文章目录
针对目前Agent开发需求逐渐增长,本文主要讲解向量、向量数据库、PostgreSQL+PGVector实现向量存储、RAG基础等
向量
在 Agent 开发中,"向量"通常指的是向量表示 或嵌入(embedding) ,它是一种将非结构化数据(如文本、图像、音频等)转换为高维数值向量的技术。这些向量能够被计算机高效处理,并用于衡量语义相似性、检索、分类、推荐等任务。
举个例子:
你有一句话:"我想学习Java编程语言"
Agent 会把它变成一个向量,比如:
[0.23, -0.45, 0.78, ..., 0.12] // 维度可能是 384、768、1536 等这个向量不是随机的,而是语义压缩的结果。
如果另一句话是:"我想学习Python编程语言",它们的向量会很接近,Agent 就知道这两句话意思相似,可以触发同一个意图(比如"学习编程")。
所以可以简单理解为:向量是 Agent 的"语义眼睛",让它看懂用户说什么、记得住、找得到。
向量数据库
向量数据库是一种专门设计用来存储和管理向量嵌入(vector embeddings)的数据库系统。它可以将非结构化数据 (如文本、图片、音频等)转换成高维向量的形式进行存储,并提供高效的相似性搜索功能。
在基于大模型的应用开发中,向量数据库主要解决以下核心问题:
1)高效的相似性搜索
通过将用户查询转换为向量,可以快速找到语义相似的内容,这对于实现智能问答、推荐系统等功能至关重要
2)海量数据处理
能够高效处理大模型生成的海量数据,传统数据库难以处理百万甚至数十亿的数据点,而向量数据库专门针对这种场景进行了优化。
3)实时交互支持
在需要实时用户交互的应用中如聊天机器人),向量数据库可以确保快速检索相关上下文信息,提供实时响应。
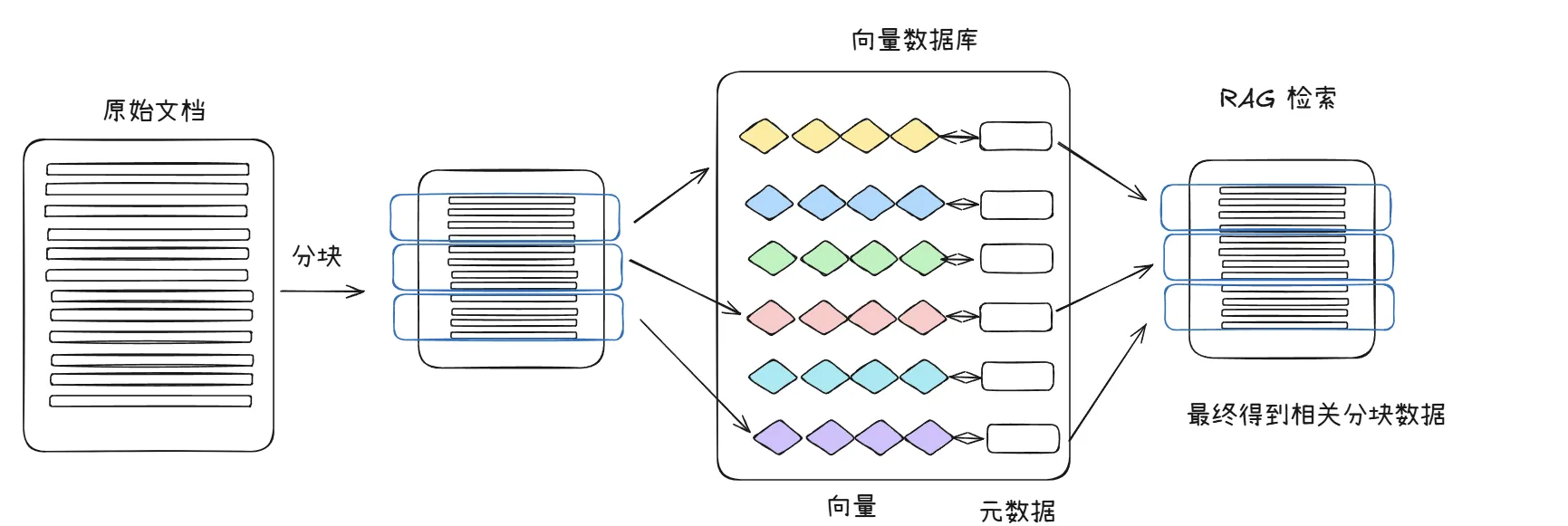
向量数据库工作原理
用户查询 查询向量 原始数据 向量嵌入 向量存储 相似度搜索 返回结果
PGSQL/PGVector实现向量存储
