windows首先安装rabbitmq 点击参考安装
1、环境介绍
Python 3.10.16
其他通过pip安装的版本(Django、pika、celery这几个必须要有最好版本一致)
amqp 5.3.1
asgiref 3.8.1
async-timeout 5.0.1
billiard 4.2.1
celery 5.4.0
click 8.1.7
click-didyoumean 0.3.1
click-plugins 1.1.1
click-repl 0.3.0
colorama 0.4.6
Django 4.2
dnspython 2.7.0
eventlet 0.38.2
greenlet 3.1.1
kombu 5.4.2
pika 1.3.2
pip 24.2
prompt_toolkit 3.0.48
python-dateutil 2.9.0.post0
redis 5.2.1
setuptools 75.1.0
six 1.17.0
sqlparse 0.5.3
typing_extensions 4.12.2
tzdata 2024.2
vine 5.1.0
wcwidth 0.2.13
wheel 0.44.02、创建Django 项目
py
django-admin startproject django_rabbitmq3、在setting最下边写上
py
# settings.py guest:guest 表示的是你安装好的rabbitmq的登录账号和密码
BROKER_URL = 'amqp://guest:guest@localhost:15672/'
CELERY_RESULT_BACKEND = 'rpc://'4.1 简单模式
4.1.1 在和setting同级的目录下创建一个叫consumer.py的消费者文件,其内容如下:
import pika
def callback(ch, method, properties, body):
print(f"[x] Received {body.decode()}")
def start_consuming():
# 创建与RabbitMQ的连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个队列
channel.queue_declare(queue='hello')
# 指定回调函数
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
print('[*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
if __name__ == "__main__":
start_consuming()4.1.2 在和setting同级的目录下创建一个叫producer.py的生产者文件,其内容如下:
import pika
def publish_message():
# message = request.GET.get('msg')
# 创建与RabbitMQ的连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个队列
channel.queue_declare(queue='hello')
# 发布消息
message = "Hello World!"
channel.basic_publish(exchange='', routing_key='hello', body=message)
print(f"[x] Sent '{message}'")
# 关闭连接
connection.close()
if __name__ == "__main__":
publish_message()4.1.3 先运行消费者代码(consumer.py)再运行生产者代码(producer.py)
先:python consumer.py
再: python producer.py4.1.4 运行结果如下:


4.2 消息持久化模式
4.2.1 在和setting同级的目录下创建一个叫recv_msg_safe.py的消费者文件,其内容如下:
py
import time
import pika
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(20)
print(" [x] Done")
# 下边这个就是标记消费完成了,下次在启动接受消息就不用从头开始了,即
# 手动确认消息消费完成 和auto_ack=False 搭配使用
ch.basic_ack(delivery_tag=method.delivery_tag) # method.delivery_tag就是一个标识符,方便找对人
def start_consuming():
