前言
学习C语言的过程中,涉及到各种各样的关键词,在我们点击编译的时候,都会做什么呢?让我们来拆解一下
C语言的编译过程
C语言的编译过程包括预处理、编译、汇编和链接四个主要步骤。每个步骤都有其特定的任务和输出文件类型,通过这些步骤,源代码被逐步转换为可执行的机器码。
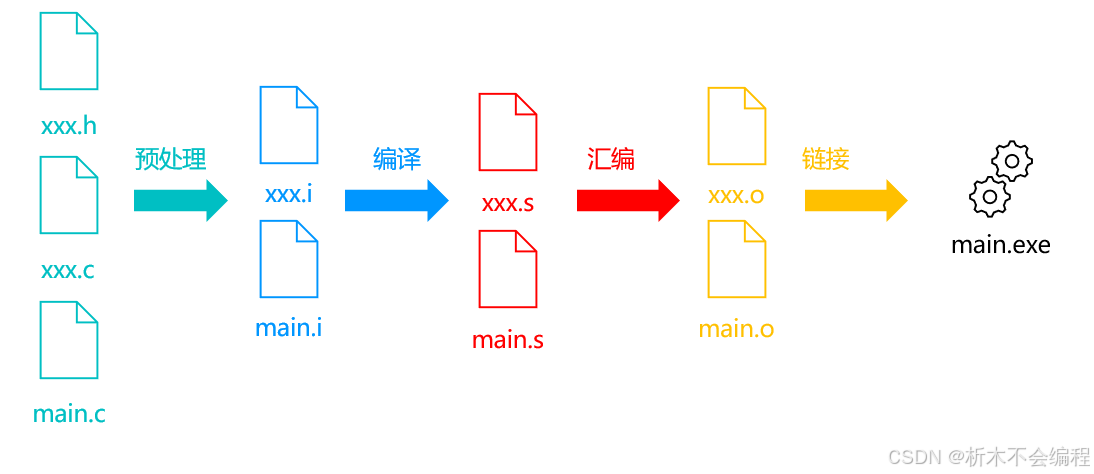
预处理
预处理器处理源代码中的预处理指令:
- 预处理器处理源代码文件中的预处理指令,如
#include、#define等。 #include指令会将指定的头文件内容插入到源文件中。#define指令会进行宏替换。- 处理所有条件编译指令(
#ifdef、#ifndef、#endif等)。 - 预处理后的代码通常会生成一个扩展名通常为
.i的文件。 - 删除所有注释
- 添加行号和文件名标识,便于在调试和出错时给出具体代码位置
编译
- 编译器将预处理后的代码转换为汇编代码。
- 这个阶段会进行语法分析、语义分析、优化等操作。
- 确定变量的类型,作用域及储存位置。
- 生成的汇编代码通常保存在一个扩展名为
.s的文件中。
汇编
- 汇编器将汇编代码转换为机器码,即目标代码。
- 确定局部变量的内存。
- 生成的目标代码通常保存在一个扩展名为
.o或.obj的文件中。
链接
- 链接器将多个目标文件和库文件链接在一起,生成最终的可执行的二进制文件。
- 链接过程中,链接器会解决符号引用,确保所有函数和变量都能正确调用。
- 生成的可执行文件在Windows上通常扩展名为
.exe,在Unix/Linux系统上没有特定的扩展名。
举例
假设有一个C语言源文件main.c,其内容如下:
cs
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}1. 预处理
使用gcc编译器的预处理命令:
cs
gcc -E main.c -o main.i生成的main.i文件内容可能如下:
cs
# 1 "main.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "main.c"
# 1 "/usr/include/stdio.h" 1 3 4
...
# 2 "main.c" 2
int main() {
printf("Hello, World!\n");
return 0;
}2. 编译
使用gcc编译器的编译命令:
cs
gcc -S main.i -o main.s生成的main.s文件内容可能如下:
cs
.file "main.c"
.section .rodata
.LC0:
.string "Hello, World!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $.LC0, %edi
call puts
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0"
.section .note.GNU-stack,"",@progbits使用gcc编译器的汇编命令:
3. 汇编
使用gcc编译器的汇编命令:
cs
gcc -c main.s -o main.o生成的main.o文件是二进制格式的目标文件。
4. 链接
使用gcc编译器的链接命令:
cs
gcc main.o -o main生成的main文件是最终的可执行二进制文件。
总结
C语言的编译过程包括预处理、编译、汇编和链接四个主要步骤。每个步骤都有其特定的任务和输出文件类型,通过这些步骤,源代码被逐步转换为可执行的机器码。