0 写在前面
Stable Diffusion 是当前最火热的图像生成模型之一,目前已经广泛应用于艺术创作、游戏开发、设计模拟等领域,因其开源生态和易于使用而受到创作者的广泛关注,相比 Midjourney 而言,其最大的优势是完全免费,且拥有庞大的社区资源。
如果需要本地部署 Stable Diffusion,首选 Stable Diffusion Webui。不过本地部署
对设备硬件要求还是比较高的,通常需要至少 4G 显存,有关如何在 Windows 上使用,社区已经有了非常不错的一键启动脚本。
如果需要一个稳定的服务,还是建议将其部署到云服务器上。
本文主要记录一下如何在 Linux 上部署 Stable Diffusion Webui,在把所有的坑都踩了一遍之后,希望对有类似需求的小伙伴有所帮助。
1 Stable Diffusion
1.1 什么是 Stable Diffusion
Stable Diffusion 是一种生成式模型,所谓生成式模型也就是能够生成和训练集分布非常相似的输出结果,主流的生成式模型包含如下几类:
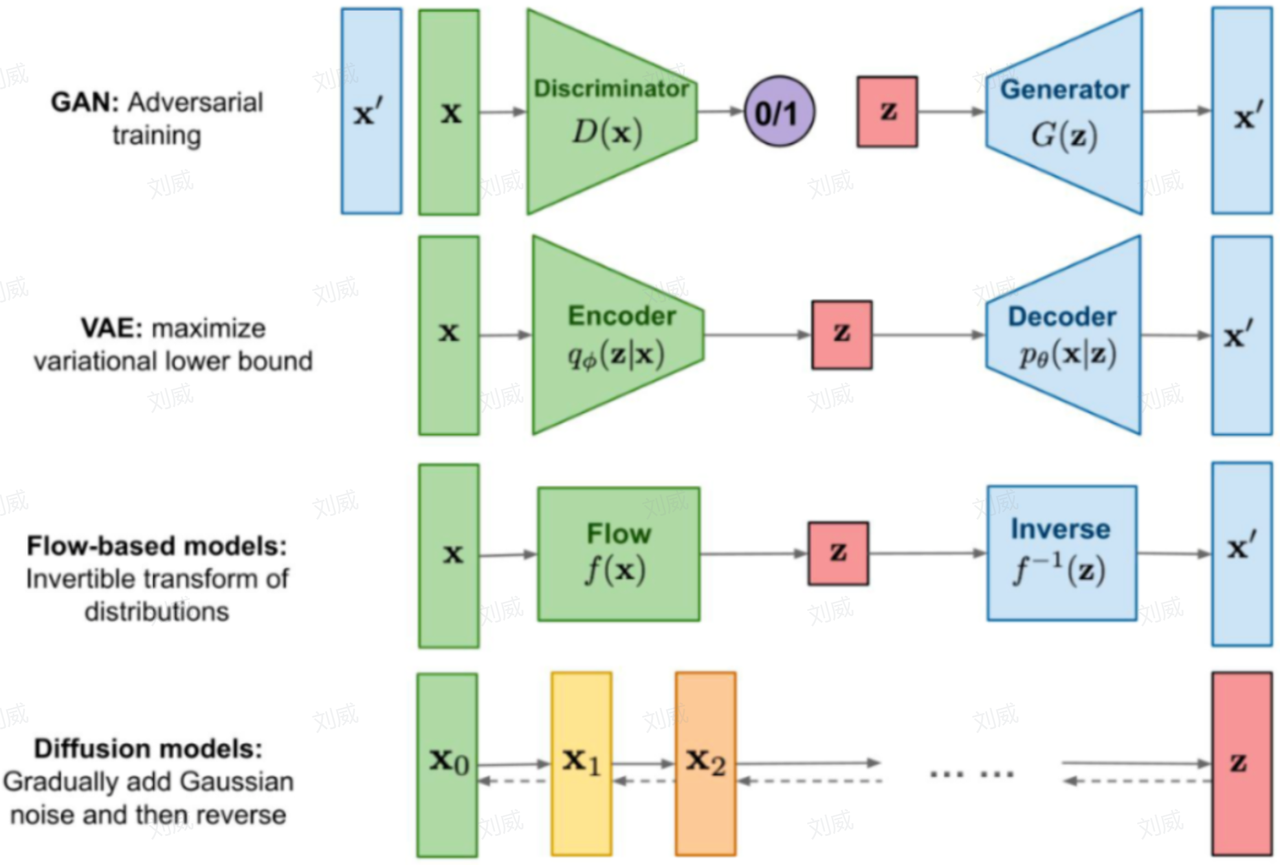
Stable Diffusion 是 Diffusion Model 的改进版,完整的Stable Diffusion网络结构应该包含三个部分:
- 自动编码器:
- 将图像从像素空间(Pixel Space)压缩到潜在空间(Latent Space)
- 将潜在表示转换成最终图像
- 条件生成器:
- 生成去噪过程中依赖的条件(Conditioning),条件包括文字和图像,对文字而言,最常见的是CLIP text encoder ,用于编码文字信息,控制生成对应文字描述的图像。
- 噪声估计模型UNet:
- 针对潜在空间的图片做扩散(Diffusion Process):添加噪声
- 编码用户输入的 prompt
- 预测噪声,然后依据「去噪条件」去噪,生成图片的潜在表示

1.2 什么是 LoRA
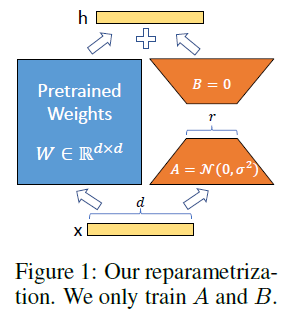
LoRA,即Low-Rank Adaptation,是一种轻量级的大模型微调方法,文本生成模型GPT 和 图像生成模型Stable-Diffusion,都可以采用LoRA 进行轻量级微调。它通过在模型的特定部分引入低秩结构来进行微调,从而减少了计算资源的需求。LoRA训练可以在保持模型原有性能的同时,对模型进行个性化调整,使其适应特定的应用场景。
LoRA的思想很简单,在原始模型旁边增加一个旁路,做一个降维再升维的操作。训练的时候固定原始模型的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与原始模型的参数叠加。
2 Stable Diffusion WebUI
Stable Diffusion WebUI 为 Stable Diffusion 模型定制了友好的网页界面,基于 Gradio 实现,它让用户可以轻松地访问和使用 Stable Diffusion 的图像生成能力。有关 Windows 下如何使用,建议直接使用 B 站 @秋葉aaaki 的免费启动器和安装包。
