Whisper 是论文中提出的用于自动语音识别 (ASR) 和语音翻译先进的模型通过大规模弱监督实现稳健语音识别 作者:Alec Radford 等人,来自 OpenAI。Whisper 在 >5M 小时的标记数据上进行了训练,表现出了很强的泛化能力 数据集和域。
模型地址: https://huggingface.co/openai/whisper-large-v3-turbo
本文将详细记录如何在本地部署 Whisper 模型,利用 CUDA 提升性能,并通过 Flask 提供一个简洁的 API 来实现语音转录功能。
1. 环境准备
在开始部署 Whisper 模型之前,首先需要准备一些基础环境,确保 GPU 可用并且所有依赖项都已正确安装。
1.1 安装 CUDA 和 GPU 驱动
由于 Whisper 在大规模模型训练和推理过程中对计算资源要求较高,使用 CUDA 和 GPU 可以大大加速模型的加载和推理过程。
- 安装 NVIDIA GPU 驱动:确保你已经安装了适用于你 GPU 的最新驱动。
- 安装 CUDA :Whisper 支持 CUDA 加速,你需要安装正确版本的 CUDA。你可以参考 NVIDIA 官网 根据系统类型进行安装。
安装完成后,可以通过以下命令验证 CUDA 是否正常工作:
bash
nvcc --version如果输出显示 CUDA 版本信息,则表明 CUDA 已成功安装。
1.2 创建 Python 虚拟环境
为了避免依赖冲突,我们建议创建一个新的 Python 虚拟环境。可以通过 conda 或 venv 来创建虚拟环境,这里以 conda 为例:
bash
conda create -n whisper_cuda_env python=3.9 conda activate whisper_cuda_env 1.3 安装 PyTorch 和 Whisper
接下来,安装 PyTorch 并确保启用了 CUDA 支持。你可以根据你的 CUDA 版本选择正确的 PyTorch 安装命令,以下为常用命令:
bash
# 安装 PyTorch,假设 CUDA 版本为 11.3
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113安装 PyTorch 后,再安装 Whisper 库:
pip install git+https://github.com/openai/whisper.git 完成后,可以通过以下命令验证 Whisper 是否安装成功:
import whisper model = whisper.load_model("base").cuda() 1.4 安装其他依赖
Whisper 依赖一些音频处理库,如 ffmpeg,用于音频文件的加载和预处理。你可以通过以下命令安装它:
# Windows 下安装
ffmpeg conda install -c conda-forge ffmpeg
# 或者使用 pip 安装
pip install ffmpeg-python 确保 ffmpeg 能够正确执行,你可以通过以下命令进行验证:
fmpeg -version 2. 使用 Whisper 进行语音转录
2.1 加载和使用 Whisper 模型
一旦所有依赖安装完成,接下来就可以加载 Whisper 模型并进行音频转录了。以下是加载并使用 Whisper 模型进行音频转录的代码:
python
import whisper # 加载模型(使用 GPU)
model = whisper.load_model("base").cuda() # 转录示例音频
