一、Redis初识
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
------>摘自Redis中文网
相较于MySql,Redis的最大特点就是更快 Redis - The Real-time Data Platform 
在之前的学习中,定义变量是通过变量存储的方式,而Redis是在内存中存储数据
在分布式系统中,Redis更具优势
Redis基于网络,将自己内存中的数据给别的进程(主机)使用 (进程的隔离性)
二、分布式系统
1.单机架构
应用程序+数据库服务器
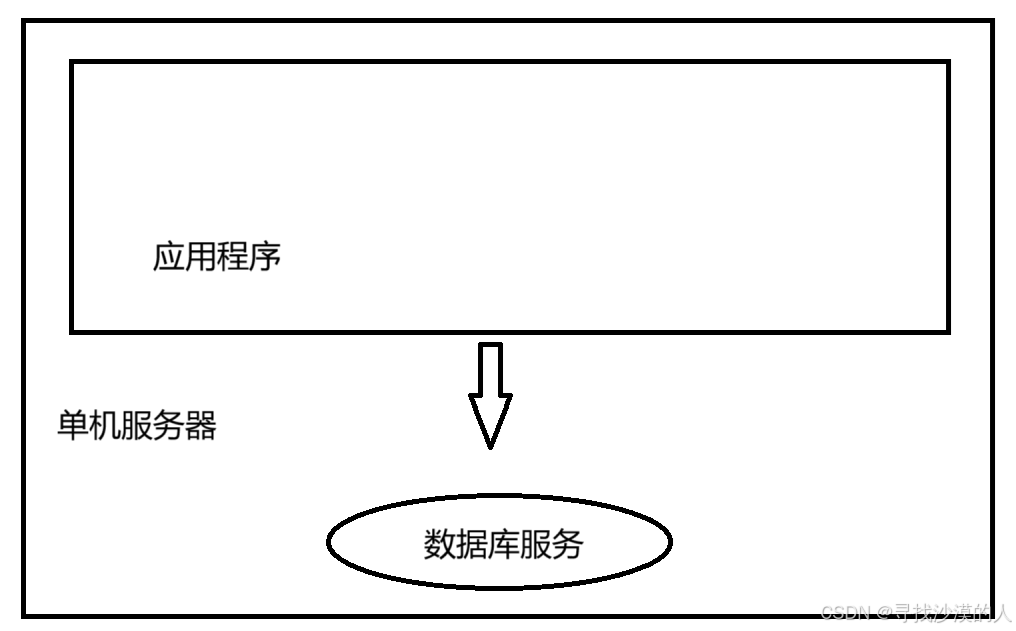