# 创建与RabbitMQ的连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个队列
channel.queue_declare(queue='hello2', durable=True) # 若声明过,则换一个名字
# 指定回调函数
channel.basic_consume(queue='hello2',
on_message_callback=callback,
# auto_ack=True # 为true则不能持久话消息,即消费者关闭后下次收不到之前未收取的消息
auto_ack=False # 为False则下次依然从头开始收取消息,直到callback函数调用完成
)
print('[*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
if __name__ == "__main__":
start_consuming()4.2.2 在和setting同级的目录下创建一个叫send_msg_safe.py的生产者文件,其内容如下:
py
import pika
def publish_message():
# 创建与RabbitMQ的连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个队列 durable=True队列持久化
channel.queue_declare(queue='hello2', durable=True)
channel.basic_publish(exchange='',
routing_key='hello2',
body='Hello World!',
# 消息持久话用,主要用作宕机的时候,估计是写入本地硬盘了
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
# 关闭连接
connection.close()
if __name__ == "__main__":
publish_message()4.2.3 先运行消费者代码(recv_msg_safe.py)再运行生产者代码(send_msg_safe.py) 执行结果如下:
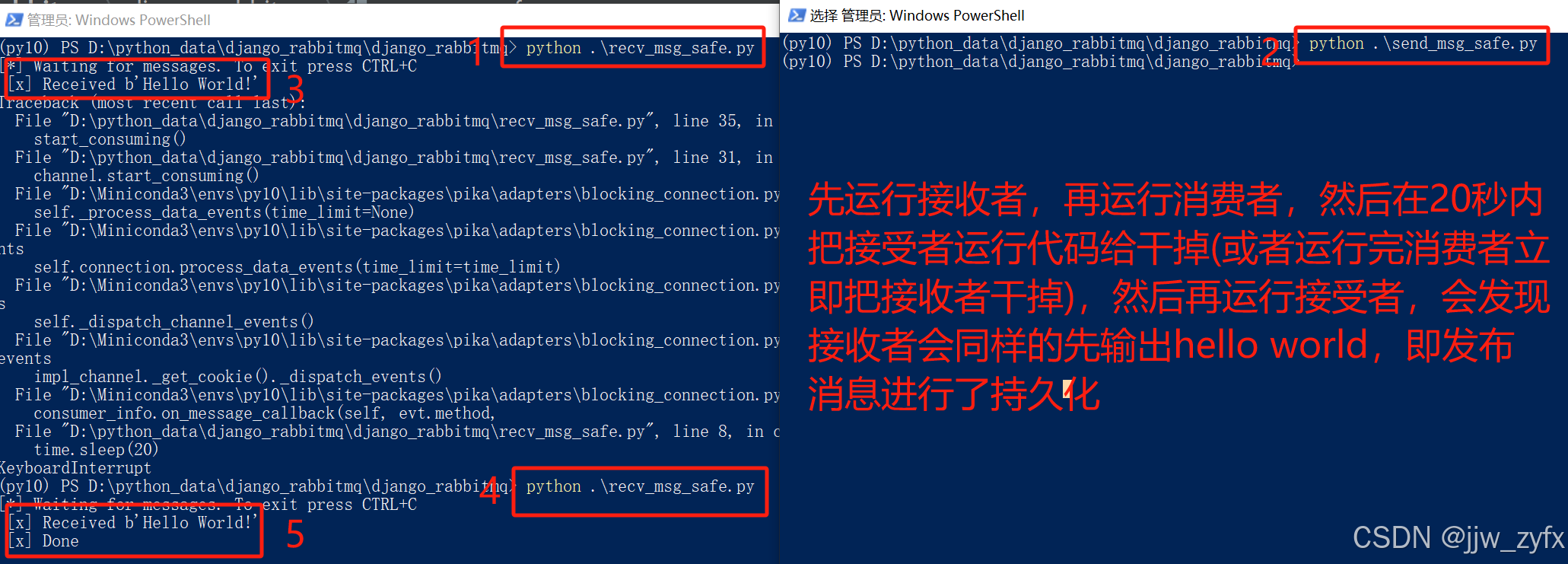
4.3 广播模式
4.3.1 在和setting同级的目录下创建一个叫fanout_receive.py的消费者文件,其内容如下:
py
# 广播模式
import pika
# credentials = pika.PlainCredentials('guest', 'guest')
# connection = pika.BlockingConnection(pika.ConnectionParameters(
# host='localhost', credentials=credentials))
# 在setting中如果不配置BROKER_URL和CELERY_RESULT_BACKEND的情况下请使用上边的代码
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 指定发送类型
# 必须能过queue来收消息
result = channel.queue_declare("", exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name) # 随机生成的Q,绑定到exchange上面。
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(on_message_callback=callback, queue=queue_name, auto_ack=True)
channel.start_consuming()4.3.2 在和setting同级的目录下创建一个叫fanout_send.py的生产者文件,其内容如下:
py
# 通过广播发消息
import pika
import sys
# credentials = pika.PlainCredentials('guest', 'guest')
# connection = pika.BlockingConnection(pika.ConnectionParameters(
# host='localhost', credentials=credentials))
# 在setting中如果不配置BROKER_URL和CELERY_RESULT_BACKEND的情况下请使用上边的代码
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', exchange_type='fanout') #发送消息类型为fanout,就是给所有人发消息