PGSQL介绍
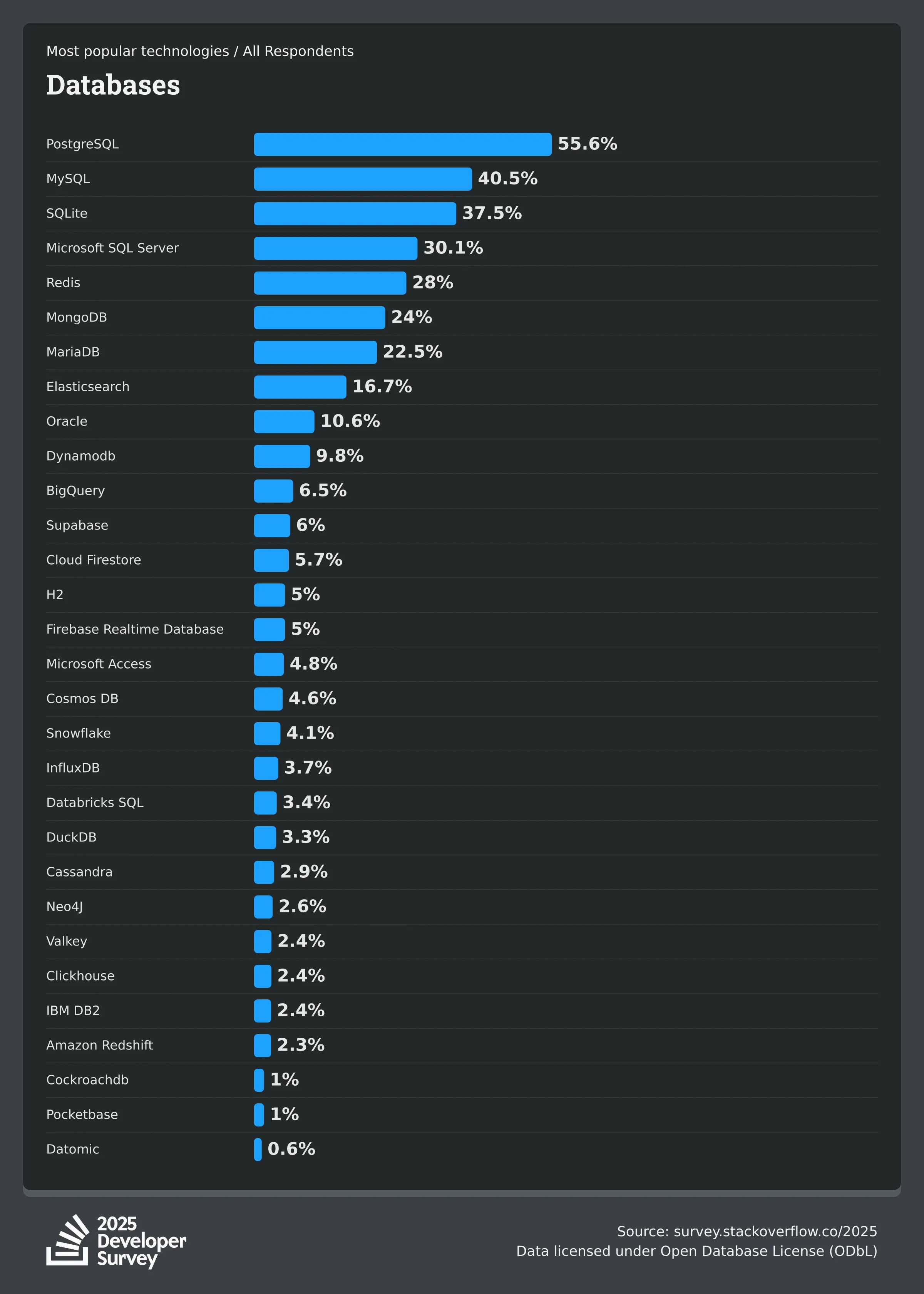
PostgreSQL数据库是功能强大的开源数据库,它支持丰富的数据类型(如JSON和JSONB类型、数组类型)和自定义类型,目前在Stack Overflow2025年开发者调查中排名第一。
PostgreSQL数据库的优势
PostgreSQL数据库具有以下优势:
- PostgreSQL数据库是目前功能最强大的开源数据库 ,它是最接近工业标准SQL92的查询语言,至少实现了SQL:2011标准中要求的179项主要功能中的160项(注:目前没有哪个数据库管理系统能完全实现SQL:2011标准中的所有主要功能)。
- **稳定可靠:**PostgreSQL是唯一能做到数据零丢失的开源数据库。目前有报道称国内外有部分银行使用PostgreSQL数据库。
- 开源省钱: PostgreSQL数据库是开源的、免费的,而且使用的是类BSD协议,在使用和二次开发上基本没有限制。
- **支持广泛:**PostgreSQL 数据库支持大量的主流开发语言,包括C、C++、Perl、Python、Java、Tcl以及PHP等。
- **PostgreSQL社区活跃:**PostgreSQL基本上每3个月推出一个补丁版本,这意味着已知的Bug很快会被修复,有应用场景的需求也会及时得到响应。
| 对比维度 | PostgreSQL | Oracle | MySQL |
|---|---|---|---|
| 开源/商业 | 开源(PostgreSQL License) | 商业(需授权,费用高) | 开源(GPL)+ 商业版(Oracle 提供) |
| 事务支持 | 完全支持 ACID,MVCC 实现优秀,支持所有隔离级别 | 完整 ACID,企业级事务控制,支持分布式事务 | 支持 ACID(InnoDB),默认隔离级别为 Repeatable Read |
