简介
COUNT()函数定义
COUNT()函数是SQL中常用的 聚合函数 ,用于统计满足特定条件的记录数。它可以灵活地应用于各种查询场景,帮助用户快速获取所需的数据统计信息。该函数不仅能够计算所有行的数量,还能针对特定列进行计数,并支持去除重复值的计数操作。这种多功能性使得COUNT()成为数据分析和报表生成的重要工具,在日常数据库管理和决策支持中发挥着关键作用。
语法结构
COUNT()函数是SQL中常用的聚合函数,用于统计满足特定条件的行数。其基本语法格式如下:
SELECT COUNT(expression) FROM table_name [WHERE condition];其中,expression可以是以下几种形式之一:
-
COUNT(*) :统计所有行,包括NULL值
-
COUNT(column_name) :统计指定列的非NULL值
-
COUNT(DISTINCT column_name) :统计指定列的不同非NULL值
值得注意的是,COUNT()函数对NULL值的处理有所不同:
-
COUNT(*)始终包括NULL值
-
COUNT(column_name)和COUNT(DISTINCT column_name)会忽略NULL值
这种灵活性使COUNT()函数能够在各种查询场景中发挥作用,满足不同的统计需求。
基本用法
COUNT(*)
COUNT(*)函数是SQL中最常用的聚合函数之一,用于统计表中的行数。它的主要特点是 包括所有行,无论各列的值是否为NULL 。这一特性使其成为获取表中总记录数的理想选择。
在实际应用中,COUNT(*)函数广泛用于各种统计场景。例如,假设我们有一个名为"employees"的员工表,可以使用以下查询来获取员工总数:
SELECT COUNT(*) AS total_employees FROM employees;这个查询将返回表中的总行数,包括所有员工记录。
COUNT()的一个重要优势是其 执行效率 。特别是在InnoDB存储引擎中,MySQL对COUNT( )进行了专门的优化。从MySQL 8.0.13版本开始,对于没有附加查询条件的SELECT COUNT() FROM tbl_name查询,InnoDB引擎会遍历最小可用的辅助索引,从而提高查询性能。这意味着即使表中有大量数据,COUNT()也能提供较快的响应。
然而,需要注意的是,COUNT()的性能可能会受到 并发事务 的影响。由于InnoDB不保存表中的内部行数,每个事务可能看到不同数量的行。因此,SELECT COUNT()语句仅统计当前事务可见的行数。这种行为在高并发环境中尤为重要,可能导致不同事务获得略有不同的结果。
为了进一步提高COUNT(*)的性能,特别是对于大型表,可以考虑以下优化策略:
-
创建计数器表 :这种方法涉及创建一个单独的表来跟踪行数变化,并让应用程序根据插入和删除操作更新计数器。虽然这种方法可能无法很好地扩展到数千个并发事务同时更新同一计数器表的情况,但在适当的应用场景下可以显著提高性能。
-
使用SHOW TABLE STATUS :如果只需要近似的行数,可以使用SHOW TABLE STATUS命令。这个命令提供了表的大致行数,虽然精度可能在40%~50%左右,但在某些情况下足以满足需求。
通过合理使用COUNT(*)函数并结合适当的优化策略,可以在各种复杂的查询场景中高效地获取所需的统计信息,同时平衡查询性能和数据准确性之间的权衡。
COUNT(column_name)
COUNT(column_name)函数是SQL中一种强大的统计工具,特别适用于需要精确了解特定列非NULL值数量的场景。与COUNT(*)不同,它 专注于指定列的有效值 ,自动过滤掉NULL值,这在处理部分字段可能存在缺失数据的表时尤为有用。
在实际应用中,COUNT(column_name)常用于多种统计需求:
-
产品库存管理 :假如我们有一个名为"inventory"的产品库存表,其中包含"product_id"和"quantity"等字段。使用COUNT(quantity)可以帮助我们快速统计有多少种产品的库存数量大于零:
SELECT COUNT(quantity) AS non_zero_inventory_items
FROM inventory
WHERE quantity > 0;
这个查询不仅排除了NULL值,还进一步过滤了库存为零的商品,为我们提供了准确的库存统计。
-
用户活跃度分析 :在用户行为分析中,我们可以利用COUNT(login_date)来统计过去一个月内至少登录过一次的活跃用户数:
SELECT COUNT(login_date) AS active_users_last_month
FROM users
WHERE login_date >= DATE_SUB(CURDATE(), INTERVAL 1 MONTH);
这个例子展示了COUNT(column_name)与日期函数结合使用的强大功能,为我们提供了用户活跃度的关键指标。
-
订单完成率评估 :对于电子商务平台,COUNT(order_status)可以帮助我们计算已完成订单的比例:
SELECT COUNT(order_status) AS completed_orders,
COUNT(*) AS total_orders
FROM orders
WHERE order_status = 'Completed';
通过这两个COUNT函数的组合,我们可以轻松计算出已完成订单占总订单的比例,为业务运营提供有价值的洞察。
COUNT(column_name)的灵活性在于它可以根据具体需求进行定制化使用。例如,结合CASE语句,我们可以实现更复杂的统计逻辑:
SELECT COUNT(CASE WHEN payment_method = 'Credit Card' THEN 1 ELSE NULL END) AS credit_card_payments,
COUNT(CASE WHEN payment_method = 'PayPal' THEN 1 ELSE NULL END) AS paypal_payments
FROM transactions;这个查询展示了如何使用COUNT(column_name)来统计不同支付方式的交易次数,为财务分析提供了详细的细分数据。
通过这些例子,我们可以看到COUNT(column_name)在数据统计和分析中的广泛应用价值。它不仅能有效处理NULL值,还能与其他SQL构造巧妙结合,为用户提供高度定制化的统计结果,满足多样化的数据分析需求。
COUNT(DISTINCTcolumn_name)
COUNT(DISTINCT column_name)函数是SQL中一种强大的统计工具,用于计算指定列中 唯一非NULL值的数量 。这个函数在数据去重和汇总分析中扮演着关键角色,尤其适用于需要精确统计不同实体数量的场景。
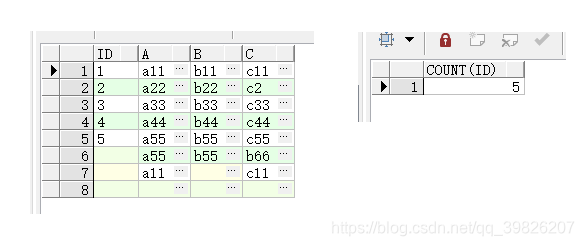
在执行COUNT(DISTINCT)时,数据库会遍历指定列的所有值,使用哈希表或其他数据结构来追踪唯一值。这种方法在小型数据集上表现出色,但面对大型数据集时可能会面临性能挑战。为了优化大规模数据的处理,可以采用以下策略:
-
使用索引 :在涉及的列上建立索引可以显著提升查询效率。
-
使用临时表或子查询 :通过预先过滤数据,可以有效减少计算量。
-
使用近似算法 :对于超大数据集,考虑使用如HyperLogLog算法进行近似统计。
在实际应用中,COUNT(DISTINCT)常与其他SQL构造结合使用,以满足复杂的数据分析需求。例如,结合GROUP BY子句可以实现多维度的统计:
SELECT country, COUNT(DISTINCT city) AS unique_cities
FROM locations
GROUP BY country;这个查询展示了如何统计每个国家的独特城市数量,体现了COUNT(DISTINCT)在地理数据分析中的应用价值。
通过合理运用COUNT(DISTINCT),数据分析师和开发者可以更精准地把握数据特征,为决策制定和业务优化提供有力支持。
高级应用
条件COUNT()
在MySQL中,条件COUNT()是一种高级应用,允许用户根据特定条件进行计数。这种技术通常涉及使用WHERE子句或IF()函数与COUNT()函数相结合,以实现更精细的数据统计。
使用WHERE子句进行条件计数
最常用的方法是通过WHERE子句来限定计数范围。例如,如果我们有一个名为"sales"的销售表,我们可以使用以下查询来统计销售额超过1000元的订单数量:
SELECT COUNT(*) FROM sales WHERE amount > 1000;这种方法简洁明了,适合处理单一条件的计数需求。
使用IF()函数进行复杂条件计数
对于更复杂的条件,IF()函数提供了一种灵活的方式来控制计数行为。IF()函数的基本语法如下:
SELECT COUNT(IF(condition, expression, NULL)) FROM table;这里的condition是我们设定的条件,expression是在条件成立时返回的值。如果条件不成立,函数返回NULL,这样就不会被计入COUNT()的结果中。
IF()函数的优势在于可以处理多个条件的组合。例如,如果我们想统计既属于电子产品类别又售价超过500元的产品数量,可以使用以下查询:
SELECT COUNT(IF(category = 'Electronics' AND price > 500, 1, NULL)) FROM products;这种方法允许我们在一个COUNT()函数中实现多条件的逻辑判断,提高了查询的灵活性和效率。
多层嵌套实现复杂统计
在处理复杂的数据统计需求时,可以将IF()函数与子查询结合起来,实现多层次的条件计数。例如,如果我们有一个包含用户信息的"users"表和一个记录用户活动的"activities"表,我们可以使用以下查询来统计过去一年内至少登录过三次的活跃用户数量:
SELECT COUNT(IF((SELECT COUNT(*) FROM activities WHERE user_id = u.id AND activity_date >= DATE_SUB(NOW(), INTERVAL 1 YEAR)) >= 3, 1, NULL))
FROM users u;这个查询首先在子查询中统计每个用户的登录次数,然后在外部查询中使用IF()函数判断是否满足条件,最后使用COUNT()函数计算满足条件的用户数量。这种方法虽然语法较为复杂,但能够处理非常复杂的统计需求。
性能考虑
在使用条件COUNT()时,性能是一个需要重点关注的问题。对于大型数据表,频繁使用IF()函数可能会导致性能下降。在这种情况下,可以考虑以下优化策略:
-
使用子查询 :将复杂的条件判断放入子查询中,可以简化外部查询的复杂度。
-
使用JOIN操作 :对于涉及多表关联的统计,使用JOIN操作往往比嵌套子查询更高效。
-
合理使用索引 :确保参与条件判断的列都有合适的索引,可以显著提高查询速度。
通过合理设计查询结构和优化索引,可以在保证查询精度的同时,最大限度地提高条件COUNT()的执行效率。
组合COUNT()
在SQL查询中,组合使用多个COUNT()函数是一种强大的技术,可以实现复杂的数据统计需求。这种方法特别适用于需要同时获取多个维度统计数据的场景,能够提供全面而详细的数据概览。
一个典型的应用场景是对用户行为进行多角度分析。假设我们有一个电子商务网站的用户表,包含用户ID、注册日期和最近登录日期等字段。我们可以使用以下查询来获取不同类型用户的数量:
SELECT
COUNT(*) AS total_users,
COUNT(DISTINCT CASE WHEN last_login IS NOT NULL THEN user_id END) AS active_users,
COUNT(DISTINCT CASE WHEN registration_date >= DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY) THEN user_id END) AS new_users
FROM users;这个查询同时计算了总用户数、活跃用户数(最近有过登录的用户)和新注册用户数(过去30天内注册的用户)。通过组合使用COUNT()、DISTINCT和CASE语句,我们可以一次性获取多个重要的用户指标,大大提高了查询效率。
在处理大型数据集时,组合使用多个COUNT()函数可能会对查询性能产生一定影响。为了优化这类查询,可以考虑以下策略:
-
使用子查询 :将复杂的COUNT()表达式拆分为多个子查询,可以降低单个查询的复杂度,有时能提高整体性能。
-
合理使用索引 :确保参与COUNT()计算的列上有适当的索引,尤其是使用DISTINCT时,索引可以显著加快去重过程。
-
使用近似算法 :对于一些不需要精确统计的场景,可以考虑使用HyperLogLog等近似算法来估算COUNT(DISTINCT)的结果,以换取更快的查询速度。
通过合理组合使用多个COUNT()函数,我们可以实现更灵活、更高效的数据统计分析,为业务决策提供强有力的支持。
性能考虑
索引对COUNT()的影响
在探讨COUNT()函数的性能时,索引的选择和使用起着至关重要的作用。MySQL查询优化器在处理COUNT(*)查询时,会根据不同的索引类型和表结构做出智能选择,以提高查询效率。
MySQL 5.7.18及以上版本引入了一项重要优化: 优先使用最小的可用二级索引 来处理COUNT(*)查询。这一改变源于对成本效益的考量------二级索引树通常比主键索引树小,因此扫描成本更低。
二级索引(又称辅助索引)在处理COUNT(*)查询时展现出显著优势。这是因为二级索引的叶子节点只存储主键值,而不包含完整的行数据。这种结构使得二级索引在进行行数统计时更加轻量级,减少了I/O开销。
然而,索引的选择并非总是那么简单。在某些特殊情况下,MySQL仍可能选择使用主键索引。这种情况通常发生在 缺乏合适二级索引 或 表结构特殊 的场景中。例如,当表中只有一个主键索引而无其他索引时,查询优化器别无选择,只能使用主键索引。
值得注意的是,COUNT()函数的表现还受 并发环境 的影响。由于InnoDB存储引擎不保存表中的内部行数,每个事务可能看到不同数量的行。这意味着COUNT(*)查询的结果可能因并发事务的存在而略有差异。这种行为在高并发系统中尤为重要,开发者需要充分考虑其潜在影响。