# 如果等于空,就输出hello world!
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='', # routing_key 转发到那个队列,因为是广播所以不用写了
body=message)
print(" [x] Sent %r" % message)
connection.close()4.3.3 先运行消费者代码(fanout_receive.py)再运行生产者代码(fanout_send.py) 执行结果如下:

4.4 组播模式
4.4.1 在和setting同级的目录下创建一个叫direct_recv.py的消费者文件,其内容如下:
py
import pika
import sys
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:] # 接收那些消息(指info,还是空),没写就报错
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) # 定义了三种接收消息方式info,warning,error
sys.exit(1)
for severity in severities: # [error info warning],循环severities
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) # 循环绑定关键字
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(on_message_callback=callback, queue=queue_name,)
channel.start_consuming()4.4.2 在和setting同级的目录下创建一个叫direct_send.py的生产者文件,其内容如下:
py
# 组播
import pika
import sys
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',exchange_type='direct') #指定类型
severity = sys.argv[1] if len(sys.argv) > 1 else 'info' #严重程序,级别;判定条件到底是info,还是空,后面接消息
message = ' '.join(sys.argv[2:]) or 'Hello World!' #消息
channel.basic_publish(exchange='direct_logs',
routing_key=severity, #绑定的是:error 指定关键字(哪些队列绑定了,这个级别,那些队列就可以收到这个消息)
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()4.4.3 先运行消费者代码(direct_recv.py)再运行生产者代码(direct_send.py) 执行结果如下:
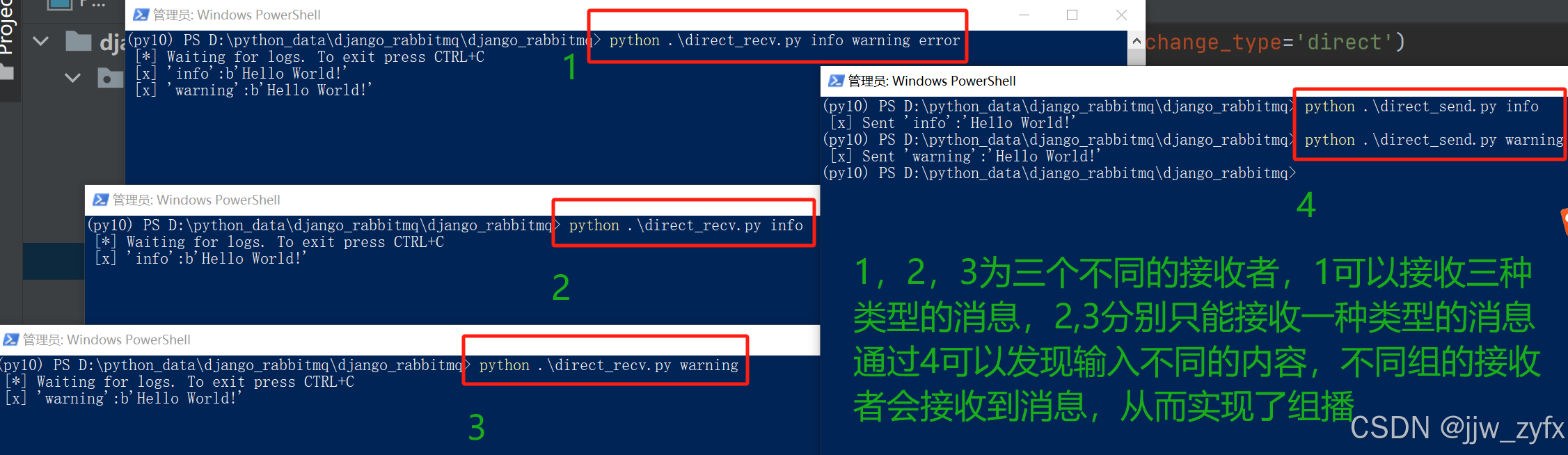
4.5 更细致的topic模式
4.5.1 在和setting同级的目录下创建一个叫topic_recv.py的消费者文件,其内容如下:
py
import pika
import sys
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',exchange_type='topic')
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
print("sys.argv[0]", sys.argv[0])
