7900 Stars 478 Forks 39 Issues 17 贡献者 MIT License Python语言
代码 : https://github.com/getomni-ai/zerox
主页 : OmniAI. Automate document workflows
更多AI开源软件 :AI开源 - 小众AI
zerox基于视觉模型 API 服务,提供了将 PDF 文档转化为 Markdown 的功能。其原理是先将原文件(如 pdf、docx)转换为图片,然后把图片发给视觉模型处理,最后汇总所有结果生成完整的 Markdown 文件。
主要功能
一种非常简单的 OCR 文档以进行 AI 摄取的方法。毕竟,文档应该是一种视觉表示。带有奇怪的布局、表格、图表等。视觉模型很有意义!
- 传入文件(pdf、docx、image 等)
- 将该文件转换为一系列图像
- 将每张图片传递给 GPT 并很好地请求 Markdown
- 聚合响应并返回 Markdown
Node Zerox安装和使用
npm install zeroxZerox 使用 和 用于 pdf => 图像处理步骤。这些应该会自动拉取,但您可能需要手动安装。graphicsmagickghostscript
在 linux 上使用:
sudo apt-get update
sudo apt-get install -y graphicsmagickNode 用法
**使用文件 URL**
import { zerox } from "zerox";
const result = await zerox({
filePath: "https://omni-demo-data.s3.amazonaws.com/test/cs101.pdf",
openaiAPIKey: process.env.OPENAI_API_KEY,
});**从本地路径**
import path from "path";
import { zerox } from "zerox";
const result = await zerox({
filePath: path.resolve(__dirname, "./cs101.pdf"),
openaiAPIKey: process.env.OPENAI_API_KEY,
});选项
const result = await zerox({
// Required
filePath: "path/to/file",
openaiAPIKey: process.env.OPENAI_API_KEY,
// Optional
cleanup: true, // Clear images from tmp after run.
concurrency: 10, // Number of pages to run at a time.
correctOrientation: true, // True by default, attempts to identify and correct page orientation.
errorMode: ErrorMode.IGNORE, // ErrorMode.THROW or ErrorMode.IGNORE, defaults to ErrorMode.IGNORE.
maintainFormat: false, // Slower but helps maintain consistent formatting.
maxRetries: 1, // Number of retries to attempt on a failed page, defaults to 1.
maxTesseractWorkers: -1, // Maximum number of tesseract workers. Zerox will start with a lower number and only reach maxTesseractWorkers if needed.
model: "gpt-4o-mini", // Model to use (gpt-4o-mini or gpt-4o).
onPostProcess: async ({ page, progressSummary }) => Promise<void>, // Callback function to run after each page is processed.
onPreProcess: async ({ imagePath, pageNumber }) => Promise<void>, // Callback function to run before each page is processed.
outputDir: undefined, // Save combined result.md to a file.
pagesToConvertAsImages: -1, // Page numbers to convert to image as array (e.g. `[1, 2, 3]`) or a number (e.g. `1`). Set to -1 to convert all pages.
tempDir: "/os/tmp", // Directory to use for temporary files (default: system temp directory).
trimEdges: true, // True by default, trims pixels from all edges that contain values similar to the given background colour, which defaults to that of the top-left pixel.
});该选项尝试通过将前一页的输出作为下一页的附加上下文传入,以一致的格式返回 markdown。这需要请求同步运行,因此速度要慢得多。但是,如果您的文档包含大量表格数据,或者经常包含跨页的表格,则此属性很有价值。maintainFormat
Request #1 => page_1_image
Request #2 => page_1_markdown + page_2_image
Request #3 => page_2_markdown + page_3_image示例输出
{
completionTime: 10038,
fileName: 'invoice_36258',
inputTokens: 25543,
outputTokens: 210,
pages: [
{
content: '# INVOICE # 36258\n' +
'**Date:** Mar 06 2012 \n' +
'**Ship Mode:** First Class \n' +
'**Balance Due:** $50.10 \n' +
'## Bill To:\n' +
'Aaron Bergman \n' +
'98103, Seattle, \n' +
'Washington, United States \n' +
'## Ship To:\n' +
'Aaron Bergman \n' +
'98103, Seattle, \n' +
'Washington, United States \n' +
'\n' +
'| Item | Quantity | Rate | Amount |\n' +
'|--------------------------------------------|----------|--------|---------|\n' +
"| Global Push Button Manager's Chair, Indigo | 1 | $48.71 | $48.71 |\n" +
'| Chairs, Furniture, FUR-CH-4421 | | | |\n' +
'\n' +
'**Subtotal:** $48.71 \n' +
'**Discount (20%):** $9.74 \n' +
'**Shipping:** $11.13 \n' +
'**Total:** $50.10 \n' +
'---\n' +
'**Notes:** \n' +
'Thanks for your business! \n' +
'**Terms:** \n' +
'Order ID : CA-2012-AB10015140-40974 ',
page: 1,
contentLength: 747,
status: 'SUCCESS',
}
],
summary: {
failedPages: 0,
successfulPages: 1,
totalPages: 1,
},
}Python Zerox安装和使用
(Python SDK - 支持来自不同提供商的视觉模型,如 OpenAI、Azure OpenAI、Anthropic、AWS Bedrock 等)
安装
-
在系统上安装 **poppler**,它应该在 path 变量中可用。请参阅 pdf2image 文档以获取平台说明。
