
关注我,学习c++不迷路:
专栏如下:
后续会更新更多有趣的小知识,关注我带你遨游知识世界

期待你的关注。

文章目录
- [1. 前言:](#1. 前言:)
- [2. 主要内容介绍:](#2. 主要内容介绍:)
-
- [2-1 什么是参数包?](#2-1 什么是参数包?)
- [2-2 举个小栗子:](#2-2 举个小栗子:)
- [2-3 sizeof计算包中参数个数:](#2-3 sizeof计算包中参数个数:)
-
- [2-3-1 如何理解...的位置:](#2-3-1 如何理解...的位置:)
- [2-3-2 如何理解答案相同:](#2-3-2 如何理解答案相同:)
- [2-4 包扩展:](#2-4 包扩展:)
- [2-5 实际应用,emplace接口系列:](#2-5 实际应用,emplace接口系列:)
- [3. 总结:](#3. 总结:)
1. 前言:
本文主要初步讲解什么是可变模板参数,为什么c++11需要引进可变模板参数,如何理解可变模板参数。
废话不多,我们来给出可变模板参数的概念,一句话:
在 C++ 中,可变模板参数(variadic templates)就是"可以接受任意数量参数"的模板参数。
(之前的模板不香吗,的确很好用。但是我每次传入不同个数的模板,你不就炸了吗,你这得写好多个模板,很显然,这是不合适的,因此我们引入了可变模板参数:你无论传入几个模板,我都可以稳稳的接住)
怎么写,长什么样?
cpp
template<class ...Args>
void func(Args ...args)
{
//
}这是一种写法,其中class可以换成typename,大体结构保持这样。接下来我们详细解释一下这些东西,其中Args并不是一定要这样写,只是这样写的是一种不成文的规矩,我还是推荐这样写的,这是因为便于理解。
cpp
template<class ...T>//这里Arg也可以变成其他的,比如T
void func(T ...args)
{
//函数体
}他其实类似与模板,甚至写法上面你也可以看出,他真的很像很类似,但是不同的是它可以接受不用的参数。接下来我们一起看看吧
2. 主要内容介绍:
2-1 什么是参数包?