单机架构,只有一台服务器,这个服务器负责所有的工作
应用程序:是程序员写的各种代码(服务器程序)
Mysql:是一个客户端服务器结构的程序,本体是Mysql服务器(存储和处理数据的部分)

2.数据库和应用分离
应用程序和数据库服务器,分别放到不同主机上部署

应用服务:里面可能会包含很多业务逻辑,可能会很吃CPU和内存
数据库服务器:需要更大的硬盘空间,更快的访问速度
3.引入负载均衡
通过负载均衡,把请求比较均匀得分发给集群中的每个应用服务器
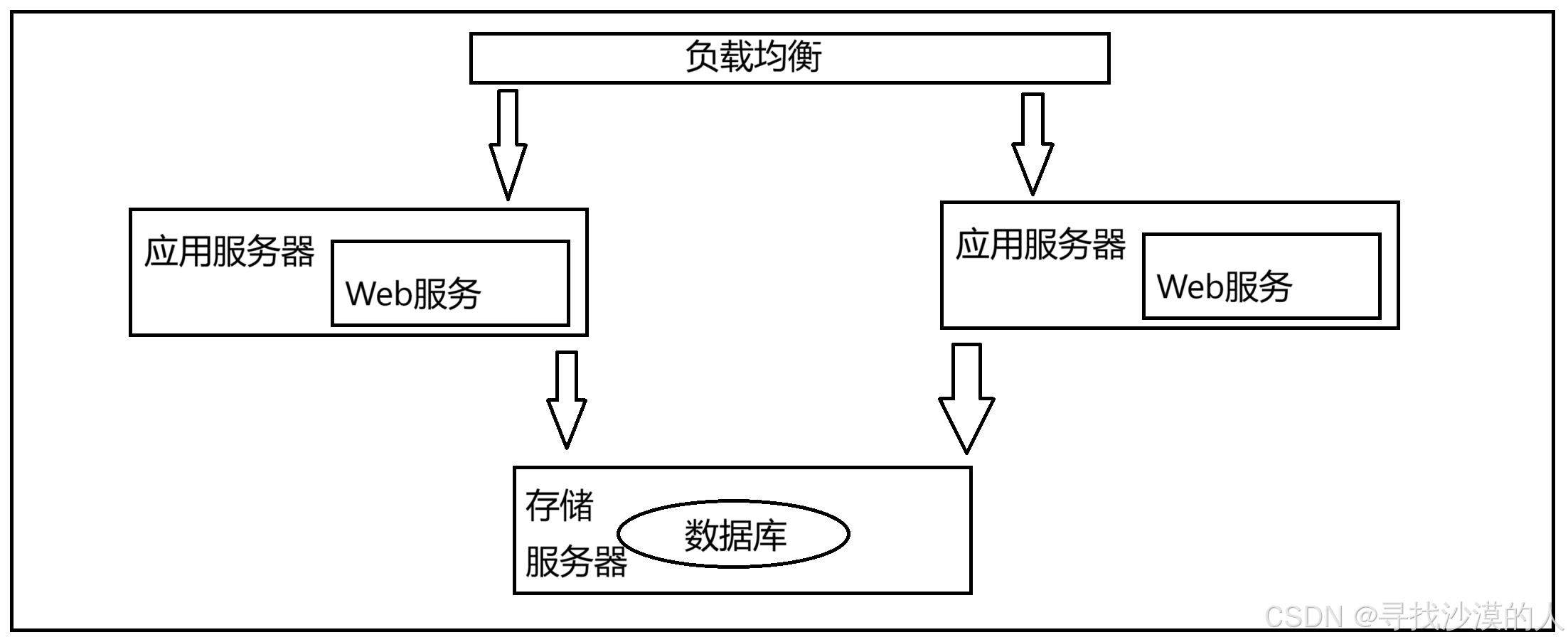
负载均衡器可以控制着多个应用服务器
用户的请求,先到达负载均衡的/网关服务器,在按照算法分发给具体的应用服务器
4.引入读写分离,数据库主从结构
一个数据库节点作为主节点,其他N个数据库节点作为从节点
主节点负责写数据,从节点负责读数据
(主节点需要把修改过的数据同步给从节点)
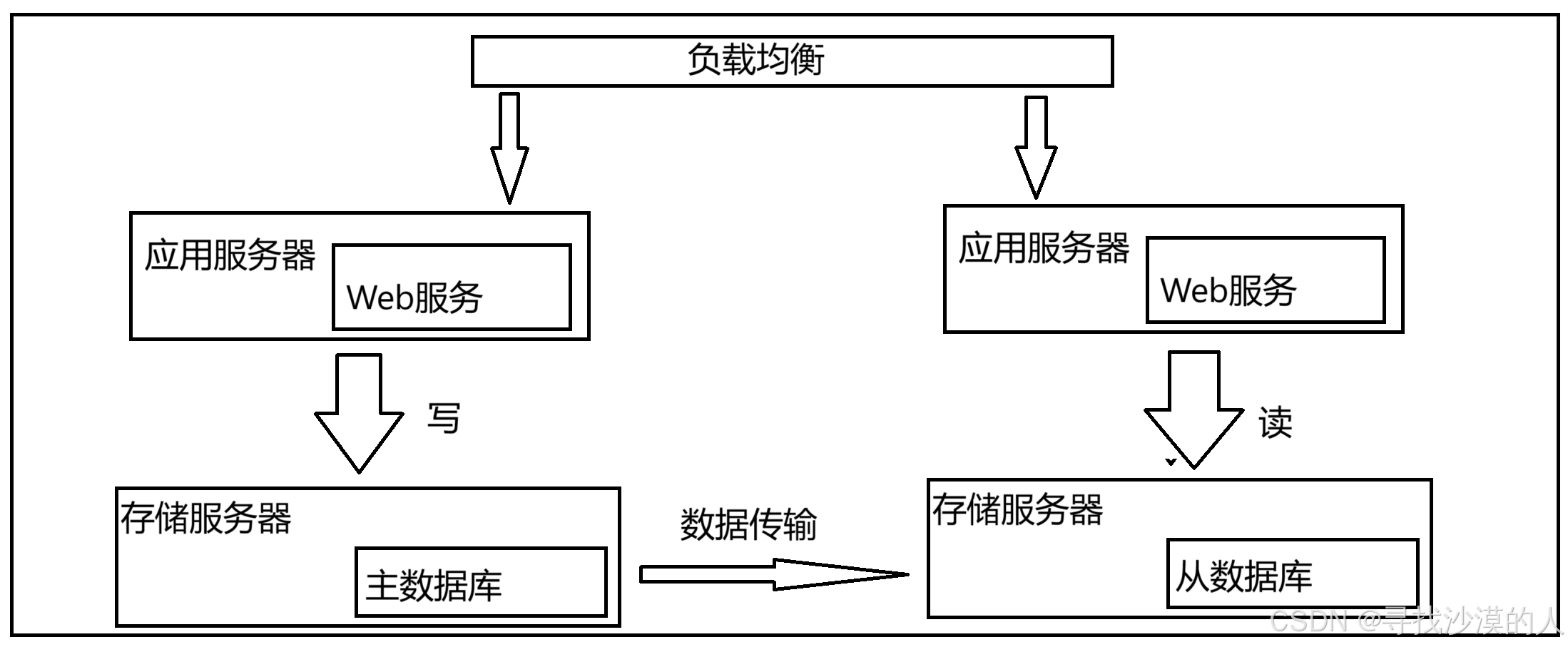
主服务器一般是一个,从服务器可以是多个
同时从数据库通过负载均衡的方式,让应用服务器进行访问
5.引入缓存,冷热数据分离
进一步提升了服务器针对请求的处理能力
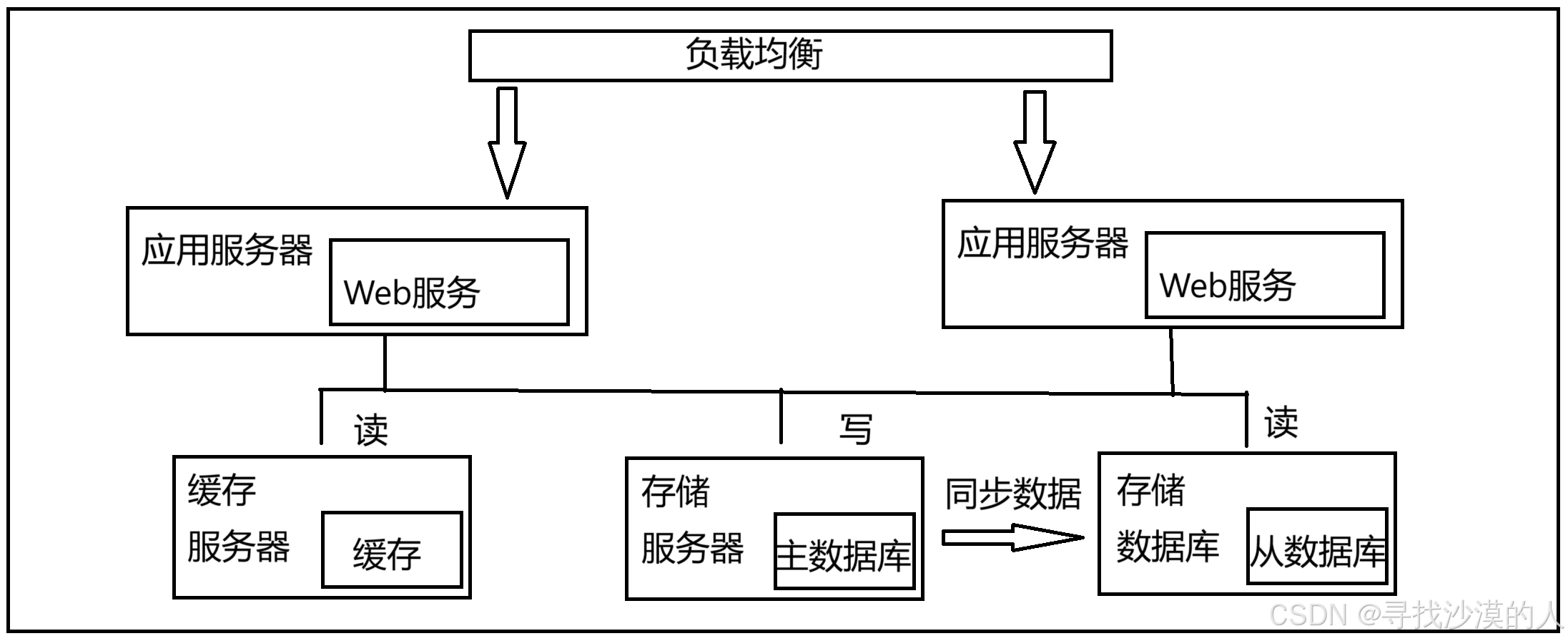
数据库天然有个问题,响应速度较慢
把数据区分"冷热",热点数据放到缓存里,缓存的访问速度往往比数据库要快得多
此时,存储数据库存储的仍然是完整的数据
6.引入分库分表
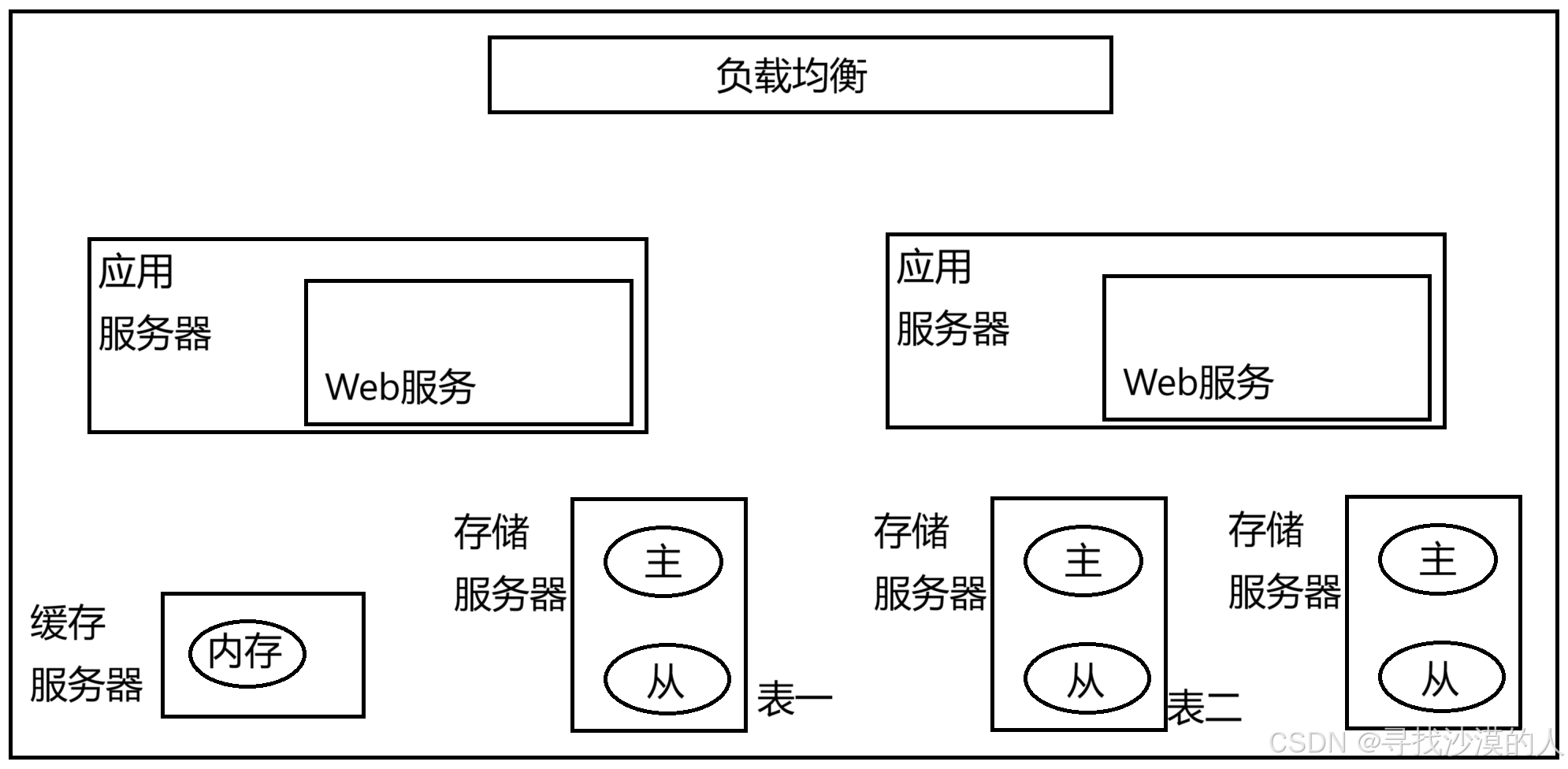
引入分布式系统,不仅要应对高请求量(并发量),同时也要应对更大的数据量
如果一台主机存储不下,就需要多台主机来存储 ------> 针对数据库进一步拆分(分库分表)
可以引入多个数据库服务器,每个数据库服务器存储一个或一部分数据库(也可以继续拆分表)
7.引入微服务
从业务功能的角度,把应用服务器,拆分成更多的功能更单一,更简单,更小的服务器
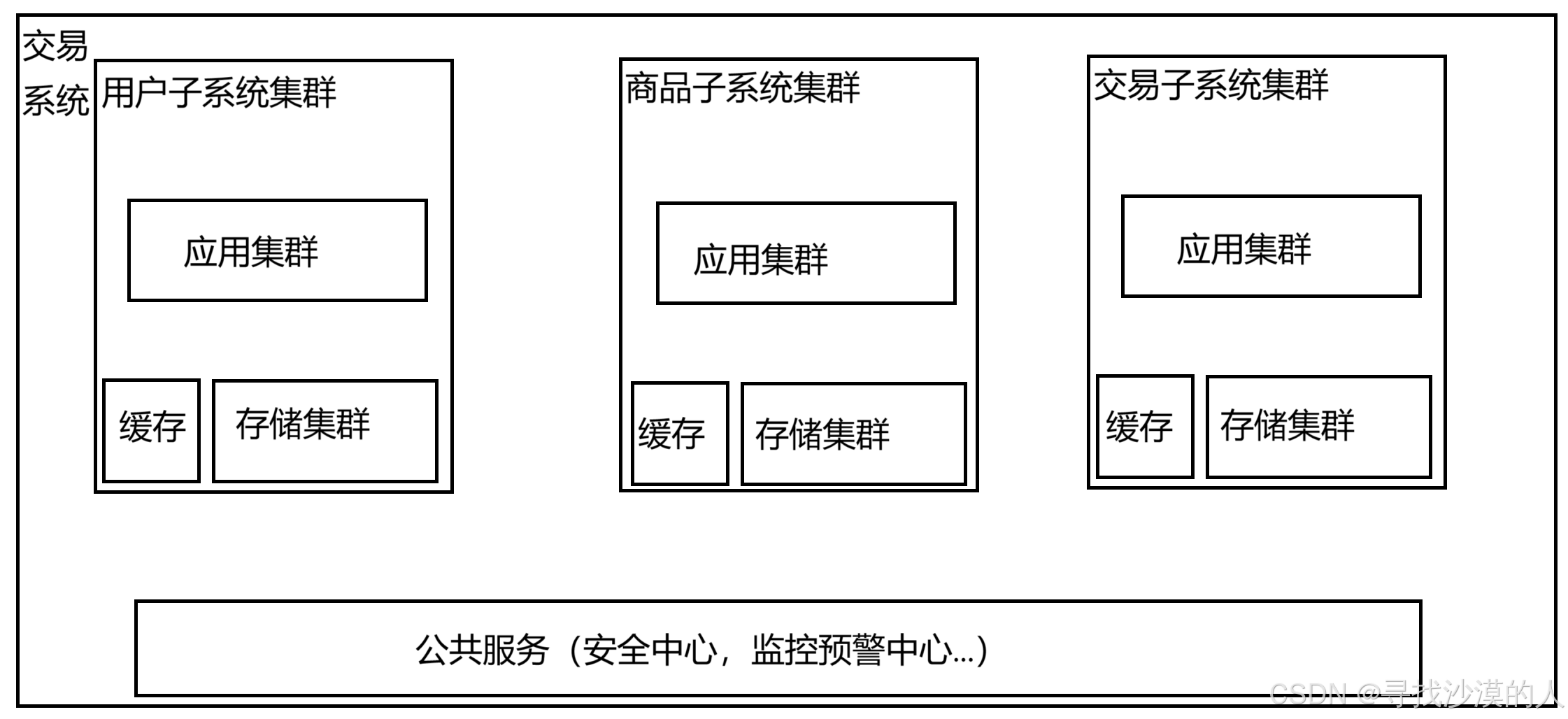
为了方便维护,可以把一个复杂的服务器,拆分成更多的,功能单一的,更小的服务器