这里主要介绍下 Linux 下如何安装和部署。
2.1 WebUI 下载和安装
推荐直接从webui源码安装,打开终端,从 github 上下载:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git一键启动脚本,会默认配置好项目环境,并安装好项目依赖包:
./webui.sh不过通常会出现各种各种的问题,主要原因是国内网络问题,其中最频繁遇到的问题有:
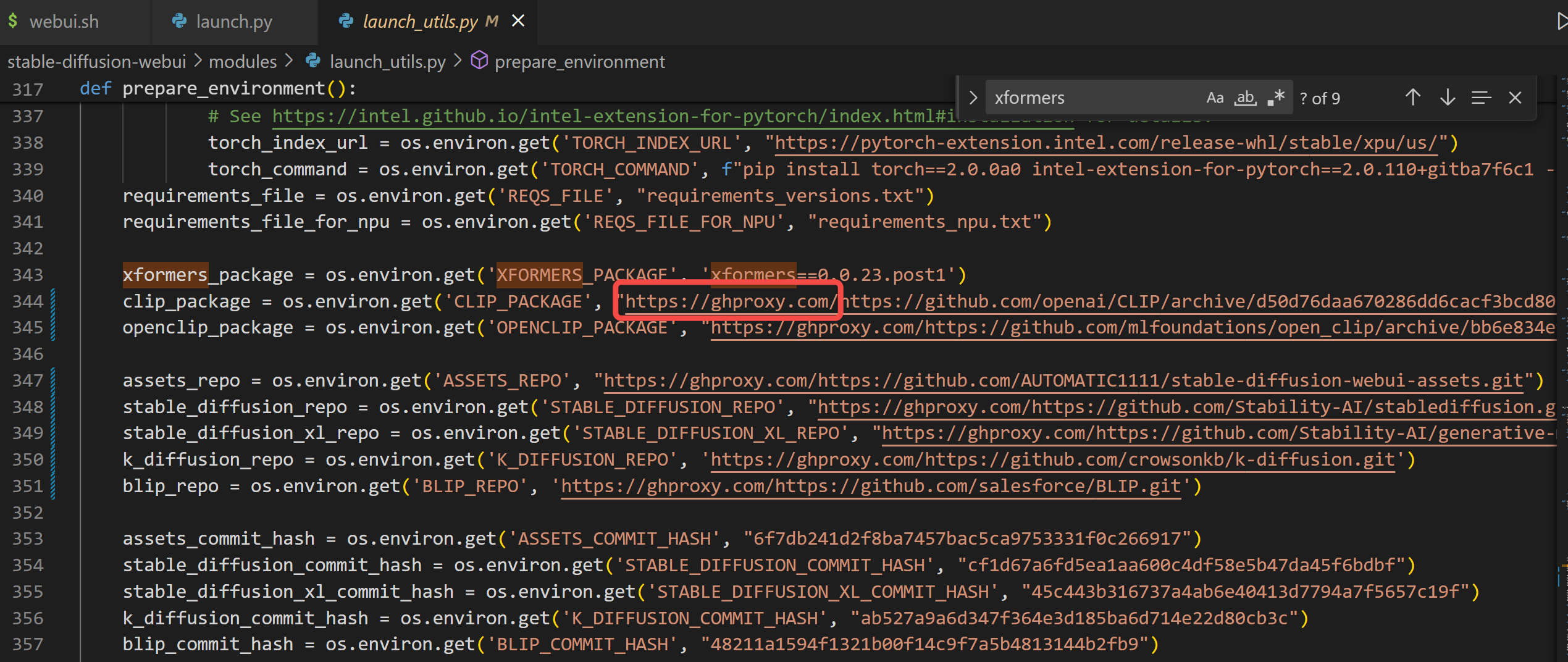
- 依赖库安装失败
主要是因为访问 github 失败,在 launch_utils.py 中找到prepare_environment()函数,将其中涉及到 github 仓库的依赖,全部添加 https://ghproxy.com/ 镜像,如下图所示:
- 下载依赖的模型失败
主要是因为访问 HuggingFace 网站失败,Stable Diffusion 依赖的很多模型权重文件托管在 HuggingFace 网站上,默认会自动从 HuggingFace 网站上下载到本地,因此网络访问失败到导致模型加载不成功,这里推荐使用国内的镜像网站:https://hf-mirror.com,只需要在终端中临时添加环境变量,再重新启动webui.sh就可以了:
export HF_ENDPOINT=https://hf-mirror.com # 引入镜像地址,否则模型下载不成功
./webui.sh终端出现如下提示,说明启动成功,这时你在本地浏览器打开http://127.0.0.1:7860,即可看到 WebUI 界面。

