Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Gold-YOLO:通过收集与分发机制实现的高效目标检测器

0.论文摘要
在过去的几年中,YOLO系列模型已成为实时目标检测领域的领先方法。许多研究通过修改架构、增强数据和设计新的损失函数,将基线提升到了更高的水平。然而,我们发现尽管特征金字塔网络(FPN)和路径聚合网络(PANet)已经缓解了这一问题,但之前的模型仍然存在信息融合问题。因此,本研究提出了一种先进的"收集与分发"机制(GD机制),该机制通过卷积和自注意力操作实现。这种新设计的模型名为Gold-YOLO,它增强了多尺度特征融合能力,并在所有模型规模上实现了延迟与准确性的理想平衡。此外,我们首次在YOLO系列中实现了MAE风格的预训练,使YOLO系列模型能够从无监督预训练中受益。Gold-YOLO-N在COCO val2017数据集上取得了39.9%的AP,在T4 GPU上达到了1030 FPS,比之前具有相似FPS的SOTA模型YOLOv6-3.0-N高出+2.4%。
1.引言
目标检测作为一项基本的视觉任务,旨在识别物体的类别并定位其位置。它可以广泛应用于智能安防、自动驾驶、机器人导航和医疗诊断等多个领域。高性能、低延迟的目标检测器在边缘设备上的部署正受到越来越多的关注。
在过去的几年中,研究人员对基于CNN的检测网络进行了广泛研究,逐步将目标检测框架从两阶段(如Faster RCNN 42和Mask RCNN 25)发展到单阶段(如YOLO 39),并从基于锚点的方法(如YOLOv3 41和YOLOv4 2)发展到无锚点的方法(如CenterNet 10、FCOS 46和YOLOX 11)。12, 7, 17通过NAS研究了目标检测任务中的最优网络结构,而16, 23, 19则探索了通过蒸馏提升模型性能的另一种途径。单阶段检测模型,尤其是YOLO系列模型,因其结构简单且在速度和精度之间取得平衡,在工业界广受欢迎。
骨干网络的改进也是视觉领域的重要研究方向。正如综述20所述,26, 27, 59, 21在精度和速度之间取得了平衡,而9, 35, 22, 18在精度方面表现出色。这些骨干网络在不同视觉任务中提升了原始模型的性能,涵盖了从目标检测等高级任务到图像恢复等低级任务。通过使用基于Transformer的编码器-解码器结构,研究人员构建了一系列类似DETR的目标检测模型,如DETR3和DINO56。这些模型能够捕捉物体之间的长程依赖关系,使得基于Transformer的检测器在性能上能够与大多数经典检测器相媲美甚至超越。尽管基于Transformer的检测器表现出色,但在速度上仍不及基于CNN的模型。基于CNN的小规模目标检测模型在速度-精度权衡中仍占据主导地位,如YOLOX11和YOLOv6-v832, 48, 14。我们关注的是实时目标检测模型,特别是面向移动端部署的YOLO系列。主流的实时目标检测器由三部分组成:骨干网络、颈部网络和头部网络。骨干网络架构已被广泛研究41, 43, 9, 35,头部网络通常较为简单,由若干卷积层或全连接层组成。YOLO系列中的颈部网络通常使用特征金字塔网络(FPN)及其变体来融合多级特征。这些颈部模块基本遵循图3所示的架构。然而,当前的信息融合方法存在一个显著缺陷:当需要跨层(例如第1层和第3层)整合信息时,传统的FPN结构无法无损地传递信息,这阻碍了YOLO系列模型实现更好的信息融合。
为了进一步提高模型的准确性,我们还引入了一种预训练方法,即在ImageNet 1K数据集上使用MAE方法对骨干网络进行预训练,这显著提升了模型的收敛速度和精度。例如,我们经过预训练的Gold-YOLO-S模型达到了46.4%的AP,优于之前SOTA的YOLOv6-3.0-S模型的45.0% AP,且速度相近。
2.相关工作
2.1 实时目标检测器
经过多年的发展,YOLO系列模型在实时目标检测领域变得非常流行。YOLOv1-v3 39, 40, 41 构建了最初的YOLO模型,确定了由backbone-neck-head三部分组成的单阶段检测结构,通过多尺度分支预测不同大小的目标,成为代表性的单阶段目标检测模型。YOLOv4 2 优化了之前使用的darknet backbone结构,并提出了一系列改进,如Mish激活函数、PANet和数据增强方法。YOLOv5 13 继承了YOLOv4 2 的方案,并改进了数据增强策略,提供了更多模型变体。YOLOX 11 将Multi positives、Anchor-free和Decoupled Head引入模型结构,为YOLO模型设计设定了新的范式。YOLOv6 32, 31 首次将重参数化方法引入YOLO系列模型,提出了EfficientRep Backbone和Rep-PAN Neck。YOLOv7 48 着重分析了梯度路径对模型性能的影响,并提出了E-ELAN结构,在不破坏原始梯度路径的情况下增强模型能力。YOLOv8 14 综合了之前YOLO模型的优势,整合了这些技术,达到了当前YOLO家族的SOTA水平。
2.2 基于Transformer的目标检测
视觉Transformer(ViT)作为一种有竞争力的替代方案,挑战了广泛应用于各种图像识别任务的卷积神经网络(CNN)。DETR 3 将Transformer结构应用于目标检测任务,重构了检测流程,消除了许多手工设计的部分和NMS组件,从而简化了模型设计和整体流程。Deformable DETR 61 结合了可变形卷积的稀疏采样能力和Transformer的全局关系建模能力,在提高模型速度和精度的同时,加快了收敛速度。DINO 56 首次引入了对比去噪、混合查询选择和前瞻两次方案。最近的RT-DETR 36 改进了编码器-解码器结构,解决了类似DETR模型速度慢的问题,在精度和速度上均超越了YOLO-L/X。然而,类似DETR结构的局限性使其在小模型领域无法展现出足够的优势,而YOLO系列在精度和速度的平衡上仍保持SOTA地位。
2.3 用于目标检测的多尺度特征
传统上,不同层次的特征携带了关于各种尺寸物体的位置信息。较大的特征包含低维的纹理细节和较小物体的位置,而较小的特征则包含高维信息和较大物体的位置。由34提出的特征金字塔网络(FPN)的原始理念是,这些多样化的信息可以通过相互辅助来增强网络性能。FPN通过跨尺度连接和信息交换,提供了一种高效的多尺度特征融合架构设计,从而提升了不同尺寸物体的检测精度。
基于FPN,路径聚合网络(PANet)49引入了自底向上的路径,使不同层级之间的信息融合更加充分。类似地,EfficientDet 44提出了一种新的可重复模块(BiFPN),以提高不同层级之间信息融合的效率。M2Det 60引入了一种高效的MLFPN架构,包含U形结构和特征融合模块。Ping-Yang Chen 5通过双向融合模块改进了深层和浅层之间的交互。与这些层间工作不同,37使用集中特征金字塔(CFP)方法探索了单个特征信息。此外,53通过渐进特征金字塔网络(AFPN)扩展了FPN,以实现非相邻层之间的交互。针对FPN在检测大物体时的局限性,30提出了一种改进的FPN结构。YOLO-F 6通过单层特征实现了最先进的性能。SFNet 33通过语义流对齐不同层级的特征,提升了FPN在模型中的性能。SAFNet 29引入了自适应特征融合和自增强模块。4提出了一种用于目标检测的并行FPN结构,具有双向融合功能。然而,由于网络中路径过多且交互方式间接,之前的基于FPN的融合结构在速度、跨层级信息交换和信息丢失方面仍存在缺陷。
然而,由于网络中路径数量过多且交互方式间接,之前基于FPN的融合结构在速度、跨层级信息交换和信息丢失方面仍存在缺陷。
3.方法
3.1 预备
YOLO系列的颈部结构,如图3所示,采用了传统的FPN(特征金字塔网络)结构,该结构包含多个分支用于多尺度特征融合。然而,它仅完全融合了相邻层次的特征,对于其他层次的信息,只能通过"递归"方式间接获取。图3展示了传统FPN的信息融合结构:其中现有的第1、2、3层从上到下排列。FPN用于不同层次之间的融合。当第1层从其他两个层次获取信息时,存在两种不同的情况:

图3:(a) 是传统颈部信息融合结构的示例图。(b) 和 © 是AblationCAM 38 的可视化结果。
-
如果层级1希望利用层级2的信息,它可以直接访问并融合这些信息。
-
如果层级1想要使用层级3的信息,层级1应递归调用相邻层的信息融合模块。具体来说,必须先融合层级2和层级3的信息,然后层级1才能通过结合层级2的信息间接获取层级3的信息。
这种传输模式在计算过程中可能导致信息的显著丢失。各层之间的信息交互只能交换由中间层选择的信息,而未选择的信息在传输过程中会被丢弃。这导致某一层级的信息只能充分辅助相邻层级,而削弱了对其他全局层级的辅助作用。因此,信息融合的整体效果可能会受到限制。
为了避免传统FPN结构在信息传递过程中的损失,我们摒弃了原有的递归方法,构建了一种新颖的收集与分发机制(GD)。通过使用统一的模块来收集和融合来自所有层级的信息,随后将其分发到不同层级,我们不仅避免了传统FPN结构中固有的信息损失,还在不显著增加延迟的情况下增强了颈部的部分信息融合能力。因此,我们的方法能够更有效地利用骨干网络提取的特征,并且可以轻松集成到任何现有的骨干-颈部-头部结构中。
在我们的实现中,收集和分发过程对应三个模块:特征对齐模块(FAM)、信息融合模块(IFM)和信息注入模块(Inject)。
• 收集过程包含两个步骤。首先,FAM从各个层级收集并对齐特征。其次,IFM融合对齐后的特征以生成全局信息。
• 在从收集过程中获得融合的全局信息后,Inject模块将这些信息分发到每个层级,并通过简单的注意力操作进行注入,从而提升分支的检测能力。
为了增强模型检测不同尺寸物体的能力,我们开发了两个分支:低阶段收集与分发分支(Low-GD)和高阶段收集与分发分支(High-GD)。这些分支分别提取并融合大尺寸和小尺寸的特征图。更多细节将在第4.1节和第4.2节中提供。如图2所示,颈部的输入包括由骨干网络提取的特征图B2、B3、B4、B5,其中 B i ∈ R N × C B i × R B i B_i ∈ \mathbb{R}^{N×C_{Bi}×R_{Bi}} Bi∈RN×CBi×RBi。批量大小用 N N N表示,通道数用C表示,维度用 R = H × W R = H × W R=H×W表示。此外, R B 2 R_{B2} RB2、 R B 3 R_{B3} RB3、 R B 4 R_{B4} RB4和 R B 5 R_{B5} RB5的维度分别为 R R R、 1 / 2 R 1/2 R 1/2R、 1 / 4 R 1/4 R 1/4R和 1 / 8 R 1/8 R 1/8R。

3.2 低阶段集散分支
在该分支中,选择骨干网络输出的B2、B3、B4、B5特征进行融合,以获得保留小目标信息的高分辨率特征。其结构如图4(a)所示。

图4:聚集与分发结构。在(a)中,Low-FAM和Low-IFM分别是低阶段分支中的低阶段特征对齐模块和低阶段信息融合模块。在(b)中,High-FAM和High-IFM分别是高阶段特征对齐模块和高阶段信息融合模块。
低阶段特征对齐模块
在低阶段特征对齐模块(Low-FAM)中,我们采用平均池化(AvgPool)操作对输入特征进行下采样,以实现统一尺寸。通过将特征调整为组内最小特征尺寸( R B 4 = 1 / 4 R R_{B4} = 1/4 R RB4=1/4R),我们得到 F a l i g n F_{align} Falign。Low-FAM技术确保了信息的高效聚合,同时最小化了通过Transformer模块进行后续处理的计算复杂度。
目标对齐尺寸的选择基于两个相互矛盾的考虑:(1) 为了保留更多的低层次信息,较大的特征尺寸更为可取;然而,(2) 随着特征尺寸的增加,后续模块的计算延迟也会增加。为了控制颈部部分的延迟,有必要保持较小的特征尺寸。
因此,我们选择 R B 4 R_{B4} RB4作为特征对齐的目标尺寸,以在速度和准确性之间实现平衡。
低阶段信息融合模块
低阶段信息融合模块(Low-IFM)设计包含多层重参数化卷积块(RepBlock)和分割操作。具体来说,RepBlock以 F a l i g n F_{align} Falign(通道数= C B 2 、 C B 3 、 C B 4 、 C B 5 C_{B2}、C_{B3}、C_{B4}、C_{B5} CB2、CB3、CB4、CB5之和)作为输入,生成 F f u s e F_{fuse} Ffuse(通道数= C B 4 + C B 5 C_{B4} + C_{B5} CB4+CB5)。中间通道数是一个可调值(例如256),以适应不同模型大小。RepBlock生成的特征随后在通道维度上被分割为 F i n j _ P 3 F_{inj\P3} Finj_P3和 F i n j _ P 4 F{inj\_P4} Finj_P4,然后与不同层次的特征进行融合。
公式如下:

信息注入模块
为了更高效地将全局信息注入到不同层级中,我们借鉴了分割经验47,并采用注意力操作来融合信息,如图5所示。具体而言,我们同时输入局部信息(即当前层级的特征)和全局注入信息(由IFM生成),分别记为 F l o c a l F_{local} Flocal和 F i n j F_{inj} Finj。我们使用两个不同的卷积层对 F i n j F_{inj} Finj进行计算,得到 F g l o b a l _ e m b e d F_{global\embed} Fglobal_embed和 F a c t F{act} Fact。而 F g l o b a l _ e m b e d F_{global\embed} Fglobal_embed则通过卷积层对 F l o c a l F{local} Flocal进行计算。随后,通过注意力机制计算融合特征 F o u t F_{out} Fout。由于 F l o c a l F_{local} Flocal和 F g l o b a l F_{global} Fglobal的尺寸不同,我们采用平均池化或双线性插值对 F g l o b a l _ e m b e d F_{global\embed} Fglobal_embed和 F a c t F{act} Fact进行缩放,使其与 F i n j F_{inj} Finj的尺寸对齐,确保正确匹配。在每次注意力融合的最后,我们添加RepBlock以进一步提取和融合信息。

图5:信息注入模块与轻量级邻层融合(LAF)模块
在低阶段, F l o c a l F_{local} Flocal 等于 B i B_i Bi,因此公式如下:

3.3 高级集散分支
High-GD融合了由Low-GD生成的特征 { P 3 , P 4 , P 5 } \{P3, P4, P5\} {P3,P4,P5},如图4(b)所示。

