2024年,中国城市智驾迎来全面爆发。在这场高阶智能驾驶的竞速赛中,广汽正以稳健而坚定的步伐,向行业第一梯队迈进。
广汽的"星灵智行" ADiGO 技术品牌,以AI重构智能汽车,全面推动AI赋能智能驾驶和智能座舱,加速汽车从"移动工具",向"智能终端"进化。广汽 GSD 智能辅助驾驶实现了对复杂城市场景的泛化理解能力。系统现已覆盖至少35个主场景、357个子场景,在红绿灯起停、拥堵博弈变道、待转区左转等高难度场景中表现游刃有余,城市场景覆盖率超99%,被动接管率优于100公里/次。同时,广汽成为全国首批 L3 自动驾驶准入的车企之一,达到行业领先水平。
而这背后,是一场关于"数据洪流"的硬仗。广汽投入在端到端自动驾驶的训练数据从PB级起步,并且已经逐步扩展到接近百PB规模,模型参数量规模从百兆起步,未来会要达到千兆以上,集群规模从千卡起步,未来也会进阶万卡。
广汽意识到:为满足技术快速迭代的需求,对主机厂而言,打造一个高性能,稳定可靠的AI基础设施至关重要。
于是,一场关于"自动驾驶数据、算力与工程体系"的攻坚战悄然打响。
智能驾驶进入"深水区",旧体系难以为继
过去几年,自动驾驶的技术路线经历了深刻变革:从早期基于规则的模块化架构,到如今主流的端到端大模型+VLA(视觉-语言-动作)范式,整个行业的研发逻辑正在被重塑。这一转变带来的最直接冲击,是数据量的指数级增长。为了研发一款具备市场竞争力的自动驾驶产品,广汽自动驾驶团队每天要处理的数据量攀升至近百PB级:摄像头图像、激光雷达点云、毫米波雷达信号、车辆状态信息......这些原始数据需要经过解包、切帧、标注、清洗、训练等多个环节,才能用于模型迭代。而在模型的训练、推理和仿真环节,还要保证集群运行的稳定性和资源的高利用率。
然而,在广汽自动驾驶研发团队的早期探索中,面临到一个几乎所有车企都会遇到的困局:数据多、流程散、效率低,传统的自建研发架构逐渐暴露出瓶颈:
-
单个clip(数据片段)处理耗时长达上百分钟;
-
百万级任务调度延迟高,资源利用率不足40%;
-
元数据分散在不同系统中,异常样本溯源困难;
-
模型训练排队严重,迭代周期长,难以应对复杂长尾场景。
与此同时,随着端到端大模型成为行业主流,数据闭环的速度直接决定了技术演进的节奏。谁能把数据流转得更快,谁就能在长尾场景覆盖、模型泛化能力和用户体验优化上建立代际优势。
联手阿里云:打造属于广汽的"智能端到端数据底座"
面对这场系统性挑战,广汽没有选择简单堆资源或者采购工具,而是决定与阿里云展开深度协同,共同构建一套面向未来的"智能端到端数据底座"。正值阿里云大数据 AI 平台全面升级其智能辅助驾驶解决方案,该方案覆盖从数据接入、处理、训练到推理仿真的全生命周期管理。这对正处于转型关键期的广汽而言,恰逢其时。借助阿里云大数据 AI 平台能力,广汽逐步构建起支撑智能驾驶业务可持续发展的技术底座。
"目前,广汽与阿里合力打造的智驾云已经高效稳定运行半年多。"广汽集团自动驾驶首席科学家周寅分享,"在这个过程中,我们整个AI基础设施的稳定性,资源利用率以及研发效率也取得了质的飞跃和提升。"  广汽基于阿里云大数据AI平台加速广汽GSD智能辅助驾驶系统迭代
广汽基于阿里云大数据AI平台加速广汽GSD智能辅助驾驶系统迭代
这不是一次简单的工具替换,而是一次面向未来的端到端数据底座范式升级。
第一步:优化数据产线,让数据真正"流动"起来
数据是燃料,但先要能"点燃"。广汽首先聚焦数据处理环节,引入阿里云 MaxCompute - MaxFrame 分布式计算框架,结合 DataWorks 一站式智能数据开发治理平台实现海量数据全流程自动化管理。 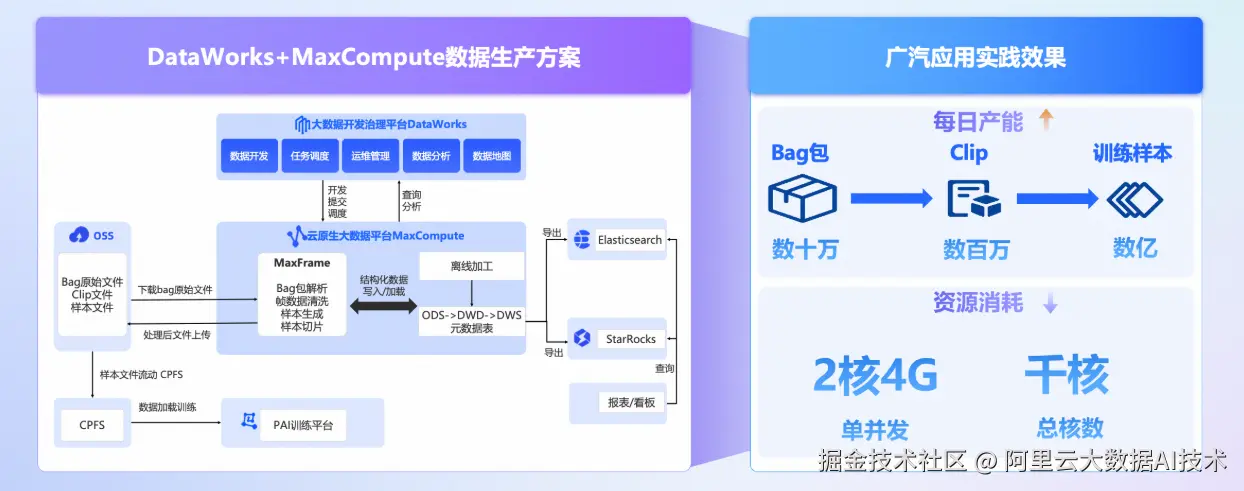
效果立竿见影:
-
单任务可调度数万Core 算力,最大20GB 单文件处理,数据包处理效率相较自建方案提升10倍以上;
-