-
安装 py-zerox:
pip install py-zerox
该函数是一个异步 API,它使用视觉模型执行 OCR(光学字符识别)以降价。它处理 PDF 文件并将其转换为 markdown 格式。在使用此 API 之前,请确保为模型和模型提供程序设置环境变量。pyzerox.zerox
请参阅 LiteLLM 文档 来设置环境并传递正确的模型名称。
用法
from pyzerox import zerox
import os
import json
import asyncio
### Model Setup (Use only Vision Models) Refer: https://docs.litellm.ai/docs/providers ###
## placeholder for additional model kwargs which might be required for some models
kwargs = {}
## system prompt to use for the vision model
custom_system_prompt = None
# to override
# custom_system_prompt = "For the below pdf page, do something..something..." ## example
###################### Example for OpenAI ######################
model = "gpt-4o-mini" ## openai model
os.environ["OPENAI_API_KEY"] = "" ## your-api-key
###################### Example for Azure OpenAI ######################
model = "azure/gpt-4o-mini" ## "azure/<your_deployment_name>" -> format <provider>/<model>
os.environ["AZURE_API_KEY"] = "" # "your-azure-api-key"
os.environ["AZURE_API_BASE"] = "" # "https://example-endpoint.openai.azure.com"
os.environ["AZURE_API_VERSION"] = "" # "2023-05-15"
###################### Example for Gemini ######################
model = "gemini/gpt-4o-mini" ## "gemini/<gemini_model>" -> format <provider>/<model>
os.environ['GEMINI_API_KEY'] = "" # your-gemini-api-key
###################### Example for Anthropic ######################
model="claude-3-opus-20240229"
os.environ["ANTHROPIC_API_KEY"] = "" # your-anthropic-api-key
###################### Vertex ai ######################
model = "vertex_ai/gemini-1.5-flash-001" ## "vertex_ai/<model_name>" -> format <provider>/<model>
## GET CREDENTIALS
## RUN ##
# !gcloud auth application-default login - run this to add vertex credentials to your env
## OR ##
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
vertex_credentials=vertex_credentials_json
## extra args
kwargs = {"vertex_credentials": vertex_credentials}
###################### For other providers refer: https://docs.litellm.ai/docs/providers ######################
# Define main async entrypoint
async def main():
file_path = "https://omni-demo-data.s3.amazonaws.com/test/cs101.pdf" ## local filepath and file URL supported
## process only some pages or all
select_pages = None ## None for all, but could be int or list(int) page numbers (1 indexed)
output_dir = "./output_test" ## directory to save the consolidated markdown file
result = await zerox(file_path=file_path, model=model, output_dir=output_dir,
custom_system_prompt=custom_system_prompt,select_pages=select_pages, **kwargs)
return result
# run the main function:
result = asyncio.run(main())
# print markdown result
print(result)参数
async def zerox(
cleanup: bool = True,
concurrency: int = 10,
file_path: Optional[str] = "",
maintain_format: bool = False,
model: str = "gpt-4o-mini",
output_dir: Optional[str] = None,
temp_dir: Optional[str] = None,
custom_system_prompt: Optional[str] = None,
select_pages: Optional[Union[int, Iterable[int]]] = None,
**kwargs
) -> ZeroxOutput:
...参数
- **cleanup** (bool, optional): 是否在处理后清理临时文件。默认为 True。
- **concurrency** (int,可选): 要运行的并发进程数。默认值为 10。
- **file_path** (可选str, 可选): 要处理的 PDF 文件的路径。默认为空字符串。
- **maintain_format** (bool,可选): 是否保留上一页的格式。默认为 False。
- **model** (str,可选): 用于生成完成项的模型。默认为 "gpt-4o-mini"。 有关正确的模型名称,请参阅 LiteLLM Providers,因为它可能因提供商而异。
- **output_dir** (Optionalstr, optional): 用于保存 Markdown 输出的目录。默认为 None。
- **temp_dir** (str,可选): 存储临时文件的目录,默认为系统临时目录中的某个命名文件夹。如果已经存在,则内容将在 zerox 使用之前被删除。
- **custom_system_prompt** (str,可选): 用于模型的系统提示符,这将覆盖默认的系统提示符 zerox。通常,除非你想要一些特定的行为,否则它不是必需的。设置后,它将引发友好警告。默认为 None。
- **select_pages** (optionalunion\[int, Iterable\[int]], 可选): 要处理的页面,可以是单个页码或页码的可迭代对象,默认为 None
- **kwargs** (dict,可选): 要传递给 litellm.completion 方法的其他关键字参数。 有关详细信息,请参阅 LiteLLM 文档 和 完成输入 。
返回
- 零x输出: 包含模型生成的 Markdown 内容以及一些元数据(请参阅下文)。
示例输出("azure/gpt-4o-mini"的输出)
Note: The output is mannually wrapped for this documentation for better readability.
