
上一篇:《人工智能大语言模型起源篇,低秩微调(LoRA)》
(14)Rae 和同事(包括78位合著者!)于2022年发表的《Scaling Language Models: Methods, Analysis & Insights from Training Gopher》,https://arxiv.org/abs/2112.11446
《Gopher》是篇特别好的论文,包含了大量分析来帮助理解大型语言模型(LLM)的训练过程。在这篇论文中,研究人员训练了一个包含2800亿参数、80层的模型,使用了3000亿个标记(tokens)。其中包括一些有趣的架构修改,比如使用RMSNorm(均方根归一化)代替LayerNorm(层归一化)。LayerNorm和RMSNorm通常比BatchNorm更受欢迎,因为它们不依赖于批量大小,也不需要同步,在使用较小批量大小的分布式环境下具有优势。不过,通常认为RMSNorm能稳定更深层架构的训练。
除了像上述的有趣细节外,这篇论文的主要焦点是对不同规模模型任务表现的分析。在152个不同任务上的评估结果显示,增加模型规模对理解、事实核查和有害语言识别等任务的提升最大。不过,涉及逻辑和数学推理的任务,从架构扩展中获益较少。
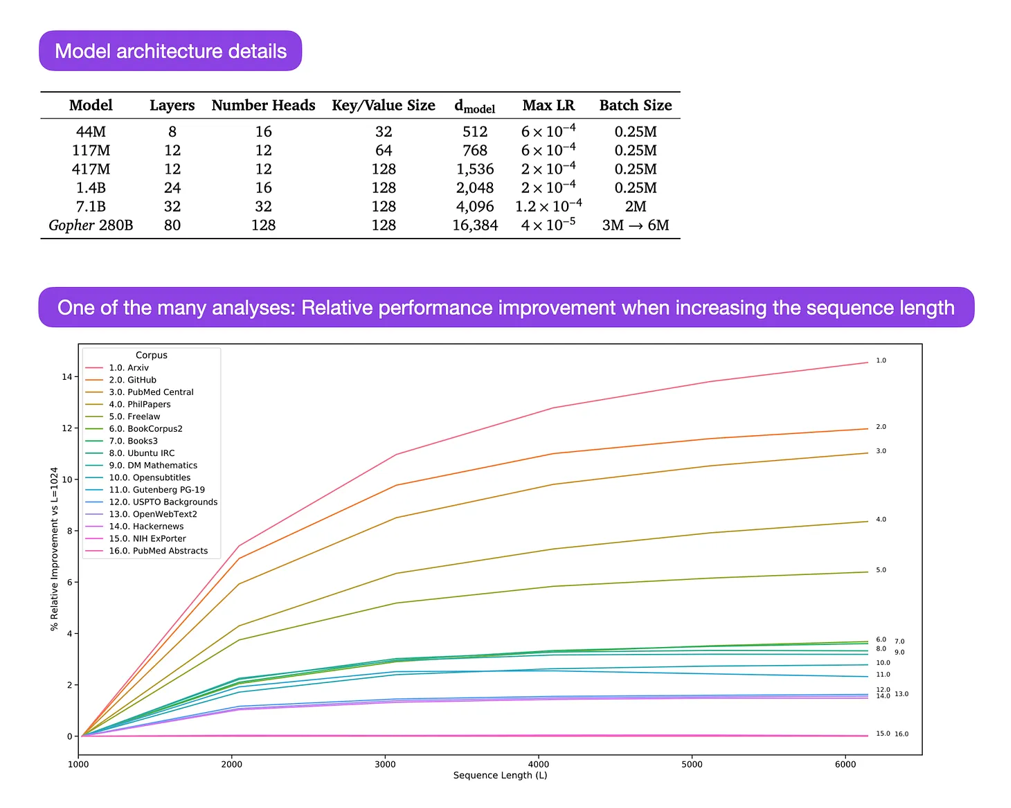
来源:图片来自https://arxiv.org/abs/2112.11446(15)Hoffmann、Borgeaud、Mensch、Buchatskaya、Cai、Rutherford、de Las Casas、Hendricks、Welbl、Clark、Hennigan、Noland、Millican、van den Driessche、Damoc、Guy、Osindero、Simonyan、Elsen、Rae、Vinyals 和 Sifre 于2022年发表的《Training Compute-Optimal Large Language Models》,https://arxiv.org/abs/2203.15556