参数包"就是把"很多个参数打包成一个整体的名字",你可以对这一整包做统一操作,然后再在需要的地方把这一包拆开(展开)成一个一个具体的参数。这里的参数包指的是:T ... args,这个概念其实很简单了。函数参数包(function parameter pack):对应的函数参数那一包值。
可能还是不清楚,我们来对比一下模板参数和参数包:
- 模板参数:只能代表"一个类型"或"一个值",例如:
template 中的 T 只代表一个类型(比如 int、double)。 - 参数包:可以代表"一串类型 / 一串值",例如:
template<typename... Ts> 中的 Ts 可能表示 {int, double, std::string} 这样的一堆类型。
这么来说相应地,函数参数里对应的"包"就是一串参数:void f(Ts... ts); 中的 ts 就是一包参数。所以,"参数包"就是一个"代表多个参数的包的名字"。
在这里我们理解了,什么是参数包,对于后面的例子就可以看的很清楚了。
2-2 举个小栗子:
这个可变模板参数是在c++11中引进的新技术,这里有什么作用呢?我来举个小例子:比如我想打印一组不同类型的数据,但是不用cout,此时我们可以尝试实现一个可变参数的函数
cpp
// 1. 终止条件:没有参数时
void print()
{
}
// 2. 至少一个参数
template <typename T, typename... Rest>
void print(const T& first, const Rest&... rest)
{
std::cout << first << std::endl; // 处理第一个
print(rest...); // 把剩下那一包展开继续递归
}
int main()
{
print(1, 1.2, 13, "111111");
return 0;
}来看结果:
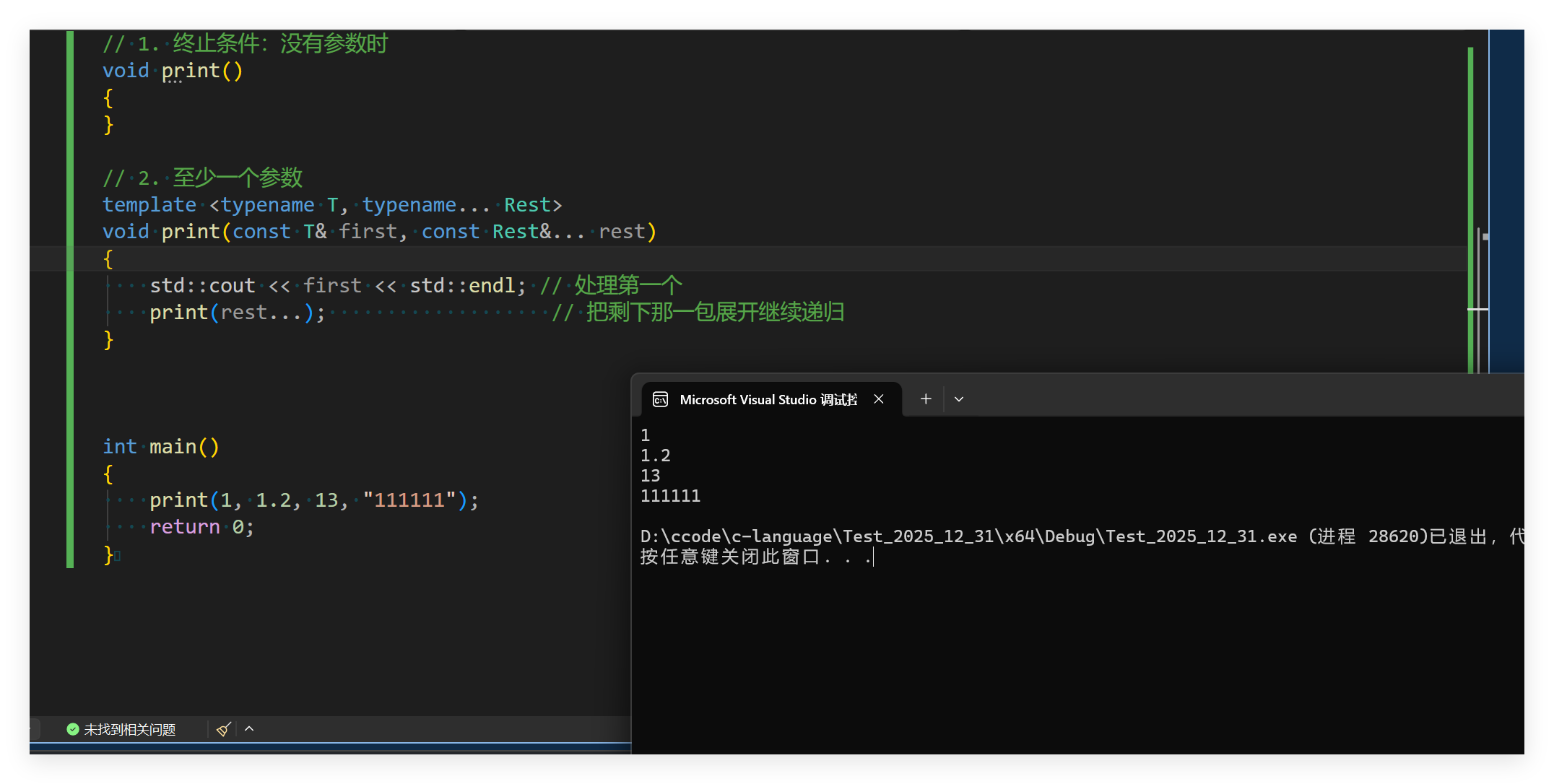
发现一切打印正常完成,此时完美的打印了每一个数据。如果不使用这个技巧,可能会导致写很多函数。有了这个他会自动帮你生成。同时我们发现这个调用很类似与递归的调用,最后有一个简单的递归终止条件。这里的 Rest 是一个模板参数包,rest 是函数参数包;rest... 表示把"剩下的那包参数全部展开传给下一层"。
2-3 sizeof计算包中参数个数:
- sizeof...(Args) -> 计算类型包 Args 有多少个类型。
- sizeof...(args) -> 计算函数参数包 args 有多少个参数。
我们继续深究参数包,我们发现,我们可以使用sizeof...来完成对包的参数的个数进行统计:
cpp
template <class ...Args>
void print(Args ...args)
{
cout << sizeof...(args) << endl;
}
int main()
{
print(1, 1.2, 13, "111111");
return 0;
}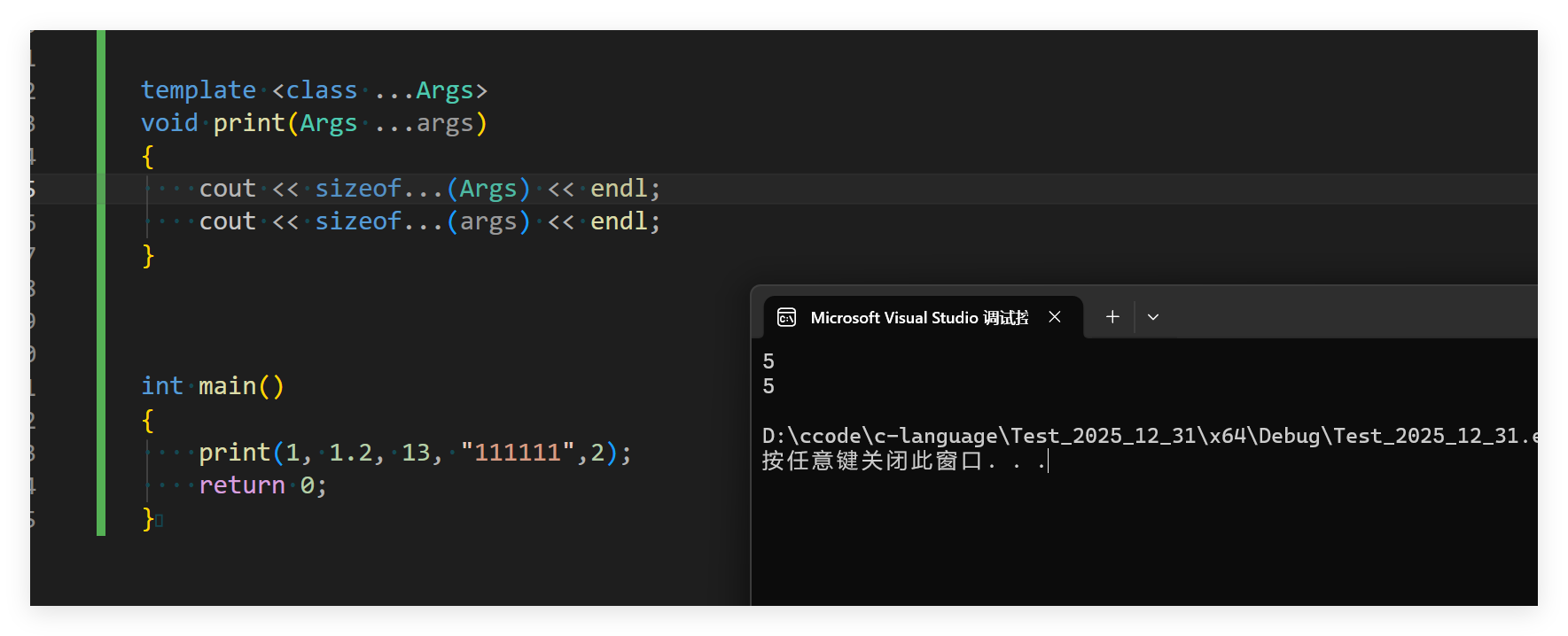
我们发现两个参数是一样的,明明说args是看有几个参数类型的,Args是有几个类型的。这是为什么呢?后面在细细解答:
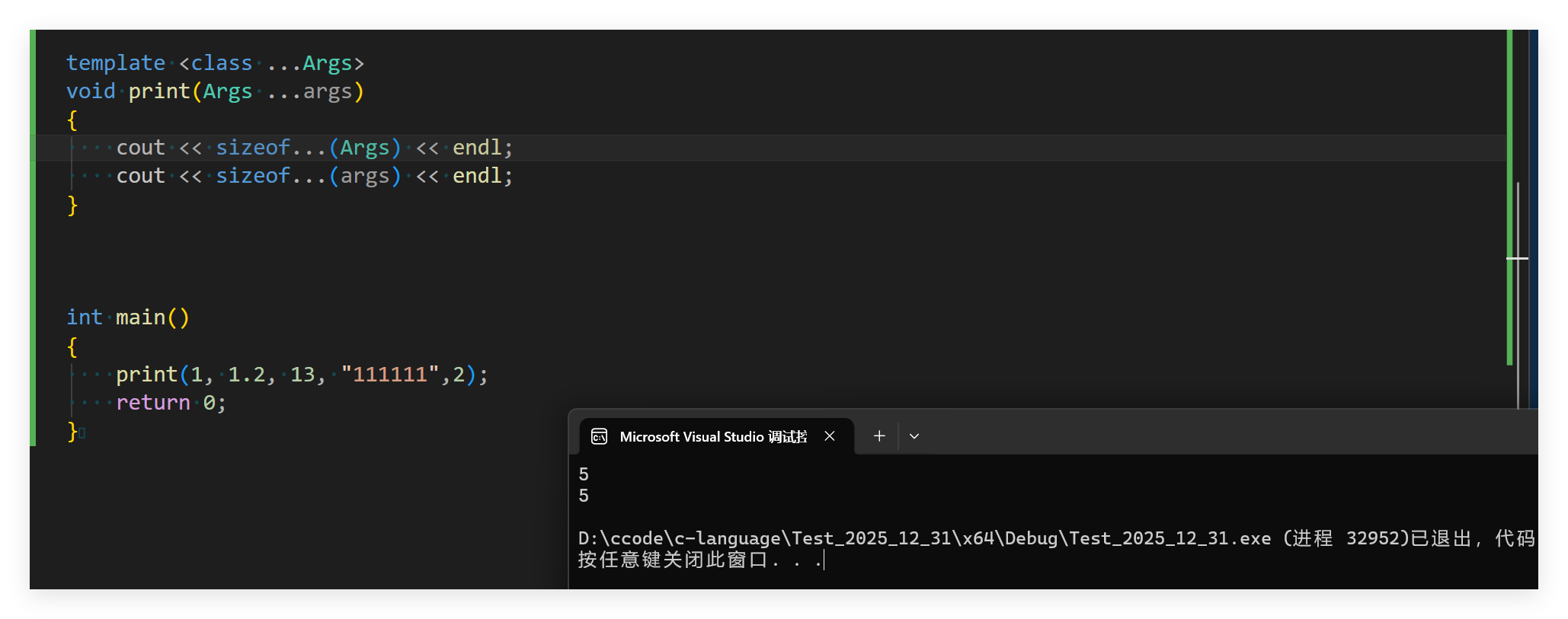
这里就完成了对模板参数的统计,需要注意的是... 需要放在指定的位置,才能编译通过完成运行。
2-3-1 如何理解...的位置:
在这里我们准确的来说,不是通过sizeof来完成对包的参数解析,而是sizeof...来完成对每一个参数的统计。
- sizeof... 是一个特定的操作符(operator),就像 sizeof、decltype 一样。
- 它后面的 ... 是操作符名字的一部分,专门用来表示"我要查的是参数包的大小",而不是"我要展开参数"。
- 这种写法是 C++ 标准规定的"固定语法",为了区别于普通的 sizeof 和普通的参数展开 args...。
sizeof...(新朋友,C++11 引入)
作用:计算参数包里有多少个参数(返回值是 std::size_t 类型)。
写法:
- sizeof...(Args) -> 计算类型包 Args 有多少个类型。
- sizeof...(args) -> 计算函数参数包 args 有多少个参数。
2-3-2 如何理解答案相同:
先给你直接结论:
-
在数量上:
sizeof...(Args) 和 sizeof...(args) 的结果永远是一样的。
因为你传入了多少个值,编译器就推导出了多少个类型,它们是一一对应的。
-
结果依然一样。
即使你传入两个 int,在编译器眼里,这依然是"两个参数",而不是"一个参数"。它不会因为类型相同就合并。