ZeroxOutput(
completion_time=9432.975,
file_name='cs101',
input_tokens=36877,
output_tokens=515,
pages=[
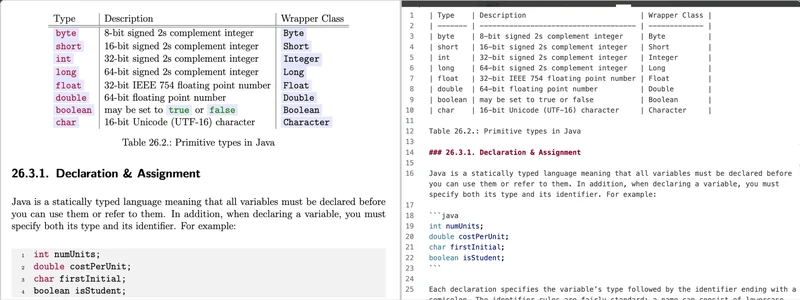
Page(
content='| Type | Description | Wrapper Class |\n' +
'|---------|--------------------------------------|---------------|\n' +
'| byte | 8-bit signed 2s complement integer | Byte |\n' +
'| short | 16-bit signed 2s complement integer | Short |\n' +
'| int | 32-bit signed 2s complement integer | Integer |\n' +
'| long | 64-bit signed 2s complement integer | Long |\n' +
'| float | 32-bit IEEE 754 floating point number| Float |\n' +
'| double | 64-bit floating point number | Double |\n' +
'| boolean | may be set to true or false | Boolean |\n' +
'| char | 16-bit Unicode (UTF-16) character | Character |\n\n' +
'Table 26.2.: Primitive types in Java\n\n' +
'### 26.3.1. Declaration & Assignment\n\n' +
'Java is a statically typed language meaning that all variables must be declared before you can use ' +
'them or refer to them. In addition, when declaring a variable, you must specify both its type and ' +
'its identifier. For example:\n\n' +
'```java\n' +
'int numUnits;\n' +
'double costPerUnit;\n' +
'char firstInitial;\n' +
'boolean isStudent;\n' +
'```\n\n' +
'Each declaration specifies the variable's type followed by the identifier and ending with a ' +
'semicolon. The identifier rules are fairly standard: a name can consist of lowercase and ' +
'uppercase alphabetic characters, numbers, and underscores but may not begin with a numeric ' +
'character. We adopt the modern camelCasing naming convention for variables in our code. In ' +
'general, variables must be assigned a value before you can use them in an expression. You do not ' +
'have to immediately assign a value when you declare them (though it is good practice), but some ' +
'value must be assigned before they can be used or the compiler will issue an error.\n\n' +
'The assignment operator is a single equal sign, `=` and is a right-to-left assignment. That is, ' +
'the variable that we wish to assign the value to appears on the left-hand-side while the value ' +
'(literal, variable or expression) is on the right-hand-side. Using our variables from before, ' +
'we can assign them values:\n\n' +
'> 2 Instance variables, that is variables declared as part of an object do have default values. ' +
'For objects, the default is `null`, for all numeric types, zero is the default value. For the ' +
'boolean type, `false` is the default, and the default char value is `\\0`, the null-terminating ' +
'character (zero in the ASCII table).',
content_length=2333,
page=1
)
]
)支持的文件类型
我们使用 和 的组合来执行 document => 图像转换。对于非图像/非 pdf 文件,我们使用 libreoffice 将该文件转换为 pdf,然后再转换为图像。libreofficegraphicsmagick
[
"pdf", // Portable Document Format
"doc", // Microsoft Word 97-2003
"docx", // Microsoft Word 2007-2019
"odt", // OpenDocument Text
"ott", // OpenDocument Text Template
"rtf", // Rich Text Format
"txt", // Plain Text
"html", // HTML Document
"htm", // HTML Document (alternative extension)
"xml", // XML Document
"wps", // Microsoft Works Word Processor
"wpd", // WordPerfect Document
"xls", // Microsoft Excel 97-2003
"xlsx", // Microsoft Excel 2007-2019
"ods", // OpenDocument Spreadsheet
"ots", // OpenDocument Spreadsheet Template
"csv", // Comma-Separated Values
"tsv", // Tab-Separated Values
"ppt", // Microsoft PowerPoint 97-2003
"pptx", // Microsoft PowerPoint 2007-2019
"odp", // OpenDocument Presentation
"otp", // OpenDocument Presentation Template
];