要开始一个 Flink 作业,通常需要如下依赖项:
1. Flink API,用来开发你的作业
2. 连接器和格式,以将你的作业与外部系统集成 比如kakfa,hbase模块
3. 若要开发自定义功能,还要添加必要的第三方依赖项比如fastjson等
其中1所需要的依赖已经在安装包lib文件夹下的flink-dist_xx.jar中,在IDEA等中编译程序时需要将相关依赖置为 provied。2、3则需要将应用程序代码及其所有需要的依赖项打包到一个 jar-with-dependencies 的 jar 包中。
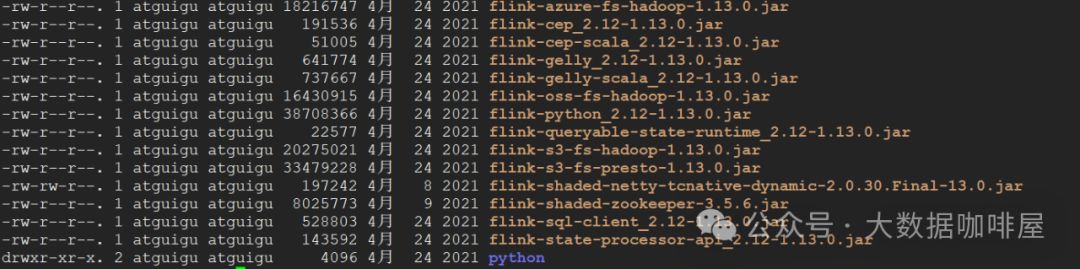
关于 flink-dist_xx.jar
flink-dist_xx.jar(下图黄色框)是 Flink 自身运行时所需的一组核心类和依赖,涵盖以下内容:
-
• 协调和网络通讯
-
• Checkpoint 和容错处理
-
• API 和算子(如窗口操作)
-
• 资源管理等
这些类和依赖构成了 Flink 运行时的核心。为了保持足够的精简,这个 JAR 不包含连接器和特定类库(如 CEP、SQL、ML 等)。
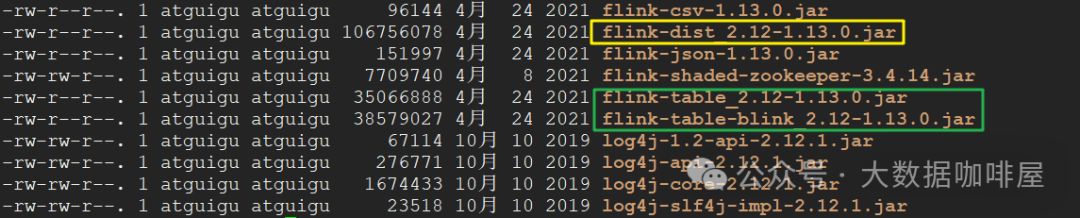
/lib 目录的其他依赖
/lib 目录中还包括一些常用模块的 JAR 文件,例如:
-
• Table 模块(上图绿色框)
-
• 数据格式支持模块(如 CSV、JSON 格式)
这些模块默认情况下会被自动加载。如果希望禁止加载某些模块,只需将对应的 JAR 文件从 classpath 的 /lib 目录中移除。
/opt 目录中的可选依赖
Flink 还在 /opt 文件夹中提供了额外的可选依赖项。需要启用时,可以将这些 JAR 文件移动到 /lib 目录中进行加载。