用 llama.cpp 调用 Intel 的集成显卡 XPU 来提升推理效率.
驱动及依赖库
安装 Intel oneAPI Base Toolkit,确保显卡驱动支持 SYCL 和 oneAPI。
#安装 dpcpp-cpp-rt、mkl-dpcpp、onednn 等库:
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0重新安装 llama.cpp
如果已经安装过llama.cpp, 则要增加--force-reinstall 重新安装 。另外 增加-DLLAMA_SYCL=ON, 以打开对intel 集成显卡的支持。
-DLLAMA_AVX: 为启用CPU的AVX指令集加速
-DLLAMA_SYCL=ON: intel 集成显卡的支持。
$env:CMAKE_ARGS = "-DLLAMA_SYCL=ON -DLLAMA_AVX=on"
pip install --force-reinstall --no-cache-dir llama-cpp-python #如果安装失败,可更换版本,eg. 0.2.23
pip install --force-reinstall --no-cache-dir llama-cpp-python==0.2.23验证
配置n_gpu_layers > 0调用模型
>>> from llama_cpp import Llama
# 初始化模型,指定模型路径和GPU层数
>>> llm = Llama(model_path="llama-2-7b-chat.Q4_K_M.gguf", n_ctx=2048,n_threads=8, n_gpu_layers=32)
>>> print(llm("who are you!", max_tokens=50)["choices"][0]["text"])
>>> print(llm("请介绍一下人工智能的发展历史。", max_tokens=256)["choices"][0]["text"]) 运行时间对比cpu vx xpu
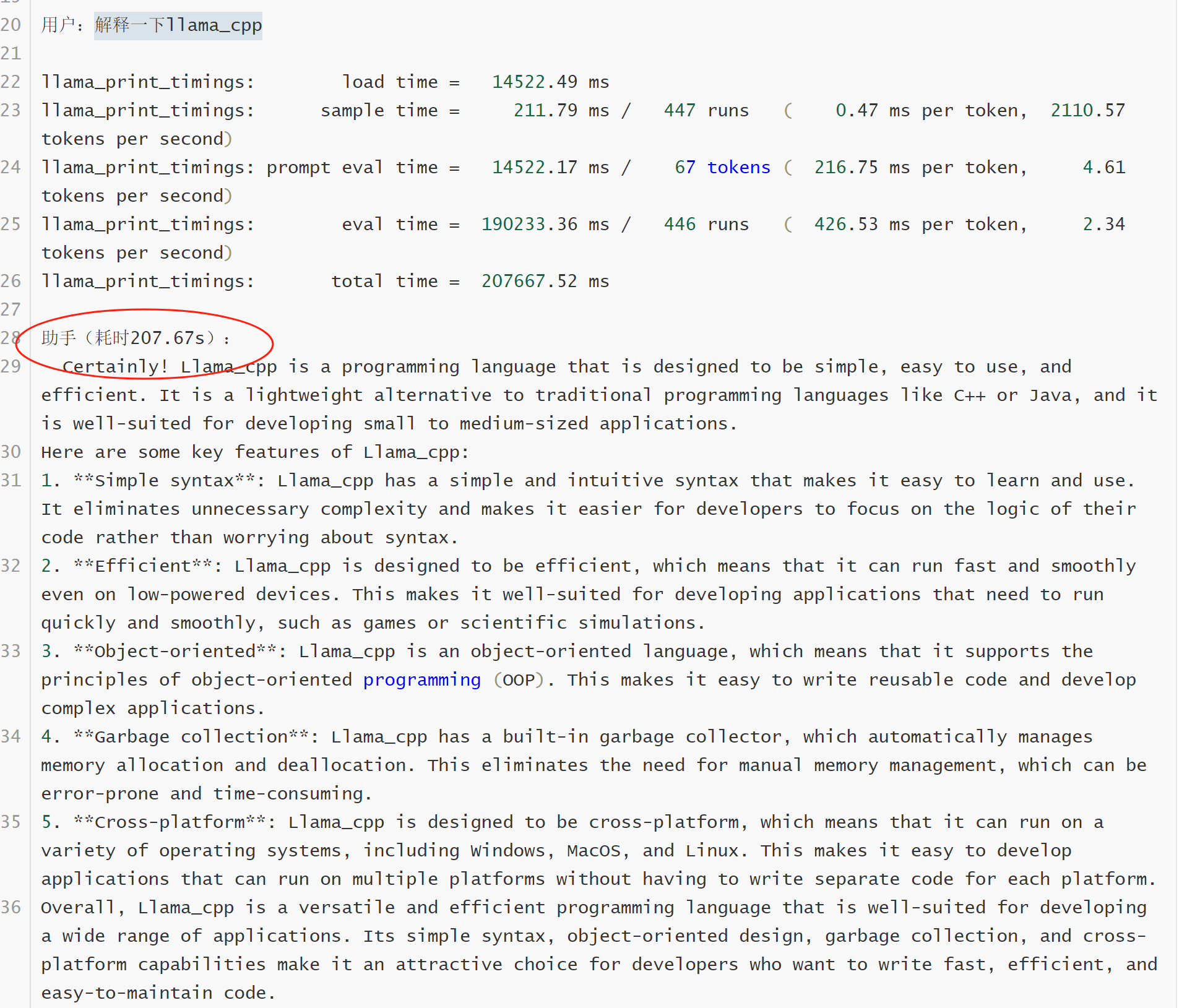
n_gpu_layers分别配置0和32, 来启动llama模型,请求相同的问题"解释一下llama_cpp", xpu方案在输出内容更长的情况下,耗时更短。178s vs 207s .
用户:解释一下llama_cpp
llama_print_timings: load time = 10713.40 ms
llama_print_timings: sample time = 297.97 ms / 500 runs ( 0.60 ms per token, 1678.00 tokens per second)
llama_print_timings: prompt eval time = 10713.22 ms / 67 tokens ( 159.90 ms per token, 6.25 tokens per second)
llama_print_timings: eval time = 163259.65 ms / 499 runs ( 327.17 ms per token, 3.06 tokens per second)
llama_print_timings: total time = 178246.50 ms
助手(耗时178.25s):
Certainly! llama_cpp is a programming language that is designed to be easy to use and understand, while also being powerful enough to build complex applications. It is based on the C++ programming language, but has several features that make it more accessible to beginners and non-experts.
Here are some key features of llama_cpp:
1. Syntax: LLama_cpp has a simplified syntax compared to C++, which makes it easier to read and write code. For example, in LLama_cpp, you don't need to use parentheses for function calls, and you can omit the semicolon at the end of statements.
2. Type Inference: LLama_cpp has type inference, which means that you don't need to explicitly specify the types of variables or function arguments. The compiler can infer the types based on the context.
3. Functional Programming: LLama_cpp supports functional programming concepts such as higher-order functions, closures, and immutable data structures. This makes it easier to write pure functions that are easy to reason about and test.
4. Object-Oriented Programming: LLama_cpp also supports object-oriented programming (OOP) concepts such as classes, objects, inheritance, and polymorphism.
5. Concise Code: LLama_cpp aims to be concise and efficient, allowing you to write code that is easy to read and understand while still being compact and efficient.
6. Cross-Platform: LLama_cpp is designed to be cross-platform, meaning it can run on multiple operating systems without modification. This makes it easier to write code that can be used on different platforms.
7. Extensive Standard Library: LLama_cpp has an extensive standard library that includes support for common data structures and algorithms, as well as a range of other useful functions.
8. Supportive Community: LLama_cpp has a growing community of developers and users who are actively contributing to the language and its ecosystem. This means there are many resources available online, including tutorials, documentation, and forums where you can ask questions and get help.
Overall, llama_cpp is a language that is designed to be easy to learn and use, while still being powerful enough to build complex applications. Its simplified syntax and type inference make it accessible to beginners, while its support for