我们先来看一段程序:
cpp
template<typename... Args>
void func(Args... args)
{
std::cout << "Types count: " << sizeof...(Args) << std::endl;
std::cout << "Args count: " << sizeof...(args) << std::endl;
}
int main()
{
func(1,2);
return 0;
}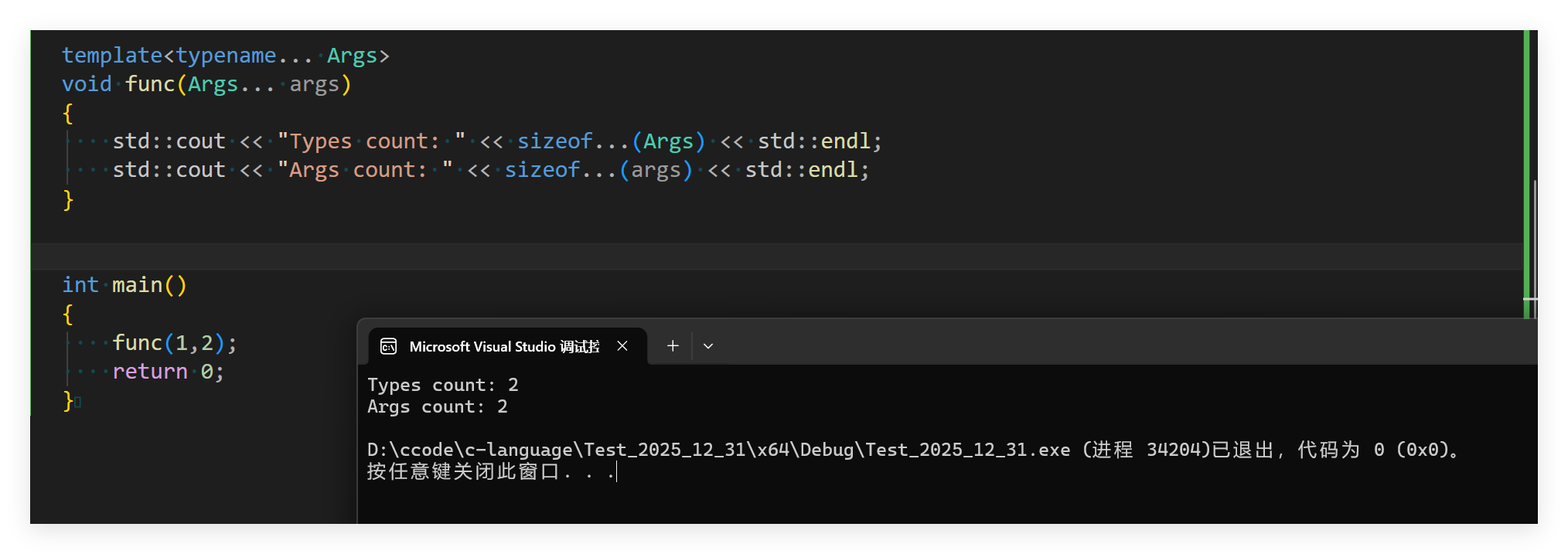
这里的运行结构依旧是一致的。在这里我们就需要讲到的他的原理了:
- 推导 Args(类型包):
- 第一个参数 10 是 int。
- 第二个参数 20 也是 int。
- 注意: C++ 编译器不会把它们合并成一个 int。它老老实实地记录为 int, int。
所以,Args = {int, int}。长度是 2。
- 匹配 args(值包):
- 对应上面的类型,参数列表变成 (int arg1, int arg2)。
- 具体值为 10, 20。
所以,args = {10, 20}。长度是 2。
你可能会问:"既然都是 int,为什么不把 Args 推导成 int,而把 args 推导成 int 的数组或者列表呢?"这是为了保持位置的对应关系。如果合并了,你就无法区分第一个 int 和第二个 int 分别对应什么逻辑了。
2-4 包扩展:
我们除了能够完成对包里面的参数完成个数统计,还可以包拓展,那什么是包拓展呢:"包扩展"(pack expansion)就是:在参数包名字后面写上 ...,让编译器把这个"一包参数"展开成一串独立的东西(类型、表达式、参数......)包扩展是一个包含"参数包 + 省略号"的结构,表示把这个参数包展开成一串模式(pattern)。
cpp
template<typename... Args>
void func(Args... args); // Args... args 就是包扩展这里的就是模板参数包Args...完成拓展。这个包里的参数一个一个的拿出来,完成包拓展。这里 Args... 扩展成一串类型,比如 int, double, std::string,从而 args 也变成一串参数 (int a1, double a2, std::string a3)