如果你是部署在云端,如果有公网 IP,需要将127.0.0.1修改为公网 IP 地址,如果是部署在内网或者 Linux 虚拟机上,则可以通过端口映射实现在本地浏览器访问,关于如何进行端口隐射,可以查看笔者之前的分享如何在 Windows 上实现和 Linux 子系统的端口映射。
浏览器打开 WebUI 界面成功后,此时是没有加载任何模型权重的,这里我们需要先搞清楚常见的模型类型。
2.2 模型类型介绍
Stable Diffusion 中用到的模型类型,可以粗略分为:大模型(基座模型,底模) 和 用于微调的小模型。
2.2.1 大模型(基座模型,底模)
大模型特指标准的 latent-diffusion 模型,拥有完整的 TextEncoder、U-Net 和 VAE。官方提供的大模型包括 sd1.5 sd2 sdxl等等,而社区提供的大模型都是在此基础上微调得到的。值得一提的是,如果发现输出的图片发灰,通常就是因为这里的 VAE 未成功使用,是由于部分合并模型导致的 VAE 不可用,需要手动添加 VAE 使用。
模型的格式,也就是后缀名,你会看到有很多种,其中 pt pth ckpt都是pytorch保存的模型格式,safetensors 是没有安全风险的文件格式,但权重内容和前面是完全一样的。
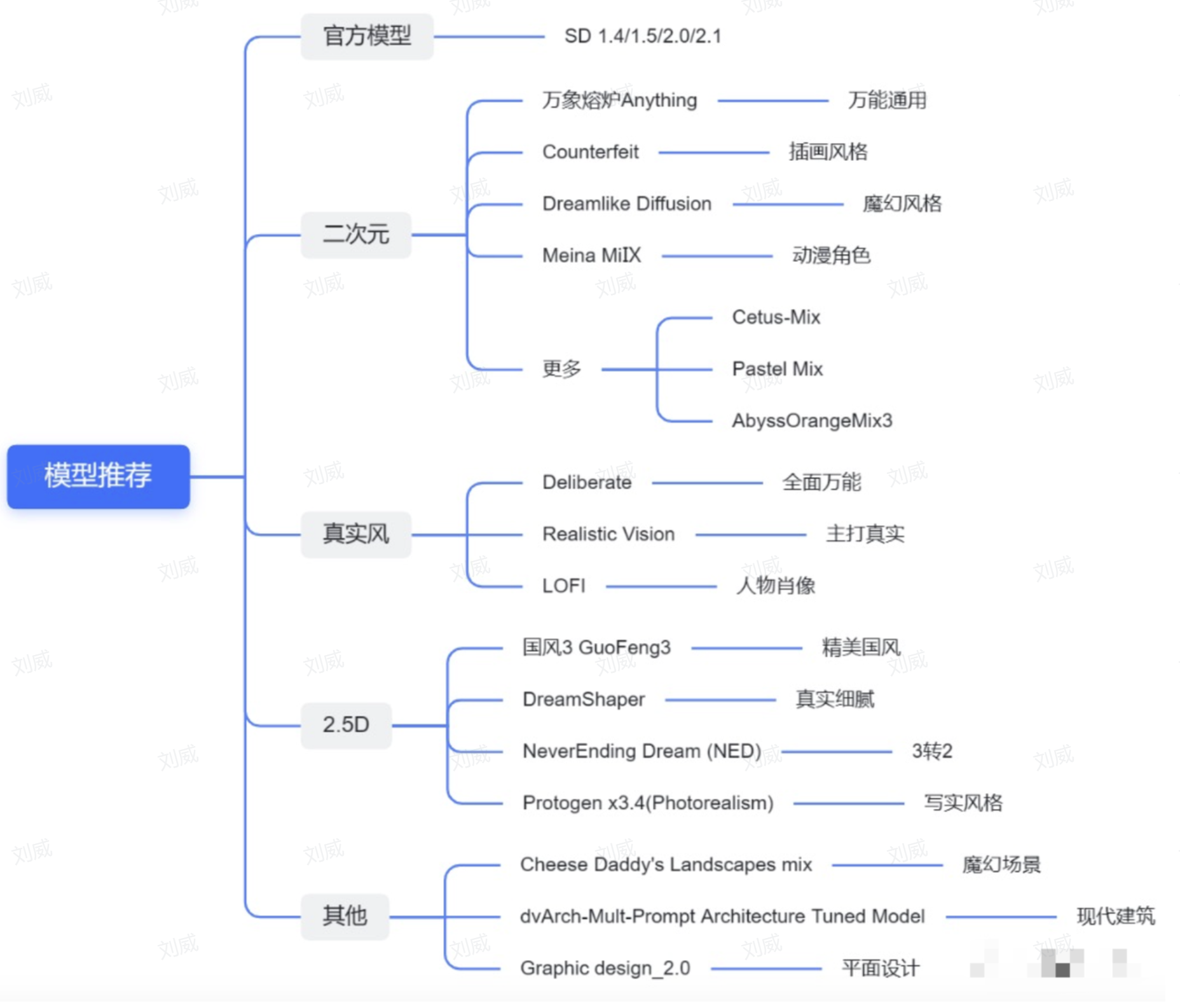
大模型的存放路径在:models/stable-diffusion,一般大小在 2G-7G 左右。目前比较常用的大模型有:
- 官方模型:sd1.5 sd2 sdxl等
