1.组合两个表(外连接)

sql
select p.firstName,p.lastName,a.city,a.state
from Person p left join Address a
on p.personId = a.personId;以左边表为基准,去连接右边的表。取两表的交集和左表的全集
2.第二高的薪水(子查询、ifnull)

解法一(子查询与LIMIT 子句):
limit的两种写法
limit 起始索引,查询数据的个数
limit 起始索引 offset 查询数据的个数
sql
select
(select distinct salary from Employee order by salary desc limit 1 offset 1)
as SecondHighestSalary;这样的写法就类似于
sqlselect 1+2 as SecondHighestSalary;不需要有数据来源,因为这个表达式的计算结果已经是一个数据了。
这里只是给数据起一个别名。若是子查询数据为空,那么返回的就是null 而不是空了
总之。在 SQL 中使用子查询而没有 FROM 子句的情况通常是为了计算一个表达式或获取一个基于特定逻辑的单一结果,子查询本身提供了数据来源和处理逻辑,无需再通过 FROM 从物理表中获取数据。但在实际应用中,需要考虑性能和可维护性,避免过度复杂的子查询结构。
解法二(使用 IFNULL 和 LIMIT 子句):
sql
select ifnull(
(select distinct salary from Employee order by salary desc limit 1,1),null
)
as SecondHighestSalary;由于若查询结果为空,返回null
因此使用 ifnull 流程控制函数 更加合适
ifnull(value1,value2)
如果value1为null,就返回value2
如果不为空,就返回value1
注意,若是value1为一个sql语句,要给它加上括号
3.第N高的薪水(函数、limit不能跟表达式)

答案:
sql
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare M INT;
set M = N-1;
RETURN (
select distinct salary from Employee order by salary desc limit M,1
);
END注意,limit中参数不能写成表达式的形式。也就是不能写成N-1
需要单独定义一个变量 M = N-1
代码解释
这个 SQL 代码创建了一个名为 getNthHighestSalary 的函数,该函数接收一个整数参数 N,用于表示要查找第 N 高的薪水。函数的返回值是一个整数,代表第 N 高的薪水值。
变量声明:
sqldeclare M INT;变量赋值:
sqlset M = N-1;查询语句
sqlRETURN ( select salary from Employee order by salary desc limit M,1 );
4.分数排名(窗口函数(排名函数dense_rank())

窗口函数的基本结构:
sql
<窗口函数>([参数]) OVER (
[PARTITION BY <分区列1>, <分区列2>,...]
[ORDER BY <排序列1> [ASC | DESC], <排序列2> [ASC | DESC],...]
[ROWS | RANGE <窗口范围说明>]
)各部分解释:
窗口函数:
这是核心部分,可以是聚合函数(如
SUM()、AVG()、COUNT()、MAX()、MIN()等)或排名函数(如RANK()、DENSE_RANK()、ROW_NUMBER()等)。OVER 子句:
- 是窗口函数的关键字,表明后面的内容是对窗口的定义。
PARTITION BY:
这是可选的。用于将数据划分为不同的分区,类似于 GROUP BY 的功能,但不会像 GROUP BY 那样对数据进行聚合操作。窗口函数会在每个分区内独立执行。
例如:partition by ...
sqlPARTITION BY department会将数据按照部门进行分区,窗口函数将在每个部门内分别计算。
ORDER BY:
通常是必需的,用于对分区内的数据进行排序。这会影响排名函数的结果,以及聚合函数的计算顺序。
例如:
sqlORDER BY salary DESC会将分区内的数据按照薪水降序排列。
ROWS | RANGE 窗口范围说明:
这也是可选的,用于进一步定义窗口的范围。
ROWS 基于物理行,例如
sqlROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING表示当前行的前一行到后一行的范围。
RANGE 基于逻辑值,例如
sqlRANGE BETWEEN 10 PRECEDING AND 10 FOLLOWING
表示在当前行的值的基础上,范围是比当前行的值小 10 到大 10 的数据范围。
排名函数(如RANK()、DENSE_RANK()、ROW_NUMBER()等)。
方法一:排名函数dense_rank()(推荐)
rank() 排名的特点是 1 2 2 4 5 5 5 8 9
dense_rank() 排名的特点是 1 2 2 3 4 5 5 5 6
ROW_NUMBER() 特点是 1 2 3 4 5 6 7 8 9
sql
select s.score,dense_rank()
over(order by s.score desc) as 'rank'
from Scores s;方法二:使用 COUNT(DISTINCT ...) 的相关子查询
sql
SELECT
S1.score,
(
SELECT
COUNT(DISTINCT S2.score)
FROM
Scores S2
WHERE
S2.score >= S1.score
) AS 'rank'
FROM
Scores S1
ORDER BY
S1.score DESC;这段 SQL 代码的主要目的是为 Scores 表中的每个 score 计算排名。它使用了一个相关子查询来计算排名,排名的依据是大于或等于当前分数的不同分数的数量。
主查询:
SELECT S1.score:从 Scores 表中选择 score 列作为主查询的一部分。
子查询部分:
COUNT(DISTINCT S2.score): 计算不同分数的数量。
FROM Scores S2: 从 Scores 表中选取数据。
**WHERE S2.score >= S1.score:**这是关键部分,对于主查询中的每个 S1.score,子查询会统计 Scores 表中大于或等于 S1.score 的不同分数的数量。最终结果是通过 ORDER BY S1.score DESC 对主查询的结果按照分数降序排列。
5.连续出现的数字(自连接)
自连接使用场景
1.比较同一表中不同行的数据:
- 示例场景:查找表中相邻行的数据关系,例如找出连续出现的记录。
2.查找父子关系或层次关系:
- 示例场景:在存储了层次结构信息的表中查找父子节点关系。
3.找出重复记录:
- 示例场景:找出表中具有相同数据的行。
4.时间序列分析:
- 示例场景:在存储了时间序列数据的表中,找出连续时间点的数据。

