大数据组件(一)快速入门调度组件Airflow
- DolphinScheduler和 Airflow是数据领域很流行的两款开源任务调度系统。DolphinScheduler 致力于用可视化的方式去完成一个 DAG 工作流,而 Airflow 则想的是用类似于编程的方式完成一个 DAG 工作流。
- Apache DolphinScheduler 可以直接在页面上完成对 DAG 工作流的开发。
- 而 Apache Airflow 需要提交一个 Python 文件到后台服务器上,由 Apache Airflow 去解析这个 Python 文件,进而生成一个 DAG 工作流。
- 我们,今天以几个简单的案例,快速了解下基于python的调度组件Airflow。
1 Airflow的安装(单机版)
这里,我们利用conda进行安装。
首先,创建环境:
shell
conda create -n airflow python=3.8 -y
conda activate airflow然后,利用pip进行安装,需要注意的是:安装时候,需要指定约束文件,否则很容易会出现依赖冲突。
shell
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-2.7.2/constraints-3.8.txt"
pip install "apache-airflow==2.7.2" --constraint "${CONSTRAINT_URL}"我们这里利用MySQL数据库进行配置:
shell
# 3、查询版本
(airflow) [root@centos01 ~]# airflow version
2.7.2
(airflow) [root@centos01 airflow]# pwd
/root/airflow
# 4、数据库初始化、改为Mysql数据库
(airflow) [root@centos01 airflow]# pip install mysql-connector-python
(airflow) [root@centos01 airflow]# airflow db init
(airflow) [root@centos01 airflow]# vim airflow.cfg
#sql_alchemy_conn = sqlite:root/airflow/airflow.db
sql_alchemy_conn = mysql+mysqlconnector://root:123456@127.0.0.1:3306/airflow_db
# 再次初始化
(airflow) [root@centos01 airflow]# airflow db init
# 报错如下:
sqlalchemy.exc.ProgrammingError: (mysql.connector.errors.ProgrammingError) 1067 (42000): Invalid default value for 'updated_at'
[SQL:
CREATE TABLE dataset (
id INTEGER NOT NULL AUTO_INCREMENT,
uri VARCHAR(3000) COLLATE latin1_general_cs NOT NULL,
extra JSON NOT NULL,
created_at TIMESTAMP(6) NOT NULL,
updated_at TIMESTAMP(6) NOT NULL,
is_orphaned BOOL NOT NULL DEFAULT '0',
CONSTRAINT dataset_pkey PRIMARY KEY (id)
)]
(Background on this error at: https://sqlalche.me/e/14/f405)