这篇论文介绍了70亿参数的Chinchilla模型,它在生成建模任务上超越了流行的175亿参数的GPT-3模型。然而,论文的核心观点是,现代的大型语言模型"明显训练不足"。
论文定义了大语言模型训练的线性扩展规律。例如,尽管Chinchilla的规模只有GPT-3的一半,但它在训练了1.4万亿(而不是仅仅3000亿)标记后,超越了GPT-3。换句话说,训练标记的数量和模型规模一样重要。
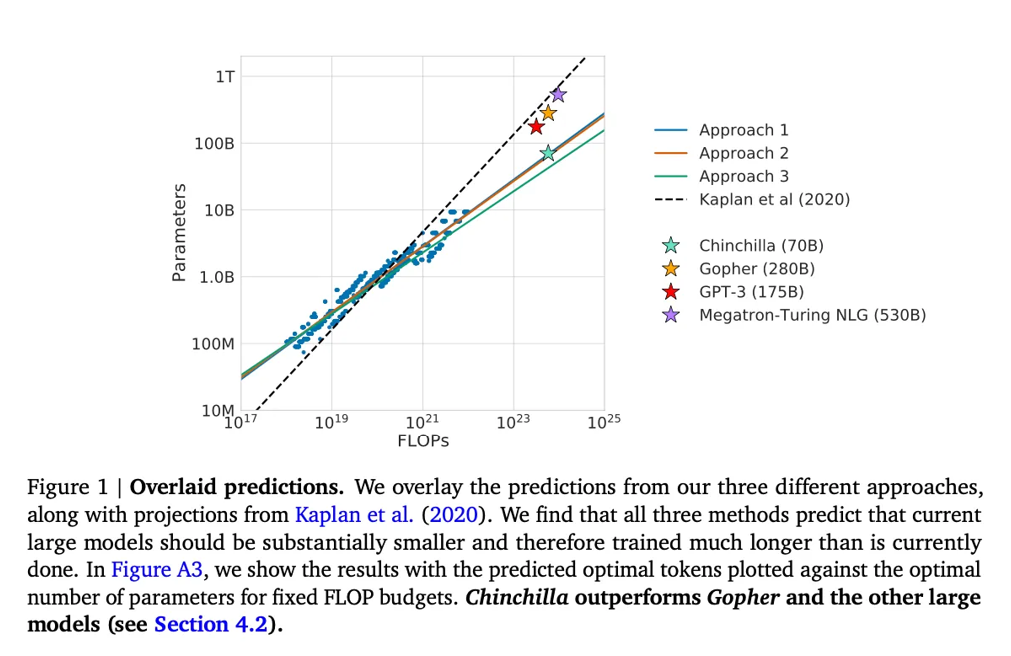
来源:https://arxiv.org/abs/2203.15556
(16)Biderman、Schoelkopf、Anthony、Bradley、O'Brien、Hallahan、Khan、Purohit、Prashanth、Raff、Skowron、Sutawika 和 van der Wal 于2023年发表的《Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling》,https://arxiv.org/abs/2304.01373
Pythia是一套开源的大型语言模型(70M到12B参数),用于研究大型语言模型在训练过程中如何演变。
它的架构类似于GPT-3,但包括了一些改进,例如,Flash Attention(类似LLaMA)和旋转位置嵌入(类似PaLM)。Pythia使用The Pile数据集(825GB)进行训练,训练了300B标记(在常规的PILE上约训练了1个epoch,在去重的PILE上训练了约1.5个epoch)。
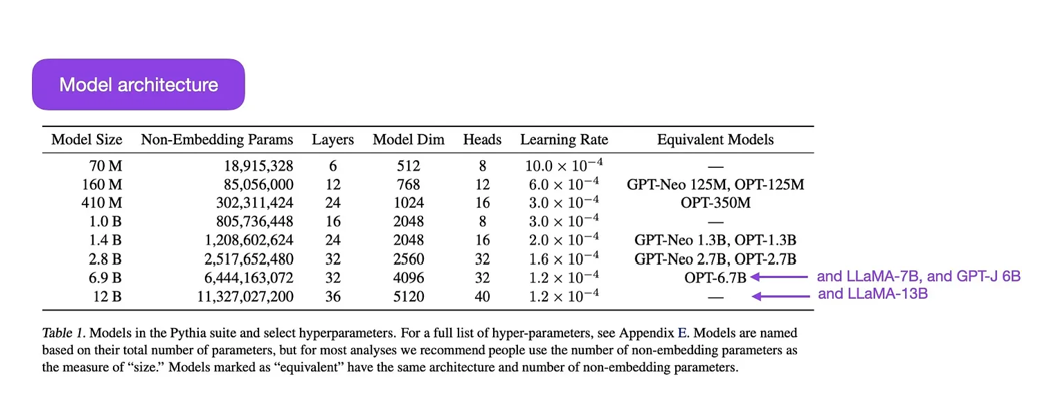
pytaiya 模型套件来自 https://arxiv.org/abs/2304.01373。Pythia研究的主要发现如下:
-
在重复数据上训练(由于大型语言模型的训练方式,这意味着训练超过一个epoch)不会对性能产生正面或负面影响。
