🚀 前言
走完bootloader,本篇博客终于来到进入main前的最后一个文件: head.s ,对应了《linux源码趣读》的第8~10回。在上部分,我们已经将CPU进入了32位保护模式,本篇这部分的功能也主要就是做了 三件事 ,第一件事是重新设置中断描述符表与全局描述符表,第二件事是开启分页,第三件事是进入main函数,具体如何操作以及为什么要做这些,本文将会一一解答。希望各位给个三连,拜托啦,这对我真的很重要!!!
目录
🏆一些重要的前提
📃内存目前情况
在开始head.s的故事之前,我们先来回顾一下目前内存的情况:
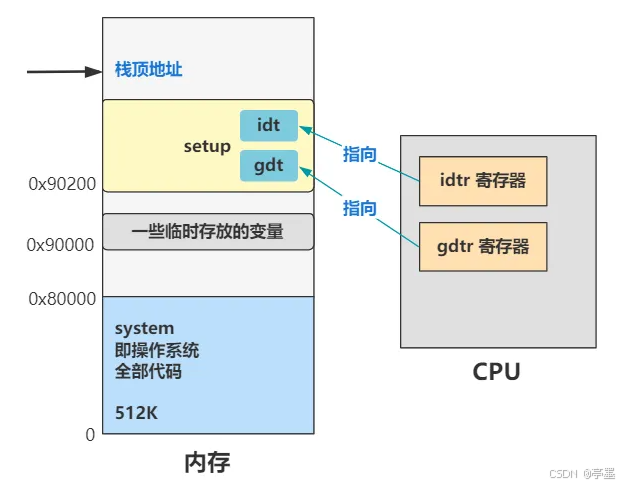
- 栈顶指针:地址是0x9FF00
- 系统代码:系统代码从0位置开始向上512KB
- 描述符表:存放在setup中,从0x90200处
📃汇编格式更改
还有一件事情需要说明,汇编语言的功能都一样,但是书写格式大致分为两种,一种是 AT&T汇编 格式,另一中是 Intel汇编 格式。本篇并不会详细说明这两种汇编格式的明确区别。现在只需要记住,两种汇编格式的mov指令的差异,以及Intel汇编采用NASM编译器,AT&T采用GNU的GAS编译器:
AT&T : MOV AX, 0x10 ; 从后面赋值到前面
Intel:mov $0x10, %ax ; 从前面赋值到后面
由于目前我们只需要看懂代码即可,因此暂时先明确这两种格式的区别方便我们看源码。在之前的boot.s和setup.s 文件中,采用的都是Intel格式 ,head.s 部分我们要采用AT&T格式。理由也很简单,因为在bootloader阶段,代码量大,Intel汇编可以方便阅读和书写;此外内核和应用程序只有一小部分关键代码要用汇编,绝大部分要用GNU C,那么搭配GNU编译的AT&T可以使得二者更加自然流畅地相互调用,提高二者的相互兼容性。
🏆重新设置中断描述符表与全局描述符表
📃为什么要重置
这里将这个问题放到前面来讨论,以免后面一直想着这回事。其实也没有什么高深的原因,就是因为原来设置的 gdt 是在 setup 程序中,之后这个地方要被缓冲区覆盖掉,所以这里重新设置在 head 程序中,这块内存区域之后就不会被其他程序用到并且覆盖了。
📃前期准备
head.s文件最开始如下所示:
AT&T
_pg_dir:
startup_32:
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
mov %ax,%fs
mov %ax,%gs
lss _stack_start,%esp这段注意到,代码格式已经变为了 AT&T汇编 ,因此要注意是将前面的值赋值给后面的寄存器。因此这一段汇编代码的作用就是将ds,es,fs,gs(fs和gs都是额外寄存器,这个不重要)寄存器的值都设置成0x10。
下面我们来详细看看为什么设置为0x10。注意!!此时我们处于保护模式下, 寻址方式需要经过段选择子!!!段寄存器的值变为段选择子的值,我们对照下面来看,将0x10拆分为二进制(0001, 0000)并参考下面的结构。