# 解决方案
原因:字段 'update_at' 为 timestamp类型,取值范围是:1970-01-01 00:00:00 到 2037-12-31 23:59:59(UTC +8 北京时间从1970-01-01 08:00:00 开始),而这里默认给了空值,所以导致失败。
推荐修改mysql存储时间戳格式:
mysql> set GLOBAL sql_mode ='STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
重启MySQL会造成参数失效,推荐将参数写入到配置文件my.cnf中。
# 在[mysqld]添加下面两行
[root@centos01 apps]# vim /etc/my.cnf
[mysqld]
skip_ssl
sql_mode=STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
# 重启mysql
[root@centos01 apps]# systemctl restart mysqld
# 5、添加admin用户
(airflow) [root@centos01 airflow]# airflow users create \
> --username admin \
> --firstname Undo \
> --lastname Undo \
> --role Admin \
> --email undo@163.com
# 输入密码
[2024-12-27T16:28:17.107+0800] {manager.py:555} INFO - Added Permission %s to role %s
Password:
# 6、启动airflow web服务和调度器, 启动后浏览器访问http://centos01:8080
(airflow) [root@centos01 airflow]# airflow webserver -p 8080 -D
(airflow) [root@centos01 airflow]# airflow scheduler -D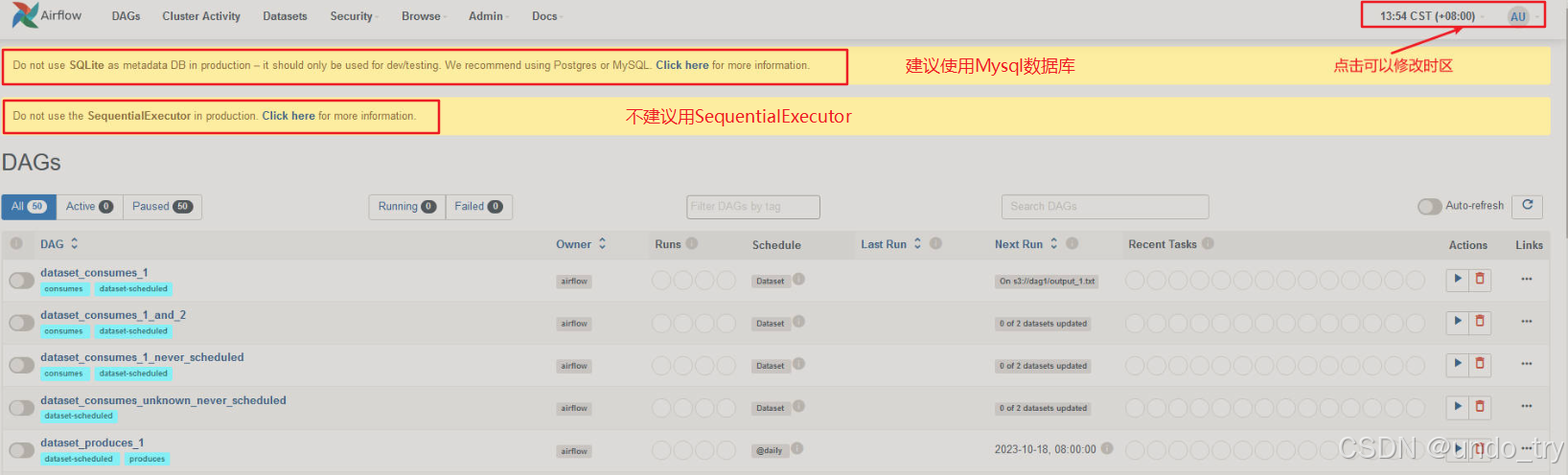
上图是默认安装时候,会出现的两条信息:
- Airflow使用SQLite数据库,建议改为Mysql数据库,我们已经修改;
- SequentialExecutor按顺序运行任务实例,不能并行执行任务,我们下面修改;
注意:右上角默认是UTC时间,我们一定要点击修改时区,同时要修改airflow.cfg文件。
shell
# 7、修改airflow的配置文件
(airflow) [root@centos01 airflow]# vim airflow.cfg
# 可以使用官方推荐的几种执行器,也可以自定义。这里我们选择本地执行器即可。
[core]
# 存放python调度脚本的目录
dags_folder = /root/airflow/dags
# The executor class that airflow should use. Choices include
# ``SequentialExecutor``, ``LocalExecutor``, ``CeleryExecutor``, ``DaskExecutor``,
# ``KubernetesExecutor``, ``CeleryKubernetesExecutor`` or the
# full import path to the class when using a custom executor.
executor = LocalExecutor
# 修改时区信息
# default_ui_timezone = UTC
default_ui_timezone = Asia/Shanghai