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(on_message_callback=callback,queue=queue_name)
channel.start_consuming()4.5.2 在和setting同级的目录下创建一个叫topic_send.py的生产者文件,其内容如下:
py
import pika
import sys
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',exchange_type='topic') #指定类型
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!' #消息
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()4.5.3 先运行消费者代码(topic_recv.py)再运行生产者代码(topic_send.py) 执行结果如下:
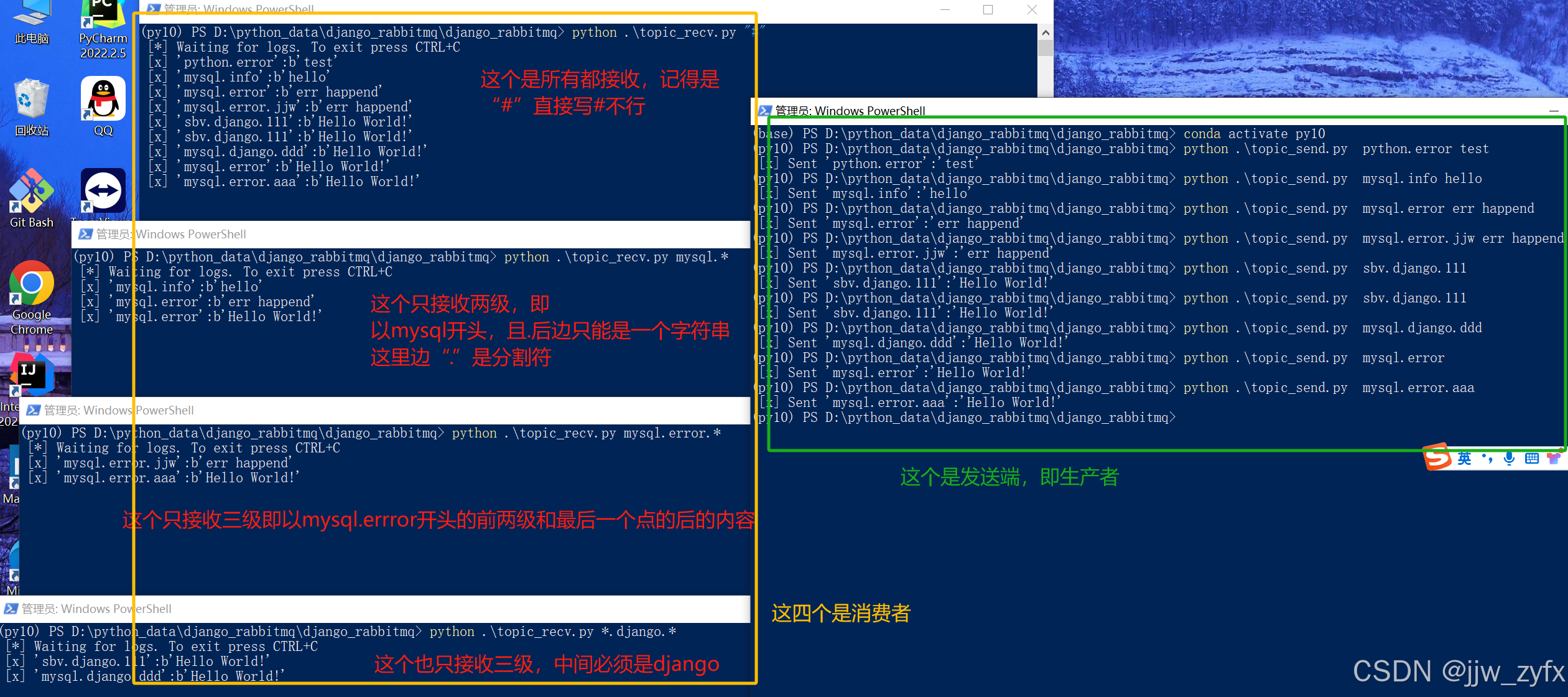
4.6 Remote procedure call (RPC) 双向模式
4.6.1 在和setting同级的目录下创建一个叫rpc_client.py的消费者文件,其内容如下:
py
import pika
import uuid
import time
# 斐波那契数列 前两个数相加依次排列
class FibonacciRpcClient(object):
def __init__(self):
# 赋值变量,一个循环值
self.response = None
# 链接远程
# self.connection = pika.BlockingConnection(pika.ConnectionParameters(
# host='localhost'))
credentials = pika.PlainCredentials('guest', 'guest')
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', credentials=credentials))
self.channel = self.connection.channel()
# 生成随机queue
result = self.channel.queue_declare("", exclusive=True)
# 随机取queue名字,发给消费端
self.callback_queue = result.method.queue
# self.on_response 回调函数:只要收到消息就调用这个函数。
# 声明收到消息后就 收queue=self.callback_queue内的消息 准备接受命令结果
self.channel.basic_consume(queue=self.callback_queue,
auto_ack=True, on_message_callback=self.on_response)
# 收到消息就调用
# ch 管道内存对象地址
# method 消息发给哪个queue
# body数据对象
def on_response(self, ch, method, props, body):
# 判断本机生成的ID 与 生产端发过来的ID是否相等
if self.corr_id == props.correlation_id:
# 将body值 赋值给self.response
self.response = body
def call(self, n):
# 随机一次唯一的字符串
self.corr_id = str(uuid.uuid4())
