目录
[1. HDFS核心架构:三大角色分工](#1. HDFS核心架构:三大角色分工)
[1. Flink核心特性](#1. Flink核心特性)
[2. Flink核心架构:三层协作模型](#2. Flink核心架构:三层协作模型)
三、Flink+K8s+HDFS:云原生大数据的"黄金组合"
[1. 弹性资源调度:降本增效的核心](#1. 弹性资源调度:降本增效的核心)
[2. 可靠数据存储:保障计算不丢数据](#2. 可靠数据存储:保障计算不丢数据)
[3. 高可用与易运维:降低集群管理成本](#3. 高可用与易运维:降低集群管理成本)
[0. 背景知识](#0. 背景知识)
[1. 问题现象](#1. 问题现象)
[NN Pod完整报错日志](#NN Pod完整报错日志)
[2. 检查PVC处于pending原因](#2. 检查PVC处于pending原因)
在Flink+K8s+HDFS的云原生大数据架构中,HDFS的NameNode(NN)是核心组件,其Pod报错"存储目录异常"且关联PVC处于Pending状态是常见问题。要高效排查这类问题,需先理清HDFS、Flink的核心概念与架构,以及三者协同的优势,再针对性定位存储资源问题。
一、HDFS:分布式存储的"数据仓库"
HDFS(Hadoop Distributed File System)是专为大数据场景设计的分布式文件系统,核心作用是安全存储海量数据并支持高并发访问,相当于大数据架构中的"共享仓库"。
1. HDFS核心架构:三大角色分工
HDFS采用"主从架构",通过三个核心角色协同实现数据存储与管理,用"图书馆"比喻更易理解:
-
NameNode(NN):仓库管理员 - 负责管理"文件元数据"(如文件名、存储路径、大小、修改时间),相当于图书馆的"索引目录",不存储实际数据。 - 是HDFS的"大脑",一旦故障整个存储系统不可用,生产环境需部署主备NN(HA架构)确保高可用。 - 核心依赖:需持久化存储元数据到本地目录(如`/hdfs-data/pv-nn/name`),该目录通常挂载K8s的PVC实现数据持久化------这也是NN Pod报错与PVC强相关的原因。
-
DataNode(DN):仓库货架 - 负责存储实际数据块(默认128MB/块,可配置),相当于图书馆的"书架",数据块会默认存3份副本避免丢失。 - 定期向NN汇报自身存储的块信息,NN据此维护全局元数据。
-
JournalNode(JN):管理员的"同步笔记本" - 仅在HA架构中存在,负责主备NN的元数据同步。主NN修改元数据后,会将操作记录写入JN集群,备NN实时读取同步,确保主备切换时数据一致。 - 需部署奇数个节点(至少3个),通过投票机制保证数据可靠性。
HDFS工作流:用户上传文件→NN分配存储块和DN节点→文件被切分成块存储到多个DN→NN记录元数据并同步到JN→用户读取文件时,NN告知DN位置,直接从DN读取。
二、Flink:大数据处理的"计算引擎"
Apache Flink是一款流批一体的分布式计算框架,既能处理实时数据流(如电商实时交易、用户行为日志),也能处理固定大小的批数据(如历史报表统计),核心定位是"让数据计算更实时、更可靠"。
1. Flink核心特性
-
流批一体:将批数据视为"有界流",用同一引擎处理,避免传统"流批两套系统"的复杂度。
-
低延迟高吞吐:基于"流处理优先"设计,可实现毫秒级延迟,同时支持每秒数百万条数据的吞吐。
-
可靠状态管理:计算过程中的中间结果(如窗口聚合值)可持久化,任务故障后能恢复状态,保证计算连续性。
2. Flink核心架构:三层协作模型
-
客户端(Client):任务提交入口 - 将用户编写的Flink作业(Java/Scala/Python代码)编译成"作业图(JobGraph)",提交给JobManager,不参与实际计算。
-
JobManager:计算指挥中心 - 集群的"大脑",负责作业调度与管理,包含: - ResourceManager:申请和分配计算资源(CPU/内存); - Dispatcher:接收作业并启动JobMaster; - JobMaster:每个作业对应一个JobMaster,将JobGraph优化为"执行图(ExecutionGraph)",调度任务到TaskManager执行。
-