result = model.transcribe("example.mp3", language="zh") print(result["text"]) 2.2 解释转录结果
Whisper 的 transcribe 方法返回一个包含多项信息的字典。主要字段包括:
text: 转录的文本内容。segments: 音频的分段信息,每个段落包含转录文本、时间戳等信息。
例如,如果 example.mp3 是一段中文音频,返回的结果可能如下所示:
python
{ "text": "坐品三号我常常遗憾我家门前那块丑石", "segments": [ { "start": 0.0, "end": 2.56, "text": "坐品三号" }, { "start": 2.56, "end": 7.76, "text": "我常常遗憾我家门前那块丑石" } ] }2.3 处理转录结果
有时我们只关心转录后的文本内容而不需要详细的段落信息。为了简化响应,可以从字典中提取 text 字段,返回简洁的转录结果。
以下是修改后的代码,简化返回内容,只返回转录的文本:
python
from flask import Flask, request, jsonify
import whisper
app = Flask(__name__)
model = whisper.load_model("base").cuda()
@app.route("/transcribe", methods=["POST"])
def transcribe():
audio_file = request.files["file"]
audio_path = f"/{audio_file.filename}"
audio_file.save(audio_path)
# 转录音频
result = model.transcribe(audio_path, language="zh")
# 只返回转录的文本部分
return jsonify({"text": result["text"]})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)2.4 使用 curl 测试 API
你可以使用 curl 来发送音频文件并获取转录结果:
bash
curl -X POST -F "file=@example.mp3" http://127.0.0.1:5000/transcribe返回的结果将是一个包含转录文本的简洁 JSON 格式:
{ "text": "坐品三号我常常遗憾我家门前那块丑石" } 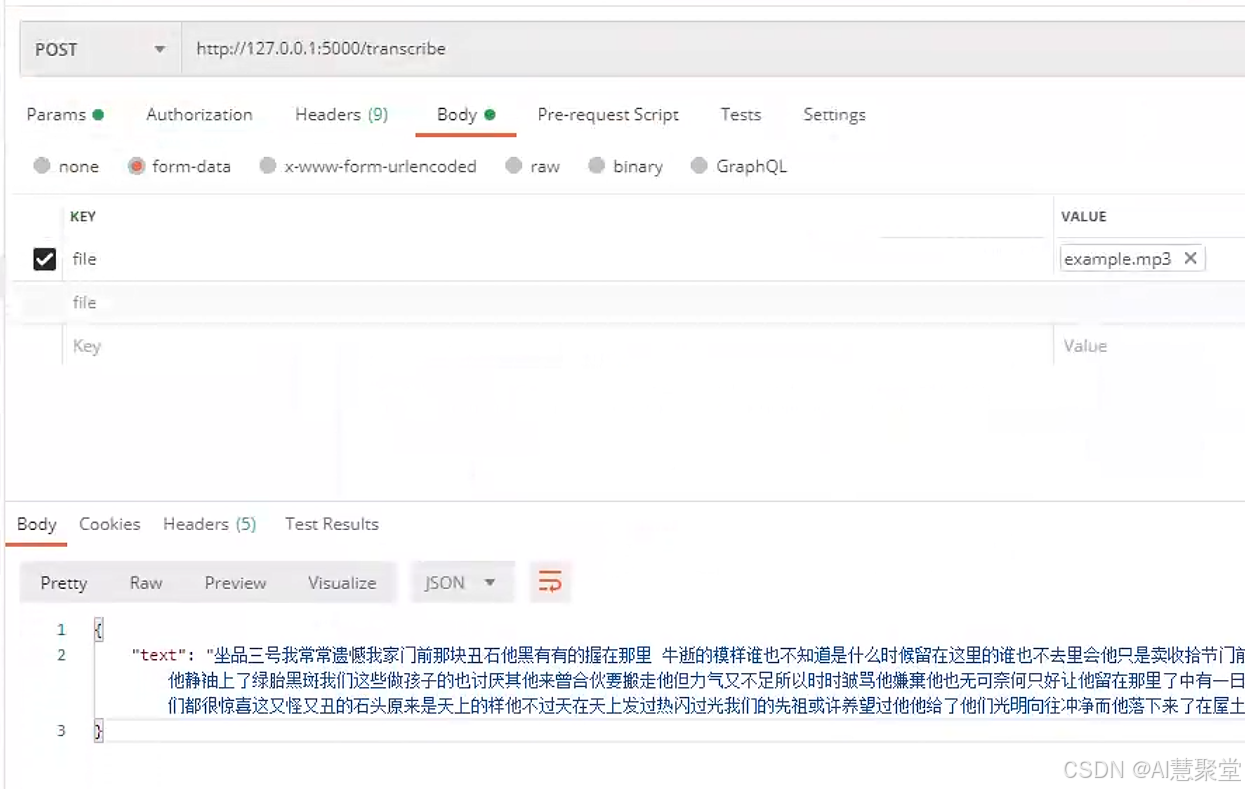
2.5 验证 CUDA 加速
Whisper 在启用了 CUDA 的 GPU 上运行时,推理速度会显著加快。你可以通过以下代码来验证 Whisper 是否成功使用了 GPU:
python
import torch print(torch.cuda.is_available()) # 输出 True 表示 CUDA 可用如果返回 True,则表明 GPU 已成功启用。
3. 总结
通过以上步骤,你已经成功地在 本地部署了 Whisper 模型,并利用 CUDA 加速推理过程。使用 Flask 构建了一个简单的 API,使得音频文件的转录变得非常方便。整个部署过程包括了环境准备、依赖安装、模型加载、音频处理、API 构建等步骤。
部署 Whisper 模型并不复杂,但需要一定的硬件支持,尤其是在处理大型音频数据时,CUDA 和 GPU 能够提供显著的性能提升。希望本文能够帮助你顺利部署并使用 Whisper 进行语音转录。如果遇到任何问题,欢迎继续提问。
附彩蛋:
一个编写标书的的AI助手:
