1.概述
掌握如何借助 DeepSeek R1 与 Ollama 搭建检索增强生成(RAG)系统。本文将通过代码示例,为你提供详尽的分步指南、设置说明,分享打造智能 AI 应用的最佳实践。
2.内容
2.1 为什么选择DeepSeek R1?
在这篇文章中,我们将探究性能上可与 OpenAI 的 o1 相媲美、但成本却低 95% 的 DeepSeek R1,如何为你的检索增强生成(RAG)系统带来强大助力。我们来深入剖析为何开发者们纷纷热衷于这项技术,以及你怎样利用它构建自己的 RAG 流程。
DeepSeek R1 的 15 亿参数模型在这方面表现出色,原因如下:
- 精准检索:每个答案仅关联 3 个文档片段
- 严格提示:采用 "我不知道" 策略,避免模型产生幻觉
- 本地执行:与云 API 相比,实现零延迟
环境:
| 组件 | 成本 |
|---|---|
| DeepSeek R1 1.5B | 免费 |
| Ollama | 免费 |
| 16GB 内存的个人电脑 | 0 元 |
2.2 构建本地 RAG 系统所需的条件
1.Ollama
Ollama 允许你在本地运行诸如 DeepSeek R1 之类的模型。
- 下载:Ollama
- 设置:通过终端安装并运行以下命令。
ollama run deepseek-r1 # For the 7B model (default) 
2.DeepSeek R1 模型
DeepSeek R1 的参数范围从 1.5B 到 671B。对于轻量级 RAG 应用程序,请从1.5B 模型开始。
ollama run deepseek-r1:1.5b 提示:更大的模型(例如 70B)提供更好的推理能力,但需要更多的 RAM。

2.3 构建 RAG 管道
1.导入库
我们将使用:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama 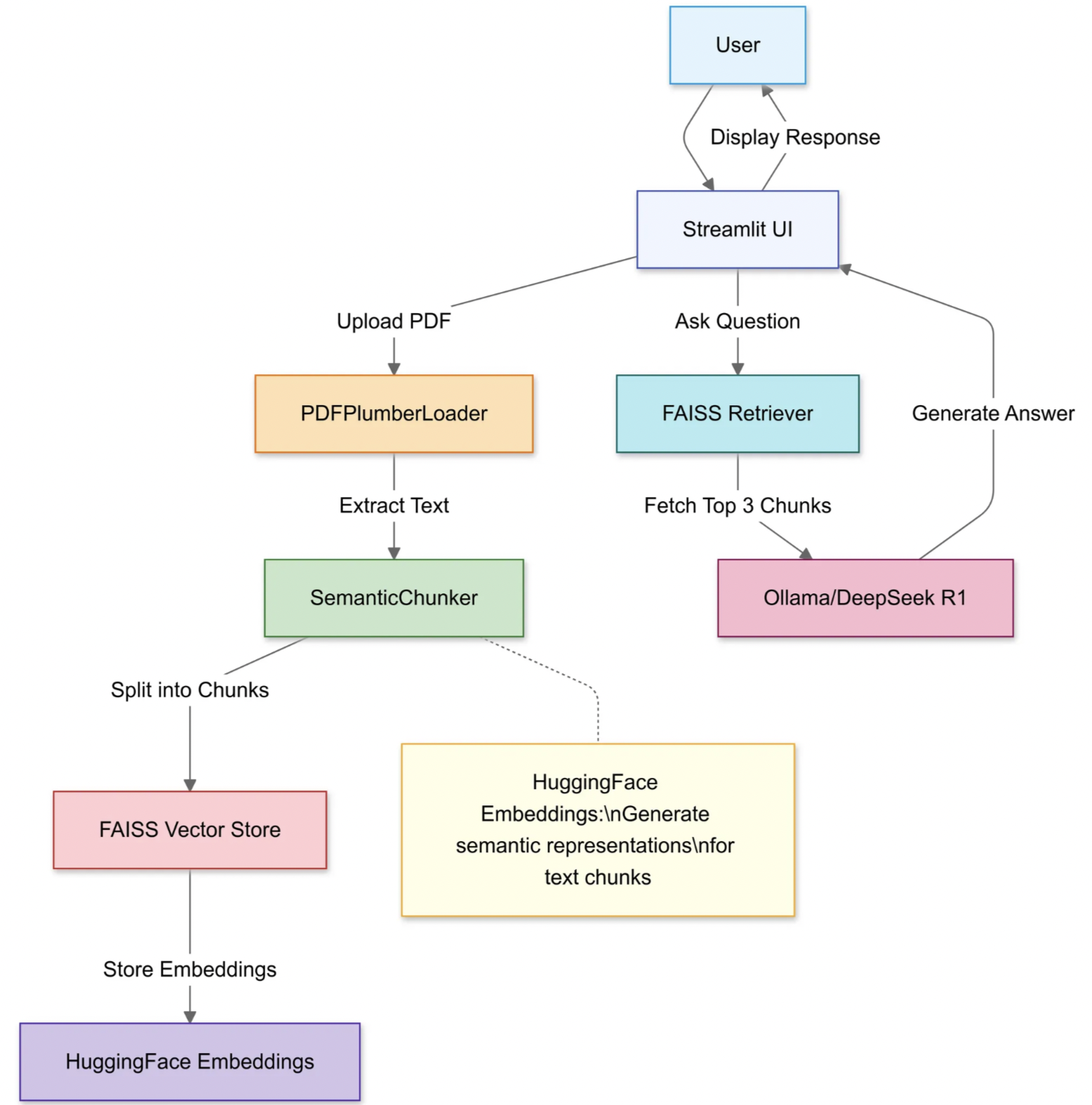
2.上传并处理 PDF
利用 Streamlit 的文件上传器选择本地 PDF。用于PDFPlumberLoader高效提取文本,无需手动解析。
# Streamlit文件上传器
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
# 临时保存PDF文件
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# 加载PDF文本
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()3.策略性地整理文件
我们打算使用递归字符文本分割器(RecursiveCharacterTextSplitter),该代码会将原始的 PDF 文本拆分成更小的片段(块)。下面我们来解释一下合理分块与不合理分块的概念:
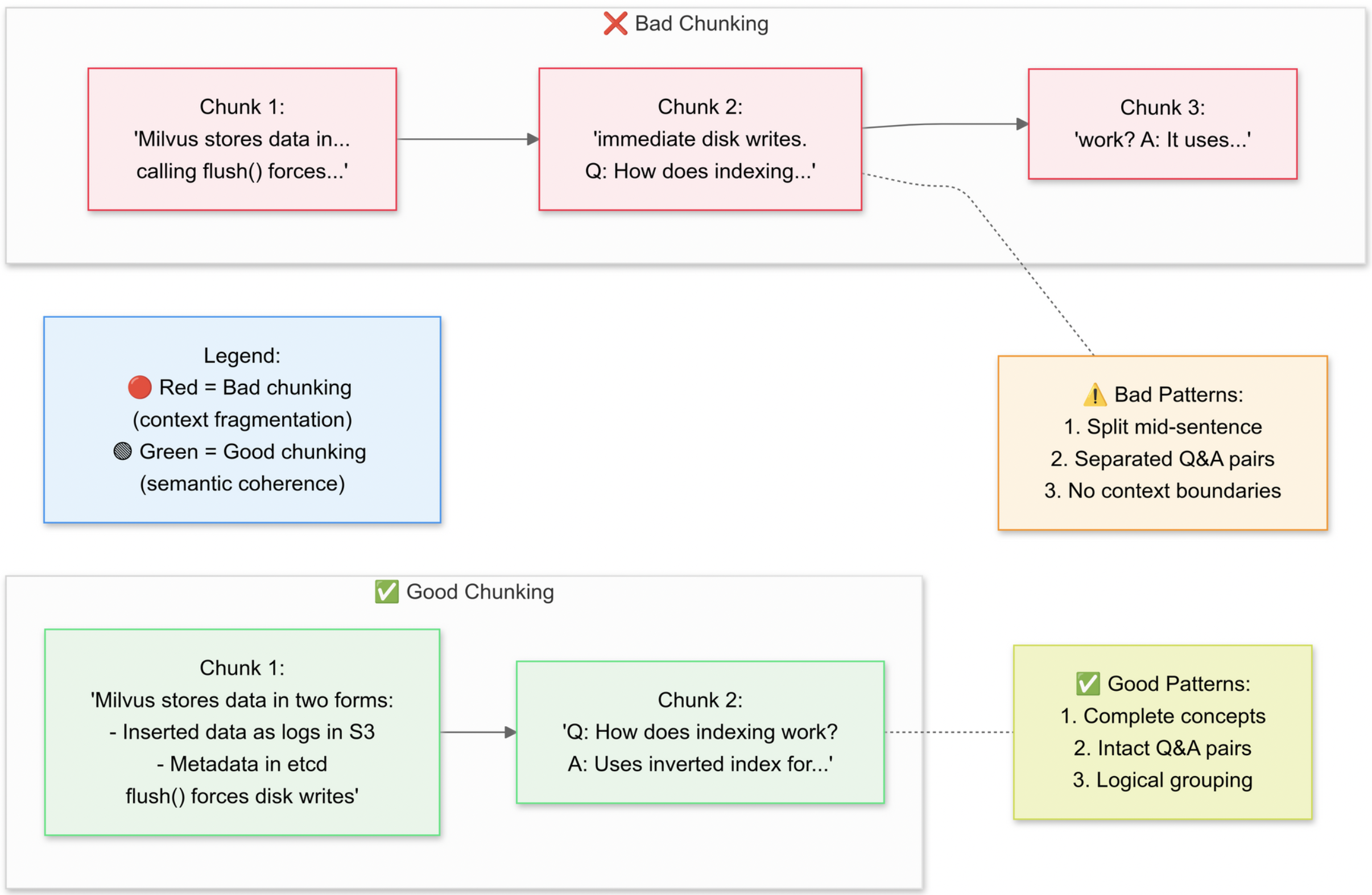
为什么要进行语义分块呢?