有这个过后,我们可以看下面这个例子:
cpp
void showList()
{
//这个类似与终止条件:
cout << endl;
}
template<class T,class... Args>
void showList(T x,Args... args)
{
cout << x << " ";
showList(args...);
}
template<class... Args>
void print(Args... args)
{
showList(args...);
}
int main()
{
print("1111", 1, 3, 4, 6,1.2,1.8);
return 0;
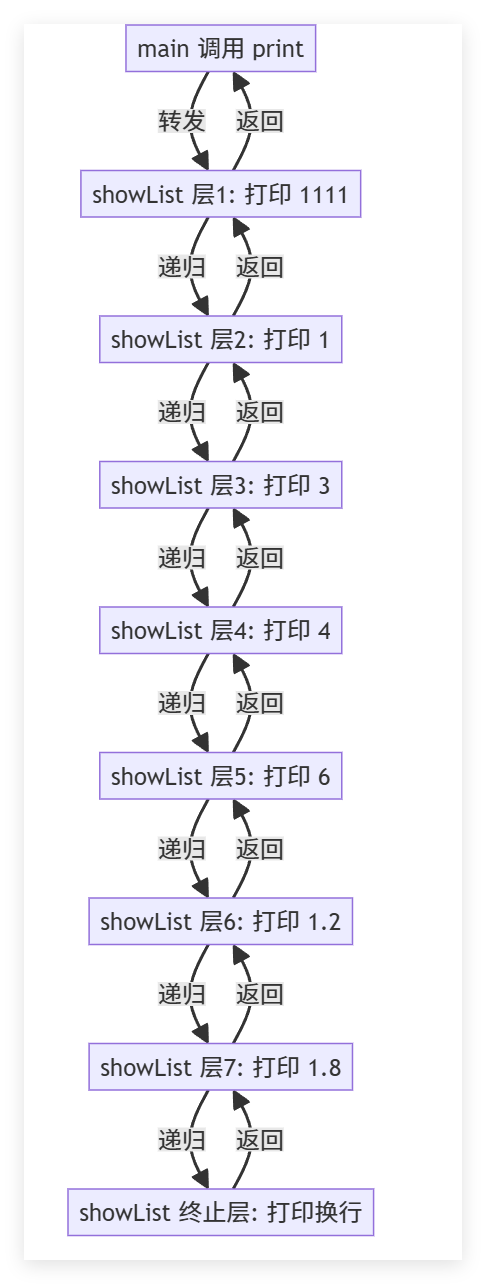
}这个函数也很好的解释了什么是包拓展,还有函数的底部是怎么调用的,下面听我一一道来:
第一部分:代码逻辑详解:
这段代码其实设计成了一个"三明治"结构: 最底层:showList() ------ "刹车"
中间层次:也是整个代码的核心:就是void showList(T x,Args... args),这个完成对包的每次取出一个,后面再成为一个包,后续语句只需在进行包拓展就行了,这样是为什么可以完成继续调用。最顶层:print(Args... args) ------ "传话筒",不是逻辑实现的关键。
第二部分:编译器在干什么?
编译器在编译这段代码时,会像生成"俄罗斯套娃"一样,自动生成多个版本的 showList 函数:入口:编译器看到 print 被调用,生成 print 实例,里面调用了 showList。
- 第1次生成:
参数:const char*, int, int, int, int, double, double (共7个)
编译器生成 showList<const char*, int, int, int, int, double, double>
内部逻辑:打印 "1111",然后调用下一层。 - 第2次生成:
参数:int, int, int, int, double, double (剩6个)
编译器生成 showList<int, int, int, int, double, double>
