOLO在实例分割和旋转目标检测中表现出卓越的性能,展示了其强大的泛化能力。
2. 相关工作
2.1. 实时目标检测器
在实际应用中,为了满足众多检测任务,更快、更强的网络被更广泛地使用。实时目标检测器由此趋势演变而来,成为许多需要即时分析和与动态环境交互的应用中不可或缺的一部分。YOLOv1-YOLOv3 1, 2, 3开创了一阶段实时检测,并奠定了多尺度检测框架的基础。YOLOv4 4引入了PAFPN结构,还利用了mosaic和mixup数据增强,这些方法一直沿用至今。YOLOv5 5基于锚框设计了更优化的一对多标签分配,改进了数据增强技术,并整合了一个基于CNN的实时通用目标检测框架,包括骨干网络、多尺度特征金字塔和密集检测头。YOLOX 6首次提出了基于动态标签分配策略的YOLO检测框架,移除了依赖人工先验或数据本身归纳偏差的锚框。这实现了一种完全无锚的多尺度标签分配。随后,PPYOLOE 12和YOLOv6 7探索了重参数化技术,并采用了任务对齐学习(TAL)23策略进行标签分配。重参数化技术增强了单个卷积的表示能力,而不会增加网络的参数数量或推理速度,从而为后续YOLO模型的优化提供了新方向。同时,TAL方法的高效性能已经标准化了这些模型中的标签分配策略。YOLOv7 8提出了高效层聚合网络(ELAN)方案,以优化来自YOLOv4的跨阶段部分网络结构,并设计了几种可训练的免费技巧方法用于无损模型优化,为轻量级YOLO网络做出了贡献。DAMO-YOLO 10使用MAE-NAS 24在低延迟和高性能约束下搜索骨干网络,并结合知识蒸馏进一步提高检测器的性能。YOLOv8 9充分吸收了广泛验证有效的动态标签分配策略、无锚检测架构和ELAN模块设计理念,并将YOLO架构扩展到分割和姿态估计领域。YOLOv9 15探索了当数据通过深度网络时发生的信息瓶颈问题,并引入了可编程梯度信息(PGI)的概念来处理深度网络实现多个目标所需的各种变化。此外,它进一步实现了网络架构的轻量化。YOLOv10 17使用一对多和一对一检测头,有效地将YOLO框架推向端到端推理范式,消除了非最大抑制的后处理步骤。YOLO11 18代表了YOLO检测技术的最新进展,引入了名为C3k2和C2PSA的特征提取模块,显著增强了每个模型的性能。
在整个YOLO模型的发展过程中,大多数版本都专注于优化和改进其基础卷积模块。然而,相对较少的YOLO模型深入解决了特征融合的挑战。值得注意的是,即使是最新版本,YOLOv7到YOLO11,仍然依赖于原始的PAFPN结构。因此,本文对卷积模块优化的流行方向和特征融合增强这一较少探索的领域进行了更全面的研究。
2.2. 用于目标检测的多尺度特征融合
不同大小的目标是检测任务的主要特征。不同尺度的特征图对应不同大小的目标信息。通常,低维信息用于表示小物体,高维信息用于表示大物体。各维度特征之间存在隐含的相关性。随着网络深度的增加,低级纹理特征将转化为高级语义信息。如何增强不同级别特征之间的连接是许多工作的重点。
特征金字塔网络(FPN)是第一个提出在目标检测中进行特征融合的算法。FPN的初衷是通过结合跨尺度连接和信息交换来增强网络的多尺度检测能力。然而,FPN的自下而上融合方法略显简单。它仅将高级层的语义信息传输到低级层,但低级层的纹理信息并未传输到高级层。路径聚合网络(PANet)采用了自下而上的路径,基于FPN使不同级别之间的信息融合更加充分。YOLOv6使用双向连接(BIC)机制更好地利用骨干网络的浅层信息,对高分辨率特征和低分辨率特征的处理可以同时考虑大目标和小目标检测。此外,渐近特征金字塔网络(AFPN)25首先融合两个相邻的低级特征,然后逐渐将高级特征纳入融合过程。通过这种方式,可以避免非相邻级别之间较大的语义差距。DAMO-YOLO采用重参数化通用FPN(RepGFPN)实现骨干网络和颈部的更丰富融合。Gold-YOLO 13提出了收集和分发机制(GD),通过卷积和自注意力实现,进一步提高了多尺度特征的融合能力。每个尺度的信息通过统一模块收集和融合,然后将融合后的特征分发到不同层。这不仅避免了传统FPN结构固有的信息丢失,而且在不显著增加延迟的情况下增强了颈部部分的信息融合能力。这些方法全面考虑了多尺度特征的特性,并为目标检测中的特征融合做出了贡献,但仍有进一步优化的空间。
2.3. 基础卷积模块
CSPNet 22从网络架构角度缓解了先前工作需要大量推理计算的问题。它在减少大量计算的同时有效提高了精度,并且具有很强的易用性和通用性。在大多数早期的YOLO网络中,CSPNet结构被广泛用作基本特征提取模块。最新的最先进YOLO模型采用CSPNet的变体来实现卓越性能。这些模块集成在网络的骨干和颈部中。值得注意的是,虽然这些模块具有相似的整体架构,但它们的瓶颈结构略有不同。不同的瓶颈由几个常规卷积、DW卷积、重参数化卷积等组成。
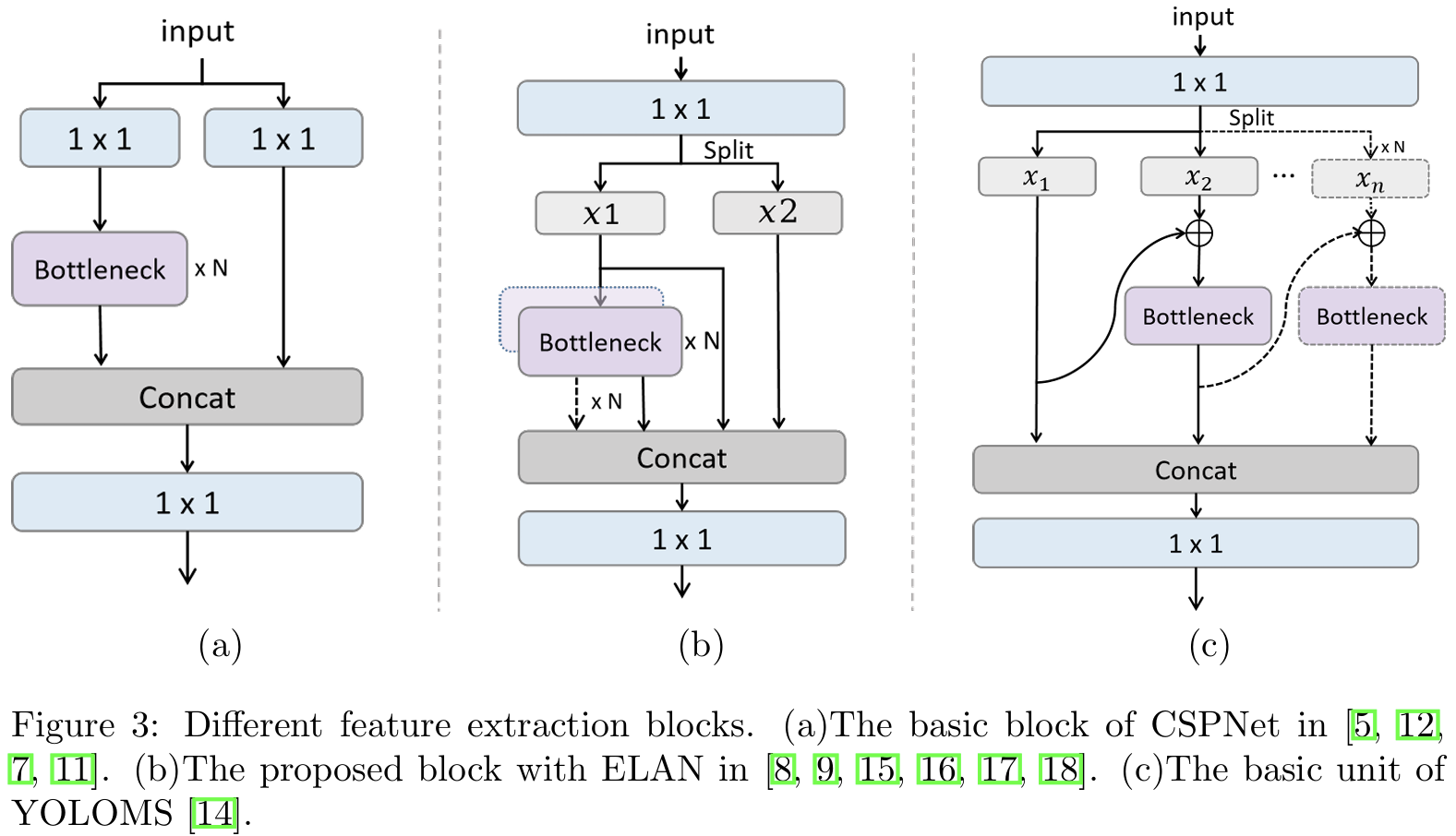
如图3(a)所示,YOLOv5中的C3模块、PPYOLOE中的CSPRes模块、YOLOv6中的BepC3模块和RTMDet中的CSPNextBlock都是经典的CSPNet结构。输入通过1×11\times11×1卷积分为两个分支,每个分支具有原始输入的一半通道。第一个分支通过多个瓶颈进行深度特征提取,然后与第二个分支连接,再进行最终输出。
在设计网络架构时,YOLOv7考虑了梯度传播效率,以平衡网络的学习能力。与CSPNet相比,ELAN的设计更注重优化梯度路径,减少与梯度消失和爆炸相关的问题。这增强了模型在训练期间的稳定性和收敛速度。此外,ELAN在保持高检测精度的同时,进一步减少了不必要的计算负载和参数数量,从而提高了模型的推理速度。它开发了ELAN,如图3(b)所示,用于后续模型,如YOLOv8中的C2f模块、YOLOv9中的GELAN模块、MAF-YOLO中的RepHELAN模块、YOLOv10中的CIB模块和YOLO11中的C3k2模块。ELAN变体用分割操作替换了CSPNet中的两个1×11\times11×1卷积,并保留了每个瓶颈的输出。在最终输出前将这些输出连接起来。
YOLOMS中提出的MSBlock与CSPNet相比,在多尺度特征表示方面提供了显著增强。它利用分层特征融合策略,使用多个分支进行特征提取,并将不同大小的卷积核引入骨干网络,以捕获不同尺度的特征。这种设计使模型能够更有效地处理各种大小的物体,从而提高检测精度。此外,与先前YOLO版本中使用的标准卷积或重参数化卷积不同,MSBlock结合了倒置瓶颈块和深度卷积以减少计算成本。如图3©所示,MSBlock通过使用宽度增强和级联连接增强了网络的深度。输入分为N个分支,每个分支通过瓶颈模块处理。每个分支的输出然后传递给后续分支,使深度特征信息在整个网络中有效传输。
3. 方法
3.1. 宏观架构
如图4所示,我们将单阶段目标检测器的宏观架构分解为三个主要组件:骨干网络、颈部和头部。在提出的MHAF-YOLO中,输入图像首先通过骨干网络,它由四个阶段组成:P2、P3、P4和P5。MAFPN被设计为颈部结构。在第一自下而上路径中,SAF模块负责从骨干网络提取多尺度特征,并在颈部的浅层执行初步辅助融合。同时,AAF通过第二自上而下路径中的密集连接从每个深层收集梯度信息,最终指导头部在三个分辨率上获得多样化的输出信息。上述两种结构都采用RepHMS模块进行特征提取,无缝集成GHFKS概念,利用动态大小的卷积核,在不同层上实现自适应感受野。最后,检测头根据每个尺度的特征图预测目标边界框及其相应类别,以计算损失。
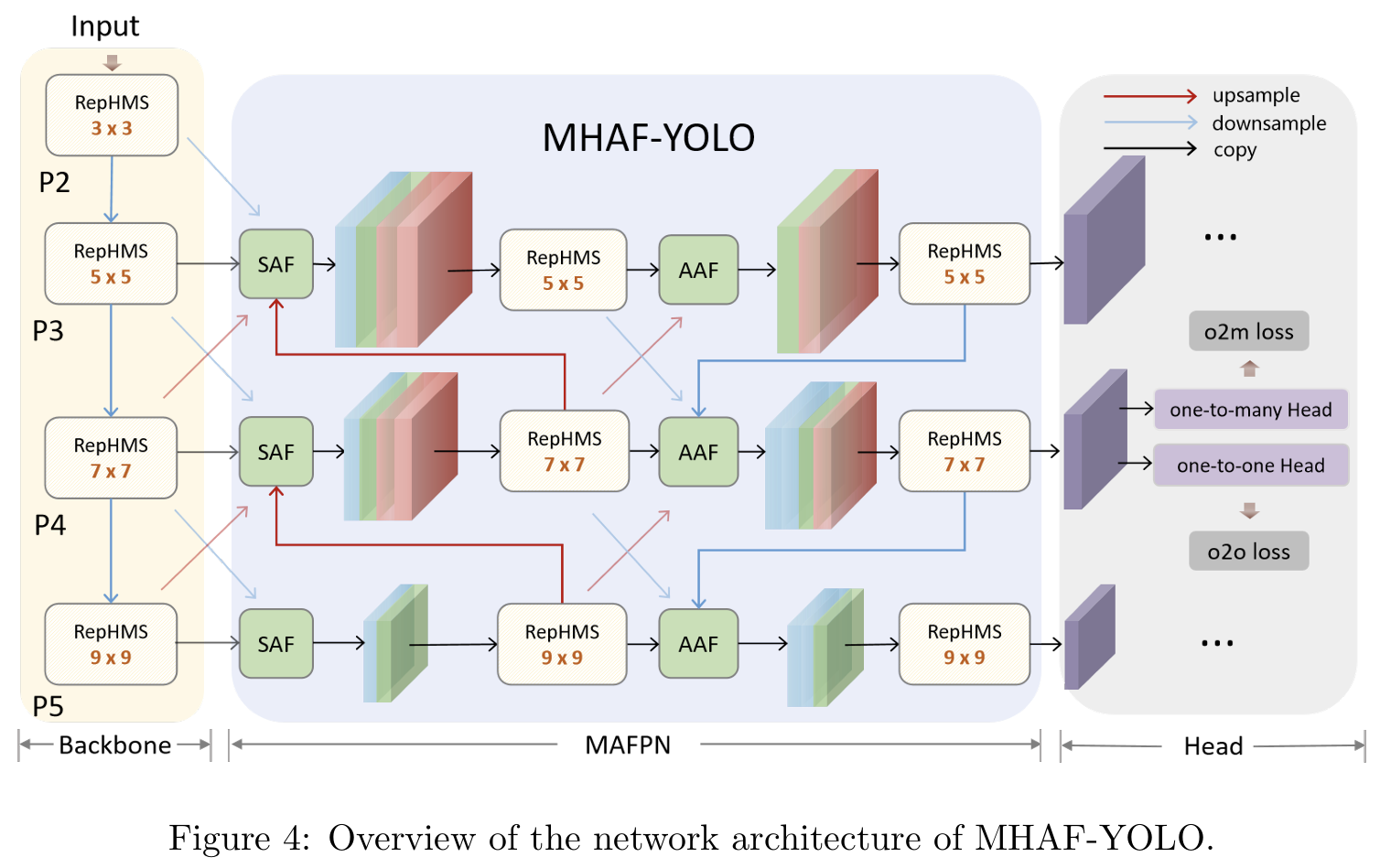
3.2. 全局自适应异构灵活核选择机制
变换器有效性的一个重要因素是它们的自注意力机制,它在全局或更大窗口尺度上执行查询-键-值操作。同样,大卷积核捕获局部和全局特征,使用适度大的卷积核增加有效感受野在几项工作中已被证明是有效的。Trident网络26进行的研究表明,具有更大感受野的网络更适合检测更大的物体,相反,更小尺度的目标受益于更小的感受野。YOLOMS 14引入了异构核选择(HKS)协议的概念。在骨干网络中采用3、5、7和9的递增卷积核设计,以平衡性能和速度。受这项工作的启发,我们将其扩展到全局异构灵活核选择(GHFKS)机制,将异构大卷积核的概念集成到整个MHAF-YOLO架构中。除了骨干网络RepHMS中递增的卷积核外,我们还在MAFPN中引入了5、7和9的大卷积核,以适应不同分辨率的要求,从而逐步获得多尺度感知场信息。
3.3. 多分支辅助FPN
精确定位依赖于浅层网络中的详细边缘信息,而精确分类需要更深的网络来捕获粗粒度信息3。我们认为,有效的FPN应该支持浅层和深层网络信息流的充分收敛。
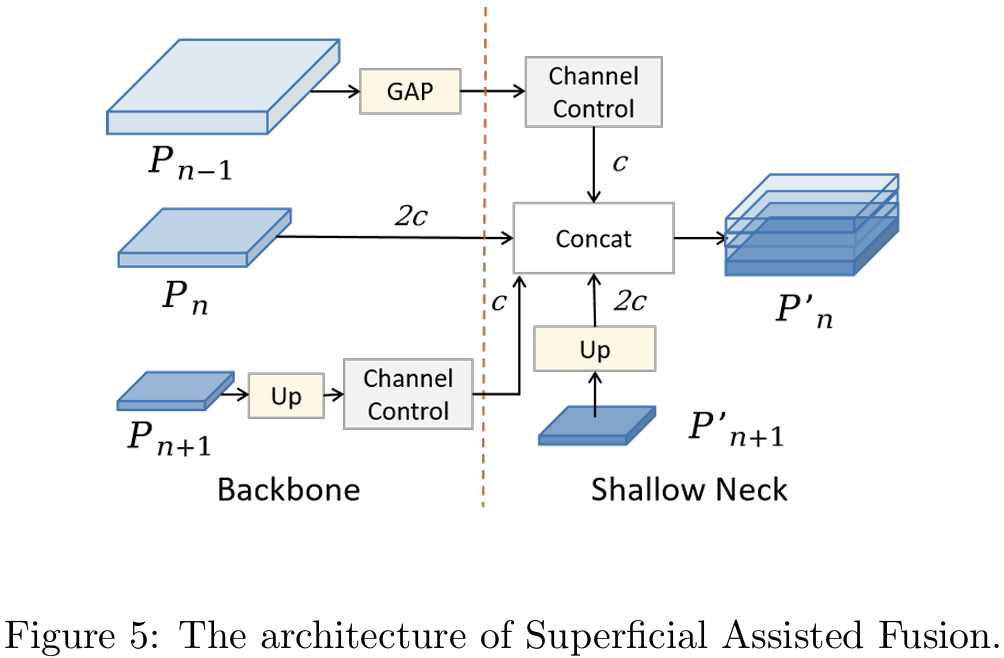
3.3.1. 表层辅助融合
在骨干网络中保留浅层空间信息对于增强小物体的检测能力至关重要。然而,骨干网络提供的信息相对基础且容易受到干扰。因此,我们将浅层信息作为辅助分支整合到更深的网络中,以确保后续层学习的稳定性。根据这些原则,我们开发了SAF模块,如图5所示。SAF的主要目标是将深层信息与骨干网络中多尺度特征层嵌入的浅层空间信息集成,旨在保留丰富的定位细节,以增强网络的空间表示。此外,我们使用1×11\times11×1卷积控制浅层信息中的通道数量,确保它在concat操作中占较小比例,不会影响后续学习。让Pn−1P_{n-1}Pn−1、PnP_{n}Pn和Pn+1 ∈ RH×W×CP_{n+1}\,\in\,R^{H\times W\times C}Pn+1∈RH×W×C表示不同分辨率的特征图,其中PnP_{n}Pn、Pn′P_{n}^{\prime}Pn′和Pn′′P_{n}^{\prime\prime}Pn′′表示骨干网络和MAFPN的两条路径的特征层。符号U(·)表示上采样操作。GAPGAPGAP代表全局平均池化,Down表示伴随批量归一化层的3×33\times33×3下采样卷积,δ\deltaδ表示silu函数,Conv表示控制通道数量的1×11\times11×1卷积。应用SAF后的输出结果如下:
Pn′=concat(δ(GAP(Pn−1)),Pn,δ(Conv(U(Pn+1))),U(Pn+1′))P_{n}^{\prime}=concat(\delta(GAP(P_{n-1})),P_{n},\delta(Conv(U(P_{n+1}))),U(P_{n+1}^{\prime}))Pn′=concat(δ(GAP(Pn−1)),Pn,δ(Conv(U(Pn+1))),U(Pn+1′))
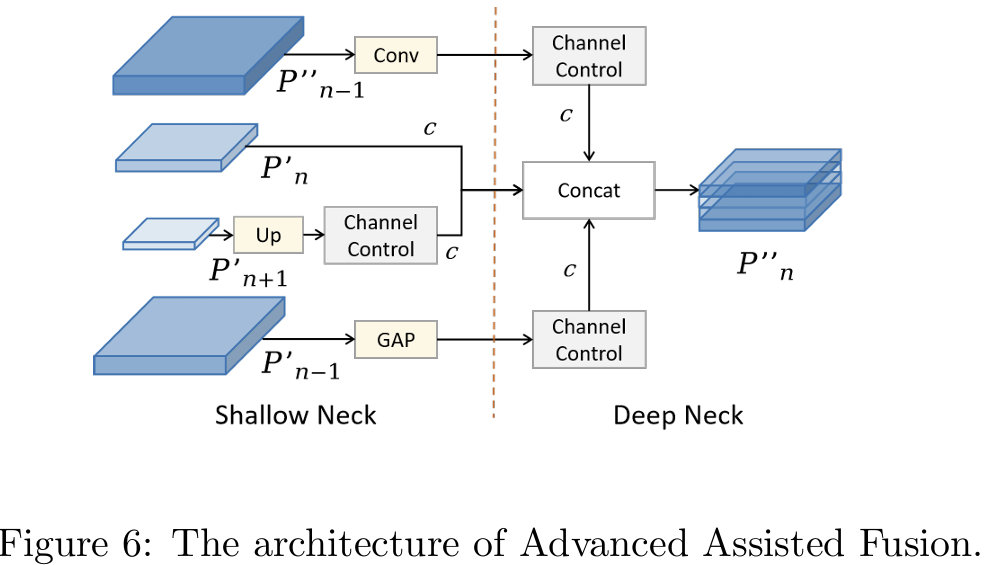
3.3.2. 高级辅助融合
为了进一步增强特征层信息的交互利用,我们在MAFPN的深层中采用AAF模块进行多尺度信息集成。具体来说,图6展示了Pn′′P_{n}^{\prime\prime}Pn′′中的AAF连接,涉及浅层高分辨率层Pn+1′P_{n+1}^{\prime}Pn+1′、浅层低分辨率层Pn−1′P_{n-1}^{\prime}Pn−1′、同级浅层Pn′P_{n}^{\prime}Pn′和前一层Pn−1′′P_{n-1}^{\prime\prime}Pn−1′′的信息聚合。此时,最终输出层P4可以同时合并来自四个不同层的信息,从而显著增强中等大小目标的性能。AAF还采用1×11\times11×1卷积控制通道来调节每层对结果的影响。通过实验,我们发现当使用SAF中的策略时,即三个浅层的通道数设置为深层通道数的一半,反而会导致性能轻微下降。借鉴FPN的传统单路径架构,我们假设初始引导信息已经嵌入在MAFPN的浅层中。因此,我们使每层的通道数相等,以确保模型获得多样化的输出。应用AAF后的输出结果如下:
Pn′′=concat(δ(Down(Pn−1′)),δ(GAP(Pn−1′′)),Pn′,δ(Conv(U(Pn+1′))))P_{n}^{\prime\prime}=concat(\delta(Down(P_{n-1}^{\prime})),\delta(GAP(P_{n-1}^{\prime\prime})),P_{n}^{\prime},\delta(Conv(U(P_{n+1}^{\prime}))))Pn′′=concat(δ(Down(Pn−1′)),δ(GAP(Pn−1′′)),Pn′,δ(Conv(U(Pn+1′))))
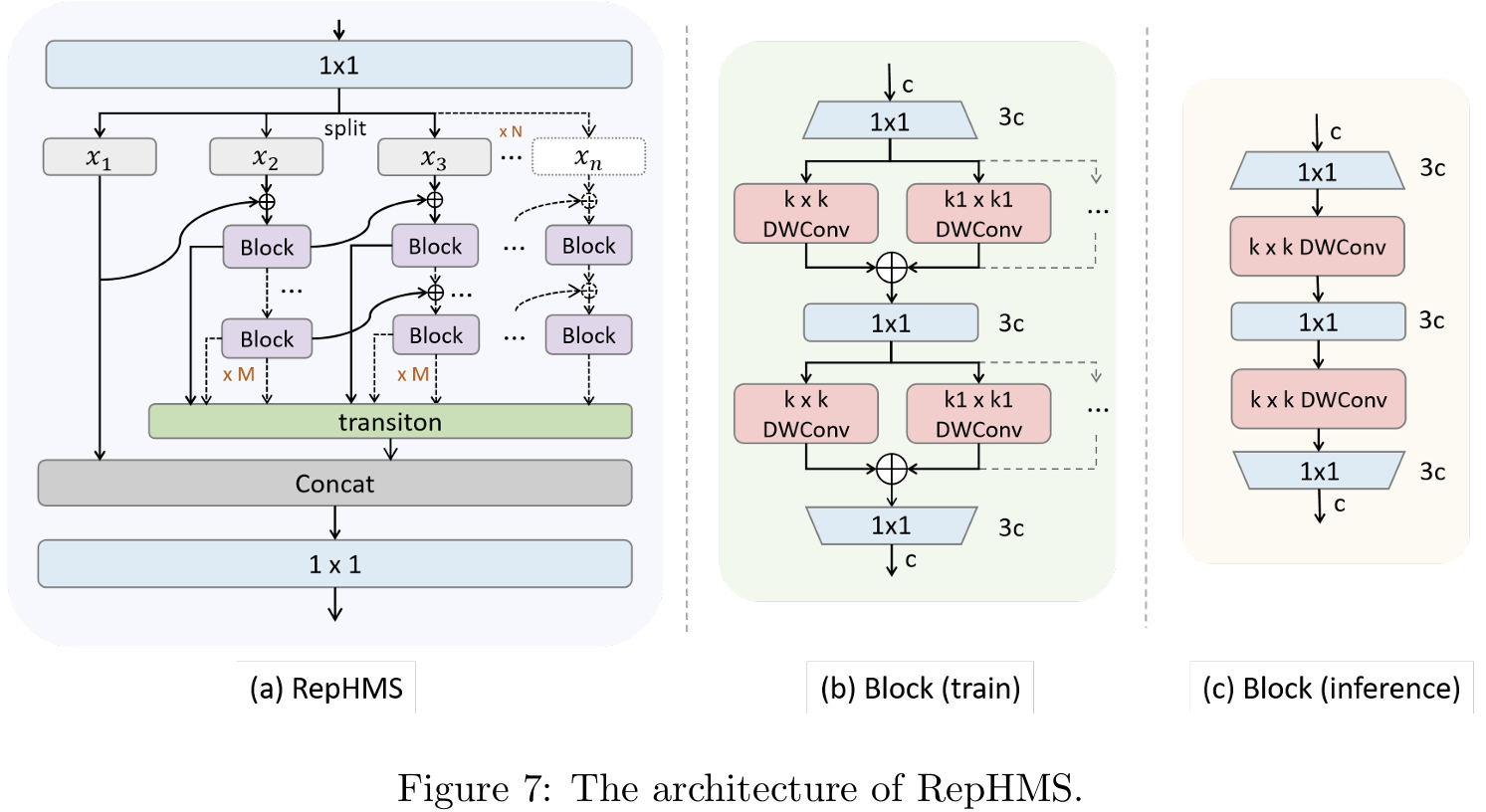
在前一节中设计了MAFPN结构后,另一个挑战在于高效设计整个架构中的特征提取块。本节介绍了一种强大的编码器架构设计,能够高效学习表达性的多尺度特征表示,具有极高的参数利用率。RepHMS的结构如图7(a)所示。最初,输入信息经过1×11\times11×1卷积和分割操作,产生N个信息流。第一个分支保留原始浅层信息。从第二个分支开始,输入信息通过M个连接的块来增强特征提取能力。结合ELAN的思想,保留每个块的输出并集成到最终输出层。此外,每个分支包括级联概念,允许即使是并行分支也能接收来自前一分支的浅层信息,从而丰富梯度流。最后一个分支输出最深级别的信息,最终的连接和1×11\times11×1卷积操作整合并输出多样化的分支信息。通过调整系数M和N,我们可以轻松控制RepHMS的特征提取能力。RepHMS尽可能多地保留每个分支中的梯度流信息,同时通过级联连接逐步整合来自前一层的更深层信息。随着过程继续,分支中的信息变得越来越多样化,特征提取变得更加彻底,将信息的表示优化到最大程度。因此,RepHMS模块可以无缝集成到任何高级检测器中,显著增强其性能。
如图7(b)所示,每个块由几个DW卷积组成,结合先进的重参数化技术实现高参数效率。第一个1×11\times11×1卷积扩展通道,每个RepHConv后跟一个点卷积以补偿DW卷积的性能损失。最终卷积缩放通道数量。
3.5. 重参数化异构深度卷积
首先,我们在全局架构中采用大核深度卷积来实现上述GHFKS机制。我们的研究还表明,虽然更大的卷积核可能通过编码更广泛的区域能够增强性能,但它们可能会无意中模糊与小目标相关的细节,因此仍有改进空间。因此,我们将全局架构中的异构思想转移到单个卷积,并结合重参数化27,28,29的思想来实现RepHConv。具体来说,我们通过同时运行大核和小核卷积来补充小目标的检测。不同大小的卷积核增强了网络的ERF和特征的多样化表示。
如图7(b)和©所示,Block在训练和推理之间存在某些差异。在训练期间,网络运行n个不同大小的并行深度卷积(DWConv)操作,而在推理期间,这些卷积被合并为一个,不会降低推理速度。我们认为RepHDWConv是一种卓越的卷积策略,它以最小损失增强了多尺度的表示能力。
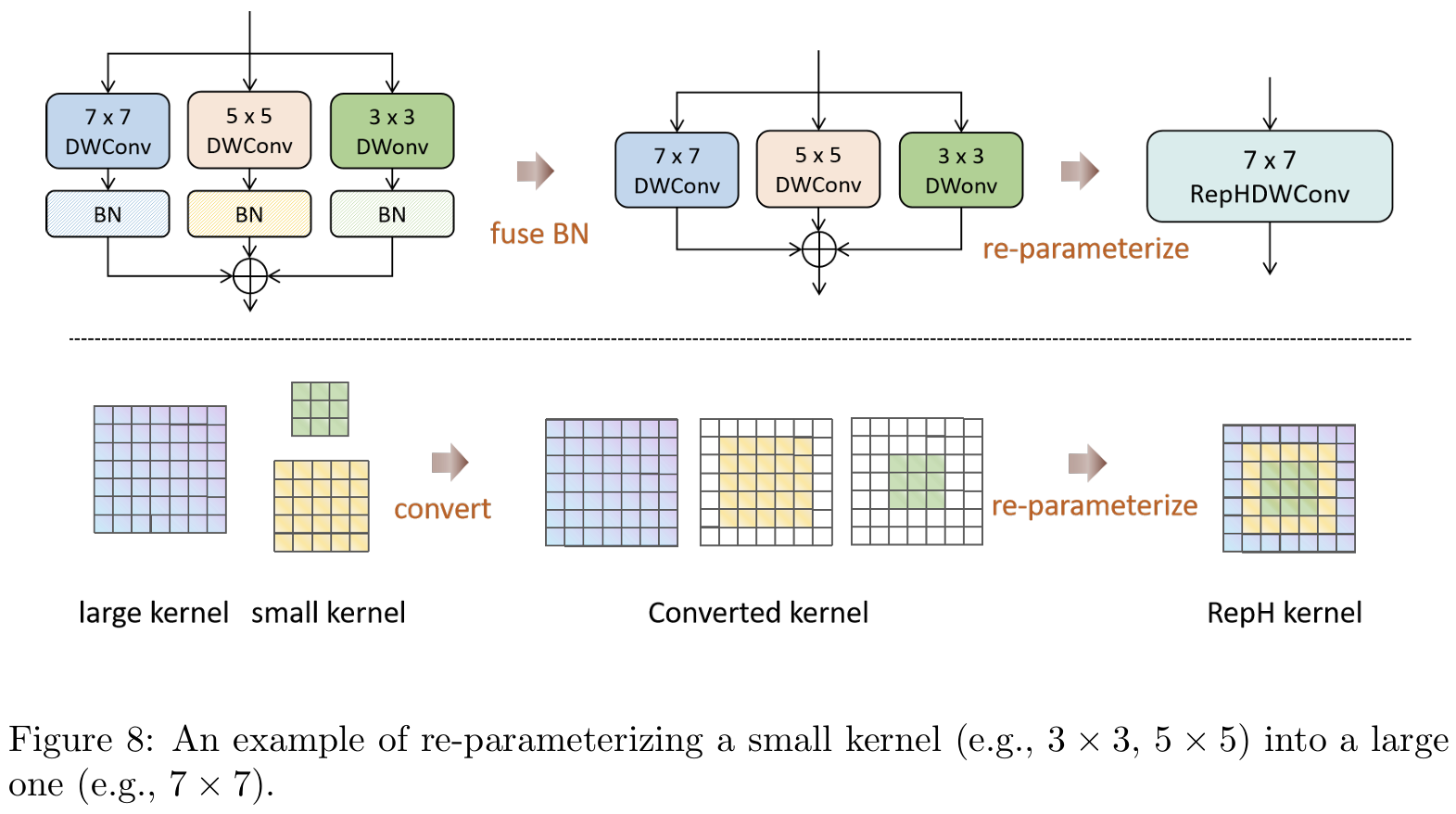
重参数化7×77\times77×7 RepHDWConv的步骤如图8所示。让μ\muμ、σ\sigmaσ、γ\gammaγ、β\betaβ作为BN层的累积均值、标准差和学习缩放因子及偏置。RepHDW(x)(x)(x)表示RepHDWConv参数。I表示输入特征图,KnK_{n}Kn和BnB_{n}Bn显示n×nn\times nn×n核的卷积权重和偏置。
首先,在RepHDWConv中并行一个k1×k⊥k_{1}\times k_{\perp}k1×k⊥大DWConv和许多k2×k2k_{2}\times k_{2}k2×k2小DWConv,每个DWConv后跟一个批量归一化(bn)层。然后,每个卷积核的参数将与其对应的bn层的参数合并。
BN(RepHDW(x))=γ⋅(RepHDW(x)−μ)σ2+ϵ+βBN(RepHDW(x))=\frac{\gamma\cdot(RepHDW(x)-\mu)}{\sqrt{\sigma^{2}+\epsilon}}+\betaBN(RepHDW(x))=σ2+ϵ γ⋅(RepHDW(x)−μ)+β
让WfusedW_{fused}Wfused和BfusedB_{fused}Bfused表示BN融合后卷积操作的参数和偏置。提取融合参数WfusedW_{fused}Wfused和BfusedB_{fused}Bfused得到:
Wfused=γ⋅RepHDWσ2+ϵ,Bfused=γ⋅(−μ)σ2+ϵ+βW_{fused}=\frac{\gamma\cdot RepHDW}{\sqrt{\sigma^{2}+\epsilon}},B_{fused}=\frac{\gamma\cdot(-\mu)}{\sqrt{\sigma^{2}+\epsilon}}+\betaWfused=σ2+ϵ γ⋅RepHDW,Bfused=σ2+ϵ γ⋅(−μ)+β
然后,融合bn层后的Conv可以表示为:
BN(RepHDW(x))=Wfused(x)+BfusedBN(RepHDW(x))=W_{fused}(x)+B_{fused}BN(RepHDW(x))=Wfused(x)+Bfused
在第二步中,通过填充将许多小DWConv等同于一个大DWConv,然后进行重参数化。这些异构DWConv的参数和偏置通过累积构造,得到一个新的RepHDWConv,输出特征图O为:
O=I⊗(K2n−1+∑i=1mK2n−(2i+1))+(B2n−1+∑i=1mB2n−(2i+1))\begin{array}{r}{O=I\otimes\left(K_{2n-1}+\displaystyle\sum_{i=1}^{m}K_{2n-(2i+1)}\right)}\\ {+\left(B_{2n-1}+\displaystyle\sum_{i=1}^{m}B_{2n-(2i+1)}\right)}\end{array}O=I⊗(K2n−1+i=1∑mK2n−(2i+1))+(B2n−1+i=1∑mB2n−(2i+1))
其中n≥3n\geq3n≥3,m是满足2n−(2m+1)≥32n-(2m+1)\geq32n−(2m+1)≥3的最大整数。
4. 实验
4.1. 实验设置
数据集 。为了验证所提方法的有效性,我们在三个权威公共基准数据集上进行了实验,涉及三个不同任务:目标检测、实例分割和旋转目标检测。使用的数据集如下:
· MS COCO 30。COCO数据集由微软于2014年发布,旨在提供一个大型且具有挑战性的多任务图像数据集。我们在该数据集上评估目标检测任务,使用train2017集进行训练,包含118,287张图像,val2017集进行验证,包含5,000张图像。此外,我们还在COCO数据集上执行实例分割,以评估我们模型的多任务能力。
· Pascal VOC 31。我们遵循大多数主流VOC数据集配置,包含20个类别,使用train2012、val2012、train2007和val2007数据集进行模型训练,共16,551张图像。test2007集包含4,952张图像,用于验证和测试。
· DOTA-v1.0 32。DOTA-v1.0是一个专门为遥感图像中旋转目标检测设计的数据集,包含2,806张图像和15个类别中的188,282个实例。我们采用默认配置,使用1,411张图像作为训练集,458张图像作为验证集,937张图像作为测试集。
4.2. 实现细节
目标检测和实例分割。我们的实现基于YOLOv10框架。对于目标检测任务,所有实验在4块NVIDIA GeForce RTX 2080Ti GPU上进行,MHAF-YOLO的所有规模都从头开始训练500个周期,不依赖其他大规模数据集,如ImageNet 33,或预训练权重。我们主要遵循YOLOv10设置,使用SGD优化器进行训练,并将原始的mixup数据增强策略替换为RTMDet 11中更先进的cached-mixup策略,同时使用较低概率的copy-paste 34方法。最后10个周期关闭这些强数据增强策略。对于实例分割任务,我们遵循YOLOv8、RTMDet和YOLO11的配置,只将MHAF-YOLO的目标检测头修改为实例分割头以适应此任务。我们还使用与目标检测任务相同的超参数配置和训练周期,从头开始训练模型。
旋转目标检测。首先,我们将MHAF-YOLO的目标检测头替换为YOLO11的旋转目标检测头,并将IOU替换为旋转IOU以实现此任务。我们统一训练过程为200个周期,并可选择应用多尺度离线数据增强、旋转增强和垂直翻转。此外,为了与其他旋转目标检测任务进行基准测试,我们在ImageNet数据集上训练了MHAF-YOLO的骨干网络300个周期,这也可以作为进一步微调的基础。对于单尺度训练和测试,原始图像被裁剪为1024×1024的补丁。在多尺度训练和测试的情况下,原始图像以0.5、1.0和1.5的比例调整大小,然后裁剪为1024×1024的补丁。每个补丁有500像素的重叠。对于评估指标,我们使用与PASCAL VOC2007 31中相同的mAP计算方法,不同之处在于我们使用旋转IoU来确定匹配的对象。
4.3. RepHMS分析
在本小节中,我们将对RepHMS模块进行一系列消融研究。默认情况下,我们在所有实验中使用MHAF-YOLO nano。
4.3.1. 探索RepHMS的灵活性
我们首先在表1中对RepHMS模块与其他先进YOLO模型的各种计算块进行消融实验。所有模块都在网络的骨干和颈部使用。为了确保实验的公平性,我们设置了相似的深度和宽度系数,使每个改进模型的参数数量尽可能接近。RepHMS模块与其他模块相比,通过利用重参数化DWConv和多尺度感受野,具有卓越的参数效率,在参数数量和精度之间实现了最佳平衡。
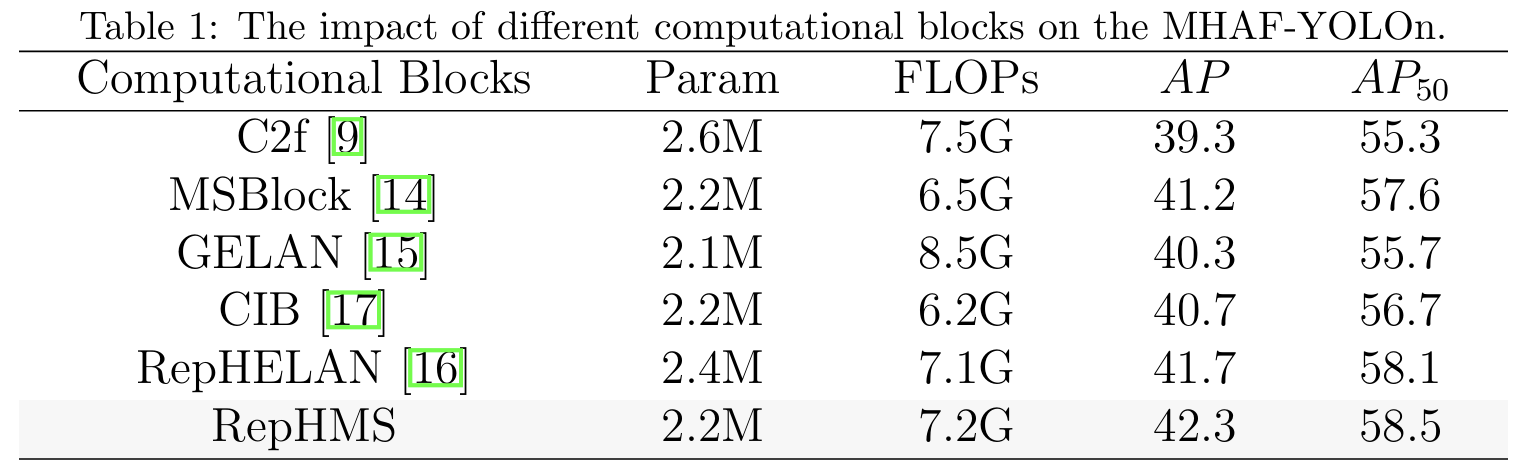
4.3.2. RepHMS的消融研究
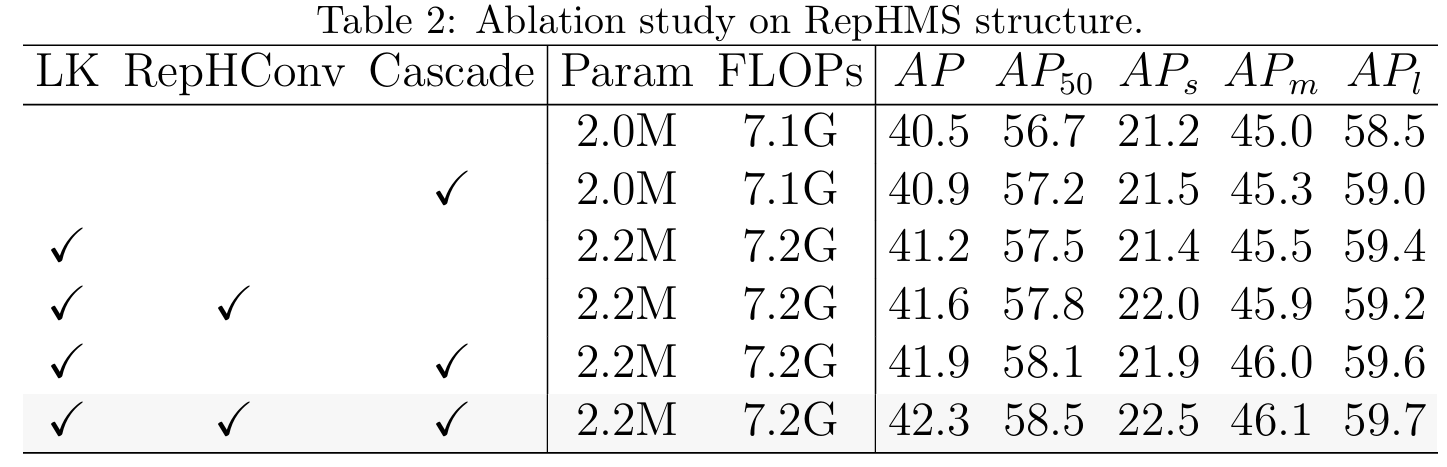
如表2所示,我们对RepHMS模块进行了消融研究,RepHMS中的每个瓶颈默认包含一个5×55\times55×5 DWConv。当采用大核(LK)策略时,模型根据GHFKS策略在骨干和颈部使用最大9×99\times99×9的卷积核。当应用额外的RepHConv策略时,每个大卷积核通过重参数化技术与多个小核并行组合。根据表2的第一行和第三行,使用大卷积核使性能提高了0.7%,其中大物体的增益最显著,达到0.8%,而小物体的改进较小。当用RepHConv替换大DWConv时,模型的参数和计算成本保持不变,但整体性能提高了0.4%,小目标检测有明显增强。可以总结如下:使用大卷积核有效增加了感受野,带来性能增益。当与RepHConv策略结合时,模型可以优化不同尺度物体的性能。此外,级联策略也是实现无损性能提升的好方法。
4.4. MAFPN分析
在本小节中,我们对MAFPN的每个模块进行了消融实验,并通过在各种实验中用不同算法替换颈部结构,展示了MAFPN的即插即用能力。
4.4.1. MAFPN的消融研究
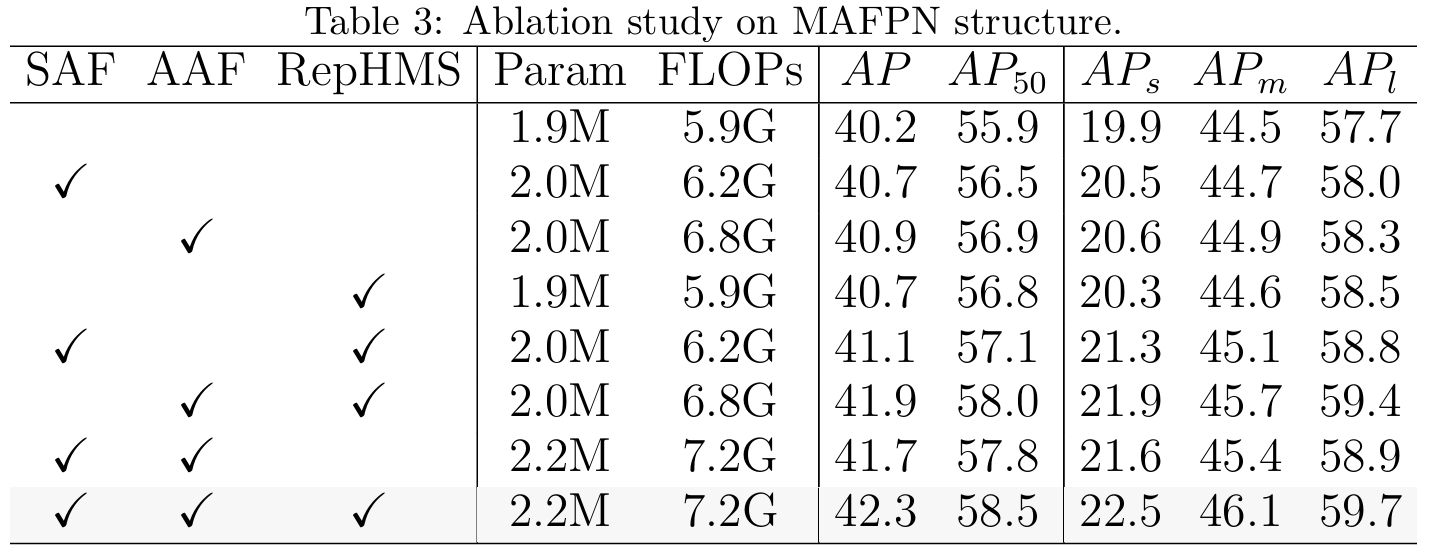
本实验结果如表3所示,默认模型颈部设置为PAFPN,包含四个C2f块。首先,我们在骨干和颈部的浅层中整合了SAF模块,这导致性能提升了0.5%,参数增加了0.1M,值得注意的是,通过SAF,我们在小目标上实现了0.6%的性能改进。其次,仅添加AAF模块,我们观察到所有尺度物体性能的具体增强。接下来,我们在MAFPN中用RepHMS替换了C2f。模型的参数数量和计算成本基本保持不变,而整体性能提高了0.5%,证明了RepHMS在颈部中的强有效性。最终,在将所有三种策略集成到MAFPN后,模型的整体性能提高了2.1%,小物体检测提高了2.4%,证明MAFPN有效解决了传统PAFPN在小物体上表现不佳的问题。此外,得益于多样化的感受野,在中等和大物体检测方面也观察到了显著改进。