三、总结
这里对一些比较重要的概念在进行再介绍:
1)应用(Application)/ 系统(System)
一个应用就是一个/组 服务器程序
2)模块(Module)/ 组件(Component)
一个应用,里面有很多的功能,每个独立的功能,就可以成为是一个 模块/组件
3)分布式(Distributed)
引入多个 主机/服务器,协同完成一系列的工作(物理上的主机)
4)集群(Cluster)
引入多个 主机/服务器,协同完成一系列的工作(逻辑上的主机)
5)主(Master)/ 从(Slave)
多个服务器节点,其中一个是 主,另外的是 从,从节点 的数据要从 主节点 同步过来
6)中间件(Middleware)
和业务无关的服务(功能更通用的服务)
-
数据库
-
缓存
-
消息队列
...
7)可用性(Availability)
考察单位时间段内,系统可以正常提供服务的概率/期望
平时只是⽤⾼可⽤(High Availability HA)这个非量化⽬标简要表达我们系统的追求
8)响应时⻓(Response Time)
用户完成输入到系统给出用户反应的时长
9) 吞吐(Throughput)vs 并发(Concurrent)
吞吐考察单位时间段内,系统成功处理的请求的数量。并发指系统同⼀时刻⽀持的请求最高量
平时⽤高并发(Hight Concurrnet)这个非量化目标简要表达系统的追求