| SQL 标准兼容 | 高度兼容 SQL 标准,支持复杂查询、CTE、窗口函数等 | 支持 SQL 标准 + 企业扩展(如 PL/SQL) | 基本兼容,部分高级功能(如窗口函数)8.0 后才支持 |
| JSON 支持 | 原生支持 JSON 和 JSONB,支持索引、路径查询,功能最强 | 12c 起支持 JSON,功能较强,适合混合结构数据 | 5.7 起支持 JSON,功能较弱,不支持 JSONB |
| 数据类型支持 | 支持丰富类型(如 JSONB、数组、UUID、GIS 等) | 支持结构化、半结构化数据(如 XML、JSON、CLOB) | 数据类型较少,JSON 支持较弱 |
| 高可用与复制 | 支持流复制、逻辑复制、热备、Patroni 高可用方案 | Data Guard、RAC(共享存储集群),企业级高可用 | 主从复制、半同步复制、MHA、InnoDB Cluster |
| 扩展性 | 插件丰富(如 PostGIS、TimescaleDB),支持 FDW 访问外部数据源 | 企业级扩展(如分区、压缩、OLAP 选项),支持异构访问 | 插件机制有限,分库分表需借助中间件(如 Vitess) |
| 并发控制 | MVCC,读写不冲突,适合高并发读 | 行级锁 + 自动锁升级,支持大并发写入 | InnoDB 行级锁,但间隙锁可能引发写入阻塞 |
| 适用场景 | 数据分析、GIS、JSON 存储、科学计算、复杂业务系统 | 金融、电信、大型企业核心系统,强事务一致性场景 | Web 应用、中小型系统、读多写少场景 |
PGVector
pgVector 是一个开源的 PostgreSQL 扩展插件 ,用于在 PostgreSQL 数据库中高效存储、查询和处理高维向量 数据。它特别适合需要进行向量相似性搜索的场景,例如语义搜索、图像检索、推荐系统等。通过 pgVector,PostgreSQL 可以被用作一个强大的向量数据库,与传统关系型数据库功能无缝集成。
具体安装可参考这篇博客跨平台向量库:Linux & Windows 上一条龙部署 PostgreSQL 向量扩展