-
训练顺序不会影响记忆效果。这很遗憾,因为如果情况相反,我们可以通过重新排序训练数据来缓解不希望的逐字记忆问题。
-
预训练的词频会影响任务性能。例如,较常见的词汇通常会提高少样本准确率。
-
将批量大小加倍,可以将训练时间减少一半,但不会影响收敛性。
对齐------引导大型语言模型朝向预期目标和利益
近年来,我们看到许多相对强大的大型语言模型,它们可以生成真实的文本(比如GPT-3和Chinchilla等)。似乎我们在使用常见的预训练范式上已经达到了瓶颈。
为了让语言模型更有帮助,并减少错误信息和有害语言,研究人员设计了额外的训练范式来微调预训练的基础模型。
(17) 《训练语言模型以遵循指令并结合人类反馈》(2022年),作者:Ouyang、Wu、Jiang、Almeida、Wainwright、Mishkin、Zhang、Agarwal、Slama、Ray、Schulman、Hilton、Kelton、Miller、Simens、Askell、Welinder、Christiano、Leike、Lowe,网址:https://arxiv.org/abs/2203.02155。
在这篇所谓的InstructGPT论文中,研究人员使用了一个带有人类在环的强化学习机制(RLHF)。他们从一个预训练的GPT-3基础模型开始,使用人类生成的提示-回应对进行监督学习,进一步微调模型(步骤1)。接下来,他们让人类对模型输出进行排名,以训练一个奖励模型(步骤2)。最后,他们使用奖励模型,通过近端策略优化(PPO)强化学习更新预训练并已微调的GPT-3模型(步骤3)。
顺便提一下,这篇论文也被认为是描述ChatGPT背后思想的论文------根据最近的传闻,ChatGPT是InstructGPT的扩展版,已经在更大的数据集上进行了微调。
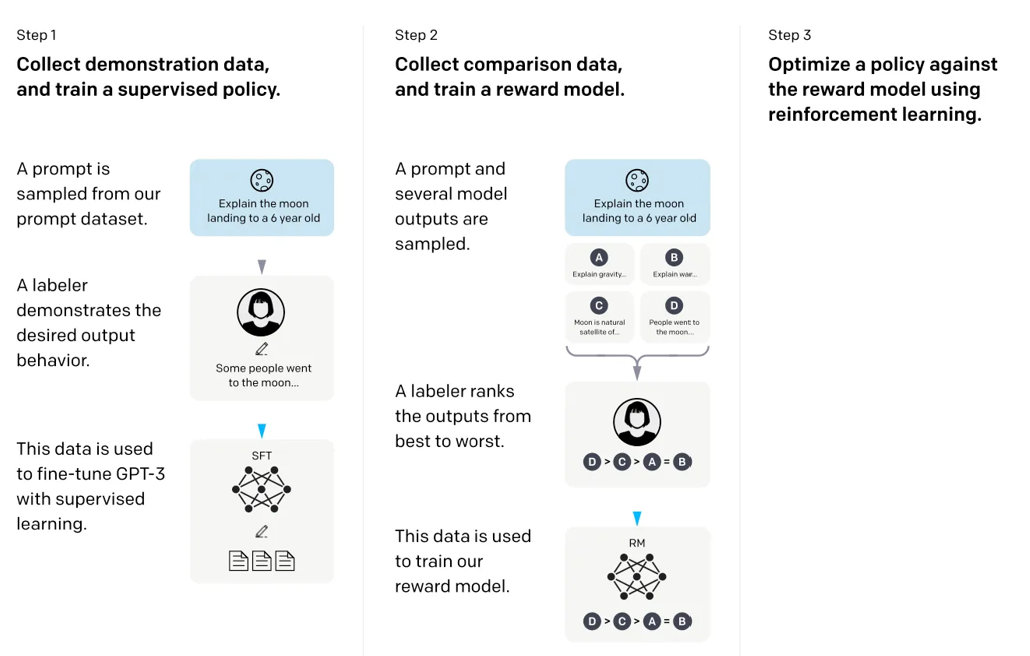
来源:https://arxiv.org/abs/2203.02155