- 二次元模型:anything等
- 真实系模型:LOFI等
- 2.5D 模型:国风3等
2.2.2 小模型
用于微调的小模型通常分为以下几种:
- Lora:放在models/Lora。大小一般在 100MB 级别。点击一个模型以后会向提示词列表添加类似这么一个tag, lora:模型名:权重 ,也可以直接用这个tag调用lora模型。
- Embedding (Textual inversion) :放在models/embedding。常见格式为 pt、png图片、webp图片。大小一般在 KB 级别。生成图片的时候需要带上 文件名 作为 tag。
- VAE: 放在models/VAE。
- Hypernetwork:一般没人用了
2.3 模型权重获取
模型权重的获取有多种方式,比较推荐的有如下几种:
2.3.1 开源社区下载
目前托管 SD 模型的开源社区有很多,这里主要推荐两个:
- 一个是国外的:
https://civitai.com/,国内访问需要借助梯子。点击导航栏中的Models可以查看所有模型,可以关键字搜索,也可以使用右侧的Filters只查找需要的模型:Checkpoint: 特指大模型,而 LoRA 则是社区开发者微调的小模型,下文笔者也将带领大家微调自己的 LORA 小模型。
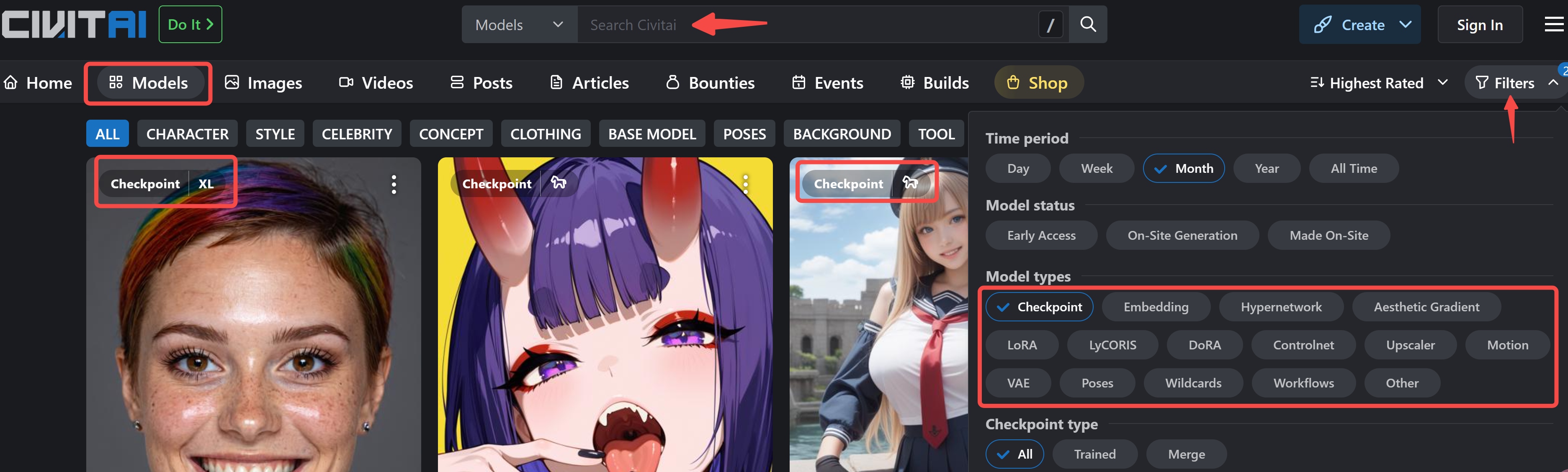
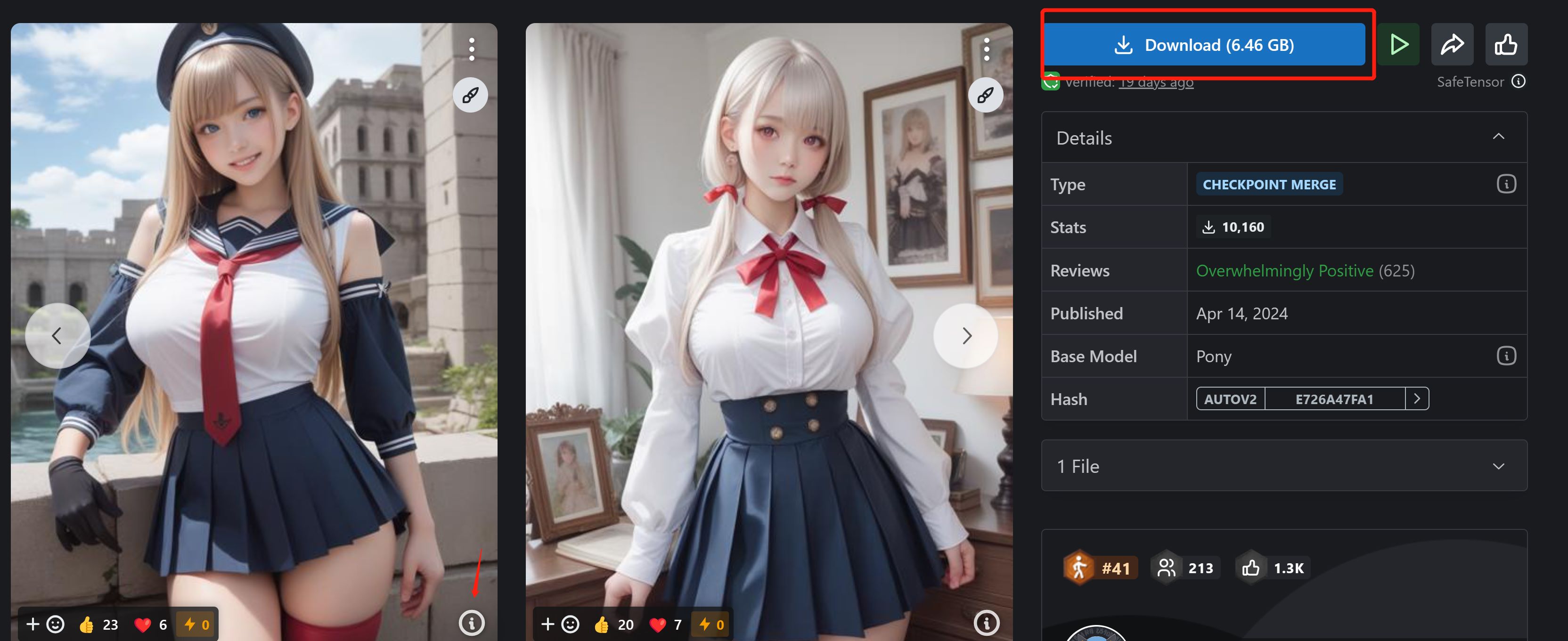
找到感兴趣的模型进去以后,右侧可以看到模型类型等信息,图片下方的感叹号可以查看提示词,右上角可以直接点击 下载,或者右键选择复制链接,然后在终端 wget 下载。