pgVector 的核心功能
- 向量数据类型 :
- pgVector 提供了一个名为
vector的数据类型,用于存储高维向量(浮点数数组)。 - 支持高达 16,000 维 的向量,适用于主流嵌入模型(如 OpenAI 的 text-embedding-ada-002)。
- pgVector 提供了一个名为
- 相似性搜索 :
- 支持多种距离度量:
- 欧几里得距离(L2) :
<->运算符,计算向量间的直线距离。 - 余弦相似度 :
<=>运算符,比较向量方向。 - 内积 :
<#>运算符,适用于某些机器学习场景。 - 其他距离如 L1(曼哈顿距离)、汉明距离等。
- 欧几里得距离(L2) :
- 支持精确搜索 和近似最近邻(ANN)搜索,后者速度更快但精度略低。
- 支持多种距离度量:
- 索引支持 :
- HNSW(Hierarchical Navigable Small World):基于图的索引,适合高精度、高频查询场景,召回率高但构建时间长。
- IVFFlat:基于倒排索引的索引,适合大数据量场景,构建快但精度略低。
- 索引可以显著提高查询性能,尤其是在处理数百万条向量时。
- 无缝集成 :
- 作为 PostgreSQL 扩展,pgVector 使用标准的 SQL 语法,开发者无需学习新查询语言。
- 支持与 PostgreSQL 的其他功能(如 JOIN、事务、备份)结合。
- 可通过任何支持 PostgreSQL 的客户端(如 Python 的
psycopg2或 Node.js 的pg)访问。
- 其他特性 :
- 支持单精度、半精度、二进制和稀疏向量,优化存储和性能。
- 利用 PostgreSQL 的 ACID 事务、WAL(写前日志)等特性,确保数据一致性和可靠性。
RAG基础
什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和Al内容生成的混合架构,
