Whisper[1]是OpenAI发布的一个开源自动语音识别(ASR)系统,它于 2022 年发布,目的是提供一个强大、通用、易于使用的语音转文本工具。
自从Whisper发布以后,市面上就涌现出大量"视频生成字幕"工具,但大部分工具都是要付费的,而且能在Windows和Linux下使用的较少。其实这部分工具就是将Whisper包装一层以后使用,我们完全可以直接在本地电脑上运行Whisper模型,借助自己显卡的力量来为视频生成字幕。
这篇文章介绍一下我的操作步骤,并发布一个为自己写的小工具,可以实现生成字幕的完整过程。
0x01 下载Whisper.cpp
OpenAI发布的原版Whisper是基于PyTorch的,安装和使用比较麻烦,对于普通用户也不太友好。后面Georgi Gerganov[2]将其移植到ggml框架下,让推理过程可以更容易运行在多种平台下,比如Windows、Mac OS、Linux、iOS、Android、树莓派等,这就是Whisper.cpp[3]。
不过,官方仓库release中,只能下载到苹果生态下的依赖库(XCFramework包),主要是用于App开发。如果我们想要更方便的使用,比如获得一个可执行文件,需要自己编译官方给出的example:https://github.com/ggml-org/whisper.cpp/tree/master/examples/cli
如果你和我一样是Windows,不太方便自己编译。也可以来到官方仓库的Github Action中,找到CI这个workflow,选择任意一个master分支下且完全跑成功的测试:
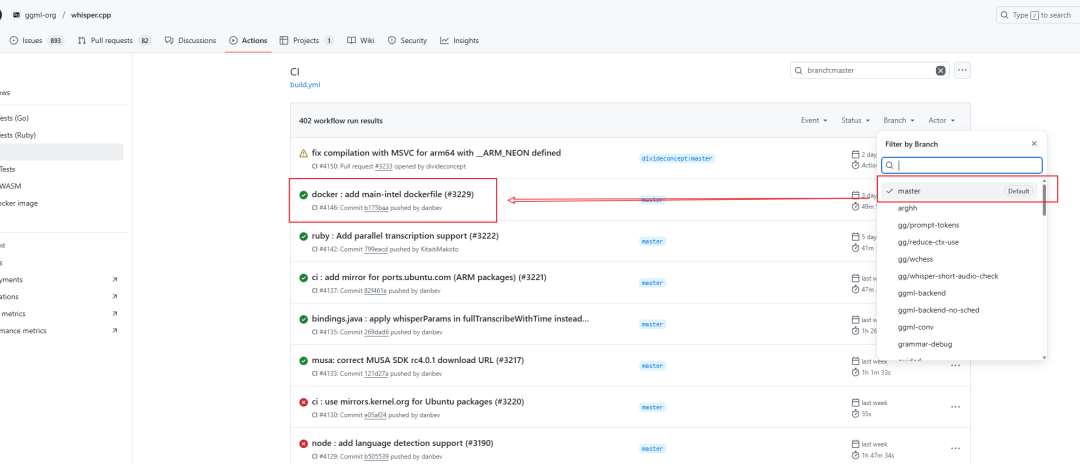
点进去即可看到各个平台的运行日志。选择"windows-cublas (Release, x64, ON, ON, 12.2.0)",这个编译增加了对CUDA的支持:
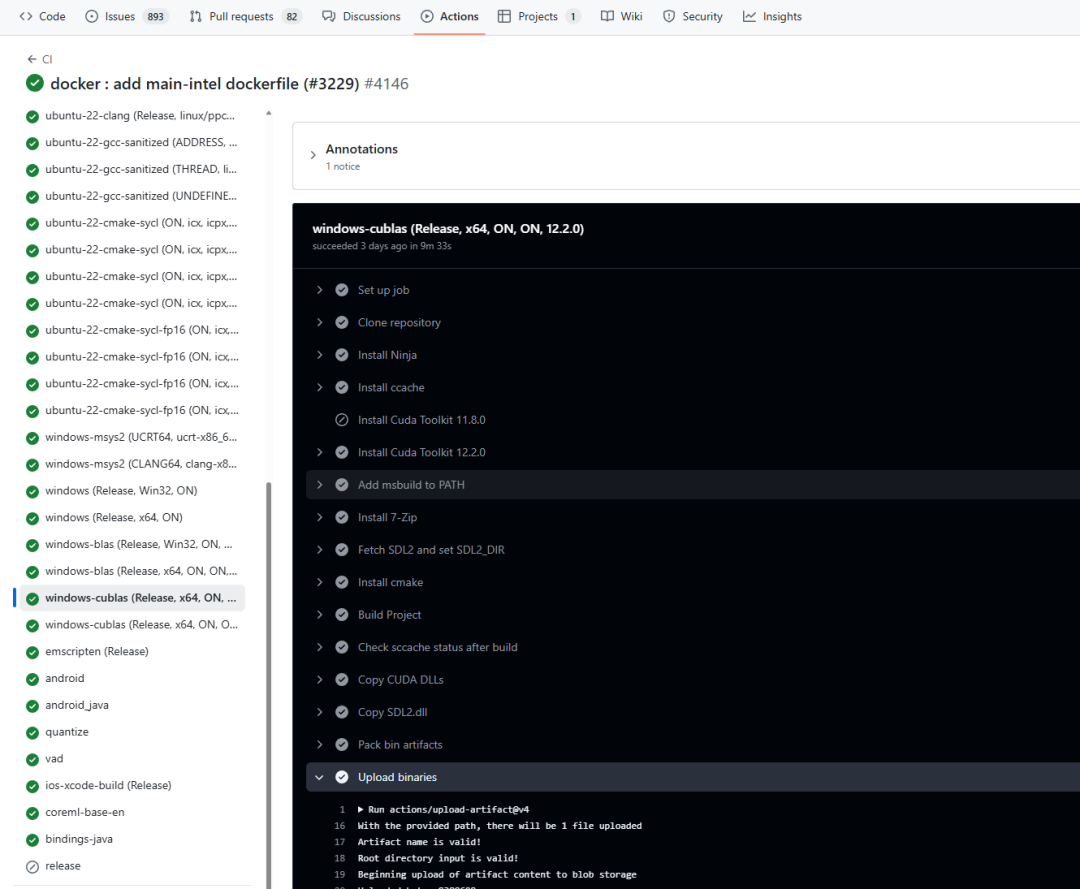
