问题描述
在flink1.16(甚至以前的版本)中,使用rank()或者dense_rank()进行排序时,某些场景会导致报错空指针NPE(NullPointerError)
报错内容如下

该报错没有行号/错误位置,无法排查
现状
目前已经确认为bug,根据github上的PR日志,目前在1.18及以上的版本中已经修复,现阶段用老版本的Coder们只能用row_number来代替下。
在新版本中,通过添加为空情况的判断,来避免掉了这个报错。
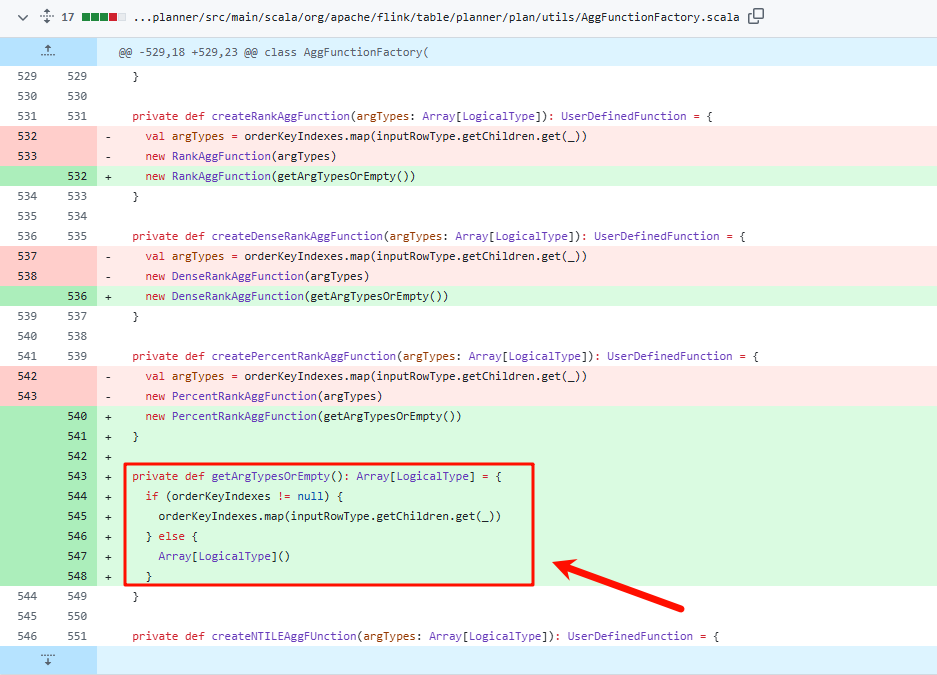
BUG问题表现及修复的方式具体看FLINK-27741table-planner Fix NPE when use dense_rank() and rank()... by chenzihao5 · Pull Request #19797 · apache/flink · GitHub
总结
个人在排查过程中经历了极大的困难,主要原因是国内搜索引擎和gpt并未给出相关的结论,最后一页页翻apache issue找到了原因。