# default_timezone = utc
default_timezone = Asia/Shanghai
# 创建目录,用来存放python调度脚本
(airflow) [root@centos01 airflow]# mkdir dags我们把airflow启动、关闭封装为脚本:
shell
(airflow) [root@centos01 ~]# vim af.sh
(airflow) [root@centos01 ~]# chmod +x af.sh
#!/bin/bash
case $1 in
"start"){
echo " --------start airflow-------"
conda activate airflow;airflow webserver -p 8080 -D;airflow scheduler -D;conda deactivate
};;
"stop"){
echo " --------stop airflow-------"
ps -ef | egrep 'scheduler|airflow-webserver' | grep -v grep | awk '{print $2}' | xargs kill -15
};;
esac
# 然后重启
(airflow) [root@centos01 ~]# ./af.sh stop
--------stop airflow-------
(airflow) [root@centos01 ~]# ./af.sh start
--------start airflow-------
# 查看是否启动成功
(airflow) [root@centos01 ~]# ps -ef | grep 8080
root 1935 1 1 20:55 ? 00:00:00 /opt/apps/minoconda3/envs/airflow/bin/python /opt/apps/minoconda3/envs/airflow/bin/airflow webserver -p 8080 -D
root 2618 1630 0 20:55 pts/0 00:00:00 grep --color=auto 8080
# 访问http://centos01:8080/页面,页面上会出现很多官方示例
# 当然,我们也能通过命令查看
(airflow) [root@centos01 ~]# airflow dags list
dag_id | filepath | owner | paused
========================================================+======================================================================================================================================+=========+=======
dataset_consumes_1 | /opt/apps/minoconda3/envs/airflow/lib/python3.8/site-packages/airflow/example_dags/example_datasets.py | airflow | True
dataset_consumes_1_and_2 | /opt/apps/minoconda3/envs/airflow/lib/python3.8/site-packages/airflow/example_dags/example_datasets.py | airflow | True