展开"Upload binaries"这一栏,最下来就可以看到编译好的artifact,下载即可:
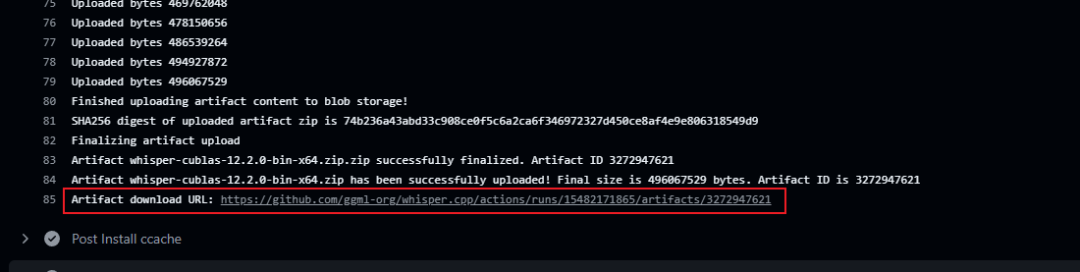
其中就包含whisper-cli.exe这个命令行程序。
0x02 下载模型文件
Whisper 是基于 Transformer 架构训练的端到端语音识别模型,所以我们在本地运行Whisper.cpp时,还需要下载模型文件。
Whisper模型在这里下载:https://huggingface.co/ggerganov/whisper.cpp/tree/main,我们可以看到,这里面包含很多个模型文件,但大体就分为下面几种版本:
| 模型版本 | 参数数量 | 大小 | 延迟 | 准确率 |
|---|---|---|---|---|
| tiny | ~39M | 75 MB | 最快 | 最低 |
| base | ~74M | 142 MB | 很快 | 一般 |
| small | ~244M | 466 MB | 中等 | 中等 |
| medium | ~769M | 1.5 GB | 较慢 | 较高 |
| large | ~1.5B | 2.9 GB | 最慢 | 最高 |
我的显卡是NVIDIA GeForce GTX 1660 SUPER,已经属于比较老的显卡了,所以我选择下载"ggml-medium-q8_0.bin"这个模型,在medium的基础上再进行8 bit量化,缩小了体积和内存占用,但效果测试下来还不错。
Whisper和常见的大语言模型都是基于Transformer架构,其注意力机制在处理长序列时会出现注意力稀释的问题,这反应在Whisper中就是,当需要识别的语音太长时,前半部分的效果还可以,但后面可能就会变差。
所以,除了下载whisper模型外,最好再下载一个VAD模型。VAD(Voice Activity Detection,语音活动检测)模型用于识别音频中何时有人在说话、何时是静音或非语音内容,这可以在转录时自动分段,将一些非语音的音频片段去除,来增加Whisper的准确率。
"Silero" 是由 Silero.ai[4] 团队开源的语音系列工具,其中Silero VAD就是一个用来识别人类语音的模型,在ggml-org/whisper-vad[5]下载到ggml格式的模型文件,可以直接用于Whisper.cpp中。
0x03 为视频生成字幕
一切就绪后,我们就可以为视频生成字幕了。
首先,Whisper的定位是"语音转文本",所以我们需要先将视频变成音频,这一步使用FFmpeg就可以了:
go
ffmpeg -i /path/to/video.mp4 -af aresample=async=1 -ar 16000 -ac 1 -c:a pcm_s16le -loglevel fatal /path/to/audio.wav这其中需要注意的是-af aresample=async=1这个选项。默认情况下,ffmpeg转换音频时会丢弃音轨中出现的错误帧,这可能导致某些视频文件生成的音频比视频短,字幕不同步。增加这个选项后,ffmpeg会自动填充这些错误帧,避免类似问题。
其他的参数基本都是固定的,因为whisper.cpp暂时只支持采样率为16000的单声道wav音频。
生成wav文件后,即可调用whisper-cli命令行文件来生成字幕了:
go
whisper-cli.exe -l auto -osrt --vad --vad-threshold 0.3 --vad-model ggml-silero-v5.1.2.bin -m ggml-medium-q8_0.bin file.wav这里面涉及的参数如下:
-
•
-l auto指定语言,默认情况下会自动识别视频语言,如果很明确视频语言是什么,手工指定效果会更好: -
-
•
en英语 -
•
ja日语
-
-
•
-osrt输出成srt格式 -
•
--vad --vad-threshold 0.3 --vad-min-speech-duration-ms 1000 --vad-model ggml-silero-v5.1.2.bin开启VAD -
-
•
--vad开启VAD功能 -
•
--vad-threshold 0.3VAD的阈值是0.3。这个值越低,将有更多的音频会被识别成"语音片段";这个值越高,则声音越有可能被识别为环境音而忽略。默认是0.5。 -
•
--vad-model file指定VAD的模型文件路径
-
-
•
-m file指定whisper.cpp模型文件的路径
执行whisper-cli时,它会自动识别到电脑上安装的显卡,当我们使用显卡来生成字幕时,在任务管理器中可以看到GPU的占用率:
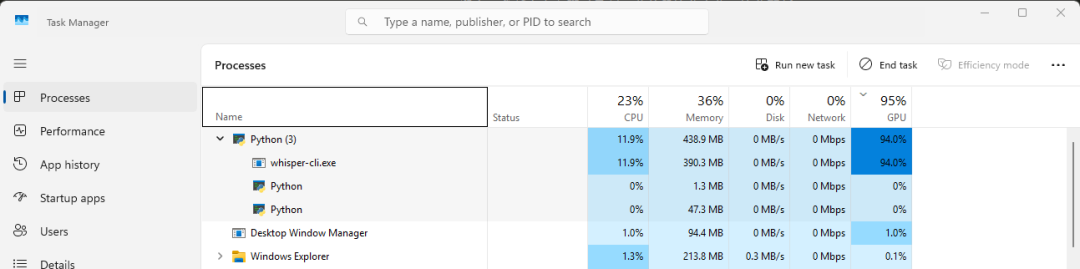
可见,正常情况下GPU应该是跑满的。如果你运行whisper-cli后,发现GPU没有跑满,那说明有可能程序没有正确识别到GPU,降级成CPU在运行,这样速度会变慢很多。(也有可能是下载的whisper-cli没有增加CUDA支持)
0x04 字幕翻译
Whisper-cli生成的SRT文件是对应视频的语言,如果我们不懂这个语言,还需要进行翻译。
其实Whisper-cli本身是提供了一个--translate选项,但其只支持将内容翻译成英文,不能自定义语言,而且其效果也没有特别好。更好的方案是使用现在的大语言模型进行翻译,我这里就推荐Google Gemini,其在保证功能强大的基础上,还能做到非常低廉的价格,使用起来也很方便。
来到AI Studio[6],可以看到Gemini 2.5 Flash,即使开启Thinking模式,每百万Token的价格只有0.15/3.5美元:
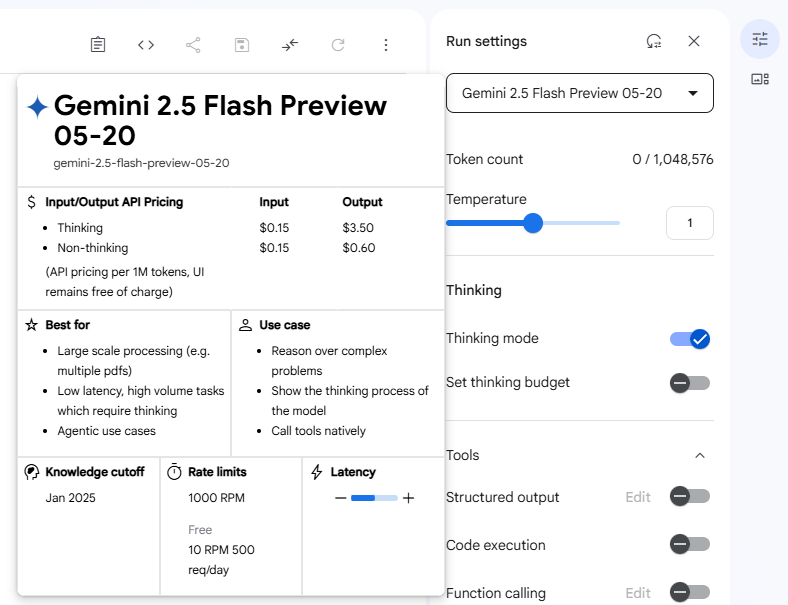
经过我的测试,翻译一部电影,大概的花费也就是0.1美元。
0x05 All in One脚本:v2srt
我写了一个小工具,支持在本地的Windows机器下对一个视频进行中文字幕的生成:https://github.com/phith0n/v2srt。它的工作就是将上面说到的命令整合到一起,变成一个一键工具。
