机器人技术的突破让OpenAI过时了
Ignacio de Gregorio

最近,Figure AI,一家价值数十亿美元的AI机器人公司,宣布取消与OpenAI的合作伙伴关系,这一举动看起来是相当大胆的。在此之前,机器人的大脑是一个经过精细调教的OpenAI模型(由OpenAI专门为他们的机器人构建的模型),但该公司的公告暗示,他们在内部取得了一个突破,允许他们训练自己的模型。
不再需要OpenAI了。
几周后,他们计划以惊人的395亿美元估值筹集资金,这一估值是去年最新估值的15倍,即便在AI狂潮中,这样的增幅也极为罕见(通常公司在融资轮次之间增长两到三倍,而不是十五倍)。
但为什么突然做出如此多的大胆举动呢?
原因就是Helix,他们的新型机器人视觉-语言-动作AI模型,而且这个模型对NVIDIA来说也有着极大的潜力。
但这个革命性的系统是如何运作的呢?
多方面的首次突破
Helix在多个方面都是首次突破,例如:
全身上肢控制:Helix是首个能够对整个类人上半身进行高速、连续控制的VLA(视觉-语言-动作)模型,包括手腕、躯干、头部和单独的手指。
多机器人协作:Helix是首个能够同时在两台机器人之间运作的VLA,使它们能够在涉及陌生物体的长期协作任务中进行协调。
多功能物体处理:由Helix驱动的机器人现在可以抓取和操作几乎任何小型家居物品------包括成千上万他们从未接触过的物品------仅凭自然语言指令进行指导。
统一神经网络:与以往的方法不同,Helix采用一组神经网络权重来学习广泛的行为,从拾取和放置物体到与家具互动,再到与其他机器人合作,所有这些都无需针对特定任务进行微调。
但该发布的最令人印象深刻的方面是这个模型的多机器人特性。在发布的视频中,两台机器人通过Helix进行互动,合作解决团队任务,这是前所未有的(视频缩略图)。
这真是令人震惊。那么Helix是如何工作的呢?
认知层次结构
Helix建立在这样的观点上:AI模型的结构需要被分成快速部分和慢速部分,以创建功能完整的AI机器人。
• 快速模型将处理感官和语义数据,并以更高频率执行动作,例如移动手部的驱动器。
• 慢速模型将处理相同的数据,但它们的目标更为高层,关键是执行速度会低得多。
这就创建了一个认知层次结构。较慢但更强大的模型处理更困难、更高层次的任务,比如推理接下来该做什么。
与此同时,较快但较不强大的模型执行低级动作,比如移动手或头部。可以这样理解:较慢的模型指引机器人该做什么(目标设定者),这是一个较慢的思考过程,需要较低的输出频率;而较快的模型则展示该如何做(执行者),这涉及数百个低级动作,因此需要更快的输出速度。
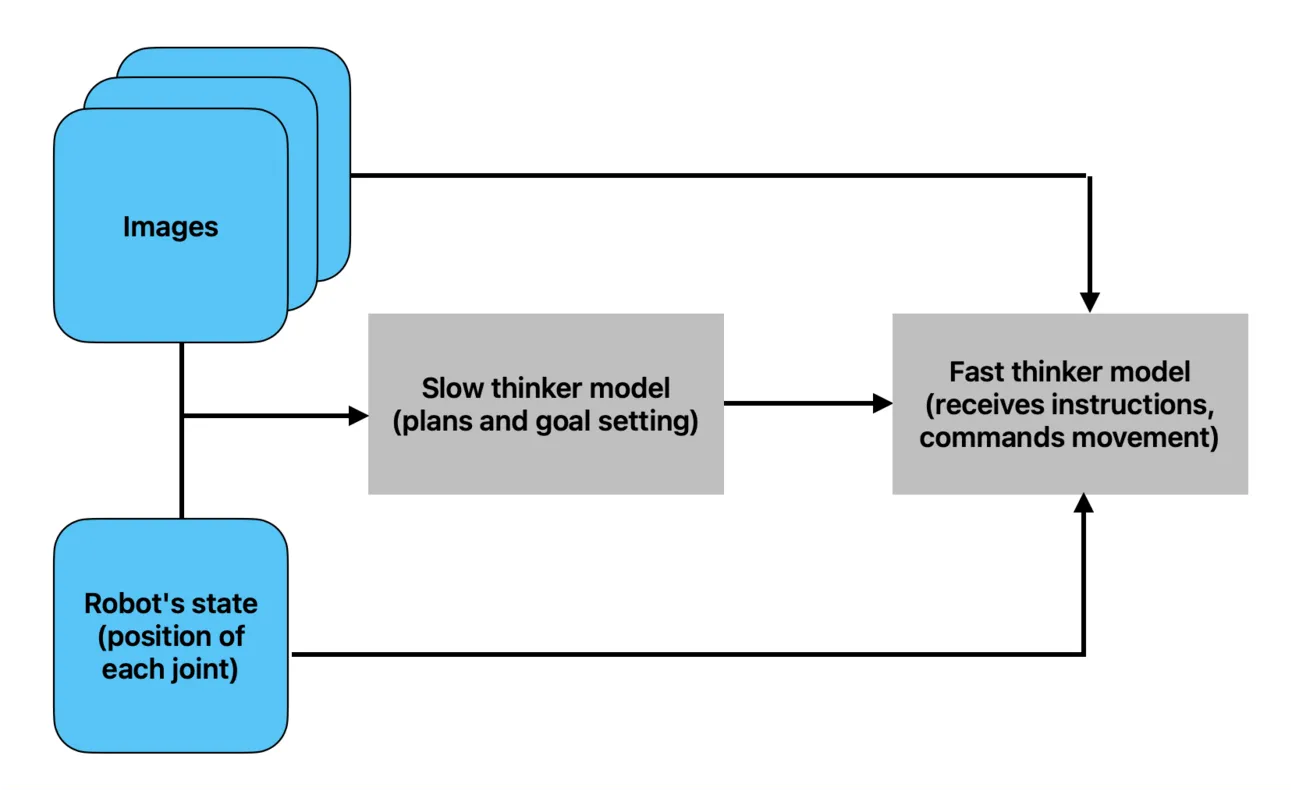
为什么要采用不同的速度呢?关键原则是,高层决策(例如"抓住杯子")不需要毫秒级的精度,但马达控制(例如调整手指的握持)则需要。使用一个模型来同时处理这两者,不仅会非常缓慢,而且性能不佳。
通过这种方式,虽然某些任务需要更长的时间来处理,但较慢但更深思熟虑的模型会处理这些任务,决定该做什么(规划目标)。相比之下,较小的模型则执行那些处理更快的、需要较少智能的功能,而且重要的是,需要更快执行(以特定方式移动手)。
那么它的内部工作是怎样的呢?
创建模型的新方式
如前所述,Helix完美展示了这种快/慢架构。
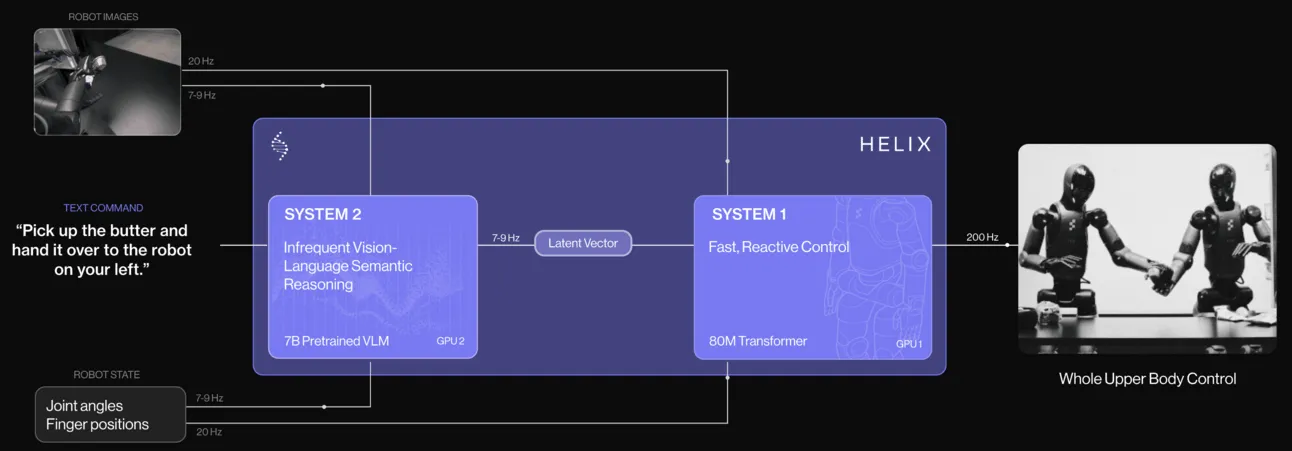
它包括两个模型:
系统2:一个VLA(视觉-语言-动作)模型,是一个变换器(像ChatGPT那样的模型),以每秒7到9次的频率处理图像和每个驱动器的状态(手腕、躯干、头部和单独的手指)。该模型负责处理需要较慢但更智能思考的复杂任务。
系统1:一个更快的混合注意力卷积模型,且更小(仅8000万参数,比VLA小一千倍),它同样摄取相同的数据输入,以及VLA模型输出的语义向量。前者数据输入以每秒20次的速度传入,潜在向量以每秒7至9次的速度传入,关键是该模型负责以每秒200次的速度输出机器人执行的实际动作(每台机器人每秒执行200个小动作)。换句话说,该模型接收与系统2相同的感官输入,再加上VLA模型的高级指令(它应该做什么),以大约200次/秒的速度产生马达动作。
那么,每个模型如何在后台工作呢?