可以解决大模型的知识时效性限制和幻觉问题。
从技术角度看,R八G在大语言模型生成回答之前,会先从外部知识库中检索相关信息,然后将这些检索到的内容
作为额外上下文提供给模型,引导其生成更准确、更相关的回答。
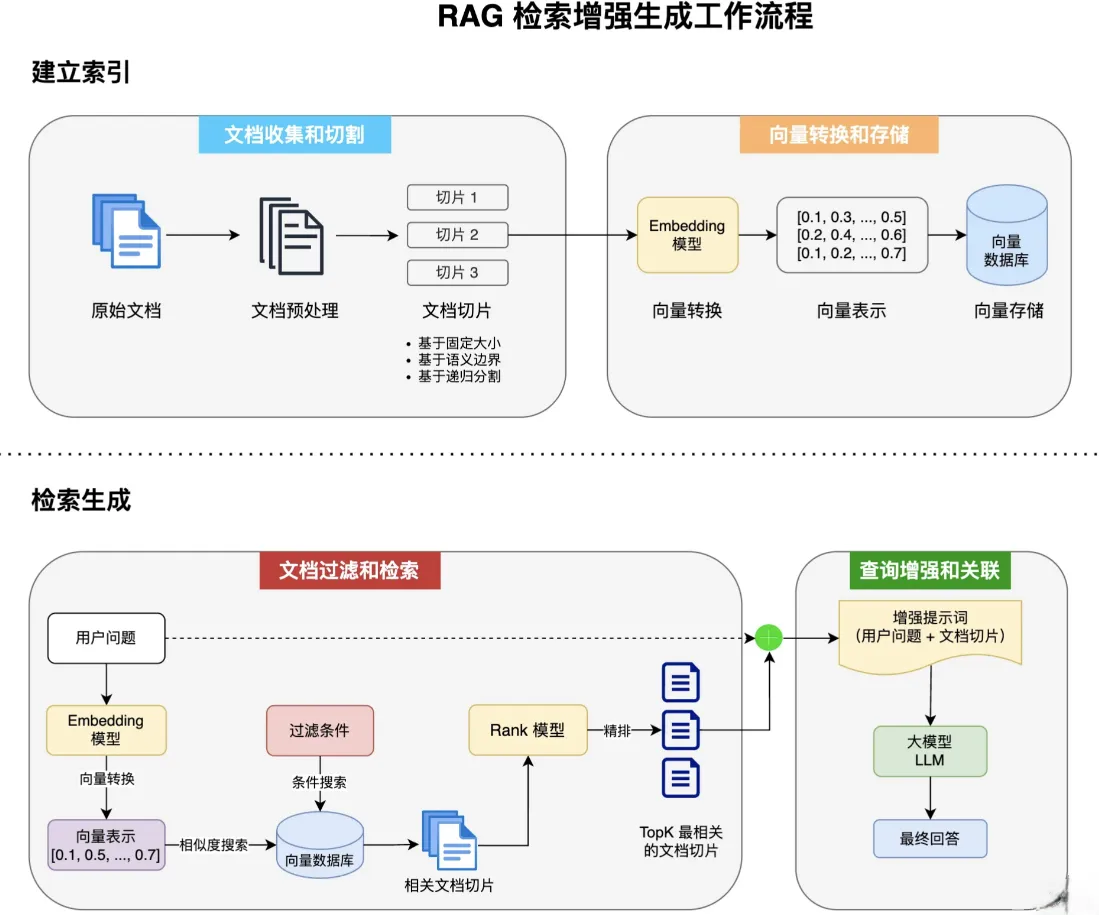
RAG工作流程
1.文档收集与切割
文档收集:从各种来源(网页、PDF、数据库等)收集原始文档
文档预处理:清洗、标准化文本格式
文档切割:将长文档分割成适当大小的片段(俗称chunks)
- 基于固定大小(如512个token)
- 基于语义边界(如段落、章节)
- 基于递归分割策略(如递归字符n-gram切割)

2. 向量转换与存储
向量转换:使用Embedding模型将文本块转换为高维向量表示,可以捕获到文本的语义特征
向量存储:将生成的向量和对应文本存入向量数据库,支持高效的相似性搜索

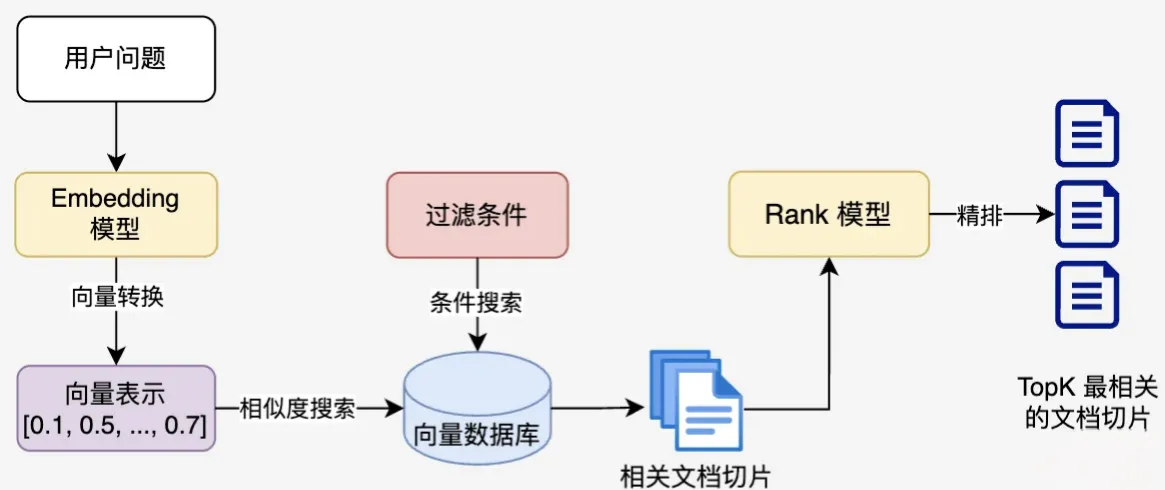
3. 文档过滤与存储
查询处理:将用户问题也转换为向量表示
过滤机制:基于元数据、关键词或自定义规则进行过滤
相似度搜索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦相似度、欧氏距离
等
上下文组装:将检索到的多个文档块组装成连贯上下文
4.查询增强与关联
提示词组装:将检索到的相关文档与用户问题组合成增强提示词
上下文融合:大模型基于增强提示生成回答
源引用:在回答中添加信息来源引用
后处理:格式化、摘要或其他处理以优化最终输出
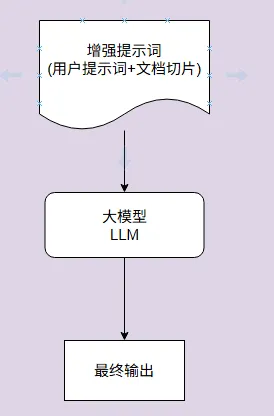
完整工作流程
.查询增强与关联
提示词组装:将检索到的相关文档与用户问题组合成增强提示词
上下文融合:大模型基于增强提示生成回答
源引用:在回答中添加信息来源引用
后处理:格式化、摘要或其他处理以优化最终输出
外链图片转存中...(img-wr1oRCmA-1760885182079)
完整工作流程