语义分块能够将相关的句子归为一组(例如,"Milvus 如何存储数据" 这样的内容会保持完整),还能避免拆分表格或图表。
利用 Streamlit 的文件上传器选择本地 PDF。用于PDFPlumberLoader高效提取文本,无需手动解析。
# 将文本拆分为语义块
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)这一步通过让各文本片段稍有重叠来保留上下文信息,这有助于语言模型更准确地回答问题。小而明确的文档片段还能让搜索变得更高效、更具相关性。
4.创建可搜索的知识库
分割完成后,流程会为这些文本片段生成向量嵌入表示,并将它们存储在 FAISS 索引中。
# Generate embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Connect retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Fetch top 3 chunks 这一过程将文本转换为一种数值表示形式,从而使查询变得更加容易。后续的查询操作将针对该索引展开,以找出上下文最为相关的文本片段。
5.配置 DeepSeek R1
在这里,你要使用 Deepseek R1 1.5B 参数模型作为本地大语言模型(LLM)来实例化一个检索问答(RetrievalQA)链。
llm = Ollama(model="deepseek-r1:1.5b") # Our 1.5B parameter model
# Craft the prompt template
prompt = """
1. Use ONLY the context below.
2. If unsure, say "I don't know".
3. Keep answers under 4 sentences.
Context: {context}
Question: {question}
Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt) 这个模板会迫使模型依据你 PDF 文档的内容来给出答案。通过将语言模型与和 FAISS 索引绑定的检索器相结合,任何通过该链发起的查询都会从 PDF 内容中查找相关上下文,从而让答案有原始材料作为依据。
6.组装RAG链
接下来,你可以将上传、分块和检索这几个步骤整合为一个连贯的流程。
# Chain 1: Generate answers
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Chain 2: Combine document chunks
document_prompt = PromptTemplate(
template="Context:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Final RAG pipeline
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)这就是检索增强生成(RAG)设计的核心所在,它为大语言模型提供经过验证的上下文信息,而非让其单纯依赖自身的内部训练数据。
7.启动 Web 接口
最后,代码利用了 Streamlit 的文本输入和输出函数,这样用户就可以直接输入问题并立即查看回答。
# Streamlit UI
user_input = st.text_input("Ask your PDF a question:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response) 一旦用户输入查询内容,检索链就会找出最匹配的文本片段,将其输入到语言模型中,并显示答案。只要正确安装了langchain库,代码现在应该就能正常运行,不会再触发模块缺失的错误。
提出并提交问题,即可立即获得答案!
8.完整示例代码
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
# color palette
primary_color = "#1E90FF"
secondary_color = "#FF6347"
background_color = "#F5F5F5"
text_color = "#4561e9"
# Custom CSS
st.markdown(f"""
<style>
.stApp {{
background-color: {background_color};
color: {text_color};
}}
.stButton>button {{
background-color: {primary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
.stTextInput>div>div>input {{
border: 2px solid {primary_color};
border-radius: 5px;
padding: 10px;
font-size: 16px;
}}
.stFileUploader>div>div>div>button {{
background-color: {secondary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
</style>
""", unsafe_allow_html=True)
# Streamlit app title
st.title("Build a RAG System with DeepSeek R1 & Ollama")
# Load the PDF
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file is not None:
# Save the uploaded file to a temporary location
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load the PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
# Split into chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
# Instantiate the embedding model
embedder = HuggingFaceEmbeddings()
# Create the vector store and fill it with embeddings
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Define llm
llm = Ollama(model="deepseek-r1")
# Define the prompt
prompt = """
1. Use the following pieces of context to answer the question at the end.
2. If you don't know the answer, just say that "I don't know" but don't make up an answer on your own.\n
3. Keep the answer crisp and limited to 3,4 sentences.
Context: {context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(
llm=llm,
prompt=QA_CHAIN_PROMPT,
callbacks=None,
verbose=True)
document_prompt = PromptTemplate(
input_variables=["page_content", "source"],
template="Context:\ncontent:{page_content}\nsource:{source}",
)
combine_documents_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context",
document_prompt=document_prompt,
callbacks=None)
qa = RetrievalQA(
combine_documents_chain=combine_documents_chain,
verbose=True,
retriever=retriever,
return_source_documents=True)
# User input
user_input = st.text_input("Ask a question related to the PDF :")
# Process user input
if user_input:
with st.spinner("Processing..."):
response = qa(user_input)["result"]
st.write("Response:")
st.write(response)
else:
st.write("Please upload a PDF file to proceed.")3.总结
本文详细介绍了利用 DeepSeek R1 和 Ollama 构建检索增强生成(RAG)系统的方法。首先说明了 DeepSeek R1 1.5B 模型的优势,如精准检索、避免幻觉、零延迟等。接着阐述了搭建流程,包括用 Ollama 本地运行模型、上传 PDF 文件、使用递归字符文本分割器进行语义分块、生成向量嵌入并存储于 FAISS 索引、实例化检索问答链,最后整合各步骤形成连贯流程。通过 Streamlit 实现用户输入问题并即时获取答案,且确保安装langchain库可避免错误。
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出新书了《深入理解Hive》、同时已出版的《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》也可以和新书配套使用,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。