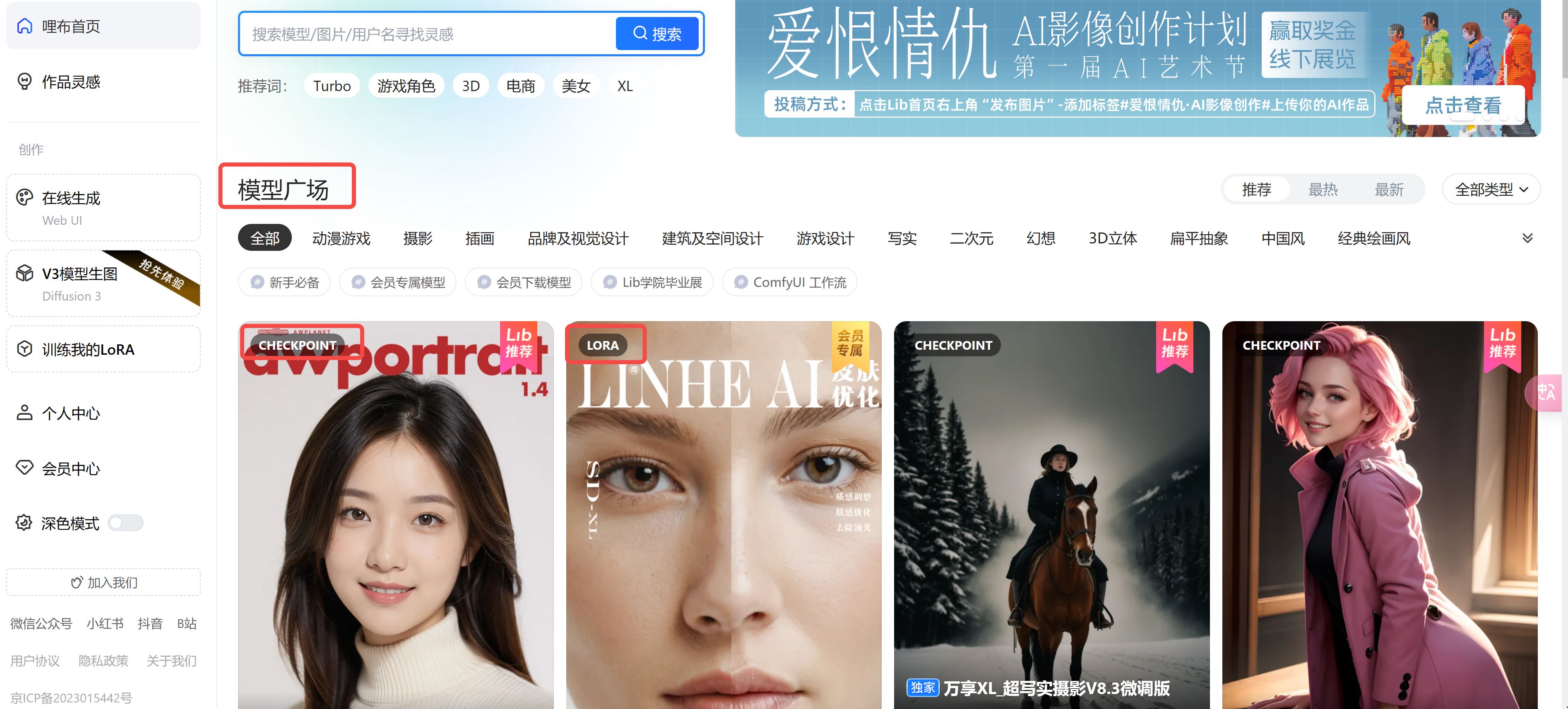
- 一个是国内的:
https://www.liblib.art/,不需要梯子就可以访问,基本也可以满足绝大部分人的需求,和 civitai 的用法基本一致,就不再赘述了。
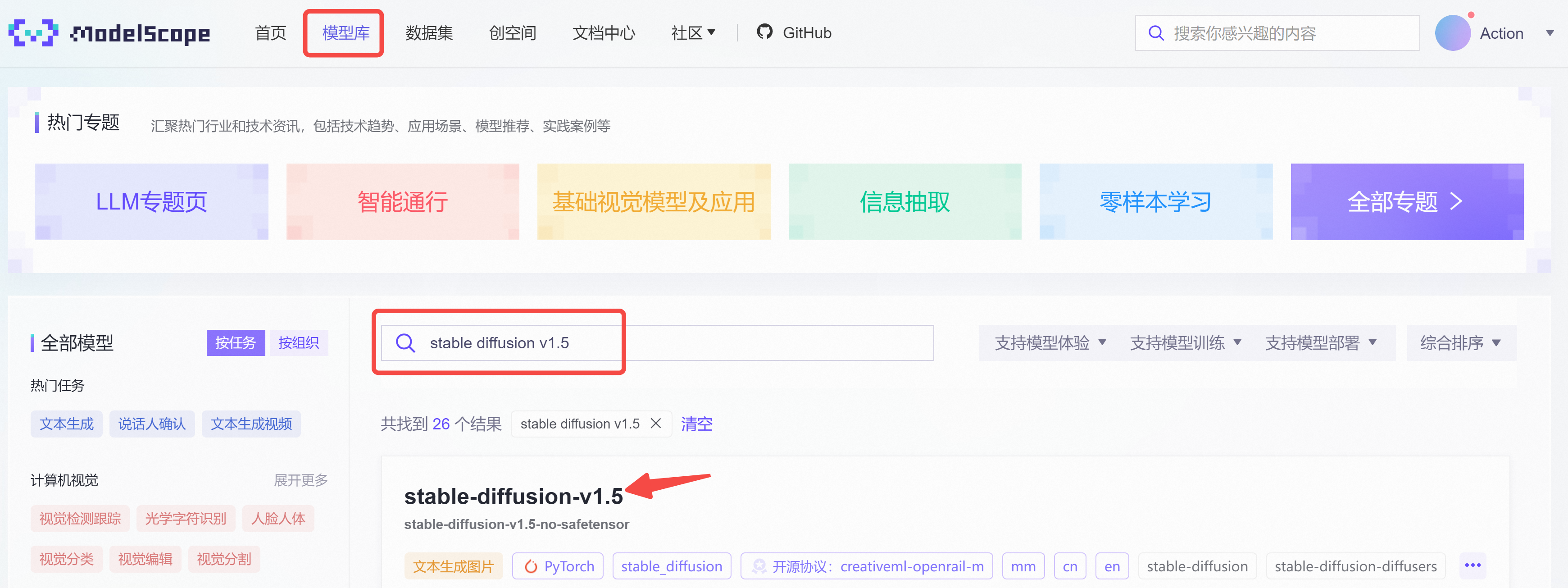
2.3.2 Model Scope(国内)
Model Scope 模型库由阿里提供,对标国外的 Hugging Face,托管了各类机器学习模型,比如我们需要下载 stable-diffusion-v1.5,可以直接在模型库搜索:
点击进去后,找到模型文件,选择v1-5-pruned-emaonly.ckpt。

右上角有 下载,右键选择复制链接,然后在终端输入:
# -O 代表存放的模型名称
wget -O v1-5-pruned-emaonly.ckpt 'https://modelscope.cn/api/v1/models/AI-ModelScope/stable-diffusion-v
1.5-no-safetensor/repo?Revision=master&FilePath=v1-5-pruned-emaonly.ckpt'注意:终端中一定要对复制的链接加双引号,否则不会成功下载。
2.3.3 Hugging Face(国外)
Hugging Face 国内访问需要梯子,如果能够访问的话,和 Model Scope 的用法基本一致,这里就不在赘述了。