如今使用的大多数模型都是序列到序列的模型,它们输入的数据是有序的(文本是一个词的序列,图像是像素/像素组的序列,等等)。
它们学会了将该序列映射为输出序列。在ChatGPT的情况下,输出是一个继续输入序列的词序列。
但你也可以映射不同的数据结构。图像生成模型将文本序列映射为图像(同样是像素的序列),图像代表了请求的文本。它们的任务是输出与输入语义相关的内容。对ChatGPT来说,输出词是输入文本的语义延续;对图像生成器来说,输出图像应该是输入文本的视觉语义表示。
当然,这适用于任何数据结构,包括音频或视频。只要它是可排序的(大多数数据结构都可以),就可以将其映射到代表原始输入的另一数据结构中。
在Helix的情况下,这个模型也是这么做的,但映射从图像+机器人的当前状态(如姿态)到动作需求,或者它应该做什么。通俗地讲,系统2模型的输出就是(这是我们当前的位置,这是接下来我们应该做的事)。
然后,这个结果会被传递给一个更小的模型,虽然它看到的和较大模型相同的数据(机器人看到的图像以及当前状态),但它输出的是机器人执行的动作(因此,系统1模型的映射是{视觉输入+机器人状态+目标,由系统2模型提供},并输出动作)。
简明总结如下:
• 系统2将视觉和驱动器数据映射到下一个高级动作,
• 系统1将视觉和驱动器数据以及系统2模型的高级指令映射到驱动器动作。
这样,系统2模型指引着机器人朝着实现目标的轨迹前进,而系统1模型则执行成千上万个小动作,最终将整个物理轨迹指向目标。
对于技术爱好者,你可能已经注意到,我提到小模型是一个混合卷积/注意力神经网络(感谢Nikolaus Correll的指正),而不是变换器。你可能会问,为什么?
我推测的原因有三个:
-
卷积比执行注意力机制来处理图像要快得多,
-
卷积能更好地检测局部依赖关系。为了执行下一个动作,最近的动作比执行1000步之前的动作要相关得多。因此,虽然系统2模型(确实是一个变换器)需要处理整个轨迹,以确保机器人朝着正确的方向前进,但较小的模型完全不在乎很久以前发生的事件。
-
一旦图像通过卷积处理,模型就会在图像、机器人状态和系统2模型输出的潜在向量之间执行交叉注意力,以将三者映射到一组新的动作。
如果你仔细想想,这一切都和人类的认知方式有些相似。
类似人类的思维
人类以极快的速度处理并执行多项动作。
与此同时,我们更多的认知任务由大脑的前额叶皮层以更慢的速度处理(事实上,Caltech的研究人员称这个速度大约是10bit/s),比其他无意识的大脑认知过程慢几个数量级,远低于某些个别神经元的反应时间,这些神经元可以处理高达500Hz(每秒500次)的信号,甚至是1000Hz。
换句话说,举个例子,虽然我们有意识地控制着抓取薯片的高层动作,但我们并不会意识到每个关节和肌肉的精确动作,这些都在背后默默完成。
此外,这种模型的分离使得机器能够与其他机器人互动,这是人类也擅长的一项能力。
例如,在视频缩略图中所见,一台机器人会在意识到另一台机器人完成了那部分任务时,纠正自己的动作。
之所以能够做到这一点,是因为快速思考者几乎能立即反应(它每秒更新200次动作),在发现需要修正后,这一信息也会被较大模型捕捉到,经过确认后,修改全局目标(尽管整体目标尚未达成,但其中的一步已经完成)。
将两个系统解耦,可以通过较慢但更强大的模型生成更高级、更复杂的目标;同时,我们也能使用较小但更快的模型执行所有必要的动作,以期望的速度进行。
2025年,机器人年?
AI机器人技术的加速发展令人眼花缭乱(Figure AI并不是唯一一家在推动这一边界的公司)。
然而,一大亮点是,机器人公司似乎不再依赖OpenAI这样模型层公司了。相反,随着构建AI模型骨架的知识逐渐普及,它们正在垂直整合到AI链条中,自己构建模型。
虽然像OpenAI这样的公司背后有巨大价值,但像Figure AI这样的公司,因为它们即将把类人机器人投入我们的家庭和工厂,可能会比那些仅限于数字领域的软件公司更具价值。
是的,模型层公司在知识工作者岗位中有巨大的颠覆潜力,但机器人在劳动力各个层面的转型性影响是巨大的。蓝领工人的数量是白领工人的好几倍。
根据我使用AI进行的深度研究分析,通过ILOSTAT、美国劳工统计局、英国国家统计局和Statista的数据推算中国数据(因此要谨慎对待这些数据),得出的总数为11.1亿白领工人和22亿蓝领工人。
综合考虑,哪些科技巨头将在这里赢得最多,哪些又会失去最多?
需要注意的是,Figure AI的机器人是在模拟中训练的,而不是在真实世界中。它们被送入世界的数字表现中进行训练。如果模拟符合现实,它们就会毫无缝隙地被转移到它们的物理体内,无需进一步训练。
而谁在构建这些模拟呢?
你猜对了:NVIDIA,除了提供硬件和模拟环境(如Isaac GYM/Lab),它还恰好是Figure AI的投资者。
机器人热潮的其他潜在受益者包括苹果和特斯拉,它们都具备相当的硬件知识、数据,特别是对于"被咬了一口"的苹果来说,现金流也足够支撑必要的投资。
然而,与谷歌一样,特斯拉和苹果的最大敌人,巧妙地说,其实就是它们自己。