dataset_consumes_1_never_scheduled | /opt/apps/minoconda3/envs/airflow/lib/python3.8/site-packages/airflow/example_dags/example_datasets.py | airflow | True
......2 Airflow入门案例
2.1 BashOperator
- Airflow中最重要的还是各种Operator,其允许生成特定类型的任务,这个任务在实例化时称为DAG中的任务节点,所有的Operator均派生自BaseOparator,并且继承了许多属性和方法。
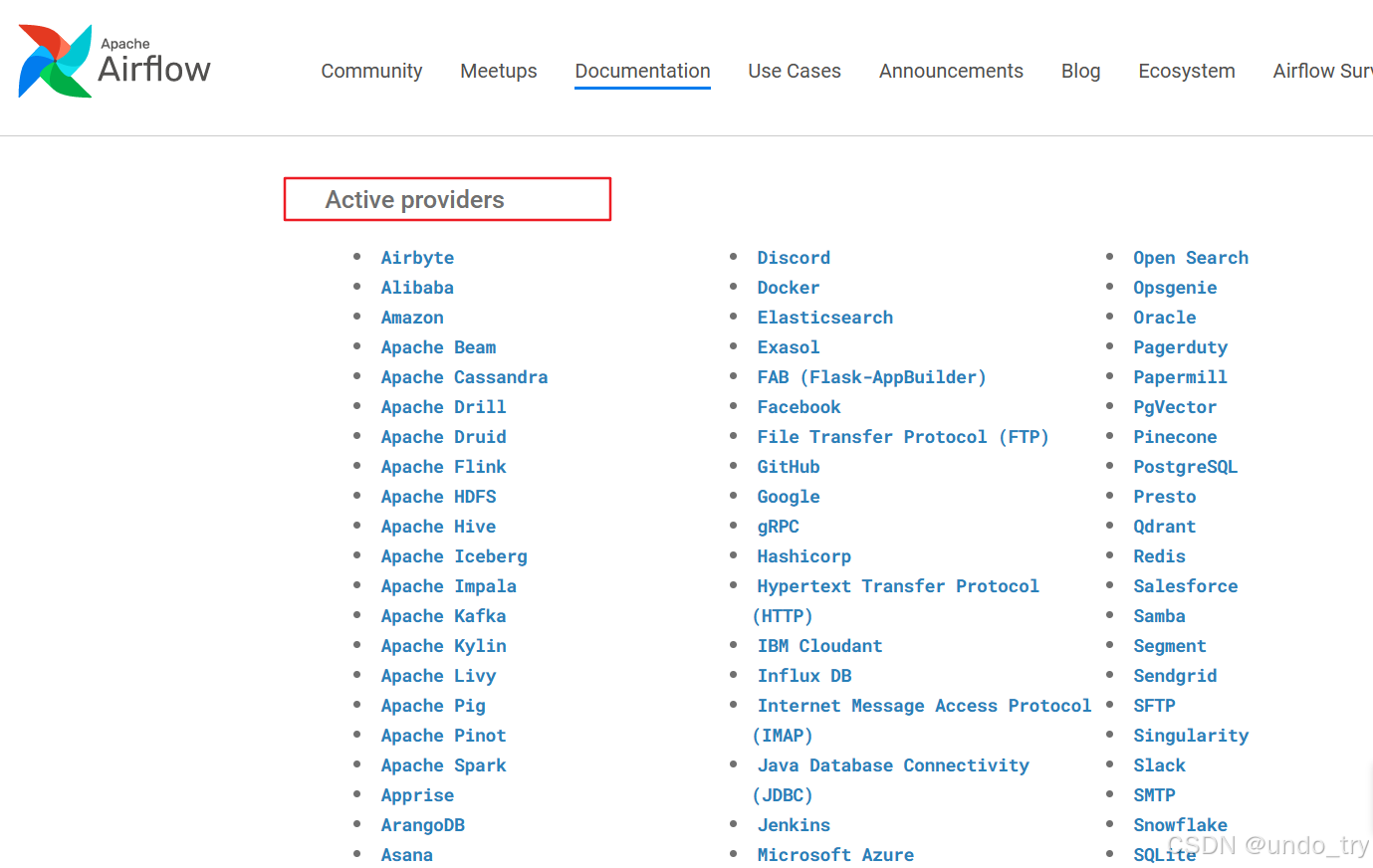
- BashOperator主要执行
bash脚本或命令。 - Operator参考:https://airflow.apache.org/docs/
shell
(airflow) [root@centos01 shell_jobs]# cat first_shell.sh
#!/bin/bash
dt=$1
echo "==== execute first shell ===="
echo "---- first : time is ${dt}"
(airflow) [root@centos01 shell_jobs]# cat second_shell.sh
#!/bin/bash
dt=$1
echo "==== execute second shell ===="
echo "---- second : time is ${dt}"- python脚本如下(
可以用VS Code远程连接),注意:要放在配置的目录下:
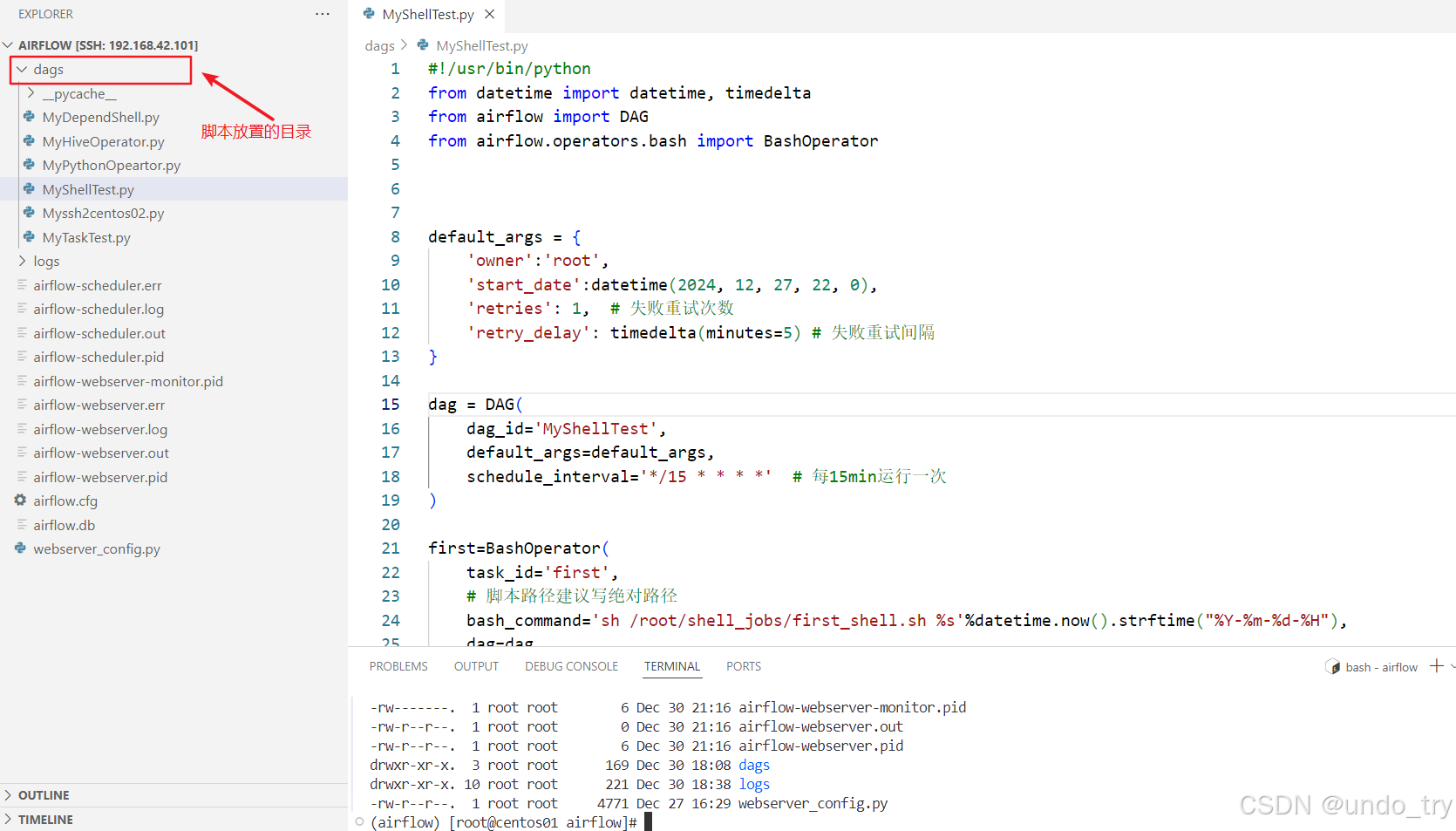
python
#!/usr/bin/python
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner':'root',
'start_date':datetime(2024, 12, 27, 22, 0), # 调度开始时间
'retries': 1, # 失败重试次数
'retry_delay': timedelta(minutes=5) # 失败重试间隔
}
dag = DAG(
dag_id='MyShellTest',
default_args=default_args,
schedule_interval='*/15 * * * *' # 每15min运行一次
)
first=BashOperator(
task_id='first',
# 脚本路径建议写绝对路径
bash_command='sh /root/shell_jobs/first_shell.sh %s'%datetime.now().strftime("%Y-%m-%d-%H"),
dag=dag
)
second=BashOperator(
task_id='second',
# 脚本路径建议写绝对路径
bash_command='sh /root/shell_jobs/second_shell.sh %s'%datetime.now().strftime("%Y-%m-%d-%H"),
dag=dag
)
first >> second

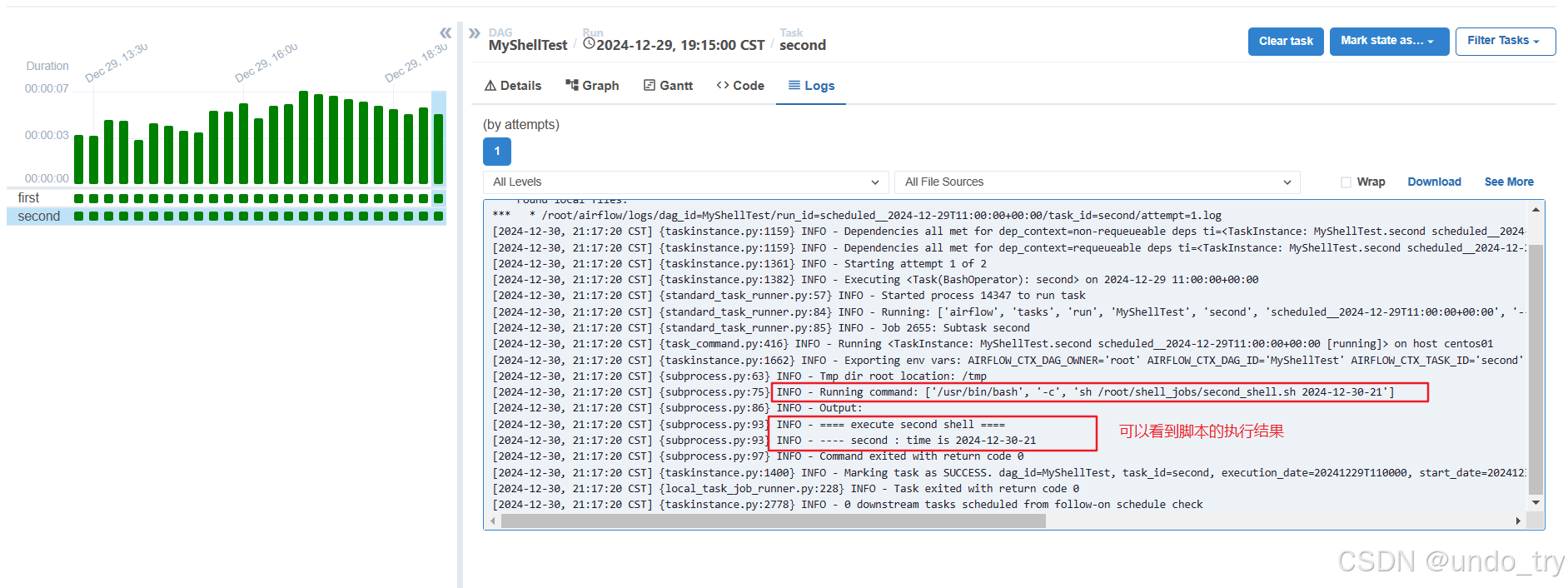
2.2 SSHOperator
-
在实际的调度任务中,任务脚本大多分布在不同的机器上,我们可以使用SSHOperator来调用远程机器上的脚本任务。
-
Airflow中提供了很多的providers,需要通过pip安装
apache-airflow-providers-ssh包。-
安装哪个版本的apache-airflow-providers-ssh包呢?