2.4 WebUI 使用
2.4.1 模型权重准备
模型权重下载好后,需要将模型放到对应的文件夹中,这里最常用的是:大模型 和 微调的LoRA 模型,分别放在 models/stable-diffusion 和 models/Lora下,启动后,WebUI 会自动从这几个文件夹中找到对应的模型。
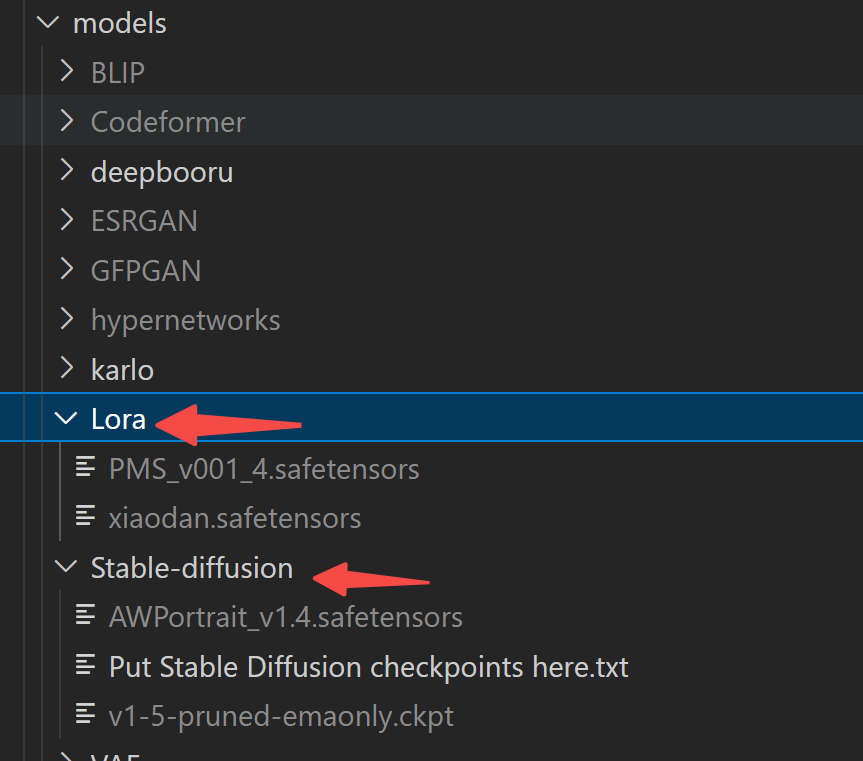
2.4.2 前端界面使用
启动成功后,选择对应的大模型,开始愉快地画图吧!关于界面上这些功能以及更多插件,笔者再更一篇文章详细聊聊。

3 LoRA模型训练实战
大模型无法实现风格和人物的定制化,我们可以通过下载开源社区的 LoRA 模型实现想要的风格,那么开源社区的 LoRA 模型是怎么炼出来的?
这里笔者打算以一个简单的案例带领大家训练自己的 LoRA 模型。
3.1 下载 lora-scripts
打开终端,git 下载 lora-scripts 仓库:
git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts注意:要加上--recurse-submodules,因为该仓库还依赖了几个子模块仓库,如果忘记了加 --recurse-submodules, 可以继续使用如下命令重新下载子模块仓库:
git submodule update --init --recursive接下来,一键执行环境准备:
install.bash3.2 准备训练数据集
首先,需要搜集几张带有特定风格的图片数据,保存在同一个文件夹下。