sql
select distinct l1.num as ConsecutiveNums
from Logs l1,Logs l2,Logs l3
where
l1.id = l2.id-1 and
l2.id = l3.id-1 and
l1.num = l2.num and
l2.num = l3.num;找出至少出现三次的数字。因此进行自连接三次
条件是
第一张表id 等于 第二张表 id-1
第二张表id 等于 第三张表 id-1
且
第一张表num 等于 第二张表 num
第二张表num 等于 第三张表 num
6.超过经理收入的员工(自连接)

解法一:自连接(隐式where语句)
sql
select e1.name as Employee
from Employee e1,Employee e2
where e1.managerId = e2.id and e1.salary > e2.salary; SQL解释
表的自连接:
sqlfrom Employee e1, Employee e2这里将 Employee 表自连接,使用别名 e1 表示员工,e2 表示经理。
sqlwhere e1.managerId = e2.id and e1.salary > e2.salary;e1.managerId = e2.id:
这是自连接的关键条件, 它将 e1 表中的 managerId 与 e2 表中的 id 进行连接,意味着 e2 表中的员工是 e1 表中员工的经理。e1.salary > e2.salary:
**这是筛选条件,**它确保只选择那些员工的工资(e1.salary)高于其经理的工资(e2.salary)的记录。
解法二:自连接(显示on语句)
sql
SELECT
a.NAME AS Employee
FROM Employee AS a JOIN Employee AS b
ON a.ManagerId = b.Id
AND a.Salary > b.Salary
;一、自连接过程:
首先,将 Employee 表自连接,形成笛卡尔积。这意味着 e1 和 e2 表的组合将包含所有可能的行对,即每个 e1 中的行将与 e2 中的所有行组合在一起,总共会有 种组合(假设 Employee 表有 n 行)。对于我们的示例表,会有6的平方 = 36 种组合,但很多组合将不符合条件。
e1.managerId = e2.id:这一条件将确保 e1 中的员工的经理是 e2 中的员工。例如:
对于 e1 中的 Bob(id = 2,managerId = 1),只有当 e2 中的 id = 1 时,这个条件才满足。所以,Bob 可以和 Alice 组合。
e1.salary > e2.salary:在上述满足 e1.managerId = e2.id 的组合中,进一步筛选出员工(e1)工资高于经理(e2)工资的组合:
对于 Bob(e1)和 Alice(e2)的组合:Bob 的工资是 6000,Alice 的工资是 5000,满足 e1.salary > e2.salary,所以 Bob 会被选中。
注意e1.managerId = e2.id 与 e1.id = e2.managerId的区别
e1.managerId = e2.id
这个条件表示 e2 表中的员工是 e1 表中员工的经理。也就是说,通过 managerId 建立了从员工(e1)到其经理(e2)的关联。
e1.id = e2.managerId:这个条件表示 e1 表中的员工是 e2 表中员工的经理。与第一个语句相反,这里是通过 managerId 建立了从经理(e1)到其下属员工(e2)的关联。
7.找到重复的电子邮箱(自连接 | group by... having)

法一:自连接(效率低一点)
sql
select distinct p1.email as Email
from Person p1, Person p2
where p1.id <> p2.id and p1.email = p2.email; 法二:(GROUP BY 和临时表) (比自连接效率高)
表子查询
先
sqlselect email, count(*) as num from Person group by email得到临时表
再根据这个表找到email数量大于 1 的 email就可以了

sql
select email as Email
from (select email, count(*) as num from Person group by email) t
where num > 1;法三、使用 GROUP BY 和 HAVING 条件 (效率相对高一点)
sql
select email from Person
group by email
having count(*) > 1;分完组之后,再用having count(*)来计算组内的行数。
再筛选组内行数大于1的email
8.从不订购的客户(is null)

