目录
安装:pip install PyMuPDF -i https://pypi.mirrors.ustc.edu.cn/simple/
PyMuPDF库支持多种文档格式的内容读取,如PDF、XPS、CBZ等,支持将文档转换为其他格式,如HTML、SVG、PDF和CBZ等。
PyMuPDF可以修改pdf文件的内容。其他文件类型用PyMuPDF是只读的。但可以将任何文档(包括图像)转换为PDF(Document.convert_to_pdf()),然后将再使用PyMuPDF的功能进行操作。
参考文档:https://pymupdf.readthedocs.io/en/latest/page.html
文档操作
打开文档
open()没有参数时是打开新的文档,有参数时是加载指定文档
fitz和pymupdf 是同一个库,操作相同
python
import fitz # fitz就是PyMuPDF的别名
# import pymupdf # 同fitz
# new_pdf = pymupdf.open()
# pdf_document = pymupdf.open(pdf_path) # 打开文档,获取文档对象
new_pdf = fitz.open()
pdf_document = fitz.open(pdf_path) # 打开文档,获取文档对象获取文档信息
python
print(pdf_document.metadata) # 获取文档信息
print(pdf_document.get_toc()) # 获取目录大纲
print(pdf_document.page_count) # 获取页数文档信息如下:
python
{'format': 'PDF 1.7', 'title': '', 'author': '', 'subject': '', 'keywords': '7e1d6144af9e0ffb0HJ_0924E1RQy4S3U_uCQ-ernv_VMhNm', 'creator': 'Microsoft® Word 2021', 'producer': 'Microsoft® Word 2021; modified using iText® 5.5.13 ©2000-2018 iText Group NV (AGPL-version)', 'creationDate': "D:20240322202301+08'00'", 'modDate': "D:20240423092659+08'00'", 'trapped': '', 'encryption': None}删除页
delete_page 删除指定页,一次只删除一页,参数为对应页的索引
python
pdf_document.delete_page(-1)delete_pages 删除多页,传入参数如果为列表/元组/范围,可删除对应页,如果是两个整数则删除从第n页到第m页(关键字'from_page'/'to_page')
python
pdf_document.delete_pages((2,4,7))
pdf_document.delete_pages(3,5)复制页
python
pdf_document.copy_page(2) # copy_page(n,m)将第n+1页复制到第m+1页,m默认为-1(最后一页),复制PDF文档中的页面。这只会创建同一个页面对象的另一个引用
pdf_document.fullcopy_page(2) # fullcopy_page(n,m)将第n+1页复制到第m+1页,m默认为-1(最后一页),复制一整页移动页
python
pdf_document.move_page(0,2) # move_page(n,m)将第n+1页移动到第m+1页,m默认为-1(最后一页)选择重构合并
在列表中建立带有页码的子pdf。参数为需要重新创建指定页的页码列表,页码必须是在范围内,会根据列表中的顺序选择整合文档,这里演示只合并奇数页。
python
pdf_document.select([i for i in range(0,pdf_document.page_count,2)]) 保存关闭
python
def save(
self,
filename,
garbage=0,
clean=0,
deflate=0,
deflate_images=0,
deflate_fonts=0,
incremental=0,
ascii=0,
expand=0,
linear=0,
no_new_id=0,
appearance=0,
pretty=0,
encryption=1,
permissions=4095,
owner_pw=None,
user_pw=None,
preserve_metadata=1,
use_objstms=0,
compression_effort=0,
):
python
pdf_document.save(rf'{save_img_path}\{pdf_file_name}-副本{int(time())}.pdf')
pdf_document.close()页对象操作
内容读取
PyMuPDF支持将读取到的内容转为多种格式的数据,默认为text纯文本内容
"text":(默认)带换行符的纯文本(不包含格式、文字位置详细信息和图像)。
python
pdf_document = fitz.open(pdf_path) # 打开文档,获取文档对象
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num) # 获取页对象
text = page.get_text() # 获取页面文本内容
print(text)"blocks":生成文本块(段落)的列表。
"words":生成不包含空格的字符串单词列表。
"html":创建包括任何图像的html数据。
python
def fitz_pdf(pdf_path):
pdf_document = fitz.open(pdf_path) # 打开文档,获取文档对象
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num) # 获取页对象
html = page.get_text("html") # 获取页面内容
with open(f'test-{page_num}.html', 'w') as f:
f.write(html)
pdf_document.close()"dict" 或 "json":
"rawdict"或 "rawjson":包含XML之类字符详细信息的"dict"及"json"的超级集合。
"xhtml":包含图像及文本信息级别的html数据。
"xml":不包含图像,只有每个文本字符的完整位置和字体信息。
获取页对象的字体样式
python
page = pdf_document.load_page(page_num) # 获取页对象
print(page.get_fonts()) # 获取字体样式
cpp