内部逻辑:打印 1,然后调用下一层。 - 第3次生成:
参数:int, int, int, double, double (剩5个)
...生成 showList<...>,打印 3... - ... (以此类推,每层少一个参数) ...
- 倒数第2次生成:
参数:double (剩1个)
编译器生成 showList
内部逻辑:打印 1.8,然后调用下一层。注意!此时调用的是 showList(),也就是没有参数的那个版本。 - 最后匹配:
编译器发现没有参数了,直接匹配到非模板函数 void showList()。
这个就解释了为什么什么是包拓展,什么是包,是怎么调用的:
2-5 实际应用,emplace接口系列:
它们的设计目的是:"在容器内部直接构造元素",而不是"在外部构造好再拷贝/移动进去"。这点比push或者c++11之前的接口要现代许多,这也是c++这个语言一直保持很高的生命力的典型:
核心实现套路就是:
- 声明为可变模板函数:template<class... Args>
- 参数用"转发引用"接收:Args&&... args
- 内部使用完美转发转发给构造函数:T(std::forward(args)...)
(之前已经讲过什么是万能引用,什么是完美转发,详细可以去我的主页去找,也可以问AI哦)
cpp
template<class... Args>
reference emplace_back(Args&&... args);template<class... Args>:这就是"可变模板"------可以接受 0 个或多个不同类型的参数。
Args&&... args:这是"转发引用"形式的"函数参数包",配合 std::forward 实现完美转发。(不会改变左右值的属性,继续往下一层)
这里也不详细讲了,这个接口系列是比insert和push系列高效一点。
emplace 系列通常比 push / insert "高效",根本原因是:
emplace 在容器内部的内存上"直接构造"对象,而 push / insert 一般需要"先构造出一个对象,再拷贝/移动进去",这就多了一次构造或者一次移动的开销
3. 总结:
c++11引入了可变模板参数,极大的节省了我们写模板函数的时间,很大的方便了程序员。是c++11的典型进步。
点个关注吧,大家新年快乐。