# routing_key='rpc_queue' 发一个消息到rpc_queue内
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
# 执行命令之后结果返回给self.callaback_queue这个队列中
reply_to=self.callback_queue,
# 生成UUID 发送给消费端
correlation_id=self.corr_id,),
# 发的消息,必须传入字符串,不能传数字
body=str(n))
# 没有数据就循环收
while self.response is None:
# 非阻塞版的start_consuming()
# 没有消息不阻塞 检查队列里有没有新消息,但不会阻塞
self.connection.process_data_events()
print("no msg...")
time.sleep(0.5)
return int(self.response)
# 实例化
fibonacci_rpc = FibonacciRpcClient()
response = fibonacci_rpc.call(5)
print(" [.] Got %r" % response)4.6.2 在和setting同级的目录下创建一个叫rpc_server.py的生产者文件,其内容如下:
py
#_*_coding:utf-8_*_
import pika
import time
# 链接socket
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost', credentials=credentials))
channel = connection.channel()
# 生成rpc queue 在这里声明的所以先启动这个
channel.queue_declare(queue='rpc_queue')
# 斐波那契数列
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
# 收到消息就调用
# ch 管道内存对象地址
# method 消息发给哪个queue
# props 返回给消费的返回参数
# body数据对象
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
# 调用斐波那契函数 传入结果
response = fib(n)
ch.basic_publish(exchange='',
# 生产端随机生成的queue
routing_key=props.reply_to,
# 获取UUID唯一 字符串数值
properties=pika.BasicProperties(correlation_id=props.correlation_id),
# 消息返回给生产端
body=str(response))
# 确保任务完成
# ch.basic_ack(delivery_tag = method.delivery_tag)
# 每次只处理一个任务
# channel.basic_qos(prefetch_count=1)
# rpc_queue收到消息:调用on_request回调函数
# queue='rpc_queue'从rpc内收
channel.basic_consume(queue="rpc_queue",
auto_ack=True,
on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
channel.start_consuming()4.6.3 先运行消费者代码(rpc_server.py)再运行生产者代码(rpc_client.py) 执行结果如下:
