电脑系统:win10专业版
不能访问需要魔法上网
安装tesseract
在GitHub上下载:tesseract下载地址
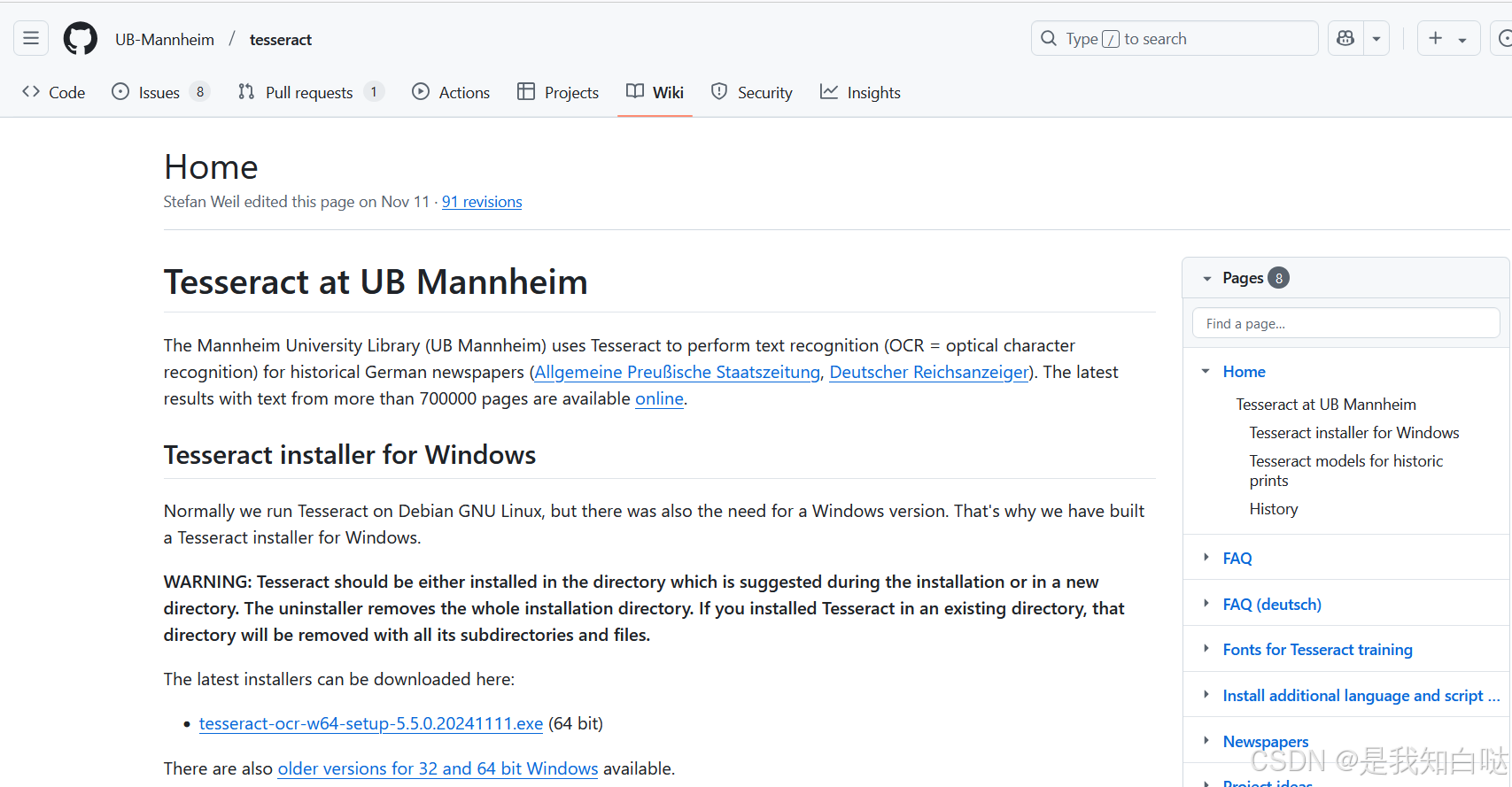
找到自己电脑版本下载
双击安装,一路next,除了这一步
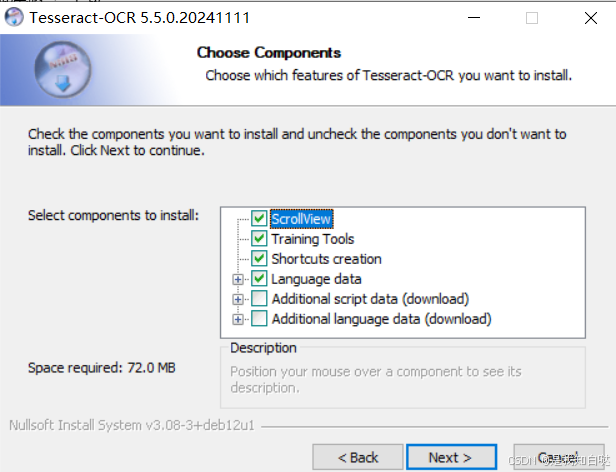
第三个加号点开,把带Chinese的都勾选
安装完成后配置环境,Win R输入sysdm.cpl
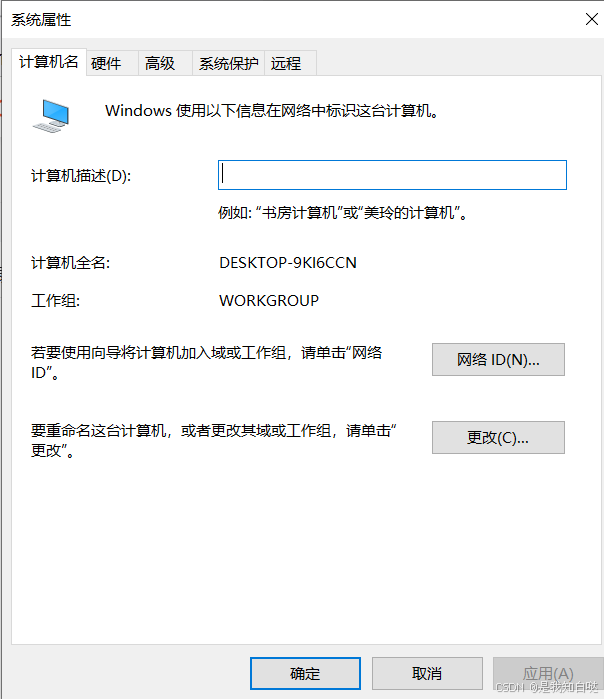
依次点击【高级】 【 环境变量】 【系统变量的Path】 【新建】
输入你的tesseract安装路径
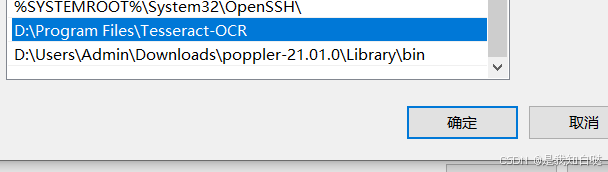
点击确认后返回
安装python库
python
pip install pytesseract pdf2image Pillow 
安装poppler
在GitHub上下载:poppler下载地址
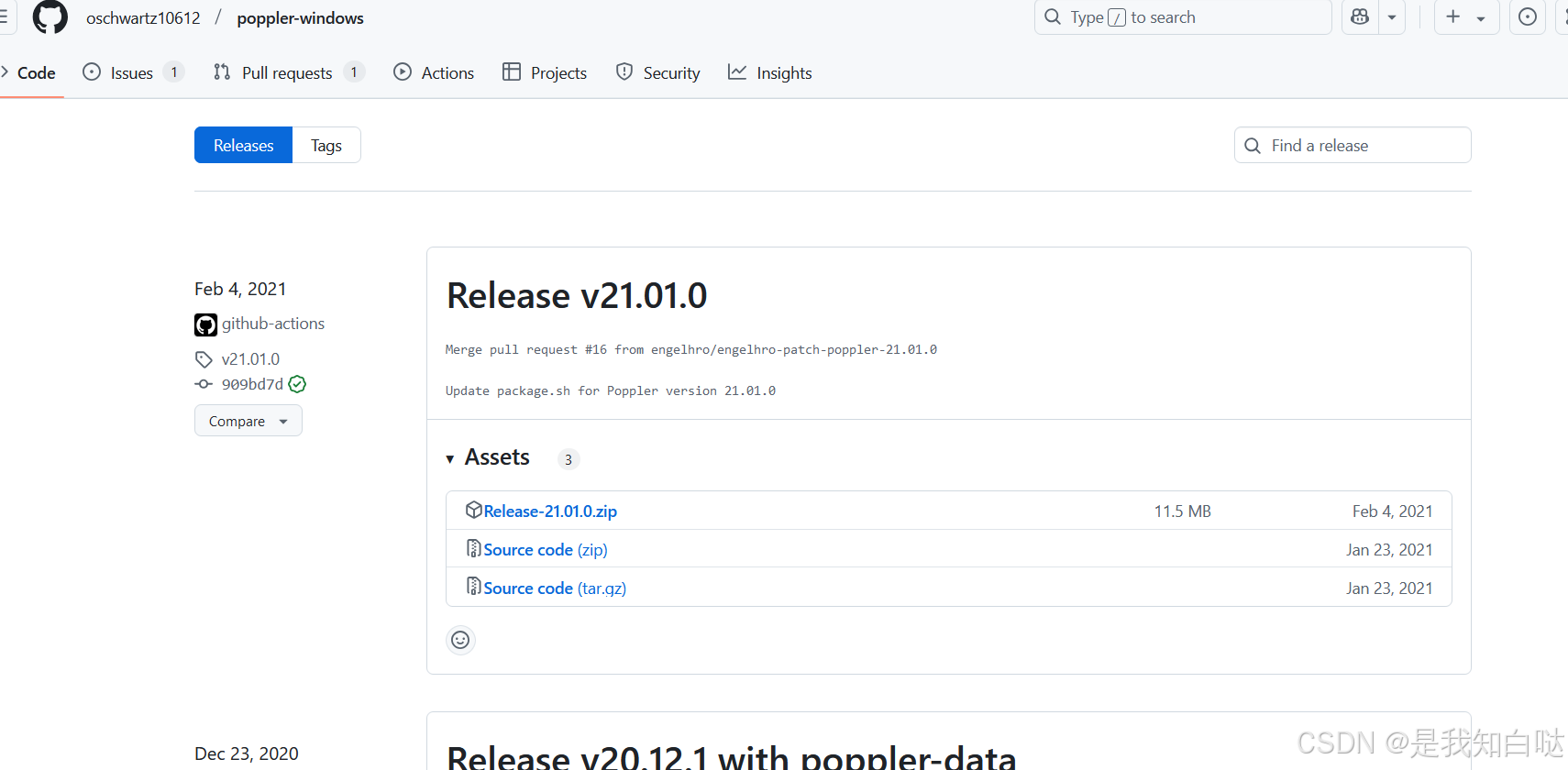
 下载到本地后解压缩,找到bin文件夹
下载到本地后解压缩,找到bin文件夹
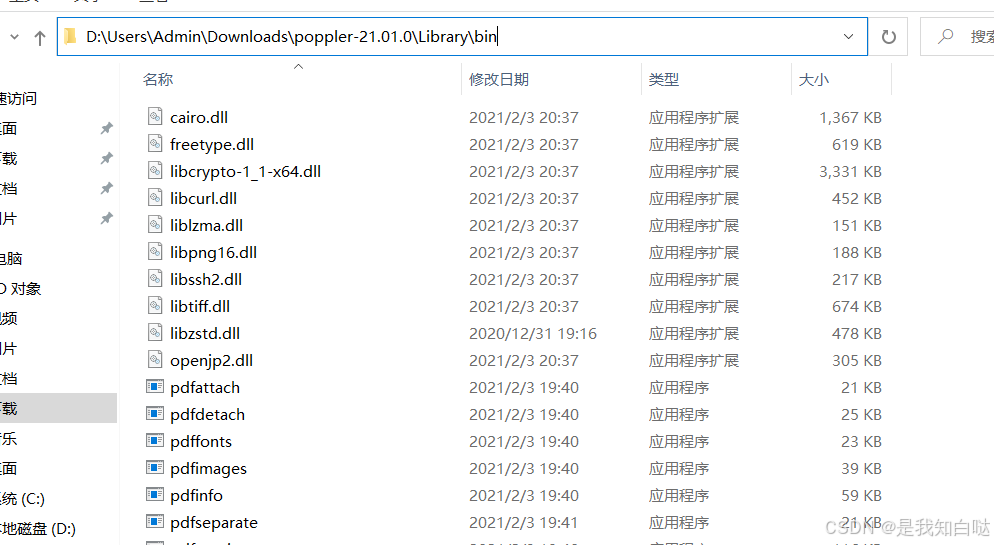
在环境变量的系统变量添加

确认后重启
测试
准备一个pdf文件,在代码同级别目录创建一个空文件夹"pdf_files"
python
import pytesseract
from pdf2image import convert_from_path
import os