4.4.2. 探索MAFPN的灵活性
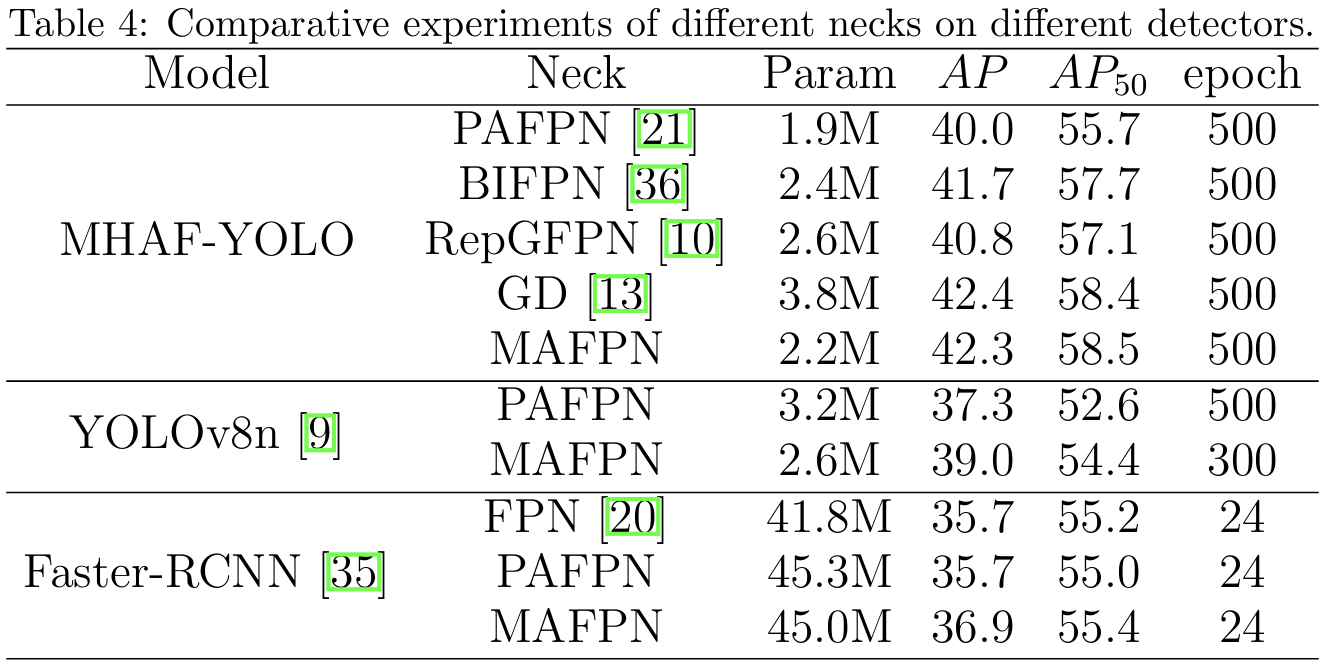
MAFPN可以作为即插即用模块用于其他模型,结果如表4所示。首先,我们在MHAF-YOLO中实验了不同的FPN结构,最终发现只有MAFPN能够实现模型参数和性能之间的更好平衡。然后,我们通过在主流单阶段检测器YOLOv8n中用MAFPN替换PAFPN,并改变通道数量以保持模型更小,来展示这种结构的通用性。YOLOv8n-MAFPN使用较少的周期(-200周期)和较少的参数,获得了1.7%的AP提升,反映了MAFPN的卓越性能。此外,我们还使用两阶段检测器Faster-RCNN 35验证了MAFPN的有效性。通过在Faster R-CNN中用MAFPN替换FPN,我们仅以最小的参数数量增加就实现了1.2%的AP增长。相比之下,用PAFPN替换FPN没有带来显著增益,突出表明MAFPN即使在经典的两阶段检测器中也能保持强劲性能。
4.5. MHAF-YOLO的消融研究
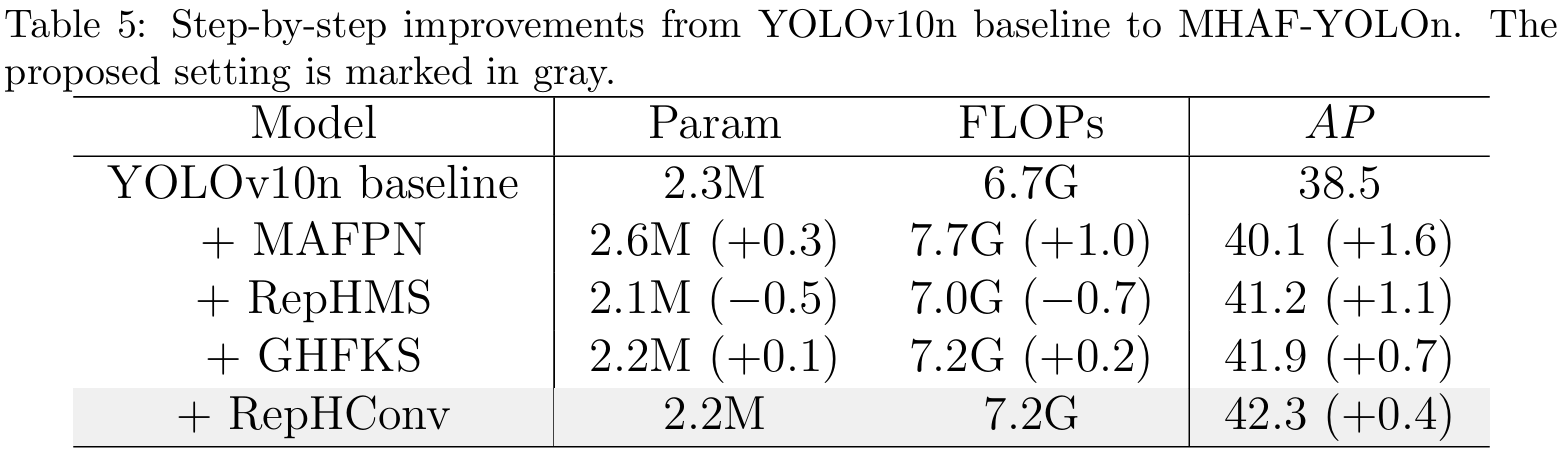
如表5所示,我们对基线模型YOLOv10n进行了一系列修改。首先,我们将MAFPN作为颈部结构。增强的特征融合使性能提高了1.6%。然而,由于添加了额外模块和连接,参数数量和计算成本分别增加了0.3M和1.0G。接下来,我们引入了RepHMS模块。由于其高效的深度卷积,我们的模型实现了高参数利用率,性能提升了1.1%,同时参数数量实际上减少了0.5M。添加GHFKS后,性能提高了0.7%,参数数量仅略有增加。在这一阶段,网络只包含大核卷积。最后,通过集成RepHConv,由于重参数化,模型大小保持不变,但它丰富了MHAF-YOLO模型的多尺度表示。最终,这使性能达到了42.3%。
4.6. 不同数据集上不同任务的检测器
4.6.1. COCO上实时检测器的比较
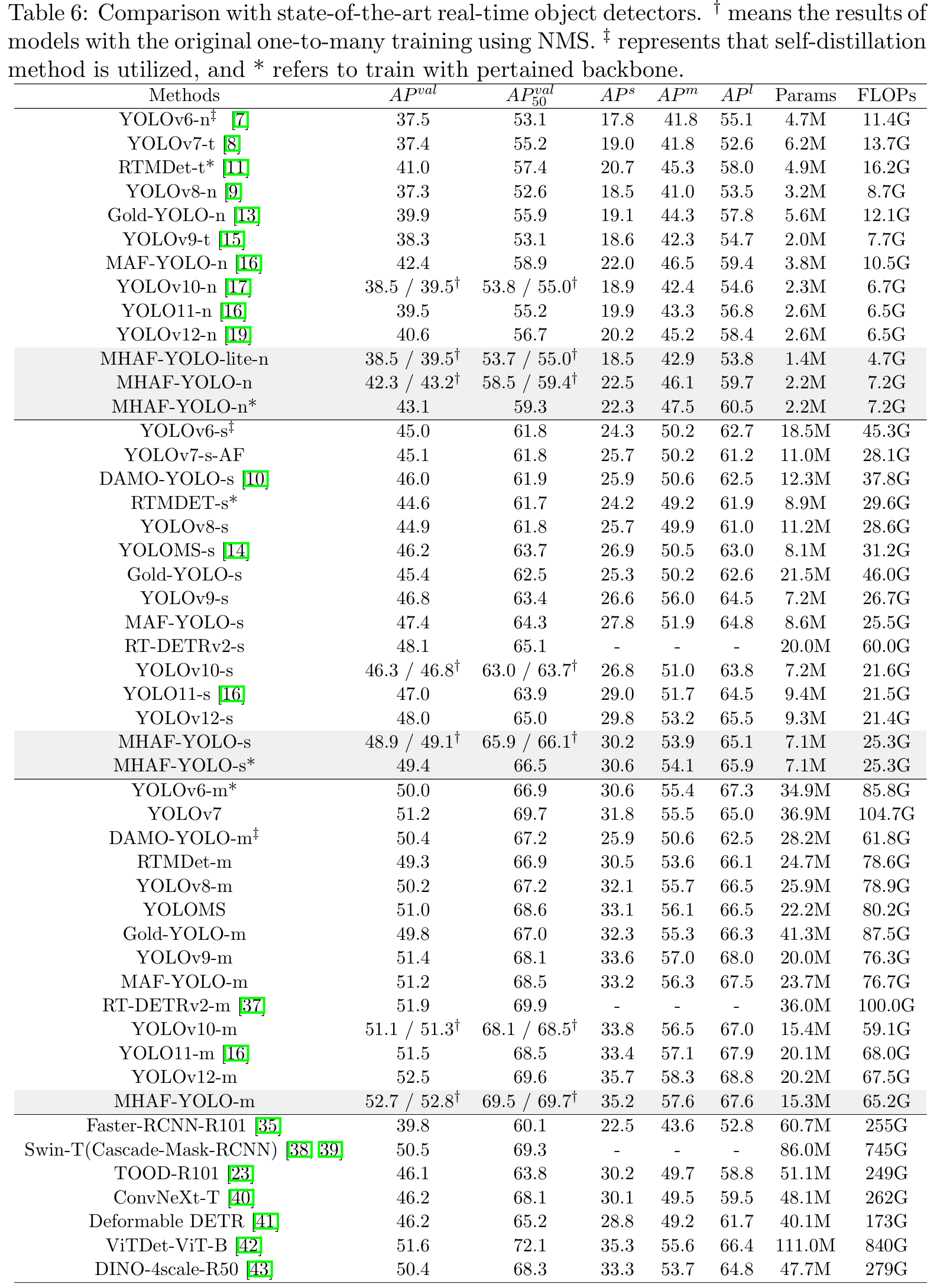
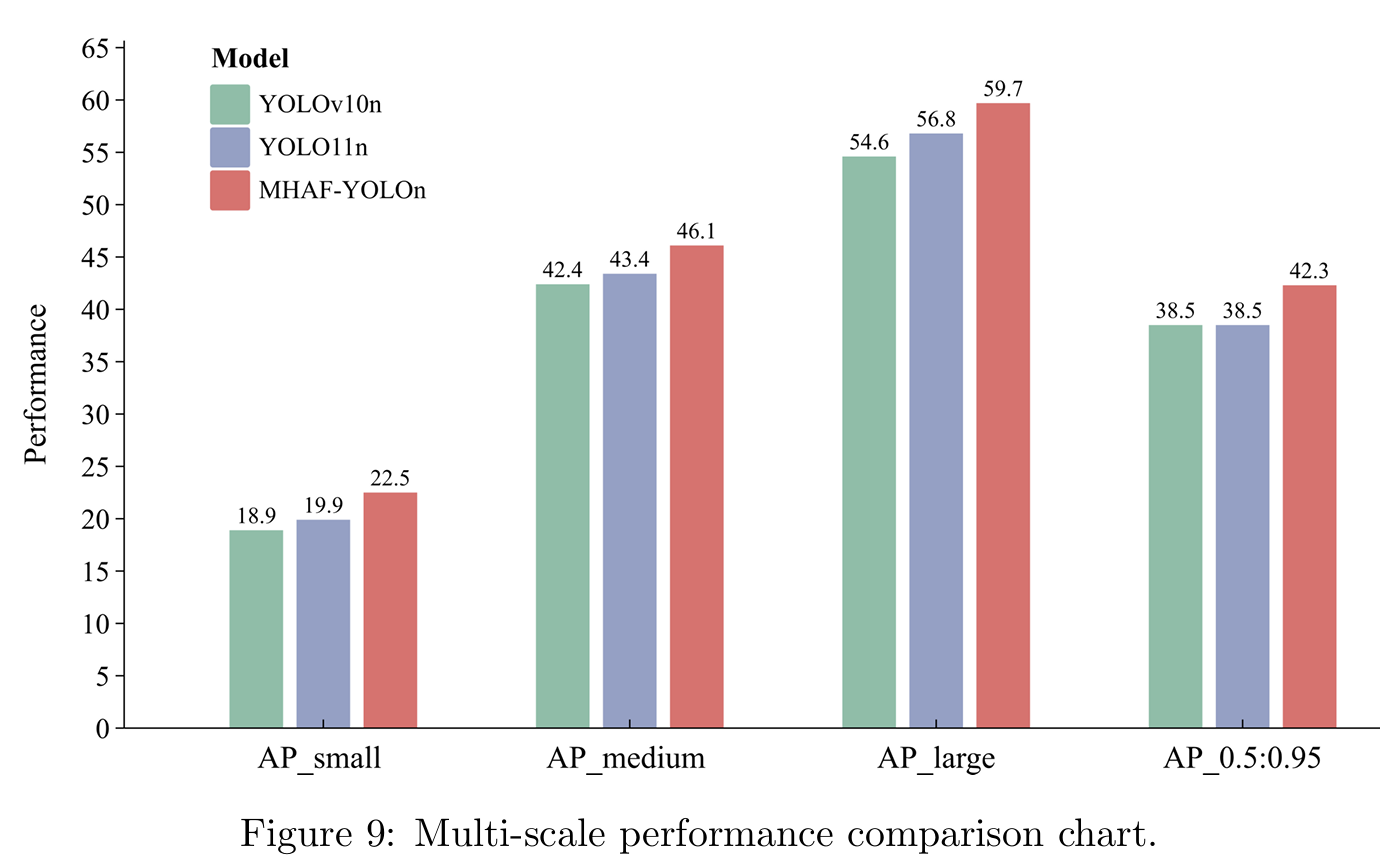
表6显示了我们提出的MHAF-YOLO与其他最先进实时目标检测器的比较结果。我们首先将MHAF-YOLO与我们的基线模型YOLOv10进行比较。在N/S/M三种变体上,我们的模型实现了3.8%/2.6%/1.6%的AP提升,参数更少。与其他YOLO相比,MHAF-YOLO也表现出精度和计算成本之间的优越权衡。例如,与Gold-YOLO相比,MHAF-YOLO在参数利用效率方面表现出非凡的效率,MHAF-YOLO N/S/M的参数数量比Gold-YOLO少60%/67%/63%,但仍实现了2.4%/3.5%/2.9%的性能增益。我们的模型对于更小规模的模型也有显著优势,与YOLOv6-n、YOLOv7-t、YOLOv8-n、YOLOv9-t、YOLOv10-n相比,MHAF-YOLO-lite-nano模型通过将参数减少30%至77%,计算需求减少30%至66%,同时保持相当的平均精度(AP)分数,展示了显著的轻量级潜力。与最新的YOLO11相比,我们的三种规模模型参数更少,但分别超过YOLO11-n、YOLO11-s和YOLO11-m 2.8%、1.9%和1.2%。这强调了我们的模型在以最小资源消耗实现高性能方面的卓越性,使其非常适合效率和紧凑性至关重要的应用。此外,我们展示了几种两阶段和基于变换器的检测器,其中我们的模型表现出卓越性能且更轻量级。此外,得益于MAFPN和多尺度感受野模块,我们的模型在检测多尺度物体方面显著优于其他模型。如图9所示,我们以条形图展示了三种不同尺度目标的检测性能,其中MHAF-YOLO在所有指标上始终优于YOLOv10和YOLO11。图10展示了COCO验证集上不同算法的一些检测结果。

4.6.2. VOC上实时检测器的比较
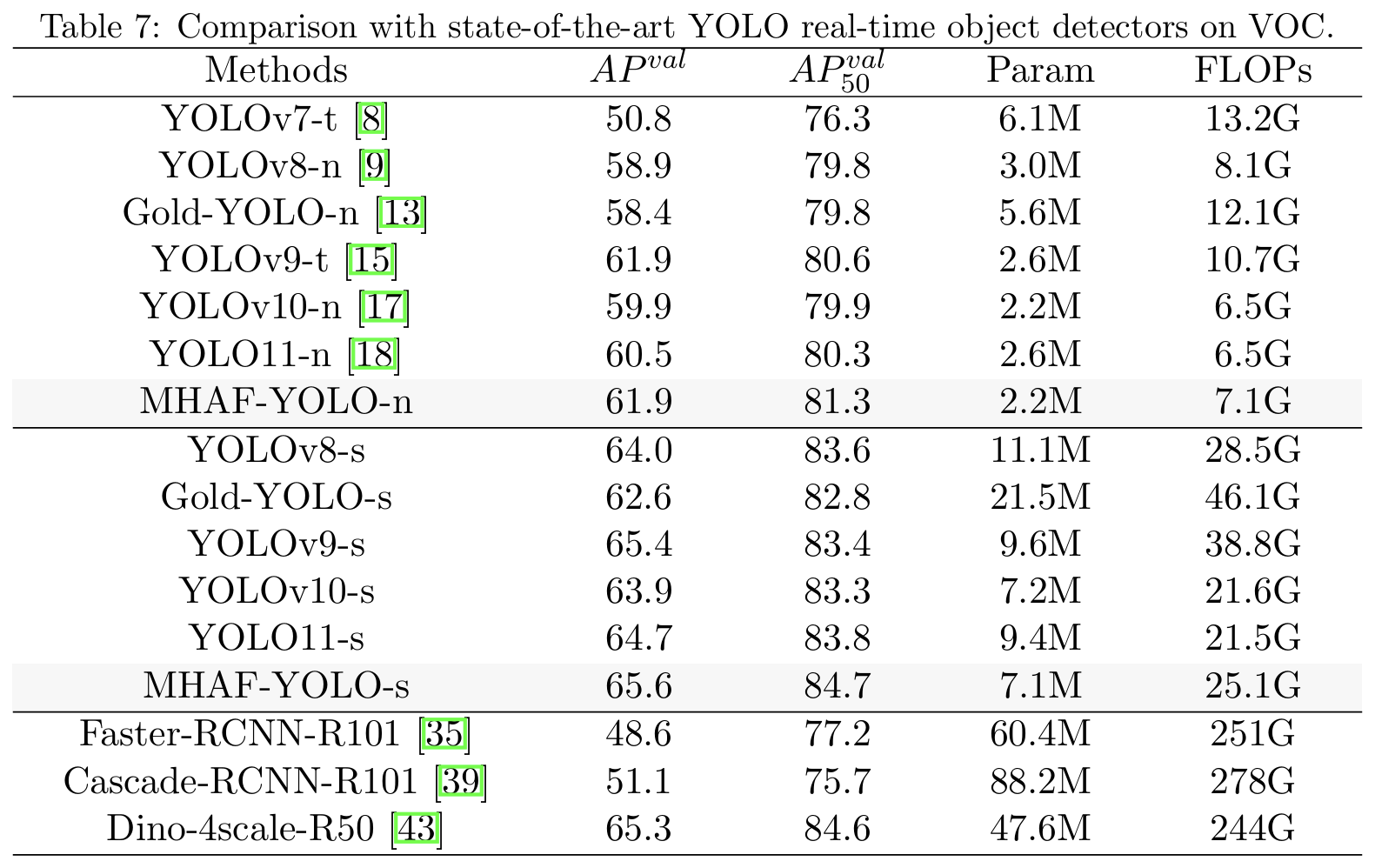
我们在VOC数据集上训练主流YOLO系列模型300个周期,并在表7中报告系统级比较,显示我们的模型比基线YOLOv10n和YOLOv10s分别高出2%和1.7% AP。与表现最好的YOLOv9相比,MHAF-YOLO在AP50AP_{50}AP50指标上仍显示出显著优势。MHAF-YOLO n/s也比YOLO11 n/s高出1.4%和0.9%,展示了我们的模型在VOC数据集上的卓越泛化能力。