TaskManager:计算执行节点 - 集群的"干活节点",负责执行具体计算任务,每个TaskManager包含多个Task Slot(计算单元),可并行运行多个任务; - 与其他TaskManager交互数据,管理本地状态存储。
三、Flink+K8s+HDFS:云原生大数据的"黄金组合"
三者并非独立存在,而是形成"计算-调度-存储"的闭环:Flink负责"计算",K8s负责"资源调度与集群管理",HDFS负责"数据存储",组合优势显著。
1. 弹性资源调度:降本增效的核心
K8s的动态调度能力与Flink结合,实现资源按需分配: - 大促等流量高峰时,K8s自动增加Flink TaskManager Pod和HDFS DataNode数量; - 低谷时自动缩减资源,避免闲置浪费; - 通过Namespace和资源配额隔离Flink、HDFS等服务,防止相互抢占资源。
2. 可靠数据存储:保障计算不丢数据
HDFS为Flink提供关键存储支撑: - Flink的Checkpoint(定期快照)和Savepoint(手动快照)存储到HDFS,故障后可恢复状态; - 计算结果数据(如实时报表)持久化到HDFS,支持后续查询和分析; - HDFS的多副本存储确保数据不丢失,适配大数据场景的可靠性需求。
3. 高可用与易运维:降低集群管理成本
三者协同实现端到端高可用: - Flink JobMaster主备切换、HDFS NN主备切换通过K8s和ZooKeeper保障; - 所有组件容器化部署,用K8s YAML定义配置,实现"一次编写,到处部署"; - 统一通过Prometheus+Grafana监控计算、资源、存储指标,运维更高效。
四、问题实战:NN报错与PVC状态关联排查
0. 背景知识
hdfs的NN的初始化是否依赖JN
在HDFS非高可用(Non-HA)模式下,NameNode的初始化不依赖JournalNode;但在高可用(HA)模式下,NameNode的初始化确实依赖JournalNode。
| 特性维度 | 🚫 非HA模式 | ✅ HA模式 |
|---|---|---|
| 核心依赖 | 初始化不依赖JN | 初始化依赖JN |
| JournalNode角色 | 无JN角色 | JN作为共享存储系统,是HA的关键组件 |
| NameNode关系 | 单个NameNode | Active与Standby NN通过JN同步元数据 |
| 初始化命令 | hdfs namenode -format |
1. 主NN: -format 2. 备NN: -bootstrapStandby |
HA模式下初始化的关键步骤
在HA模式下,NameNode的初始化是一个严谨的过程,其核心依赖JournalNode作为共享存储系统来保证元数据的一致性。具体步骤如下:
-
启动JournalNode集群 :在初始化NameNode之前,必须先在所有JournalNode节点上启动JournalNode服务。这是后续操作的基础。
-
格式化并启动主NameNode :在规划为Active的NameNode节点上,执行格式化命令
hdfs namenode -format。这个命令会初始化本地的元数据目录,并且会与配置好的JournalNode集群进行交互,初始化共享编辑日志区域。 -
同步元数据到备NameNode :在规划为Standby的NameNode节点上,执行
hdfs namenode -bootstrapStandby命令。这个命令会从JournalNode共享编辑目录(以及可选的从主NameNode拉取最新的fsimage)同步元数据,确保备节点与主节点具有一致的起点
1. 问题现象
NN Pod完整报错日志
通过kubectl logs <nn-pod-name> -n ververica查看报错,核心信息如下:
bash