为了进一步优化COUNT()查询,可以考虑以下策略:
-
创建专门的计数器表 :这种方法涉及维护一个独立的表来跟踪行数变化,特别适合需要频繁更新和查询行数的场景。
-
使用SHOW TABLE STATUS :对于只需大致行数的情况,SHOW TABLE STATUS命令可以提供快速的近似值,虽然精度可能在40%~50%之间,但在某些应用场景中已足够使用。
通过合理选择和优化索引策略,结合适当的查询技巧,可以在保证查询精度的同时,最大化COUNT()函数的执行效率,从而提升整个系统的性能表现。
大表COUNT()优化
在处理大型数据表时,COUNT(*)查询可能会面临严重的性能瓶颈。为了应对这一挑战,我们可以采取多种优化策略,以提高查询效率并减少资源消耗。以下是几种有效的优化方法:
- 使用二级索引
在InnoDB存储引擎中,选择合适的索引类型对COUNT()查询至关重要。MySQL倾向于使用最小的可用二级索引来进行COUNT()操作,这主要是因为二级索引的叶子节点只存储主键值,相比主键索引具有更高的空间效率。例如:
CREATE INDEX idx_column ON table_name(column_name);这种方法特别适用于需要频繁执行COUNT(*)查询的场景,尤其是在数据量达到数百万或更多行时。
- 使用近似算法
对于那些对结果精确度要求不高的场景,可以考虑使用近似算法来估算COUNT(*)的结果。例如,MySQL 8.0引入了APPROX_COUNT_DISTINCT()函数,它使用HyperLogLog算法来估算不同值的数量:
SELECT APPROX_COUNT_DISTINCT(column_name) FROM table_name;这种方法能在保持较高精度的同时,大幅提高查询速度,特别适合处理海量数据。
- 使用分区表
对于非常大的表,可以考虑将其划分为多个较小的分区表。这样,COUNT(*)查询就可以并行地在每个分区上执行,最后合并结果:
CREATE TABLE big_table (
...
) PARTITION BY RANGE (TO_DAYS(date_column));通过这种方式,可以显著减少查询所需的时间,特别是在处理时间序列数据时效果更为明显。
- 使用物化视图
对于需要频繁执行的复杂COUNT(*)查询,可以考虑创建物化视图来存储预计算的结果:
CREATE VIEW view_name AS
SELECT COUNT(*) FROM table_name WHERE condition;虽然这需要额外的存储空间,但在查询频繁且数据更新较少的场景下,可以极大地提高查询性能。
- 使用并行查询
在MySQL 8.0及更高版本中,可以启用并行查询功能来加速COUNT(*)操作:
SET optimizer_switch='parallel_derived=on';这允许MySQL并行执行子查询,从而显著提高大型表上COUNT(*)查询的速度。
通过综合运用这些优化策略,我们可以有效地提高大型数据表上COUNT(*)查询的性能,确保系统在处理海量数据时仍然保持良好的响应速度。在实际应用中,应根据具体的数据特性和查询需求,选择最适合的优化方法组合,以达到最佳的效果。
注意事项
NULL值处理
在讨论COUNT()函数的使用时,NULL值的处理是一个关键点。COUNT()函数对NULL值的处理方式取决于其参数:
参数
结果
COUNT(*)
包含NULL值在内的所有行
COUNT(column_name)
排除NULL值,仅计算非NULL值
这种灵活性使得COUNT()函数能够适应不同的统计需求。例如,在统计用户登录情况时,COUNT(login_date)会自动忽略未登录(NULL值)的用户,提供准确的登录用户数。
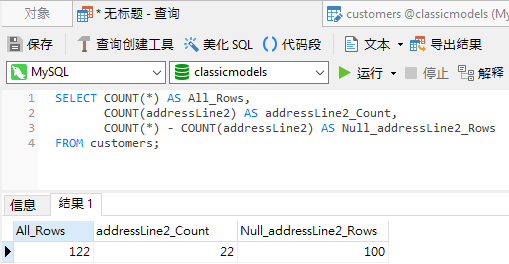
然而,在某些场景下,可能需要包含NULL值。这时,可以使用ISNULL()或NVL()函数将NULL转换为特定值后再进行计数。这种方法在处理缺失数据或需要统一计数标准时特别有用。
COUNT()与其他聚合函数的区别
在SQL聚合函数中,COUNT()、SUM()和AVG()各有独特用途:
-
SUM()用于数值列求和,AVG()计算平均值,而COUNT()则统计行数或非NULL值数量。
-
COUNT()对NULL值的处理方式灵活,可通过COUNT(*)包含所有行,或COUNT(column_name)排除NULL值。
-
SUM()和AVG()默认忽略NULL值,需使用COALESCE()或IFNULL()处理特殊情况。
-
COUNT()在性能方面表现优异,尤其在InnoDB存储引擎中,通过优化策略如使用最小可用二级索引,可大幅提升查询效率。
这种多样性使数据分析师可根据具体需求选择最适合的函数,以实现高效准确的数据统计和分析。