可以看到描述符索引的值为2,因此需要去全局描述符表中查看2对应什么,gdt如下所示,可以看到这段代码的作用就是将ds,es,fs,gs都指向数据段。
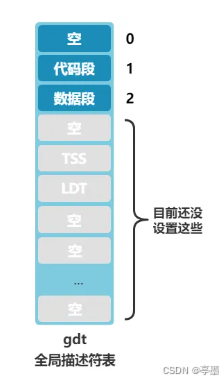
最后用了lss指令,这个指令是设置了栈顶指针,即es:esp指向_stack_start。至于这个标签,其在源码的位置为include/kernel/sched.c,具体的代码如下:
c
long user_stack[PAGE_SIZE >> 2];
struct {
long * a;
short b;
} stack_start = {&user_stack [PAGE_SIZE>>2] , 0x10}; 至于PAGE_SIZE定义在文件include/a.out.h中,为4096。最上面定义了一个4096 >> 2即 4096 / 2 / 2 = 1024 个long类型的元素,之后定义了一个结构体,包含一个long型的指针(位于低32位)和一个short型的变量(位于高16位)并初始化了一个变量stack_start,指针存储的是user_stack中最后一个元素后一个元素的地址,即后面压栈操作的新栈顶地址,会被赋给esp寄存器,变量存储的0x10,会被赋给ss栈寄存器。依据目前保护模式的寻址方式,ss寄存器中的值会按照段选择子的方式读取,读取结果是数据段。
到此处细心的读者已经发现为什么初始化结构体变量中是&user_stack [PAGE_SIZE>>2]而不是&user_stack [PAGE_SIZE>>2 - 1],那是因为这个位置需要指向一个空的地址作为新的栈顶地址,而不是需要拿出最后一个元素的地址,因此选择了最后一个元素 后一个元素 的地址。
📃重新设置IDT与GDT
回到head.S文件后面的内容:
AT&T
call setup_idt
call setup_gdt
movl $0x10,%eax ; reload all the segment registers
mov %ax,%ds ; after changing gdt. CS was already
mov %ax,%es ; reloaded in 'setup_gdt'
mov %ax,%fs
mov %ax,%gs
lss _stack_start,%esp在这段代码中,先设置了中断描述符表和全局描述符表,然后重新执行了一遍刚刚执行过的代码,对这些段寄存器重新设置。至于重新设置的原因,则是由于修改了全局描述符表,所以要重新设置一遍刷新后才能生效。
中断描述符表之前没有设置过,这里设置的代码如下:
AT&T
setup_idt:
lea ignore_int,%edx
movl $0x00080000,%eax
movw %dx,%ax /* selector = 0x0008 = cs */
movw $0x8E00,%dx /* interrupt gate - dpl=0, present */
lea _idt,%edi
mov $256,%ecx
rp_sidt:
movl %eax,(%edi)
movl %edx,4(%edi)
addl $8,%edi
dec %ecx
jne rp_sidt
lidt idt_descr