日均可处理数十万 级数据包,生成超过数百万 clips和数亿训练样本;
-
借助 DataWorks 实现百万级任务的一站式开发与调度管理;
-
通过元数据血缘追踪,异常 clip 可快速回溯至原始数据源,大幅提升可维护性;
"通过和阿里云大数据 AI 平台的合作,把每天3个亿样本处理的周期,从周级别变成了天级别,保证了迭代的效率。"广汽集团基础架构负责人王麒钧表示,"这让我们可以把精力真正放在业务创新上。"
同时,平台采用弹性伸缩与按量付费模式,有效降低单个数据包的处理成本,显著减轻长期运营的资源与财务压力。
第二步:打通检索瓶颈,让"大海捞针"变得高效
在千亿级训练数据中精准定位特定场景(如雨天施工区、夜间行人横穿),是提升长尾场景覆盖率的关键。广汽可基于阿里云大数据 AI 平台的向量检索引擎,构建高性能检索能力:
-
对文本、图像、点云等多模态混合检索;
-
实现 PB 级非结构化数据的毫秒级响应;
这项能力不仅能提升数据挖掘效率,也为后续大模型预训练提供高质量语料基础。
第三步:加速模型训练,缩短从数据到决策的闭环周期
如果说数据是燃料,训练就是燃烧过程。
广汽依托于阿里云PAI平台和灵骏集群,支持千卡规模的训练任务,稳定训练4周以上不中断。同时借助PAI的企业级资源管理功能,广汽目前智算资源利用率可以做到90%以上。
值得高兴的是,广汽在模型训练效率上,成功应用了PAI Turbo-X的模型训练加速方案,在系统侧,数据侧,模型侧等多维度全方位加速:
- 系统侧:优化 CPU 亲和性、垃圾回收机制、动态编译、流水线并行和操作系统
- 数据侧:高性能的 DataLoader 引擎,优化数据预处理流程和实现智能训练样本分组
- 模型侧:算子、Module、优化器、优化策略、量化、CPU 和 GPU 设备的自动切换

最终在单训练任务数据规模增长了20倍,模型参数规模增长了10倍的情况下,取得了缩短训练时长50%的可喜收益。版本模型2天迭代1次,这在智驾研发里,是非常大的代际差距。
第四步:技术共创,探索AI基础设施和模型训练新范式
更值得期待的是,广汽并未止步于"使用",而是与阿里云共同探索下一代AI基础设施建设和模型训练新范式。
双方围绕 Lance File ------一种新兴的具有极致压缩比的列式非结构化数据格式,开展技术共创试点。利用其极致压缩比和内置索引能力,进一步降低存储开销、提升数据加载速度。
同时,探索结合阿里云大模型训练框架PAI-Megatron-Patch和强化学习框架PAI-ChatLearn等技术,进一步加速大模型模型训练和推理的进程。
这些共创和尝试,不仅是技术的优化,更是为未来大规模车云协同训练打下基础。
迈向成熟:从"解决问题"到"构建能力"
如今,广汽已将多条核心智驾数据产线建设在阿里云大数据 AI 平台,建立起一套稳定、高效、可扩展的端到端数据智能研发体系:
-
数据闭环周期缩短 1倍
-
数据处理效率提升 10倍
-
模型训练资源利用率翻番
-
研发运维人力投入显著降低
更重要的是,这套体系具备良好的延展性,能够支撑广汽在未来几年内持续升级感知、规控等模块的技术栈。
"我们会坚定的拥抱阿里云这个合作伙伴,在 Data+AI 这一层做持续的深度建设。"广汽集团基础架构负责人王麒钧指出,"这是广汽在自动驾驶发展各种不确定因素中,最确定的一部分。" 
广汽集团基础架构负责人王麒钧在云栖大会分享
结语:在深水区稳扎稳打,才是长远之道
今天,超过80%中国车企的智驾跑在阿里云大数据 AI 平台上。
这并非偶然,而是行业共识的体现:在AI驱动的时代,主机厂的核心竞争力,不再仅仅是"造车",更是"造系统"。
今天的广汽,已经找到了正确的方向:用先进的大数据 AI 平台,支撑持续打磨的技术底座和快速迭代的模型算法。
在这条通往高阶智能驾驶的路上,广汽始终稳扎稳打,而阿里云大数据 AI 平台也将作为广汽的坚实后盾,持续陪伴广汽一路前行。