-
需要查看我们安装时候的
https://raw.githubusercontent.com/apache/airflow/constraints-2.7.2/constraints-3.8.txt约束文件 -

-
-
最后,
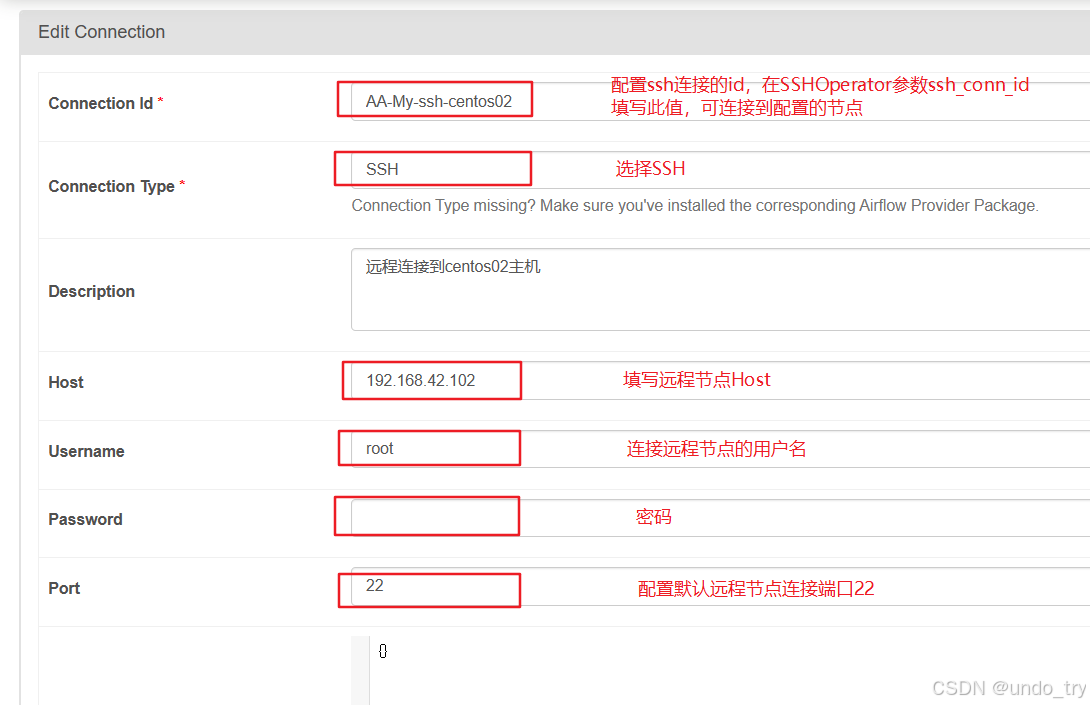
配置SSH Connection连接。登录airflow webui ,选择"Admin"->"Connections"。
shell
# 首先停止airflow webserver与scheduler
# 我们在https://raw.githubusercontent.com/apache/airflow/constraints-2.7.2/constraints-3.8.txt找相应的版本安装
(airflow) [root@centos01 airflow]# pip install apache-airflow-providers-ssh==3.7.3
# 然后启动airflow webserver与scheduler
我们在另一台机器上创建两个shell脚本:
#!/bin/bash
# 获取主机名
HOSTNAME=$(hostname)
echo "==== 执行脚本主机是: $HOSTNAME, execute first shell ===="
#!/bin/bash
# 获取主机名
HOSTNAME=$(hostname)
echo "==== 执行脚本主机是: $HOSTNAME, execute second shell ===="
[root@centos02 shell_jobs]# ll
total 8
-rw-r--r--. 1 root root 122 Dec 28 16:34 first_shell.sh
-rw-r--r--. 1 root root 123 Dec 28 16:34 second_shell.sh然后,创建Python脚本
python
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.providers.ssh.operators.ssh import SSHOperator
default_args = {
'owner':'root',
'start_date': datetime(2024, 12, 28, 16), # 开始执行时间
'retries': 1, # 失败重试次数
'retry_delay': timedelta(minutes=5) # 失败重试间隔
}
# 声明任务图, Airflow使用的是"前一个周期"来调度 DAG 运行
# 即:在2024-12-28 00:00:00时,Airflow会执行的调度账期是:2024-12-27 00:00:00
# dag = DAG('MyTaskTest', default_args=default_args, schedule_interval=timedelta(days=1))
dag = DAG(
dag_id = 'Myssh2centos02',
default_args=default_args,
schedule_interval=timedelta(minutes=10) # 10min执行一次
)
first=SSHOperator(
task_id='first',
ssh_conn_id='AA-My-ssh-centos02', # 配置在Airflow webui Connection中配置的SSH Conn id
command='sh /root/shell_jobs/first_shell.sh ', # 注意:带一个空格
dag = dag
)
second=SSHOperator(
task_id='second',
ssh_conn_id='AA-My-ssh-centos02', # 配置在Airflow webui Connection中配置的SSH Conn id
command='sh /root/shell_jobs/second_shell.sh ', # 注意:带一个空格
remote_host="192.168.42.102", # 如果配置remote_host,将会替换Connection中的SSH配置的host
dag=dag
)
first >> second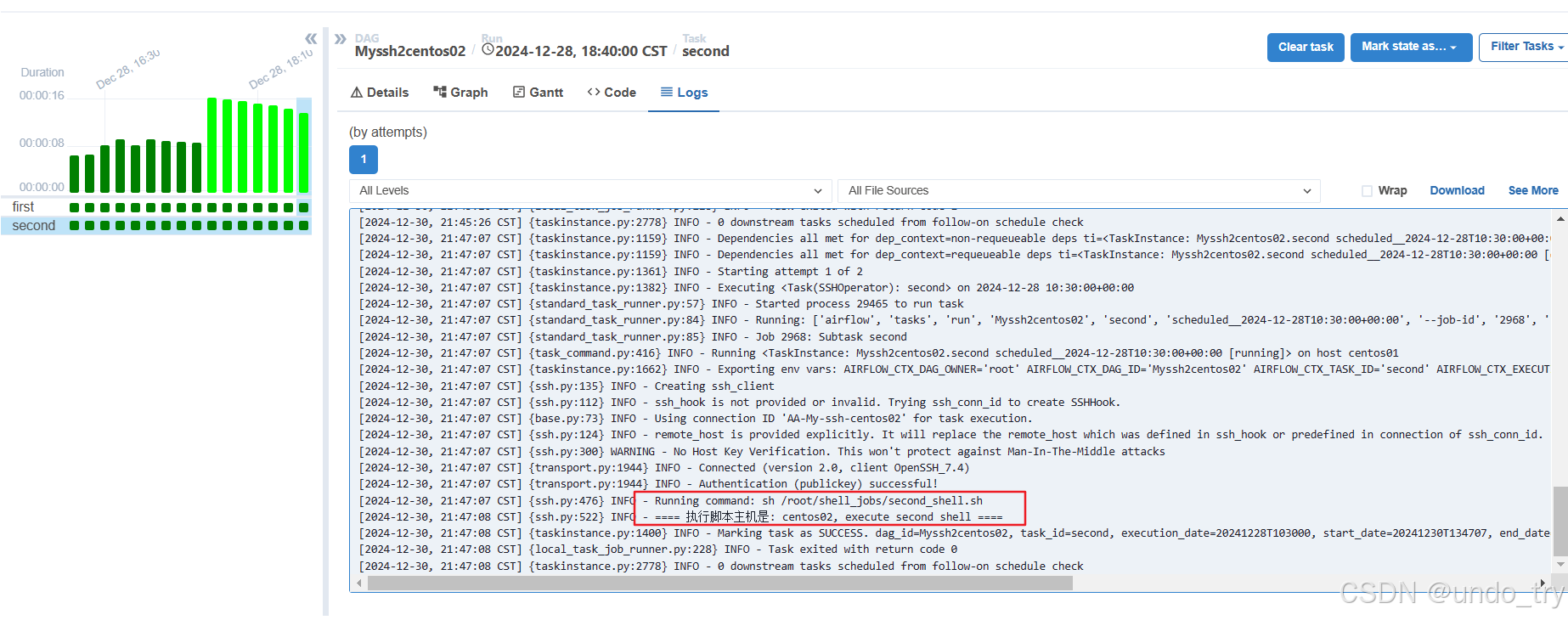
2.3 PythonOperator
- PythonOperator可以调用Python函数,由于Python基本可以调用任何类型的任务,如果实在找不到合适的Operator,将任务转为Python函数,使用PythonOperator即可。
python
import random
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python import PythonOperator
import pytz
def print__hello1(*a,**b):
"""