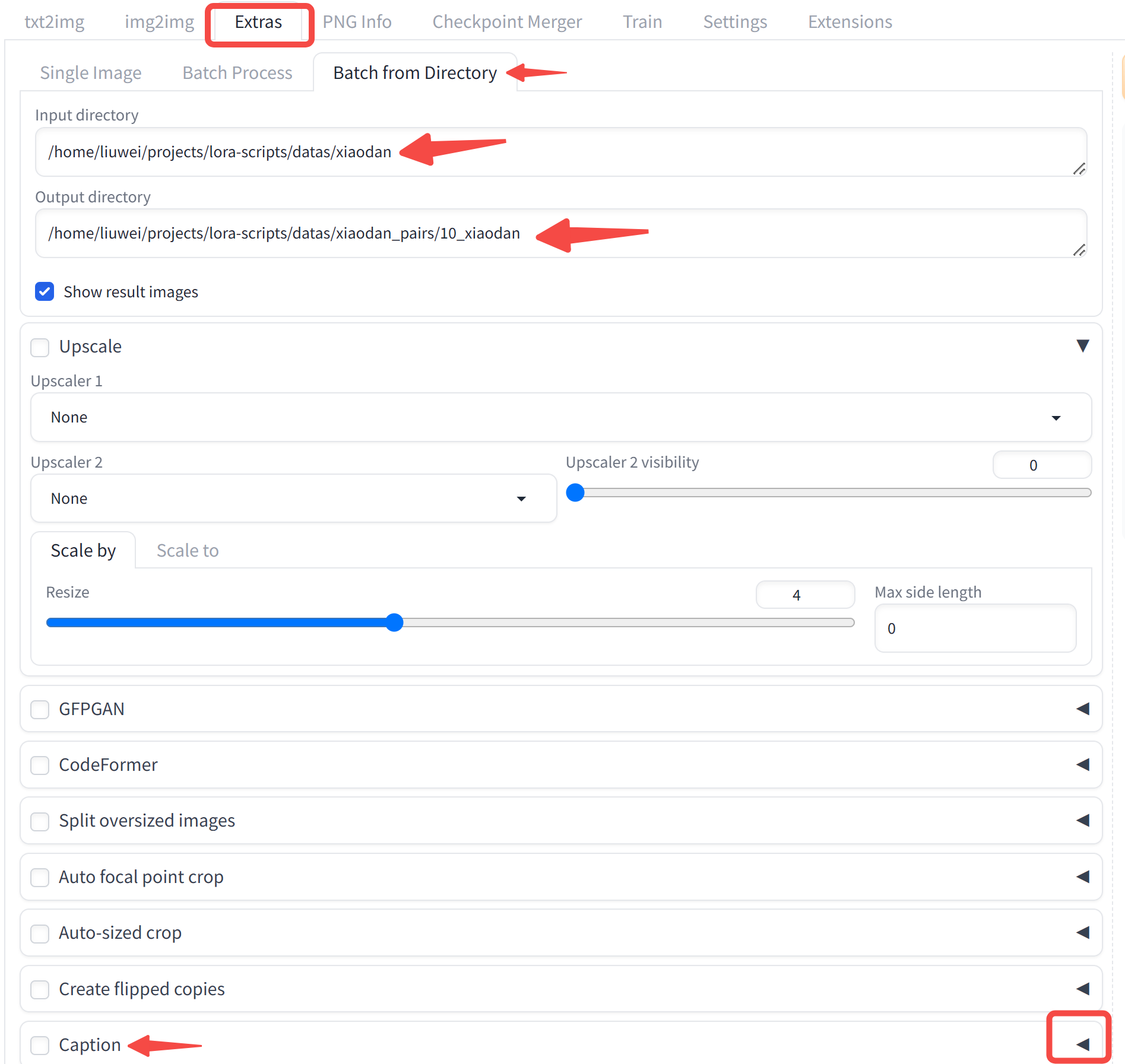
其次,需要为每张图像生成对应的描述,这一步可以通过 WebUI 实现,找到 Extras 的 tab,选择 Batch from Directory ,将你的文件夹名称输入,同时指定输出文件夹,注意we文件夹名称遵循如下格式: xxx/10_xxx,子目录需要以数字开头。在最下方找到 Caption 选项,选择 BLIP 图片描述生成模型,右上方点击 Generate,即可自动生成对应的图片描述。
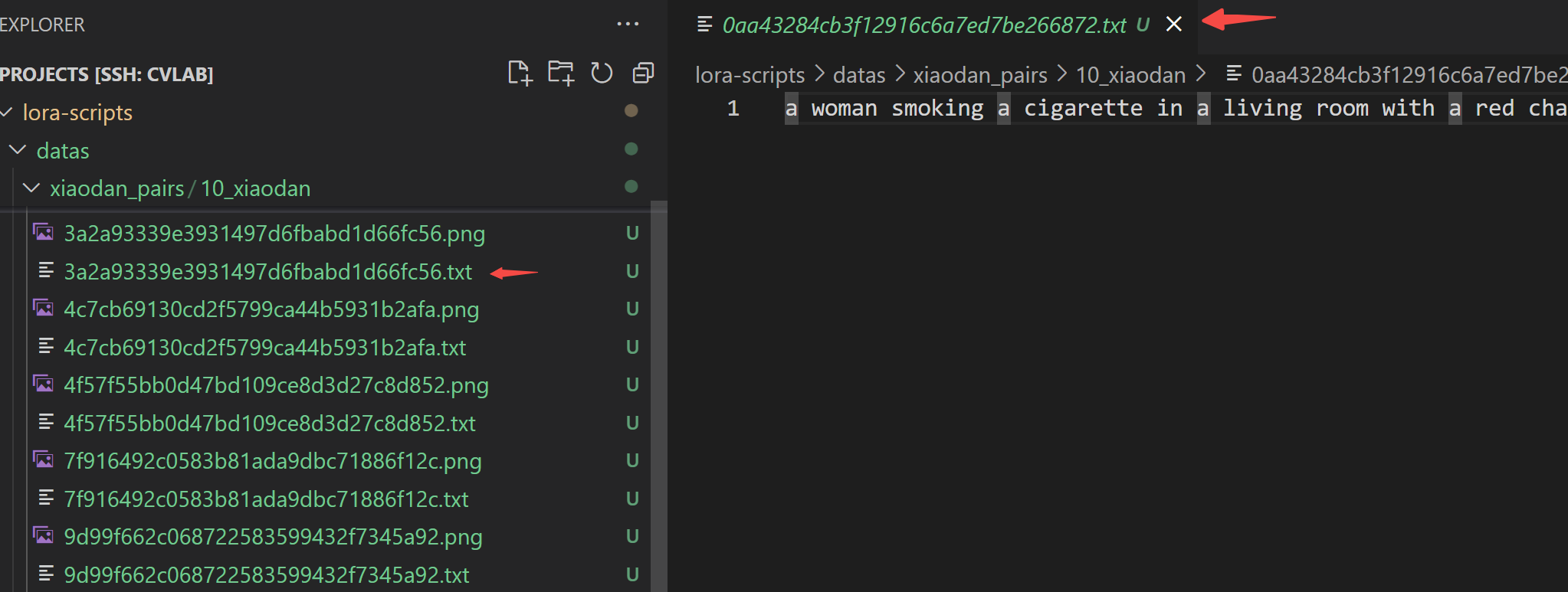
生成后的文件夹如下图所示,每张图片对应一个文本描述:
3.3 LoRA训练
首先需要修改训练脚本,打开 train.sh,主要修改以下几个地方:
- pretrained_model # base model path | 底模路径
- train_data_dir # 训练集路径,特别需要注意,如下图所示
- max_train_epoches # 训练轮数

完成后,一键启动训练:
bash train.sh生成的模型文件默认保存在outputs/文件夹下,把它 copy 到 stable-diffusion-webui的 models/Lora下,就可以直接使用这个你训好的 LoRA 模型了。
4 总结
至此,我们完成了在Linux系统上部署Stable Diffusion WebUI和进行LoRA模型训练的全过程。希望这篇文章能让你在部署Stable Diffusion WebUI的路上少踩一些坑。
感谢关注~