注意:判断是否为null 要用 is 而不是 =
法一:列子查询(子查询返回的是一列数据)
sql
select name as Customers from Customers
where id
not in (select customerId from Orders);法二:左连接(Left Join)
sql
select name as Customers from Customers c
left join Orders o
on c.id = o.customerId where customerId is null; 9.部门工资最高的员工
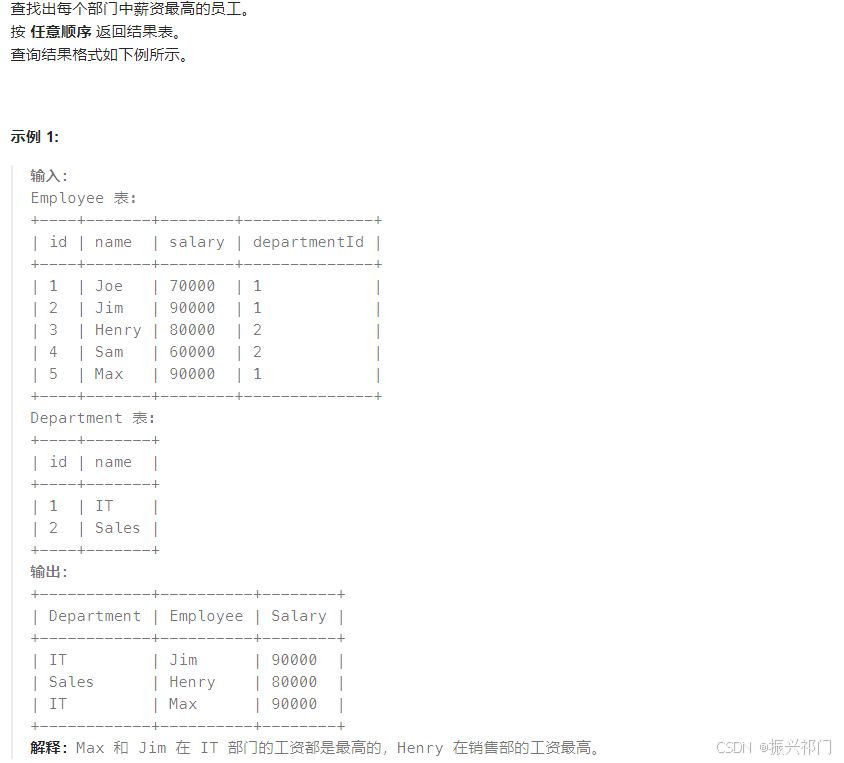
法一:隐式内连接
sql
select d.name Department,e.name Employee,e.salary
from Employee e,Department d
where e.departmentId = d.id
and e.salary >=
all (select salary from Employee t where e.departmentId = t.departmentId);
sqle.salary >= all (select salary from Employee t where e.departmentId = t.departmentId);员工薪资 ≥ 相同部门的薪资。
法二、窗口函数(MAX()+行子查询)

sql
select d.name AS 'Department',e.name AS 'Employee',Salary
FROM Employee e JOIN Department d ON e.DepartmentId = d.Id
where (e.DepartmentId , Salary) in
(select DepartmentId, MAX(Salary) from Employee
GROUP BY DepartmentId);where 条件 绑定了部门 id 和 薪资水平 in
查出来的 部门id 和最高的薪资水平。
sql
select DepartmentId, MAX(Salary) from Employee
GROUP BY DepartmentId;
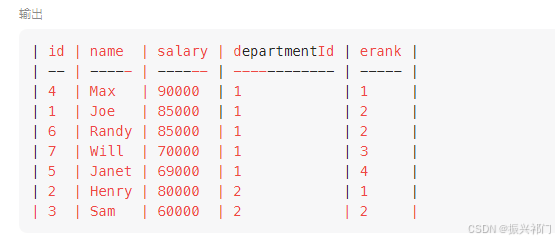
法三:窗口函数(dense_rank() partition by)(推荐)
sql
select d.name AS 'Department',e.name AS 'Employee',e.salary Salary
from
(select *,dense_rank() over(partition by departmentId order by salary desc) as erank
from Employee) e ,Department d
where e.departmentId = d.Id
and erank <= 1;10.部门工资前三高的所有员工

法一:窗口函数(dense_rank())
sql
select d.name as Department, e.name as Employee,salary Salary from
(select *, dense_rank()
over(partition by departmentId order by salary desc) as erank
from Employee) e
left join Department d on e.departmentId = d.id
where erank <= 3;其中
sqlselect *, dense_rank() over(partition by departmentId order by salary desc) as erank from Employee;#根据部门id分组,再对组内按照薪水从大到小排序,并生成对应的排名编号
再右连接Deparment表 输出排名编号≤3的