* 关键字参数允许传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple
** 关键字参数允许传入0个或任意个含【参数名】的参数,这些关键字参数在函数内部自动组装为一个dict
"""
print("hello airflow1")
print(a)
print(b)
# 返回的值只会打印到日志中
return {"sss1":"print__hello1"}
def print__hello2(execution_ds, execution_ts, random_base):
print("hello airflow2")
print("Today:{}, 当前执行的账期为:{}, 随机数为:{}".format(execution_ds, execution_ts, random_base))
# 将字符串解析为带有时区信息的datetime对象
utc_dt = datetime.strptime(execution_ts, "%Y-%m-%dT%H:%M:%S%z")
# 定义目标时区(上海时区)
shanghai_tz = pytz.timezone('Asia/Shanghai')
# 将UTC时间转换为目标时区的时间
shanghai_dt = utc_dt.astimezone(shanghai_tz)
# 格式化输出
execution_ts_sh = shanghai_dt.strftime('%Y-%m-%d %H:%M:%S')
print("Today:{}, 当前执行的账期为:{}, 随机数为:{}".format(execution_ds, execution_ts_sh, random_base))
# 返回的值只会打印到日志中
return {"sss2":"print__hello2"}
default_args = {
'owner':'root',
'start_date': datetime(2024, 12, 28, 14), # 开始执行时间
'retries': 1, # 失败重试次数
'retry_delay': timedelta(minutes=5) # 失败重试间隔
}
dag = DAG(
dag_id = 'MyPythonOperator',
default_args=default_args,
schedule_interval='*/10 * * * *' # 每10min运行一次
)
first=PythonOperator(
task_id='MyPython_first',
#填写print__hello1方法时,不要加上()
python_callable=print__hello1,
# op_args对应print_hello1方法中的a参数
op_args=[1,2,3,"hello","world"],
# op_kwargs对应print__hello1方法中的b参数,带参数名称
op_kwargs={"id":"1","name":"zs","age":18},
dag = dag
)
second=PythonOperator(
task_id='MyPython_second',
# 同样,填写print__hello2 方法时,不要加上()
python_callable=print__hello2,
op_kwargs={
# {{ ds }} 是一个Airflow Jinja模板变量,表示当前的执行日期(格式为 YYYY-MM-DD)
'execution_ds': '{{ ds }}',
# {{ ts }} 是一个Airflow Jinja模板变量,表示当前的执行时间戳,格式为 YYYY-MM-DDTHH:MM:SS
# 注意:默认传递是UTC时间,例如:2024-12-28T07:30:00+00:00
'execution_ts': '{{ ts }}',
# random_base参数对应print_hello2方法中参数的random_base
"random_base": random.randint(0, 9)
},
dag=dag
)
first >> second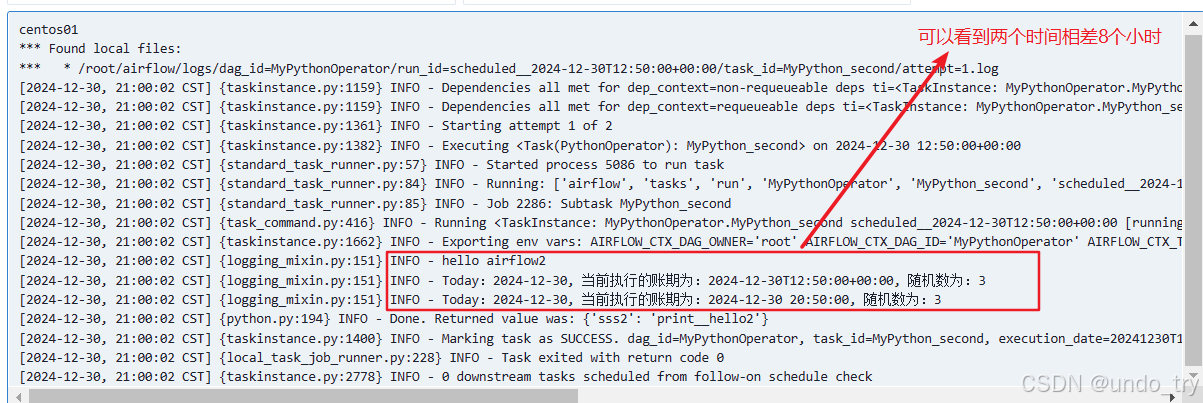
2.4 HiveOperator
- 可以通过HiveOperator直接操作Hive SQL
- 在airflow中使用HiveOperator调用Hive任务,首先需要安装以下依赖并配置Hive Metastore
shell
# 在https://raw.githubusercontent.com/apache/airflow/constraints-2.7.2/constraints-3.8.txt找相应的版本安装
pip install apache-airflow-providers-apache-hive==6.1.6- 启动HDFS、Hive Metastore,在Hive中创建下面表,并加载文件。
sql
-- 1、创建表
create table ods_person_info(id int,name string,age int, city_id int)
row format delimited fields terminated by '\t';
