个人的一些思考,请大家批评指正。
这个问题,首先当然是在恰当的时间出现,模型性能跻身世界一流,又开源,戳破了OpenAI和英伟达潜心构造的叙事逻辑。
DeepSeek为什么强?四个方面:模型的智能水平、训练成本、推理成本和用户体验。
一、DeepSeek的智能水平
DeepSeek V3的智能水平,技术报告展现的性能对比图:
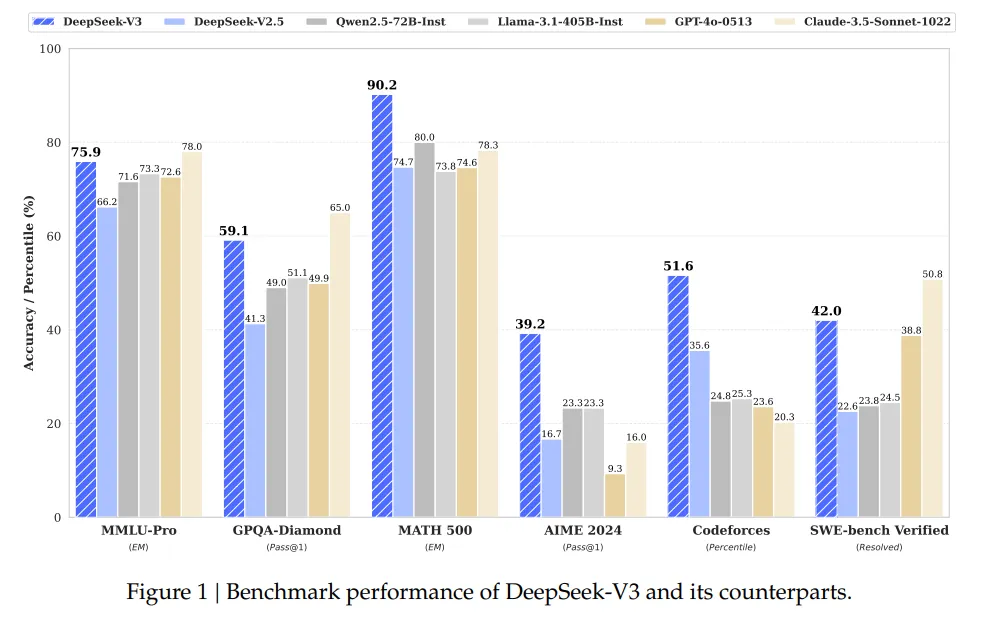
是什么导致了DeepSeek的模型性能,是模型架构吗?MoE、MLA这些?或许有一点关系,但是应该不是主要因素,决定模型性能的,主要应该是DeepSeek没有开源的内容------数据集以及训练时的数据配比。
去年看到OpenAI的一名员工的博客,内容摘录如下:
数据即模型!来自 OpenAI 模型炼丹师的 insight!人脑也是一样,其思想无限逼近于其接收到的信息;你灌输什么,他就呈现什么!
作者在 OpenAI 工作近一年,观察到生成模型的训练过程显示模型行为主要由数据集决定,而非架构、超参数或优化器选择。
🎯 Key Points
-
作者训练了大量生成模型;
-
观察到所有训练运行之间存在相似性;
-
模型高度逼近其数据集,学习到的不仅是狗或猫的概念,还有不重要的分布间隙;
-
在相同数据集上训练足够长时间,任何具有足够权重和训练时间的模型都会收敛到相同点;
-
大型扩散卷积网络和 ViT 生成器会生成相同的图像;
-
自回归采样和扩散方法也会生成相同的图像;
-
这表明模型行为不由架构、超参数或优化器选择决定,而是由数据集决定;
-
其他因素只是有效地将计算交付给逼近数据集的手段;
-
当提到"Lambda"、"ChatGPT"、"Bard"或"Claude"时,指的是数据集,而不是模型权重。
LLM预训练scaling law的发展,一开始强调模型要大,然后是数据要多,再后来就是强调数据的质量。数据质量方面,一方面是强调数据质量,通过专家撰写高质量数据、以及各种数据筛选方法和工具,保证数据质量是第一位的;第二方面,不断增加数学、逻辑、代码等能够提升大模型理性能力的数据配比比例,尤其在模型训练退火阶段,调整数据混合配比,增加高质量数据等等。
总之,我的猜测,DeepSeek V3的性能好,主要是因为数据集的原因。
DeepSeek R1的性能好,首先来源于DeepSeek V3底座模型的能力够,其次是DeepSeek R1成功摸索了一套RL方法,另外,推理成本低也会导致推理的性能增强。
二、DeepSeek的训练成本和推理成本
DeepSeek V3的训练成本,那个600万美金,从一开始,我的观点就是听听得了,只是成功训练一次的成本,不包括数据集、探索以及人力成本。AI这个事,可能最费劲的是数据集,相比数据,训练应该在其次。当然,不可否认,DeepSeek的训练成本确实低,这个确实是因为模型架构、以及训练方法。DeepSeek的训练成本低,主要是MoE和训练的低精度技术。MLA并不降低训练成本,只是推理成本低。模型的MTP,主要作用是训练更加稳定,当然,训练稳定了训练成本也会更低,细看DeepSeek V3的技术报告,看不出MTP提升模型性能,尤其的最大尺寸的模型性能。LLM的训练是一个细致活,还有其他的因素,包括PTX的使用、通信的优化等等。
DeepSeek V3的推理成本低,模型架构中的MLA、MoE和MTP等技术,应该均有贡献。
三、DeepSeek的用户体验
DeepSeek的用户体验方面嘛。首先说,时尚这个东西,之所以称为时尚,就在于难于预测。体验首先来自民心,DeepSeek撼动了美国AI界,提升了国人信心,就已经获得了最大民心。
对于用户体验,具体来说,看到有说DeepSeek说话犀利、有情绪价值,不像机器人,更像人。网上关于周鸿祎、以及为什么DeepSeek来自初创公司而不是互联网大厂这些问题,我也试了,确实可以复刻,确实犀利,敢说!但是呢,这里的原因,恐怕不是因为模型的智能水平,而是模型的最后的对齐方面,在模型的后训练方面,模型的输出对齐到了这种风格。也说明DeepSeek团队确实有性格。但是,这种风格,对于其他的LLM团队,应该不难,只是敢不敢愿不愿的问题。