import re
# 设置tesseract的路径(Windows系统)
# 如果你使用的是Windows,确保Tesseract的安装路径已经加入到环境变量中,或者手动指定路径
pytesseract.pytesseract.tesseract_cmd = r'D:\Program Files\Tesseract-OCR\tesseract.exe'
# 批量处理PDF文件并使用OCR提取文本
def pdf_to_text(pdf_path, output_txt_path):
# 将PDF转换为图片(每页一个图片)
images = convert_from_path(pdf_path, dpi=300)
full_text = ""
# 遍历每一页的图像
for page_num, image in enumerate(images):
print(f"Processing page {page_num + 1}...")
# 使用Tesseract OCR识别图像中的文本
text = pytesseract.image_to_string(image, lang='chi_tra') # 你可以选择其他语言包,例如'chi_sim'(简体中文)
# 将提取的文本加入到总文本中
full_text += f"Page {page_num + 1}:\n"
full_text += text + "\n\n"
# 保存提取的文本到文件
with open(output_txt_path, 'w', encoding='utf-8') as f:
f.write(full_text)
print(f"Text extraction complete. Text saved to {output_txt_path}")
# 处理多个PDF文件
def process_pdfs(input_folder, output_folder):
# 获取所有PDF文件
pdf_files = [f for f in os.listdir(input_folder) if f.lower().endswith('.pdf')]
for pdf_file in pdf_files:
pdf_path = os.path.join(input_folder, pdf_file)
txt_filename = re.sub(r'\.pdf$', '.txt', pdf_file)
txt_path = os.path.join(output_folder, txt_filename)
pdf_to_text(pdf_path, txt_path)
if __name__ == "__main__":
input_folder = 'pdf_files' # PDF文件所在目录
output_folder = 'txt_files' # 提取文本的输出目录
if not os.path.exists(output_folder):
os.makedirs(output_folder)
process_pdfs(input_folder, output_folder)转换的结果会在"txt_files"里,这个文件夹会自动给你创建,在代码23行需要根据pdf的字体设置语言:eng(英文)、chi_sim(繁体)、chi_tra(简体中文)