create table dim_city_info(city_id int,city_name string)
row format delimited fields terminated by '\t';
-- 2、准备两个文件
ods_person_info.csv
1 John 30 1001
2 Jane 25 1002
3 Mike 40 1001
4 Sarah 35 1003
5 Liam 22 1004
dim_city_info.csv
1001 New York
1002 Los Angeles
1003 Chicago
1004 Houston
1005 Phoenix
-- 3、加载数据
LOAD DATA LOCAL INPATH '/root/input_doris_data/ods_person_info.csv'
INTO TABLE ods_person_info;
LOAD DATA LOCAL INPATH '/root/input_doris_data/dim_city_info.csv'
INTO TABLE dim_city_info;- 同样,登录Airflow webui并设置Hive Metastore

- 编写Python脚本
python
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.apache.hive.operators.hive import HiveOperator
from airflow.operators.python_operator import PythonOperator
import pytz
default_args = {
'owner': 'root',
'start_date': datetime(2024, 12, 30, 12),
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
dag_id='MyHiveOperator',
default_args=default_args,
schedule_interval=timedelta(hours=1)
)
# 1、利用PythonOperator封装分区变量
def get_partition_hour(**context):
execution_dt = context['execution_date']
# 转换Asia/Shanghai分区时间
shanghai_tz = pytz.timezone('Asia/Shanghai')
shanghai_dt = execution_dt.astimezone(shanghai_tz)
# 分区时间
partition_hour = shanghai_dt.strftime('%Y%m%d%H')
context['ti'].xcom_push(key='partition_hour', value=partition_hour)
return {'partition_hour': partition_hour}
time_prep = PythonOperator(
task_id='prepare_times',
python_callable=get_partition_hour,
provide_context=True,
dag=dag
)
# 2、创建结果表
create_table = HiveOperator(
task_id='create_table',
hive_cli_conn_id="AA-My-centos01-hive",
hql="""
CREATE TABLE IF NOT EXISTS dwd_person_city_info (
id INT,
name STRING,
age INT,
city_id INT,
city_name STRING,
insert_time STRING
)
PARTITIONED BY (p_hour STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
""",
dag=dag
)
# 3、利用PythonOperator来预处理HQL语句,并将处理后的HQL语句传递给HiveOperator
def get_insert_time():
# 获取当前的执行时间
now = datetime.now()
formatted_time = now.strftime('%Y-%m-%d %H:%M:%S')
return formatted_time
def prepare_hql(**context):
# Airflow中可以XCom功能来共享数据
# 通过XCom,一个任务可以将数据推送到一个临时存储中,其他任务可以从这个存储中拉取数据
partition_hour = context['ti'].xcom_pull(task_ids='prepare_times', key='partition_hour')
# 调用本地方法
formatted_time = get_insert_time()