4.6.3. 语义分割结果
除了目标检测任务,我们还在COCO数据集上对实例分割任务进行了性能评估。如表8所示,我们的nano/small模型在分割AP方面分别超过YOLO11 n/s 3.6%和2.2%,同时具有更少的参数和更低的计算成本。这表明MHAF-YOLO在实例分割任务中也显示出有希望的潜力。
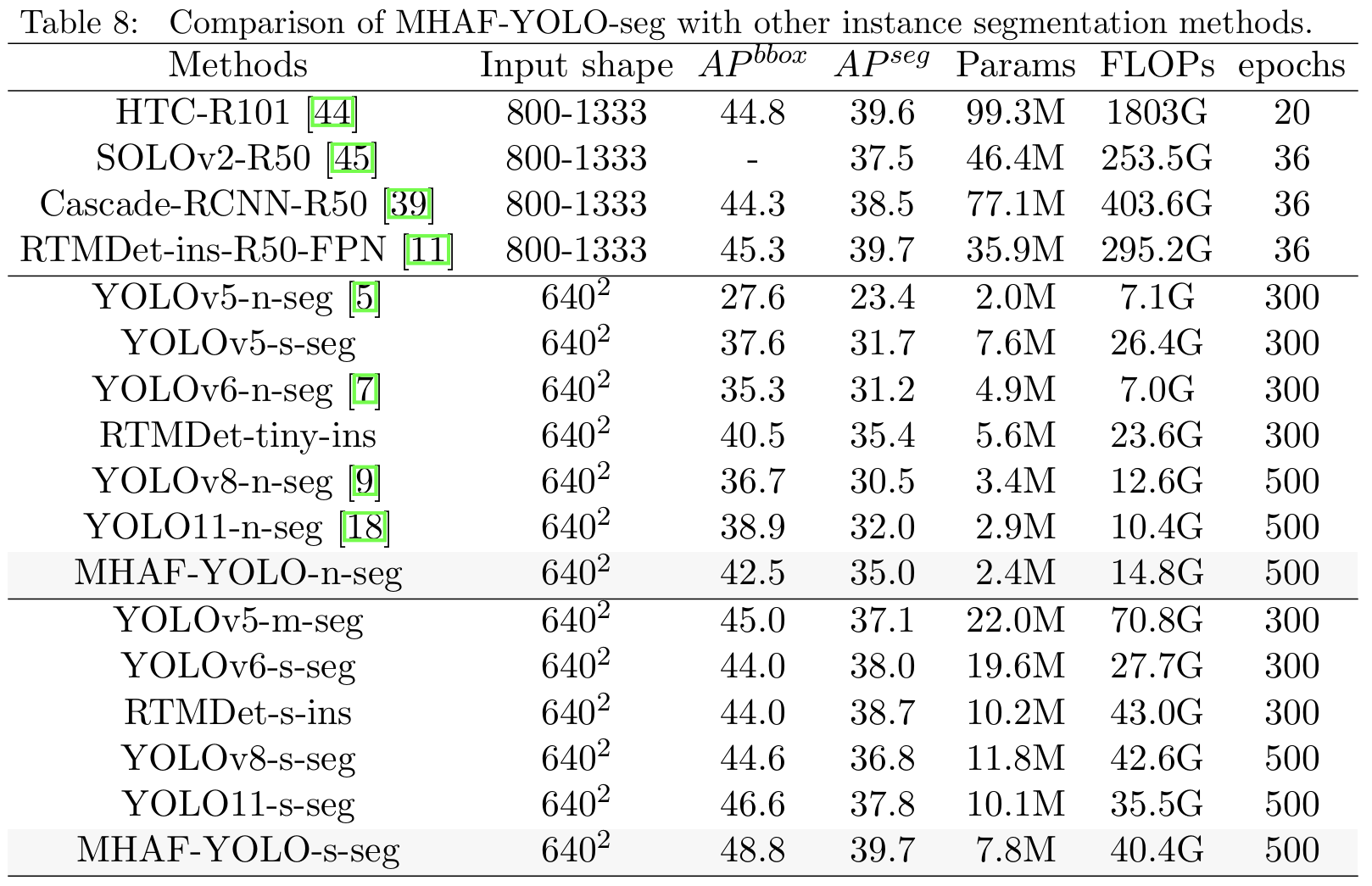
4.6.4. 旋转目标检测结果
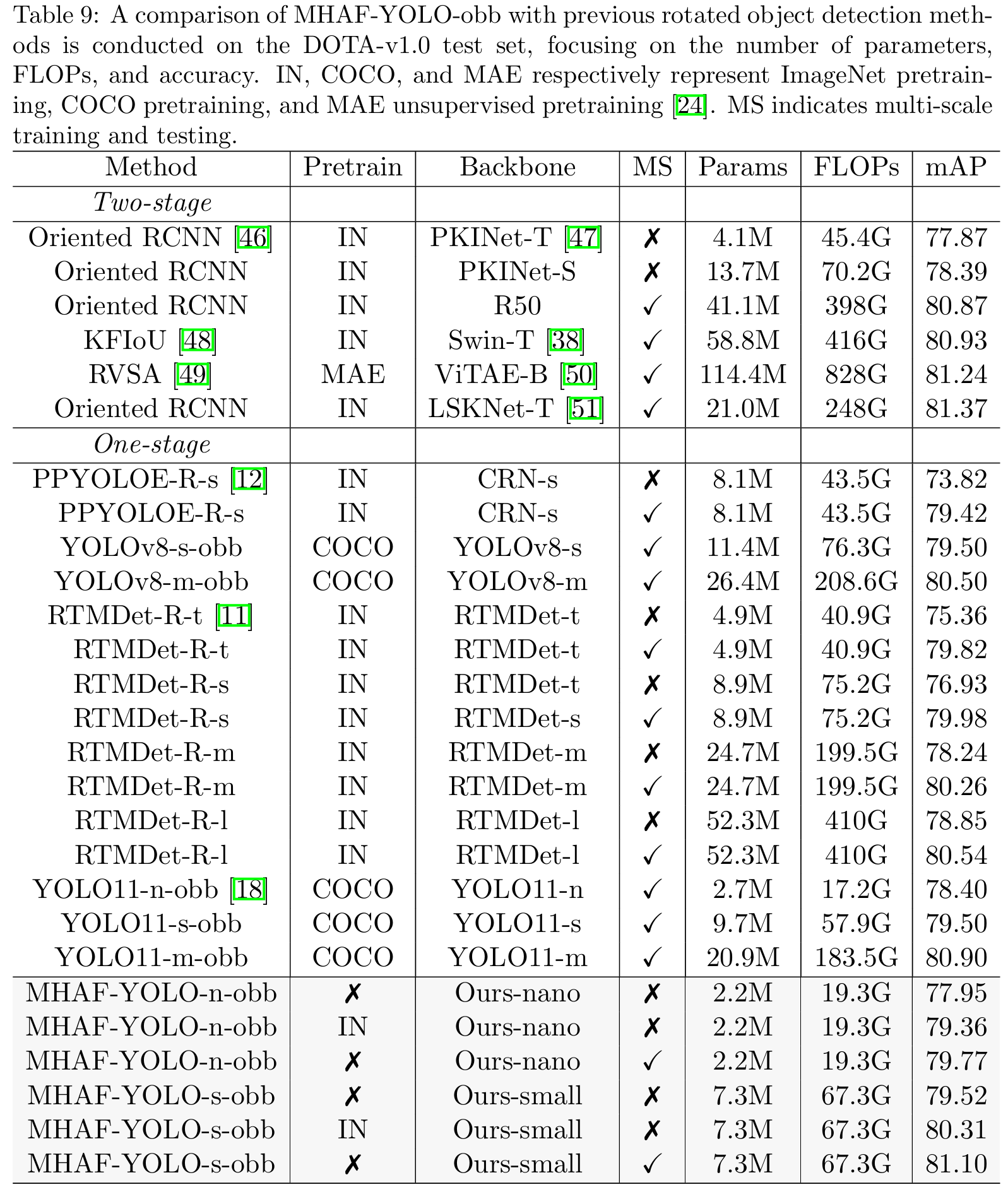
在表9中,我们将MHAF-YOLO-obb与DOTA-v1.0数据集上先前的最先进方法进行了比较。在单尺度训练和推理中,模型面临更复杂的小物体检测问题。MHAF-YOLO-n-obb和MHAF-YOLO-s-obb分别实现了79.36%和80.31%的mAP,优于几乎所有先前的单尺度方法。具体来说,我们的nano在参数和计算成本仅为RTMDet-R-l模型约1/20的情况下,性能提高了0.51%,最终达到79.36% AP。在没有ImageNet预训练的情况下,我们的小型模型也达到了79.52%的AP,超过了具有最先进骨干PKINet-S 47的O-RCNN 46方法1.13%,同时将参数数量减少了46.7%。在多尺度训练和测试中,YOLOv8和YOLO11采用COCO预训练策略,显著提升了性能。在相同的训练策略下,我们的MHAF-YOLO-n-obb在没有预训练的情况下,仍然分别超过YOLO11-n-obb和YOLO11-s-obb 1.37%和0.27%。我们的MHAF-YOLO-s-obb在多尺度设置中实现了81.10%的AP,几乎匹配最先进的旋转目标检测方法。例如,RVSA 49需要一个极大的模型和在大规模数据集上的预训练才能勉强超过81 AP。与最先进的方法LSKNet-T 51相比,我们的模型在参数数量和计算成本方面都显示出明显优势。我们相信,通过更强的预训练和旋转目标检测的进一步优化,我们的模型在未来可以实现更先进的性能。
5. 结论
在本文中,我们回顾了YOLO网络中常用的PAFPN架构,并批判性地分析了其在特征融合方面的局限性。在此基础上,我们提出了一种强大且高效的多尺度特征融合网络MAFPN,它既高效又多功能。它可以无缝集成到任何目标检测器中以增强性能。MAFPN在其浅层和深层分别集成了两个专门模块SAF和AAF。SAF模块战略性地集成了来自浅层骨干网络的更多信息,显著提高了定位精度和小物体检测能力。AAF模块采用更丰富的连接机制,使颈部内多尺度特征信息广泛交互。随着网络进行迭代更新,这些特征相互补充和精炼,最终在输出层产生更多信息丰富的梯度。我们还从全局和局部角度研究了多尺度感受野的重要性。在全局上,我们引入了GHFKS机制,它根据目标层维度自适应调整卷积核大小,逐步扩展网络的整体感受野。在局部上,我们设计了重参数化异构卷积,以减轻过大核导致的小物体信息丢失。基于上述创新,我们开发了MHAF-YOLO模型,它实现了卓越的参数效率和最先进性能。与类似模型相比,我们的方法在三个基准数据集COCO、VOC和DOTA-v1.0上表现出卓越性能,在目标检测、实例分割和旋转目标检测任务中实现了最先进结果。我们希望这项工作能为构建更高精度的实时目标检测器提供新见解。
尽管MHAF-YOLO在相当的计算成本下实现了高精度,但其推理速度仍落后于YOLOv10和YOLO11等尖端模型。这主要是由于MAFPN的相对复杂性和大核深度卷积的低效率。在未来的工作中,我们旨在保持高精度的同时优化模型的推理速度,以更好地满足工业应用的需求。
声明
利益冲突/竞争利益(查看期刊特定指南以了解应使用的标题):作者声明不存在与提交出版的作品直接或间接相关的竞争利益。
伦理批准和参与同意:不适用。
出版同意:不适用。
数据可用性:本研究中使用的数据集是公开可用的,包括:COCO 30、VOC 31和DOTA-v1.0 32。
材料可用性:不适用。
· 代码可用性:源代码可在https://github.com/yang-0201/MHAF-YOLO获取
参考文献
1 J. Redmon, You only look once: Unified, real-time object detection, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
2 J. Redmon, A. Farhadi, Yolo9000: better, faster, stronger, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7263-7271.