图4:聚集与分发结构。在(a)中,Low-FAM和Low-IFM分别是低阶段分支中的低阶段特征对齐模块和低阶段信息融合模块。在(b)中,High-FAM和High-IFM分别是高阶段特征对齐模块和高阶段信息融合模块。
高阶特征对齐模块
高阶特征对齐模块(High-FAM)包含avgpool,用于将输入特征的维度缩减至统一大小。具体而言,当输入特征的大小为 { R P 3 , R P 4 , R P 5 } \{R_{P3}, R_{P4}, R_{P5}\} {RP3,RP4,RP5}时,avgpool将特征大小缩减至该组特征中的最小尺寸( R P 5 = 1 / 8 R R_{P5} = 1/8 R RP5=1/8R)。由于Transformer模块提取的是高层次信息,池化操作在减少Transformer模块后续步骤计算需求的同时,促进了信息的聚合。
高级信息融合模块
高阶信息融合模块(High-IFM)包含Transformer块(下文将详细解释)和分割操作,该操作分为三个步骤:(1)从High-FAM中提取的 F a l i g n F_{align} Falign通过Transformer块进行融合,得到 F f u s e F_{fuse} Ffuse。(2)通过Conv1×1操作将 F f u s e F_{fuse} Ffuse的通道数减少为 s u m ( C P 4 , C P 5 ) sum(C_{P4}, C_{P5}) sum(CP4,CP5)。(3) F f u s e F_{fuse} Ffuse通过分割操作沿通道维度划分为 F i n j _ N 4 F_{inj\N4} Finj_N4和 F i n j _ N 5 F{inj\_N5} Finj_N5,随后用于与当前层级特征进行融合。
公式如下:

公式8中的Transformer融合模块由多个堆叠的Transformer组成,Transformer块的数量用L表示。每个Transformer块包括一个多头注意力块、一个前馈网络(FFN)以及残差连接。为了配置多头注意力块,我们采用与LeViT 15相同的设置,将键K和查询Q的头维度分配为D(例如16)通道,V = 2D(例如32)通道。为了加速推理,我们将对速度不友好的操作符------层归一化(Layer Normalization)替换为每个卷积的批归一化(Batch Normalization),并将所有GELU激活函数替换为ReLU。这最大限度地减少了Transformer模块对模型速度的影响。为了构建我们的前馈网络,我们遵循28, 55中提出的方法来构建FFN块。为了增强Transformer块的局部连接,我们在两个1x1卷积层之间引入了一个深度卷积层。我们还将FFN的扩展因子设置为2,旨在平衡速度和计算成本。
信息注入模块
High-GD中的信息注入模块与Low-GD中的完全相同。在高级阶段,Flocal等于 P i P_i Pi,因此公式如下:

3.4 增强的跨层信息流
我们仅使用全局信息融合结构就实现了优于现有方法的性能。为了进一步提升性能,我们从YOLOv6 31中的PAFPN模块获得灵感,引入了Inject-LAF模块。该模块是对注入模块的增强,包含一个轻量级的相邻层融合(LAF)模块,该模块被添加到注入模块的输入位置。
为了在速度和准确性之间取得平衡,我们设计了两类LAF模型:LAF低层模型和LAF高层模型,分别用于低层注入(合并相邻两层的特征)和高层注入(合并相邻一层的特征)。其结构如图5(b)所示。

图5:信息注入模块与轻量级邻层融合(LAF)模块
为确保不同层次的特征图与目标尺寸对齐,我们实现中的两个LAF模型仅使用了三种操作符:双线性插值用于上采样过小的特征,平均池化用于下采样过大的特征,以及1x1卷积用于调整与目标通道数不同的特征。
在我们的模型中,LAF模块与信息注入模块的结合有效地平衡了精度与速度。通过使用简化的操作,我们能够增加不同层级之间的信息流路径,从而在不显著增加延迟的情况下提升性能。
3.5 掩码图像建模预训练
近期的方法,如BEiT 1、MAE 24 和 SimMIM 51,已经展示了掩码图像建模(MIM)在视觉任务中的有效性。然而,这些方法并未专门针对卷积网络(convnets)进行优化。SparK 45 和 ConvNeXt-V2 50 是探索掩码图像建模在卷积网络中潜力的先驱。
在本研究中,我们采用SparK 45方法中的MIM预训练,该方法成功识别并克服了将MAE风格预训练扩展到卷积网络(convnets)中的两个关键障碍。这些挑战包括卷积操作无法处理不规则和随机掩码的输入图像,以及BERT预训练的单尺度特性与卷积网络层次结构之间的不一致性。
为了解决第一个问题,未掩码的像素被视为3D点云的稀疏体素,并采用稀疏卷积进行编码。针对后一个问题,开发了一种分层解码器,用于从多尺度编码特征中重建图像。该框架采用UNet风格的架构来解码多尺度稀疏特征图,其中所有空间位置都填充了嵌入的掩码。我们在ImageNet 1K上对多个Gold-YOLO模型的主干网络进行了预训练,并取得了显著的改进。
4.实验
4.1 实验设置
数据集。我们在微软COCO数据集上进行了大量实验,以验证所提出的检测器。在消融研究中,我们在COCO train2017数据集上进行训练,并在COCO val2017数据集上进行验证。我们使用标准的COCO AP指标,以单尺度图像作为输入,并报告在不同IoU阈值和物体尺度下的标准平均精度(AP)结果。
实现细节。我们遵循了YOLOv6-3.0 31的设置,使用了相同的结构(除了颈部)和训练配置。网络的主干部分采用了EfficientRep Backbone,而头部则使用了Efficient Decoupled Head。优化器的学习计划和其他设置也与YOLOv6相同,即使用带动量的随机梯度下降(SGD)和学习率的余弦衰减。采用了预热、分组权重衰减策略和指数移动平均(EMA)。在训练中还使用了自蒸馏和锚点辅助训练(AAT)。我们采用了Mosaic 2, 13和Mixup 57等强数据增强方法。
我们在骨干网络上使用128万张ImageNet-1K数据集8进行了MIM无监督预训练。根据Spark45的实验设置,我们采用了LAMB优化器54和余弦退火学习率策略,掩码比例为60%,掩码块大小为32。对于Gold-YOLO-L模型,我们使用了1024的批量大小,而对于Gold-YOLO-M模型,则使用了1152的批量大小。由于Gold-YOLO-N的小型骨干网络容量有限,未对其进行MIM预训练。
我们所有的模型均在8块NVIDIA A100 GPU上进行训练,速度性能则在配备TensorRT的NVIDIA Tesla T4 GPU上进行测量。
4.2 比较
我们的重点主要在于评估模型部署后的速度性能。具体来说,我们测量吞吐量(在批大小为1或32时的每秒帧数)和GPU延迟,而不是FLOPs或参数数量。为了将我们的Gold-YOLO与YOLO系列中的其他最先进检测器进行比较,例如YOLOv5 13、YOLOX 11、PPYOLOE 52、YOLOv7 48、YOLOv8 14和YOLOv6-3.0 31,我们在相同的Tesla T4 GPU上使用TensorRT测试了所有官方模型的FP16精度下的速度性能。
Gold-YOLO-N 展现了显著的进步,与 YOLOv8-N、YOLOv6-3.0-N 和 YOLOv7-Tiny(输入尺寸=416)相比,分别提升了 2.6%/2.4%/6.6%,同时在吞吐量和延迟方面提供了相当或更优的性能。与 YOLOX-S 和 PPYOLOE-S 相比,Gold-YOLO-S 的 AP 值显著提高了 5.9%/3.1%,同时以更快的速度运行,达到 50/27 FPS(批量大小为 32)。
Gold-YOLO-M 在速度相当的情况下,分别比 YOLOv6-3.0-M、YOLOX-M 和 PPYOLOE-M 的 AP 高出 1.1%、4.2% 和 2.1%。此外,它比 YOLOv5-M 和 YOLOv8-M 的 AP 分别高出 5.7% 和 0.9%,同时速度更快。Gold-YOLO-M 在保持相同 AP 的情况下,比 YOLOv7 显著提升了 98FPS(批量大小为 32)。Gold-YOLO-L 相比 YOLOv8-L 和 YOLOv6-3.0-L 也实现了更高的精度,分别具有 0.4% 和 0.5% 的明显精度优势,同时在批量大小为 32 时保持了相似的 FPS。
4.3 消融实验
4.3.1 GD结构的消融研究
为了验证我们关于FPN分析的有效性,并评估所提出的收集与分发机制的效果,我们独立检查了GD中的每个模块,重点关注AP、参数数量以及在T4 GPU上的延迟。Low-GD主要针对中小型物体,而High-GD主要检测大型物体,LAF模块则增强了两者的性能。实验结果如表2所示。

4.3.2 LAF消融实验
在本消融研究中,我们通过实验比较了LAF框架内不同模块设计的效果,并评估了模型规模变化对准确性的影响。研究结果支持了现有LAF结构确实是最优的论断。模型1和模型2的区别在于LAF使用的是加法还是拼接操作,而模型3在模型2的基础上增加了模型规模。模型4基于模型3,但舍弃了LAF。实验结果如表3所示。

4.3.3 其他模型和任务的消融研究
GD机制是一个通用概念,可以应用于YOLO之外的其他模型。我们已经将GD机制扩展到其他模型中,并取得了显著的改进。
在实例分割任务中,我们替换了Mask R-CNN中的不同颈部结构,并在COCO实例数据集上进行了训练和测试。结果如表4所示。

在语义分割任务中,我们在PointRend中替换了不同的颈部结构,并在Cityscapes数据集上进行了训练和测试。结果如表5所示。

在目标检测任务中,我们在EfficientDet中替换了不同的颈部结构,并在COCO数据集上进行了训练和测试。结果如表6所示。

5.结论
在本文中,我们重新审视了传统的特征金字塔网络(FPN)架构,并对其在信息传输方面的限制进行了深入分析。随后,我们开发了用于目标检测任务的Gold-YOLO系列模型,并取得了最先进的成果。在Gold-YOLO中,我们引入了一种创新的收集与分发机制,该机制经过精心设计,旨在提升信息融合与传输的效率和效果,避免不必要的损失,从而显著提高了模型的检测能力。我们真诚希望我们的工作能够为解决实际问题提供有价值的参考,并激发该领域研究者的新思路。
6.附录
A 一项额外实验
A.1 Gold-YOLO的详细准确性和速度数据
在本节中,我们报告了Gold-YOLO在有或没有LAF模块以及预训练情况下的测试性能。FPS和延迟是在相同环境下使用TensorRT 7在Tesla T4上以FP16精度测量的。我们模型的准确性和速度性能均在640x640的输入分辨率下进行评估。结果如表7所示。

表7:Gold-YOLO系列模型在COCO 2017验证集上的测试结果。'†'表示使用了自蒸馏方法,'⋄'表示模型没有LAF模块,'⋆'表示使用了MIM预训练方法。
A.2 MIM预训练消融实验
我们还比较了Gold-YOLO-S在COCO 2017验证集上不同MIM预训练轮次(无自蒸馏)的结果。结果如表8所示。

B 综合延迟与吞吐量基准测试
B.1 使用TensorRT 8在T4 GPU上的模型延迟和吞吐量
与其他YOLO系列检测器在COCO 2017验证集上的对比。FPS和延迟是在相同环境下使用TensorRT 8.2在Tesla T4上以FP16精度测量的。结果如表9所示。

B.2 使用TensorRT 7在V100 GPU上的模型延迟与吞吐量
与其他YOLO系列检测器在COCO 2017验证集上的对比。FPS和延迟是在Tesla V100上使用FP16精度在相同环境下通过TensorRT 7.2测量的。结果如表10所示。

C 更广泛的影响与局限性
更广泛的影响。YOLO模型可以广泛应用于医疗健康和智能交通等领域。在医疗健康领域,YOLO系列模型可以提高某些疾病的早期诊断率,降低初诊成本,从而挽救更多生命。在智能交通领域,YOLO模型可以辅助车辆自动驾驶,提升交通安全和效率。然而,YOLO模型在军事应用中也存在风险,例如用于无人机的目标识别和辅助军事侦察。我们将尽一切努力防止我们的模型被用于军事目的。
局限性。通常,对结构进行更精细的调整有助于进一步提升模型的性能,但这需要大量的计算资源。此外,由于我们的算法大量使用了注意力操作,可能对某些早期硬件支持不够友好。
D CAM 可视化
以下是YOLOv5、YOLOv6、YOLOv7、YOLOv8以及我们的Gold-YOLO在颈部区域的CAM可视化结果,如图6所示。可以看出,我们的模型对目标检测区域赋予了更高的权重。此外,我们在图7中对比了Gold-YOLO与YOLOv6在颈部区域的CAM可视化结果。

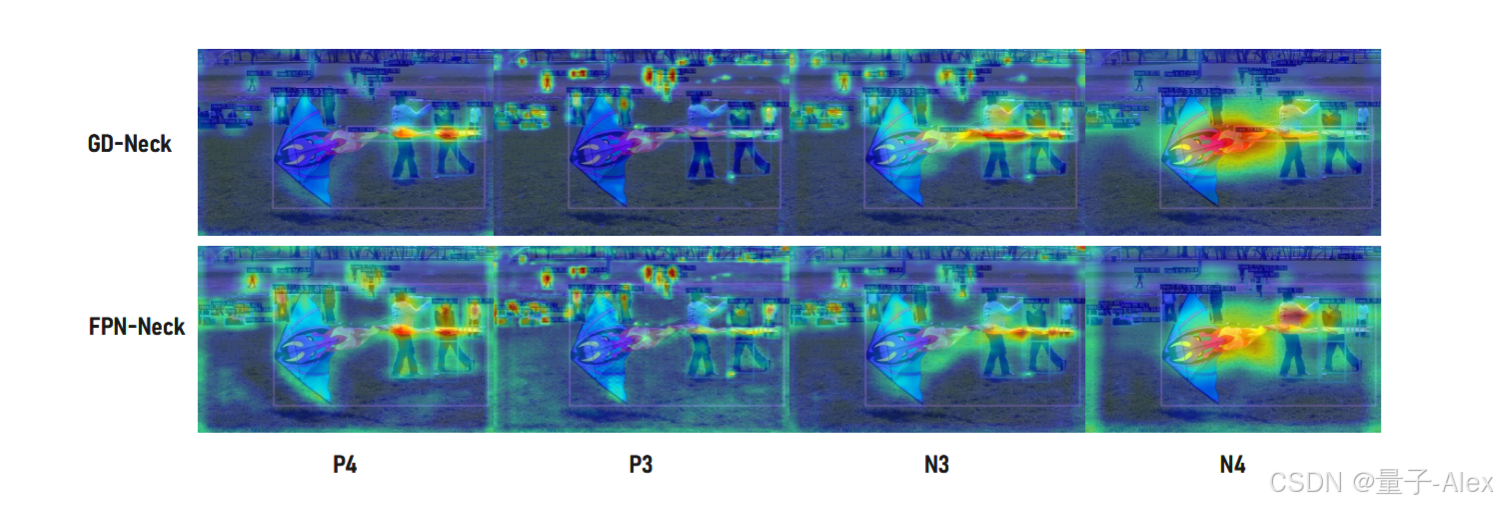
图7:颈部CAM可视化。我们可以观察到,不同层次的特征对不同大小的物体表现出不同的偏好。在传统的网格结构FPN中,随着网络深度的增加和不同层次之间的信息交互,特征图对物体位置的敏感性逐渐减弱,并伴随着信息丢失。我们提出的GD机制分别对高层和低层信息进行全局融合,生成的全局融合特征包含了丰富的大小物体的位置信息。
E.讨论
E.1 Gold-YOLO的特征对齐模块与其他类似工作的区别。
M2Det和RHF-Net都在其对齐模块中引入了额外的信息融合模块。在M2Det中,SFAM模块包含了一个SE块,而在RHF-Net中,空间金字塔池化块则通过瓶颈层进行了增强。与M2Det和RHF-Net不同,Gold-YOLO更倾向于模块之间的功能分离,将特征对齐和特征融合分别划分到不同的模块中。具体来说,GoldD-YOLO中的FAM模块仅专注于特征对齐,这确保了FAM模块的计算效率。而LAF模块则以最小的计算成本高效地融合了来自不同层次的特征,将更多的融合和注入功能留给其他模块。基于GD机制,使用简单且易于获取的算子即可实现YOLO模型的SOTA性能,这充分证明了我们所提出方法的有效性。此外,在网络构建过程中,我们有意选择了简单且经过充分验证的结构。这一选择旨在避免某些算子因部署设备不支持而可能引发的开发和性能问题,从而确保整个机制的可用性和可移植性。
E.2 简单计算操作
在网络构建过程中,我们借鉴并发展了前人的经验。与仅仅通过增强特定算子或局部结构来提升性能不同,我们的重点在于GD机制相较于传统FPN结构所带来的概念性转变。通过GD机制,YOLO模型能够使用简单且易于应用的算子实现SOTA性能。这有力地证明了所提出方法的有效性。
此外,在网络构建过程中,我们有意选择了简单且经过充分验证的结构。这一选择旨在避免由于某些操作符不被部署设备支持而可能引发的开发和性能问题。因此,它确保了整个机制的可用性和可移植性。同时,这一决策也为未来的性能提升创造了机会。GD机制是一个通用概念,可以应用于YOLO之外的其他模型。我们已将GD机制扩展到其他模型,并取得了显著的改进。实验表明,我们提出的GD机制表现出强大的适应性和泛化能力。该机制在不同任务和模型中始终带来性能提升。
7.引用文献
- 1 Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers, 2022.
- 2 Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
- 3 Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part I 16, pages 213--229. Springer, 2020.
- 4 Ping-Yang Chen, Ming-Ching Chang, Jun-Wei Hsieh, and Yong-Sheng Chen. Parallel residual bi-fusion feature pyramid network for accurate single-shot object detection. IEEE Transactions on Image Processing, 30:9099--9111, 2021.
- 5 Ping-Yang Chen, Jun-Wei Hsieh, Chien-Yao Wang, and Hong-Yuan Mark Liao. Recursive hybrid fusion pyramid network for real-time small object detection on embedded devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 402--403, 2020.
- 6 Qiang Chen, Yingming Wang, Tong Yang, Xiangyu Zhang, Jian Cheng, and Jian Sun. You only look one-level feature. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13039--13048, 2021.
- 7 Yukang Chen, Tong Yang, Xiangyu Zhang, Gaofeng Meng, Xinyu Xiao, and Jian Sun. Detnas: Backbone search for object detection. Advances in Neural Information Processing Systems, 32, 2019.
- 8 Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A largescale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248--255, 2009.
- 9 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- 10 Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6569--6578, 2019.
- 11 Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021.
- 12 Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7036--7045, 2019.
- 13 Jocher Glenn. Yolov5 release v6.1. https://github.com/ultralytics/yolov5/ releases/tag/v6.1, 2022.
- 14 Jocher Glenn. Ultralytics yolov8. https://github.com/ultralytics/ultralytics, 2023.
- 15 Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. Levit: a vision transformer in convnet's clothing for faster inference. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1225912269, 2021.
- 16 Jianyuan Guo, Kai Han, Yunhe Wang, Han Wu, Xinghao Chen, Chunjing Xu, and Chang Xu. Distilling object detectors via decoupled features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2154--2164, 2021.
- 17 Jianyuan Guo, Kai Han, Yunhe Wang, Chao Zhang, Zhaohui Yang, Han Wu, Xinghao Chen, and Chang Xu. Hit-detector: Hierarchical trinity architecture search for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11405--11414, 2020.
- 18 Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Xinghao Chen, Yunhe Wang, and Chang Xu. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12175--12185, 2022.
- 19 Jianyuan Guo, Kai Han, Han Wu, Chao Zhang, Xinghao Chen, Chunjing Xu, Chang Xu, and Yunhe Wang. Positive-unlabeled data purification in the wild for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2653--2662, 2021.
- 20 Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, et al. A survey on vision transformer. IEEE transactions on pattern analysis and machine intelligence, 45(1):87--110, 2022.
- 21 Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1580--1589, 2020.
- 22 Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang. Transformer in transformer. Advances in Neural Information Processing Systems, 34:15908--15919, 2021.
- 23 Zhiwei Hao, Jianyuan Guo, Ding Jia, Kai Han, Yehui Tang, Chao Zhang, Han Hu, and Yunhe Wang. Learning efficient vision transformers via fine-grained manifold distillation. In Advances in Neural Information Processing Systems, 2022.
- 24 Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021.
- 25 Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961--2969, 2017.
- 26 Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016.
- 27 Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- 28 Zilong Huang, Youcheng Ben, Guozhong Luo, Pei Cheng, Gang Yu, and Bin Fu. Shuffle transformer: Rethinking spatial shuffle for vision transformer. arXiv preprint arXiv:2106.03650, 2021.
- 29 Zhenchao Jin, Bin Liu, Qi Chu, and Nenghai Yu. Safnet: A semi-anchor-free network with enhanced feature pyramid for object detection. IEEE Transactions on Image Processing, 29:9445--9457, 2020.
- 30 Zhenchao Jin, Dongdong Yu, Luchuan Song, Zehuan Yuan, and Lequan Yu. You should look at all objects. In European Conference on Computer Vision, pages 332--349. Springer, 2022.
- 31 Chuyi Li, Lulu Li, Yifei Geng, Hongliang Jiang, Meng Cheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, and Xiangxiang Chu. Yolov6 v3. 0: A full-scale reloading. arXiv preprint arXiv:2301.05586, 2023.
- 32 Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976, 2022.
- 33 Xiangtai Li, Ansheng You, Zhen Zhu, Houlong Zhao, Maoke Yang, Kuiyuan Yang, Shaohua Tan, and Yunhai Tong. Semantic flow for fast and accurate scene parsing. In Computer VisionECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part I 16, pages 775--793. Springer, 2020.
- 34 Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117--2125, 2017.
- 35 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012--10022, 2021.
- 36 Wenyu Lv, Shangliang Xu, Yian Zhao, Guanzhong Wang, Jinman Wei, Cheng Cui, Yuning Du, Qingqing Dang, and Yi Liu. Detrs beat yolos on real-time object detection. arXiv preprint arXiv:2304.08069, 2023.
- 37 Y Quan, D Zhang, L Zhang, and J Tang. Centralized feature pyramid for object detection. arxiv 2022. arXiv preprint arXiv:2210.02093, 41.
- 38 Harish Guruprasad Ramaswamy et al. Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 983--991, 2020.
- 39 Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779--788, 2016.
- 40 Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7263--7271, 2017.
- 41 Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- 42 Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- 43 Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105--6114. PMLR, 2019.
- 44 Mingxing Tan, Ruoming Pang, and Quoc V Le. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10781--10790, 2020.
- 45 Keyu Tian, Yi Jiang, Qishuai Diao, Chen Lin, Liwei Wang, and Zehuan Yuan. Designing bert for convolutional networks: Sparse and hierarchical masked modeling. arXiv preprint arXiv:2301.03580, 2023.
- 46 Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9627--9636, 2019.
- 47 Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, and Li Zhang. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. arXiv preprint arXiv:2301.13156, 2023.
- 48 Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. Yolov7: Trainable bag-offreebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696, 2022.
- 49 Kaixin Wang, Jun Hao Liew, Yingtian Zou, Daquan Zhou, and Jiashi Feng. Panet: Few-shot image semantic segmentation with prototype alignment. In proceedings of the IEEE/CVF international conference on computer vision, pages 9197--9206, 2019.
- 50 Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Convnext v2: Co-designing and scaling convnets with masked autoencoders, 2023.
- 51 Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling, 2022.
- 52 Shangliang Xu, Xinxin Wang, Wenyu Lv, Qinyao Chang, Cheng Cui, Kaipeng Deng, Guanzhong Wang, Qingqing Dang, Shengyu Wei, Yuning Du, et al. Pp-yoloe: An evolved version of yolo. arXiv preprint arXiv:2203.16250, 2022.
- 53 Guoyu Yang, Jie Lei, Zhikuan Zhu, Siyu Cheng, Zunlei Feng, and Ronghua Liang. Afpn: Asymptotic feature pyramid network for object detection. arXiv preprint arXiv:2306.15988, 2023.
- 54 Yang You, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar, Srinadh Bhojanapalli, Xiaodan Song, James Demmel, Kurt Keutzer, and Cho-Jui Hsieh. Large batch optimization for deep learning: Training bert in 76 minutes, 2020.
- 55 Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou, Fengwei Yu, and Wei Wu. Incorporating convolution designs into visual transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 579--588, 2021.
- 56 Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and HeungYeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605, 2022.
- 57 Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- 58 Wenqiang Zhang, Zilong Huang, Guozhong Luo, Tao Chen, Xinggang Wang, Wenyu Liu, Gang Yu, and Chunhua Shen. Topformer: Token pyramid transformer for mobile semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12083--12093, 2022.
- 59 Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6848--6856, 2018.
- 60 Qijie Zhao, Tao Sheng, Yongtao Wang, Zhi Tang, Ying Chen, Ling Cai, and Haibin Ling. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 9259--9266, 2019.
- 61 Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020.