# 组装hive-sql
hql = f"""
INSERT OVERWRITE TABLE dwd_person_city_info
PARTITION(p_hour='{partition_hour}')
SELECT
a.id
, a.name
, a.age
, a.city_id
, b.city_name
, '{formatted_time}' AS insert_time
FROM
ods_person_info a
JOIN
dim_city_info b
ON a.city_id = b.city_id
"""
return hql
prepare_hql_task = PythonOperator(
task_id='prepare_hql',
python_callable=prepare_hql,
provide_context=True,
dag=dag
)
# 4、执行hive-sql插入到相应分区
insert_data = HiveOperator(
task_id='insert_partitioned_data',
hive_cli_conn_id="AA-My-centos01-hive",
# 注意,这里使用了task_instance.xcom_pull而不是ti.xcom_pull
# 因为在HiveOperator的模板上下文中,ti可能不是直接可用的
# 而task_instance是Airflow在模板渲染时提供的一个全局变量,用于访问当前任务实例。
hql="{{ task_instance.xcom_pull(task_ids='prepare_hql', key='return_value') }}",
dag=dag
)
time_prep >> create_table >> prepare_hql_task >> insert_data
shell
0: jdbc:hive2://192.168.42.101:10000> show tables;
+-----------------------+
| tab_name |
+-----------------------+
| dim_city_info |
| dwd_person_city_info |
| ods_person_info |
+-----------------------+
3 rows selected (0.931 seconds)
0: jdbc:hive2://192.168.42.101:10000> show partitions dwd_person_city_info;
+--------------------+
| partition |
+--------------------+
| p_hour=2024123012 |
| p_hour=2024123013 |
| p_hour=2024123014 |
| p_hour=2024123015 |
| p_hour=2024123016 |
| p_hour=2024123017 |
+--------------------+
6 rows selected (0.307 seconds)
0: jdbc:hive2://192.168.42.101:10000> select * from dwd_person_city_info a where p_hour=2024123017;
+-------+---------+--------+------------+--------------+----------------------+-------------+
| a.id | a.name | a.age | a.city_id | a.city_name | a.insert_time | a.p_hour |
+-------+---------+--------+------------+--------------+----------------------+-------------+
| 1 | John | 30 | 1001 | New York | 2024-12-30 18:00:10 | 2024123017 |
| 2 | Jane | 25 | 1002 | Los Angeles | 2024-12-30 18:00:10 | 2024123017 |
| 3 | Mike | 40 | 1001 | New York | 2024-12-30 18:00:10 | 2024123017 |
| 4 | Sarah | 35 | 1003 | Chicago | 2024-12-30 18:00:10 | 2024123017 |
| 5 | Liam | 22 | 1004 | Houston | 2024-12-30 18:00:10 | 2024123017 |
+-------+---------+--------+------------+--------------+----------------------+-------------+
5 rows selected (2.301 seconds)