[(14, 'ttf', 'TrueType', 'BCDEEE+Cambria', 'F1', 'WinAnsiEncoding'), (15, 'ttf', 'Type0', 'BCDFEE+MS-Gothic', 'F2', 'Identity-H'), (16, 'ttf', 'Type0', 'BCDGEE+MicrosoftYaHei', 'F3', 'Identity-H'), (17, 'n/a', 'TrueType', 'ArialMT', 'F4', 'WinAnsiEncoding'), (18, 'ttf', 'Type0', 'BCDHEE+SimHei', 'F5', 'Identity-H'), (19, 'ttf', 'Type0', 'BCDIEE+MicrosoftYaHei-Bold', 'F6', 'Identity-H'), (20, 'ttf', 'TrueType', 'BCDJEE+SimHei', 'F7', 'WinAnsiEncoding'), (21, 'ttf', 'TrueType', 'BCDKEE+MicrosoftYaHei', 'F8', 'WinAnsiEncoding'), (22, 'ttf', 'TrueType', 'BCDLEE+Cambria-Bold', 'F9', 'WinAnsiEncoding'), (23, 'n/a', 'TrueType', 'Arial-BoldMT', 'F10', 'WinAnsiEncoding'), (24, 'ttf', 'Type0', 'BCDMEE+Wingdings-Regular', 'F11', 'Identity-H'), (25, 'ttf', 'TrueType', 'BCDNEE+ArialUnicodeMS', 'F12', 'WinAnsiEncoding'), (26, 'ttf', 'Type0', 'BCDOEE+ArialUnicodeMS', 'F13', 'Identity-H'), (1, 'n/a', 'Type1', 'Helvetica', 'Xi0', 'WinAnsiEncoding')]插入文本标签
python
page.add_text_annot((50, 150), f'文本便利贴测试,这是{page_num + 1}页')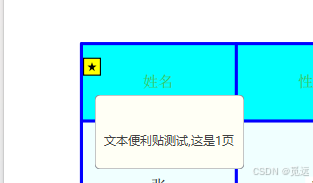
插入文本内容
字体设置
如果写入内容时不指定字体时,中文内容会乱码。
内置字体:china-s 黑体 china-ss 宋体 china-t 繁体黑体 china-ts 繁体宋体。
自定义字体添加如下,很多网上分享者都用 fitz.Font() 添加,根本没有用。
python
page.insert_font(fontname="三极妙漫体",
fontfile=r"C:\Users\DELL\AppData\Local\JianyingPro\三极妙漫体.ttf",
fontbuffer=None, set_simple=False) # 自定义字体添加insert_text添加文本
python
def insert_text(
self,
point: point_like,
buffer_: typing.Union[str, list],
fontsize: float = 11,
lineheight: OptFloat = None,
fontname: str = "helv",
fontfile: OptStr = None,
set_simple: bool = 0,
encoding: int = 0,
color: OptSeq = None,
fill: OptSeq = None,
render_mode: int = 0,
border_width: float = 1,
rotate: int = 0,
morph: OptSeq = None,
stroke_opacity: float = 1,
fill_opacity: float = 1,
oc: int = 0,
) -> int:
python
page.insert_text((50, 50), "这是中文测试", fontsize=15, fontname='china-s')insert_textbox添加文本
python
def insert_textbox(
self,
rect: rect_like,
buffer: typing.Union[str, list],
fontname: OptStr = "helv",
fontfile: OptStr = None,
fontsize: float = 11,
lineheight: OptFloat = None,
set_simple: bool = 0,
encoding: int = 0,
color: OptSeq = None,
fill: OptSeq = None,
expandtabs: int = 1,
border_width: float = 0.05,
align: int = 0,
render_mode: int = 0,
rotate: int = 0,
morph: OptSeq = None,
stroke_opacity: float = 1,
fill_opacity: float = 1,
oc: int = 0,
) -> float:
python
text_rect = fitz.Rect(80, 80, 500, 100) # 定义文本框位置
page.insert_textbox(text_rect, "测试文本框添加操作", fontsize=12,
align=fitz.TEXT_ALIGN_LEFT, fontname='三极妙漫体',
fill=(200 / 255, 250 / 255, 100 / 255), rotate=90, fill_opacity=.2)插入图片
python
insert_image(rect, *, alpha=-1, filename=None, height=0, keep_proportion=True, mask=None, oc=0, overlay=True, pixmap=None, rotate=0, stream=None, width=0, xref=0)
python
img_rect = fitz.Rect((50, 50, 150, 100))
page.insert_image(img_rect, filename=r'E:\桌面\99\测试图片\1.jpg') # 可设置位置和图片大小获取页面注释、链接、表单字段
python
for ant in page.annots(): # 获取注释
print(ant)
for link in page.links(): # 获取链接
print(link)
for widget in page.widgets(): # 获取表单字段
print(widget)获取页面RGB图像数据并将页面保存为图片
python
get_pixmap(*, matrix=pymupdf.Identity, dpi=None, colorspace=pymupdf.csRGB, clip=None, alpha=False, annots=True)获取页面RGB图像,参数包含分辨率、颜色空间(可生成灰度图像或具有减色方案的图像)、透明度、旋转、镜像、移位、剪切等。可设置宽度、高度等。
python
pix = page.get_pixmap()
pix.save('test.png')获取页面的矢量图(转svg)
python
svg_img = page.get_svg_image()
with open('test.svg', 'w') as f:
f.write(svg_img)创建新页面
python
pdf_document.new_page()