3 J. Redmon, Yolov3: An incremental improvement, arXiv preprint arXiv:1804.02767 (2018).
4 A. Bochkovskiy, C.-Y. Wang, H.-Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, arXiv preprint arXiv:2004.10934 (2020).
5 G. Jocher, A. Chaurasia, A. Stoken, et al, ultralytics/yolov5: v7.0-yolov5 sota realtime instance segmentation, Zenodo (2022).
6 Z. Ge, S. Liu, F. Wang, Z. Li, J. Sun, Yolox: Exceeding yolo series in 2021, arXiv preprint arXiv:2107.08430 (2021).
7 C. Li, L. Li, Y. Geng, et al, Yolov6 v3.0: A full-scale reloading, arXiv preprint arXiv:2301.05586 (2023).
8 C.-Y. Wang, A. Bochkovskiy, H.-Y. M. Liao, Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7464-7475.
9 G. Jocher, A. Chaurasia, J. Qiu, Yolo by ultralytics, URL: https://github.com/ultralytics/ultralytics/tree/v8.2.0 (2023).
10 X. Xu, Y. Jiang, W. Chen, et al, Damo-yolo: A report on real-time object detection design, arXiv preprint arXiv:2211.15444 (2022)
11 C. Lyu, W. Zhang, H. Huang, et al, Rtmdet: An empirical study of designing real-time object detectors, arXiv preprint arXiv:2212.07784
12 S. Xu, X. Wang, W. Lv, Q. Chang, C. Cui, K. Deng, G. Wang, Q. Dang, S. Wei, Y. Du, et al., Pp-yoloe: An evolved version of yolo, arXiv preprint arXiv:2203.16250 (2022).
13 C. Wang, W. He, Y. Nie, et al, Gold-yolo: Efficient object detector via gather-and-distribute mechanism, arXiv preprint arXiv:2309.11331 (2023)
14 Y. Chen, X. Yuan, R. Wu, et al, Yolo-ms: Rethinking multi-scale representation learning for real-time object detection, arXiv preprint arXiv:2308.05480 (2023).
15 C.-Y. Wang, I.-H. Yeh, H.-Y. M. Liao, Yolov9: Learning what you want to learn using programmable gradient information, arXiv preprint arXiv:2402.13616 (2024)
16 Z. Yang, Q. Guan, K. Zhao, J. Yang, X. Xu, H. Long, Y. Tang, Multi-branch auxiliary fusion yolo with re-parameterization heterogeneous convolutional for accurate object detection, arXiv preprint arXiv:2407.04381 (2024).
17 A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, G. Ding, Yolov10: Real-time end-to-end object detection, arXiv preprint arXiv:2405.14458 (2024)
18 G. Jocher, A. Chaurasia, J. Qiu, Yolo by ultralytics, URL: https://github.com/ultralytics/ultralytics (2024)
19 Y. Tian, Q. Ye, D. Doermann, Yolov12: Attention-centric real-time object detectors, arXiv preprint arXiv:2502.12524 (2025).
20 T.-Y. Lin, P. Dollár, R. Girshick, et al, Feature pyramid networks for object detection, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117-2125.
21 K. Wang, J. H. Liew, Y. Zou, D. Zhou, J. Feng, Panet: Few-shot image semantic segmentation with prototype alignment, in: proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9197-9206.
22 C.-Y. Wang, H.-Y. M. Liao, Y.-H. Wu, P.-Y. Chen, J.-W. Hsieh, I.-H. Yeh, CSPNet: A new backbone that can enhance learning capability of cnn, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 390-391.
23 C. Feng, Y. Zhong, Y. Gao, M.R. Scott, W. Huang, Tood: Task-aligned one-stage object detection, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE Computer Society, 2021, pp. 3490-3499.
24 Z. Sun, M. Lin, X. Sun, Z. Tan, H. Li, R. Jin, Mae-det: Revisiting maximum entropy principle in zero-shot nas for efficient object detection, arXiv preprint arXiv:2111.13336 (2021).
25 G. Yang, J. Lei, Z. Zhu, S. Cheng, Z. Feng, R. Liang, Afpn: Asymptotic feature pyramid network for object detection, in: 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE, 2023, pp. 2184-2189.
26 Y. Li, Y. Chen, N. Wang, Z. Zhang, Scale-aware trident networks for object detection, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6054-6063.
27 X. Ding, X. Zhang, N. Ma, et al, Repvgg: Making vgg-style convnets great again, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13733-13742.
28 X. Ding, X. Zhang, J. Han, G. Ding, Scaling up your kernels to 31x31: Revisiting large kernel design in cnns, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11963-11975.
29 X. Ding, Y. Zhang, Y. Ge, S. Zhao, L. Song, X. Yue, Y. Shan, Unireplknet: A universal perception large-kernel convnet for audio video point cloud time-series and image recognition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5513-5524.
30 T.-Y. Lin, M. Maire, S. Belongie, et al, Microsoft coco: Common objects in context, in: Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, Springer, 2014, pp. 740-755.
31 M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, A. Zisserman, The pascal visual object classes challenge: A retrospective, International journal of computer vision 111 (2015) 98-136.
32 G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, L. Zhang, Dota: A large-scale dataset for object detection in aerial images, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3974-3983.
33 J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, Imagenet: A large-scale hierarchical image database, in: 2009 IEEE conference on computer vision and pattern recognition, Ieee, 2009, pp. 248-255.
34 G. Ghiasi, Y. Cui, A. Srinivas, R. Qian, T.-Y. Lin, E. D. Cubuk, Q.V. Le, B. Zoph, Simple copy-paste is a strong data augmentation method for instance segmentation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 2918-2928.
35 S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, IEEE transactions on pattern analysis and machine intelligence 39 (6) (2016) 1137-1149.
36 M. Tan, R. Pang, Q. V. Le, Efficientdet: Scalable and efficient object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10781-10790.
37 W. Lv, Y. Zhao, Q. Chang, K. Huang, G. Wang, Y. Liu, Rt-detr v2: Improved baseline with bag-of-freebies for real-time detection transformer, arXiv preprint arXiv:2407.17140 (2024).
38 Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012-10022.
39 Z. Cai, N. Vasconcelos, Cascade r-cnn: High quality object detection and instance segmentation, IEEE transactions on pattern analysis and machine intelligence 43(5) (2019) 1483-1498.
40 Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, S. Xie, A convnet for the 2020s, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11976-11986.
41 X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable detr: Deformable transformers for end-to-end object detection, arXiv preprint arXiv:2010.04159 (2020).
42 Y. Li, H. Mao, R. Girshick, K. He, Exploring plain vision transformer backbones for object detection, in: European conference on computer vision, Springer, 2022, pp. 280-296.
43 H. Zhang, F. Li, S. Liu, et al, Dino: Detr with improved denoising anchor boxes for end-to-end object detection, arXiv preprint arXiv:2203.03605 (2022).
44 K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, et al., Hybrid task cascade for instance segmentation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4974-4983.
45 X. Wang, R. Zhang, T. Kong, L. Li, C. Shen, Solov2: Dynamic and fast instance segmentation, Advances in Neural information processing systems 33 (2020) 17721-17732.
46 X. Xie, G. Cheng, J. Wang, X. Yao, J. Han, Oriented r-cnn for object detection, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3520-3529.
47 X. Cai, Q. Lai, Y. Wang, W. Wang, Z. Sun, Y. Yao, Poly kernel inception network for remote sensing detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27706-27716.
48 X. Yang, Y. Zhou, G. Zhang, J. Yang, W. Wang, J. Yan, X. Zhang, Q. Tian, The kfiou loss for rotated object detection, arXiv preprint arXiv:2201.12558 (2022).
49 D. Wang, Q. Zhang, Y. Xu, J. Zhang, B. Du, D. Tao, L. Zhang, Advancing plain vision transformer toward remote sensing foundation model, IEEE Transactions on Geoscience and Remote Sensing 61 (2022) 1-15.
50 Q. Zhang, Y. Xu, J. Zhang, D. Tao, Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond, International Journal of Computer Vision 131 (5) (2023) 1141-1162.
51 Y. Li, X. Li, Y. Dai, Q. Hou, L. Liu, Y. Liu, M.-M. Cheng, J. Yang, Lsknet: A foundation lightweight backbone for remote sensing, International Journal of Computer Vision (2024) 1-22.