2025-11-03 01:46:19,924 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /hdfs-data/pv-nn/name is in an inconsistent state: storage directory does not exist or is not accessible.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:369)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:220)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1044)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:707)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:635)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:696)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:906)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:885)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1626)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1694)
2025-11-03 01:46:19,926 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1PVC与组件状态详情
博主环境中部署的HA模式
通过kubectl get pvc -n ververica和kubectl get pods -n ververica | grep jn查看状态:
bash
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
lxcfs-pvc Bound pvc-d61befd8-1be9-47f8-bb09-b179e2945767 1Ki RWX lxcfs-sc 43h
pv-jn-vvp-hdfs-cluster-jn-0 Bound yoda-0292255e-b49b-42fd-a560-cfd502359b4c 70Gi RWO fast-disks 36h
pv-jn-vvp-hdfs-cluster-jn-1 Bound yoda-3c3ef831-61b4-4099-9cc3-a793c1baf798 70Gi RWO fast-disks 36h
pv-jn-vvp-hdfs-cluster-jn-2 Pending fast-disks 36h
pv-nn-vvp-hdfs-cluster-nn-0 Bound yoda-321b0886-c3d8-46be-9972-040c3d88c227 120Gi RWO fast-disks 35h
pv-nn-vvp-hdfs-cluster-nn-1 Bound yoda-9e6052dc-8838-4fef-87aa-af1dccbe00d6 120Gi RWO fast-disks 35h
bash
# JN Pod状态
pv-jn-vvp-hdfs-cluster-jn-0 1/1 Running 0 36h
pv-jn-vvp-hdfs-cluster-jn-1 1/1 Running 0 36h
pv-jn-vvp-hdfs-cluster-jn-2 0/1 Pending 0 36h**关键结论**:当前环境中,pv-jn-vvp-hdfs-cluster-jn-2(JN 2节点)PVC处于Pending状态,导致JN集群仅2个节点就绪,未满足"奇数个节点(至少3个)"的Quorum机制要求,进而阻塞了NN的启动流程。
2. 检查PVC处于pending原因
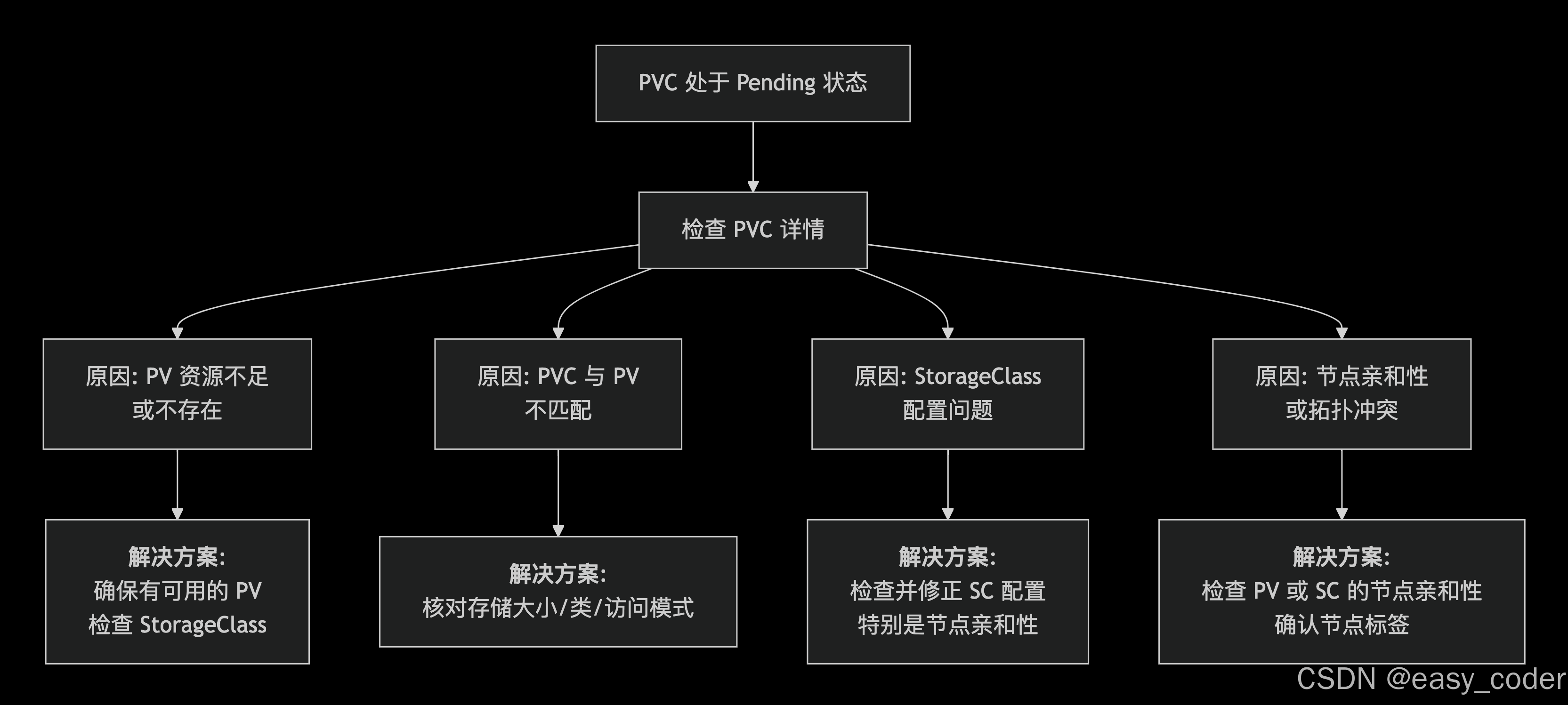
博主环境最终定位到:机器重新Clone后的节点亲和性问题。其他场景不再赘述
五、总结
这类问题的本质是云原生环境中"容器与存储"的协同细节问题,需兼顾K8s资源配置与HDFS运行依赖,才能高效解决并避免复发。
回到原始问题"NN Pod报错存储目录异常且PVC Pending",结合上述架构可知: - NN的元数据目录(如`/hdfs-data/pv-nn/name`)依赖K8s PVC挂载实现持久化,若PVC处于Pending状态,意味着NN Pod无法获取存储资源,目录自然"不存在或不可访问",导致NN启动失败。