在终端命令窗口不能直接执行select,creat等HQL命令,需要先进入hive之后才能执行,比较麻烦,但是如果使用Hive Shell就可以直接执行

在终端只执行一次Hive命令

-e 参数, "execute"(执行),使用-e参数后会在执行完Hive的命令后退出Hive
使用场景: 用Hive执行封装脚本
-S参数, "silent"(静默) , Hive 会减少输出的信息量,只显示查询结果,而不会显示额外的日志或进度信息。这在脚本中或需要最小化输出时非常有用
示例1

示例2
-S参数

在引号里面还需要套单引号时,单引号外层的引号使用双引号
示例3


在终端单独执行SQL文件

示例4
hql文件命名规范: 后缀名使用hql或sql

在Hive里执行终端命令

示例5

并非所有的Linux命令都能在Hive中运行,具体支持哪些命令可能取决于Hive的配置和运行环境
示例6

在终端执行HDFS命令

示例6

使用历史命令和补全命令

显示当前库
直接在hive里面使用ues shao,不显示库名,使用select不显示字段名

显示当前库的方法
方法1: 永久修改,直接修改hive的配置文件,如果是公司的服务器不建议修改

方法2:在当前会话里设置该参数

示例: 设置完参数后的效果

查看当前参数设置的值

local模式
本地模式可以提高查询效率 , 建议在进行hive操作前打开

在DataGrip等第三方使用命令时,前面加set

单独hive命令和sql文件的使用场景

启动MapReduce的情况

启动MapReduce的标志
比如示例3就启动了MapReduce
set mapreduce.job.reduces=<number>
用于在Hadoop的MapReduce作业中设置一个常量数量的reducer。在MapReduce编程模型中,作业通常分为两个阶段:map阶段和reduce阶段。map阶段负责处理输入数据并生成中间键值对,而reduce阶段则对map阶段输出的相同键的所有值进行归并和处理,生成最终结果。
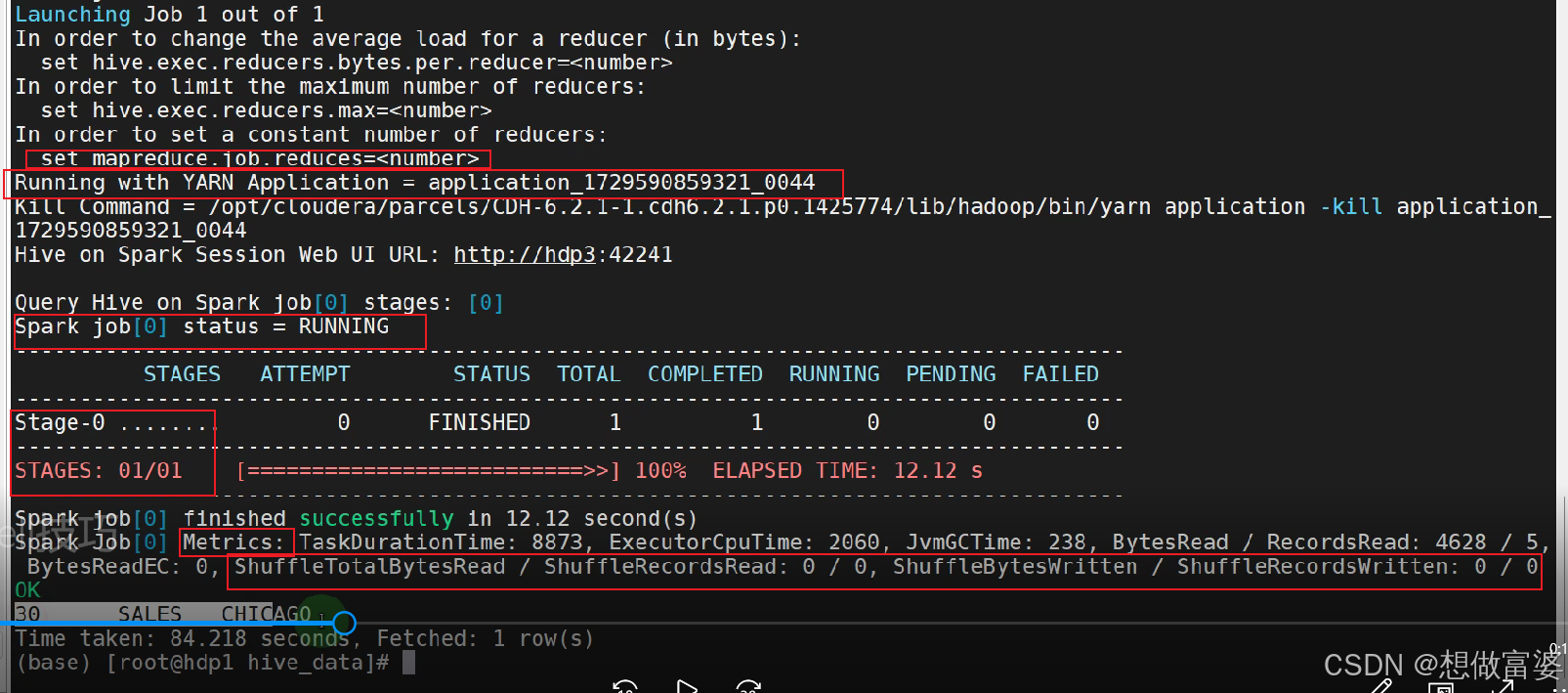
Running with YARN Application = application_1729590859321_0044
表明作业是在 YARN 上运行的,YARN 是 Hadoop 的资源管理器,通常与 MapReduce 和 Spark 作业一起使用。
Spark job[0] status = RUNNING
表示正在运行的 Spark 作业。这表明 Hive 正在使用 Spark 作为执行引擎
STAGES: 01/01 和 Stage-0
这表明作业被分成了一个或多个阶段(stage),这是 MapReduce 和 Spark 作业的典型特征。
Metrics
截图中显示了执行的指标,如 TaskDurationTime, ExecutorCpuTime, JvmGcTime, BytesRead 等。这些指标通常与分布式计算框架(如 MapReduce 和 Spark)相关。
Shuffle 信息
虽然截图中显示 ShuffleTotalBytesRead / ShuffleRecordsRead: 0 / 0 和 ShuffleBytesWritten / ShuffleRecordsWritten: 0 / 0,这意味着在这个阶段没有发生 shuffle 操作,但这并不完全排除 MapReduce 的可能性,因为有些查询可能不需要 shuffle 阶段。