比如,我为最近在看的量化交易教学视频生成了中文字幕:
go
python v2srt.py -wm D:\program\Whisper.cpp\models\ggml-medium-q8_0.bin -gm gemini-2.5-flash-preview-05-20 -vm D:\program\Whisper.cpp\models\ggml-silero-v5.1.2.bin -gk [gemini_key] -l en "K:\Learning\Art Of Trading - Pinescript Mastery\1. Introduction\4. Intro to Programming.mp4"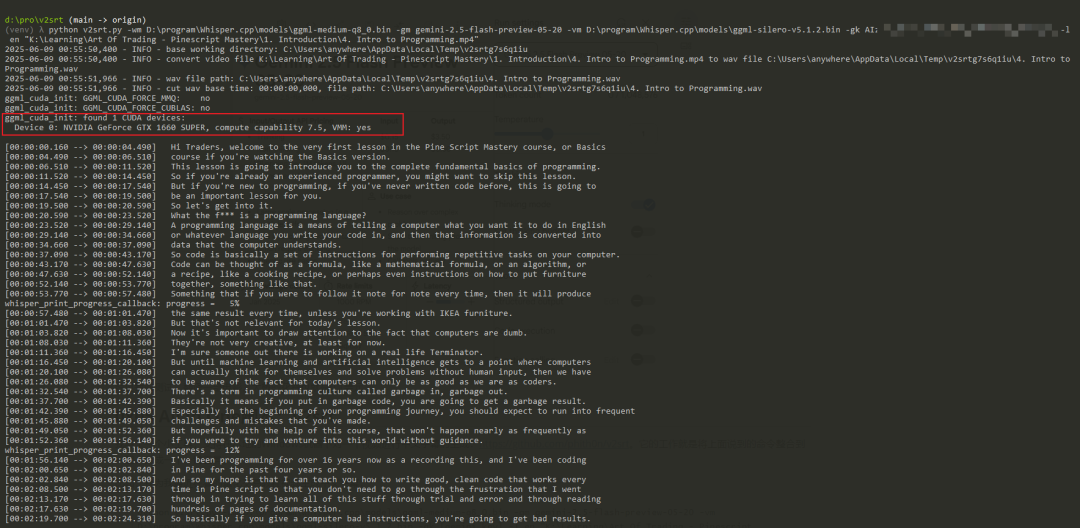
其准确识别到了我的显卡,并使用GPU运行字幕生成工作。
然后自动使用Gemini API翻译:
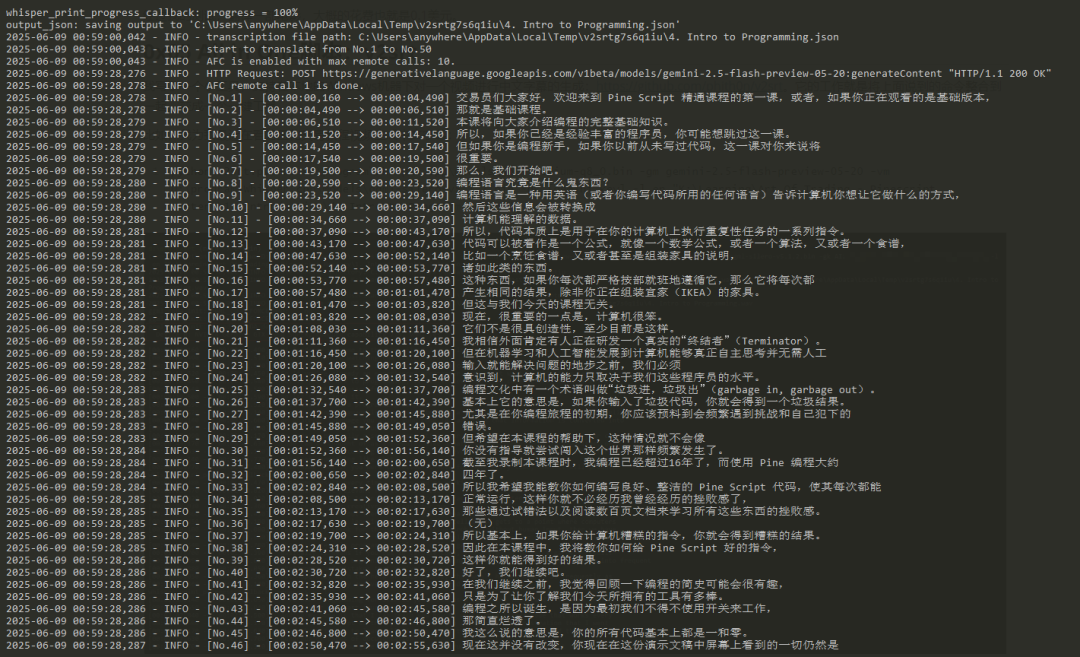
生成好的SRT字幕文件,会自动在播放视频时加载:

于是,我成功使用自己的计算机+一块老旧的GTX 1660s显卡完成了一个本地AI"字幕组",有兴趣的同学可以试用一下。
引用链接
[1] Whisper:https://github.com/openai/whisper
[2]Georgi Gerganov:https://github.com/ggerganov
[3]whisper.cpp:https://github.com/ggml-org/whisper.cpp
[4]Silero.ai:https://github.com/snakers4/silero-vad
[5]ggml-org/whisper-vad:https://huggingface.co/ggml-org/whisper-vad/tree/main
[6]AI Studio:https://aistudio.google.com/