ret
···
.align 2
.word 0
idt_descr:
.word 256*8-1 # idt contains 256 entries
.long _idt
_idt: .fill 256,8,0 # idt is uninitialized 着重理解过程,这段代码中最终实现的效果就是设置了256个中断描述符,并且让每一个中断描述符中中断程序例程指向ignore_int的函数地址,这是一个默认的中断处理程序,之后会有各个具体的中断程序覆盖。这样一个中断号过来后,CPU会去中断描述符表中查找中断描述符,依据中断描述符寻找对应的中断程序的地址。对于gdt也是同样的设置方式,设置好的新gdt如下所示:
_gdt: .quad 0x0000000000000000 /* NULL descriptor */
.quad 0x00c09a0000000fff /* 16Mb */
.quad 0x00c0920000000fff /* 16Mb */
.quad 0x0000000000000000 /* TEMPORARY - don't use */
.fill 252,8,0 /* space for LDT's and TSS's etc */先说结论,这个和我们之前设置的结果是一样的!至于为什么一模一样,这个原因在本节开头已经说了。其中具体的设置如果要自己对照可以参考博客linux0.11源码分析第二弹------setup.s内容段描述符部分。现在内存如下图所示,GDT中最后还预留了252项留给任务状态段描述符TSS和局部描述符表LDT,这些都是为多任务准备的,后面提到再说。

🏆开启分页
📃为什么要分页
首先为什么要分页,之前分段存储不是已经够好了嘛。首先要知道即使使用了分段模式,我们依旧停留在线性地址就是物理地址这一弊端上。为什么说这是一个弊端呢,举个例子,比如当前系统还有两块离散的内存,一个为10M,一个为5M,但是此时有一个程序需要12M,这种情况下是无法分配的,因为不存在一个连续的12M的内存,这种情况下系统无法分配内存给程序,只能让程序等待。而分页机制则解决了这一个问题,分页本质上将虚拟地址与物理地址进行了一个映射,这样就可以让进程通过分配连续的虚拟地址享有12M,但是物理地址上可以不连续。
📃分页机制的地址转换
分段的情况下,线性地址直接就是物理地址,但是当开启了分页机制,在线性地址变为物理地址之前需要进行一个转换,转换如下图所示:
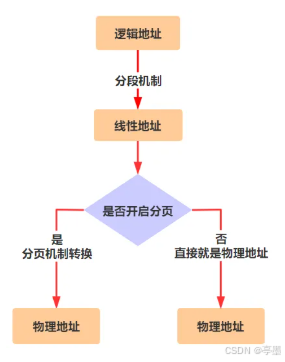
假设现在经过分段机制得到了一个线性地址15M,其二进制表示为0000000011 0100000000 000000000000。注意,此处32位的线性地址的拆分方式是: 高10位,中间10位,后12位 。高10位负责在页目录找到页目录项,页目录项加上中间10位到页表中找到页表项,页表项的值机上后12位偏移地址得到物理地址。以本博客为例,要找到上面这幅图,首先我知道这幅图大致在哪里,之后就去目录上找到 🏆开启分页 这一小节(对应页目录找页目录项的过程),之后找到 📃分页机制的地址转换(对应页表找页表项的过程),这是这一节第一张图(对应页表项加偏移地址得到物理地址的过程)。用超找流程图表示如下所示:
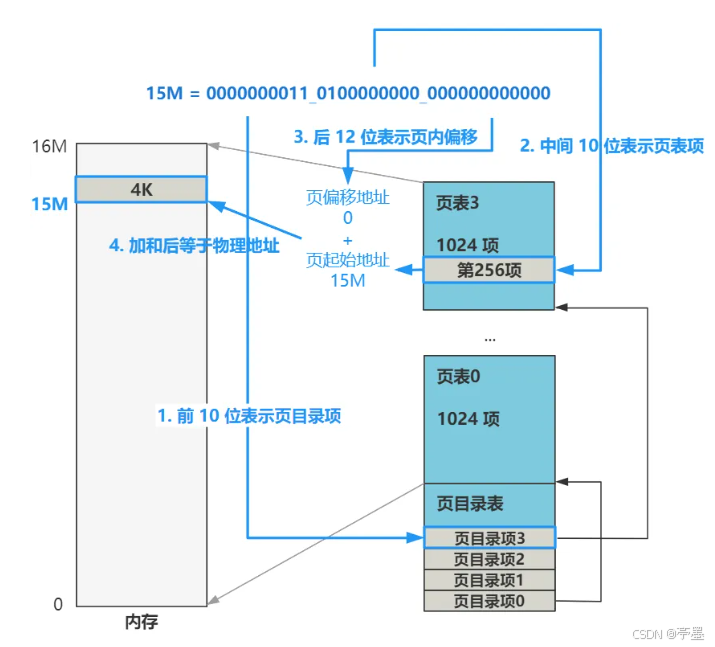
这个转换过程并不需要我们操心,计算中的内存管理单元MMU会帮我们完成,在软件层我们只需要提供好目录表和页表即可。上面这个过程是二级页表,第一级交页目录表PDE,第二级交页表PTE。结构如下图所示:

里面字段细节如下所示:
| 字段 | 描述 |
|---|---|
| P | 1:在物理内存中;0:不在物理内存中,必须置1 |
| R/W | 1:该页可读写;0:只读 |
| U/S | 1:用户和超级用户可访问;0:仅超级用户可访问 |
| PWT | 1:采用写穿透策略;0:不采用。用于控制告诉缓存的写策略 |
| PCD | 1:禁止对该页进行告诉缓存 |
| A | 当该页被访问时,硬件自动设置此位,操作系统可据此判断页的使用情况,用于页面置换算法等 |
| D | 当一个页被写入时,硬件会自动设置该位,表示此页已被修改过 |
| G | 1:该页目录项或页表项对应的映射关系是全局的 |
| AVL | 供操作系统使用的可用位,操作系统可以利用该位来记录页目录项或页表项的使用状态、统计信息等 |
📃开启方式
开启的方式很简单,依旧是控制机器状态字寄存器cr0即可,开关在第31位:
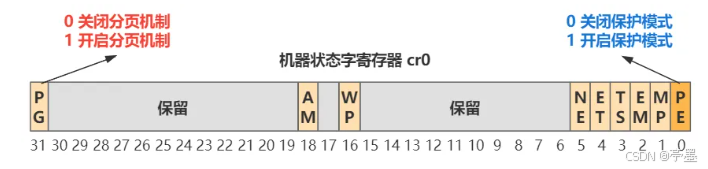
在linux中的实现方式如下:
AT&T
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
xorl %eax,%eax
xorl %edi,%edi /* pg_dir is at 0x000 */
cld;rep;stosl
movl $pg0+7,_pg_dir /* set present bit/user r/w */
movl $pg1+7,_pg_dir+4 /* --------- " " --------- */
movl $pg2+7,_pg_dir+8 /* --------- " " --------- */
movl $pg3+7,_pg_dir+12 /* --------- " " --------- */
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b首先,按照上一节介绍的方式,1个页目录表最多包含1024个页表(因为高10位决定页表编号),1个页表最多包含1024个页表项(因为中间也是10位决定页表项编号),1页为4KB(因为后12位为偏移地址)。考虑到当时 linux0.11 认为总共可以使用的内存不会超过16M,即最大地址空间位0xFFFFFF,页表最多只能有4页。这样分页最后就会用完这16MB:4 * 1024 * 1024=16MB。
上一段的作用是首先将内存清零,之后将页目录表存放在内存开始的位置(_pg_dir是在文件开始,即代表地址0x00000,证明页目录是从内存0处开始的),同时设置页表的属性($pg0+7可以自行展开并结合上一节的页表目录结构可得,表示页存在,用户可读写),将页表挨个放入页表目录中。每个页表的起始地址如下:
AT&T
.org 0x1000
pg0:
.org 0x2000
pg1:
.org 0x3000
pg2:
.org 0x4000
pg3:
.org 0x5000上面代码中后面6行(如下所示)表示填充4个页表的每一项,一共4 * 1024 = 4096项,循环次数就是 0xfff007 / 0x1000 + 1 = 4096次。如此便完成了内存与页表的映射关系。
AT&T
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b下面来看看内存中的情况:

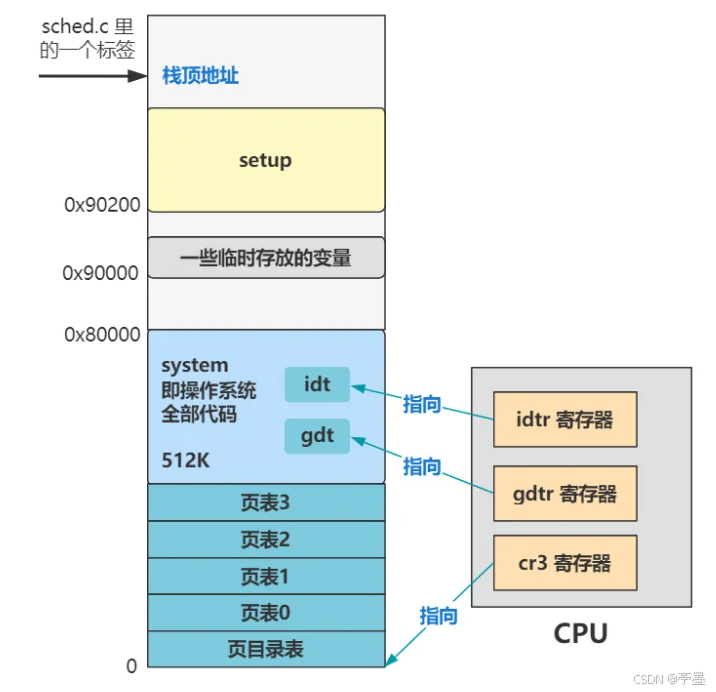
可以看到最开始的操作系统代码被覆盖了一部分,但是影响不大,因为已经执行过了。
接下来,如idt 和 gdt 一样,我们也需要通过一个寄存器告诉 CPU 我们把这些页表放在了哪,代码如下:
AT&T
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* 告诉cr3寄存器0地址是页目录表 */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* 开启分页 */
ret /* this also flushes prefetch-queue */上面的代码就告诉了 cr3 寄存器,0 地址处就是页目录表,再通过页目录表可以找到所有的页表,也就相当于 CPU 知道了分页机制的全貌了。同时通过cr0寄存器开启分页机制。
经过这一套转换,将16M的内存与16M的物理地址进行了映射,且得到的线性地址恰好是最终转换的物理地址。
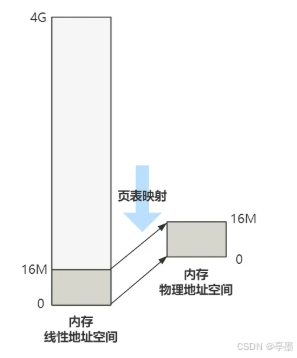
现在总结一下,逻辑地址 是程序员给出的,线性地址 是经过分段机制转换的,最后经过分页机制转换为物理地址。
🏆进入main函数
进入main函数代码如下所示:
after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0
pushl $0
pushl $L6 # return address for main, if it decides to.
pushl $_main
jmp setup_paging
L6:
jmp L6
...
setup_paging:
...
ret这代码就是将一些东西压栈,最终在设置分页后进行ret,跳转到栈顶所指的位置执行,现在栈的情况如下所示:
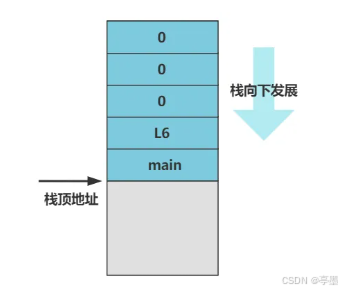
至于压入的L6,其是作为main函数返回的跳转地址,但是main函数是死循环,因此没有用,三个0是main函数的参数,但实际也没有用到。至此已经完成任务,操作系统准备完成,现在进入main函数了!
🎯总结
本文主要讲了分页操作,分页的开启主要是用cr0的31位,设置好页表目录和页表项与内存地址的映射,之后告知cr3寄存器页表目录的开始位置即可完成分页。同时在此之前还重新设置了IDT和GDT,被缓冲区覆盖掉。最后进入main函数,正式开始操作系统的内容!
📖参考资料
2 一个64位操作系统的设计与实现