目录
[一、YOLOv4 的核心设计逻辑:模块化技术整合](#一、YOLOv4 的核心设计逻辑:模块化技术整合)
[二、YOLOv4 的关键技术改进:从数据到结构的全链路优化](#二、YOLOv4 的关键技术改进:从数据到结构的全链路优化)
[2.1 数据增强](#2.1 数据增强)
[2.1.1 马赛克数据增强(Mosaic)](#2.1.1 马赛克数据增强(Mosaic))
[2.1.2 随机擦除与隐藏搜索](#2.1.2 随机擦除与隐藏搜索)
[2.1.3 自对抗训练(SAT)](#2.1.3 自对抗训练(SAT))
[2.1.4 标签平滑与 DropBlock](#2.1.4 标签平滑与 DropBlock)
[2.2 损失函数优化](#2.2 损失函数优化)
[2.3 非极大值抑制(NMS)改进](#2.3 非极大值抑制(NMS)改进)
[2.4 网络结构升级](#2.4 网络结构升级)
[2.4.1 骨干网络:CSPDarknet53](#2.4.1 骨干网络:CSPDarknet53)
[2.4.2 Neck 网络:SPP+PAN](#2.4.2 Neck 网络:SPP+PAN)
[2.4.3 注意力机制与激活函数](#2.4.3 注意力机制与激活函数)
[2.4.4 网格敏感性优化](#2.4.4 网格敏感性优化)
[三、YOLOv4 的性能优势](#三、YOLOv4 的性能优势)
在深度学习目标检测的发展中,YOLO(You Only Look Once)系列凭借 "单阶段检测" 的高效性成为热门方向。2020 年推出的 YOLOv4,虽更换了核心开发团队,却延续并深化了 YOLO 系列 "平衡速度与精度" 的核心目标 ------ 通过系统性整合当时主流框架的先进技术,在不牺牲实时检测能力的前提下,大幅提升检测性能,成为兼顾学术创新性与工业实用性的经典模型。本文将从设计思路、关键改进与性能优势出发,解析 YOLOv4 的技术核心。
一、YOLOv4 的核心设计逻辑:模块化技术整合
YOLOv4 的突破并非依赖单一技术创新,而是通过 "分类整合、按需优化" 的模块化思路,将目标检测领域的先进技术划分为两类核心策略,精准平衡性能与效率:
- 无成本增益技术(Bag of Freebies,即不增加推理时计算量的优化):仅通过数据预处理、训练策略调整提升模型性能,比如数据增强、标签平滑等,这类优化不会给实际使用时的检测速度带来负担;
- 有限成本增益技术(Bag of Specials,即轻微增加计算量的优化):以少量额外计算为代价换取显著精度提升,比如改进的网络结构、注意力机制等,既能保证实时性,又能弥补前代模型的性能短板。
这种思路让 YOLOv4 既能适配工业场景对 "快速检测" 的需求,又能解决小目标检测、边界框定位不准等实际问题。
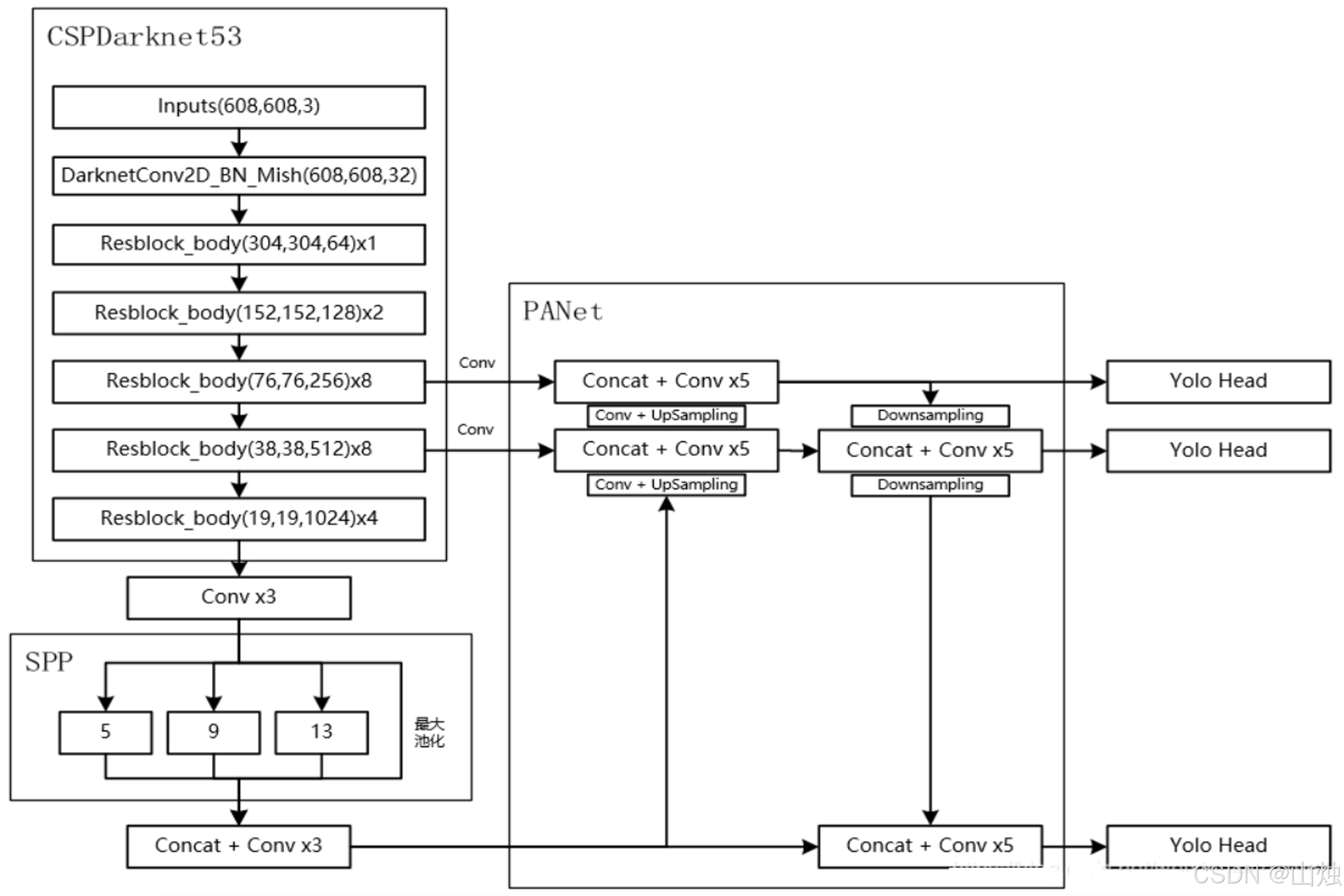
二、YOLOv4 的关键技术改进:从数据到结构的全链路优化
2.1 数据增强
数据增强是 YOLOv4 提升精度的核心手段,通过丰富训练数据的多样性,让模型在复杂场景中也能稳定工作,主要有以下几种方式:
2.1.1 马赛克数据增强(Mosaic)
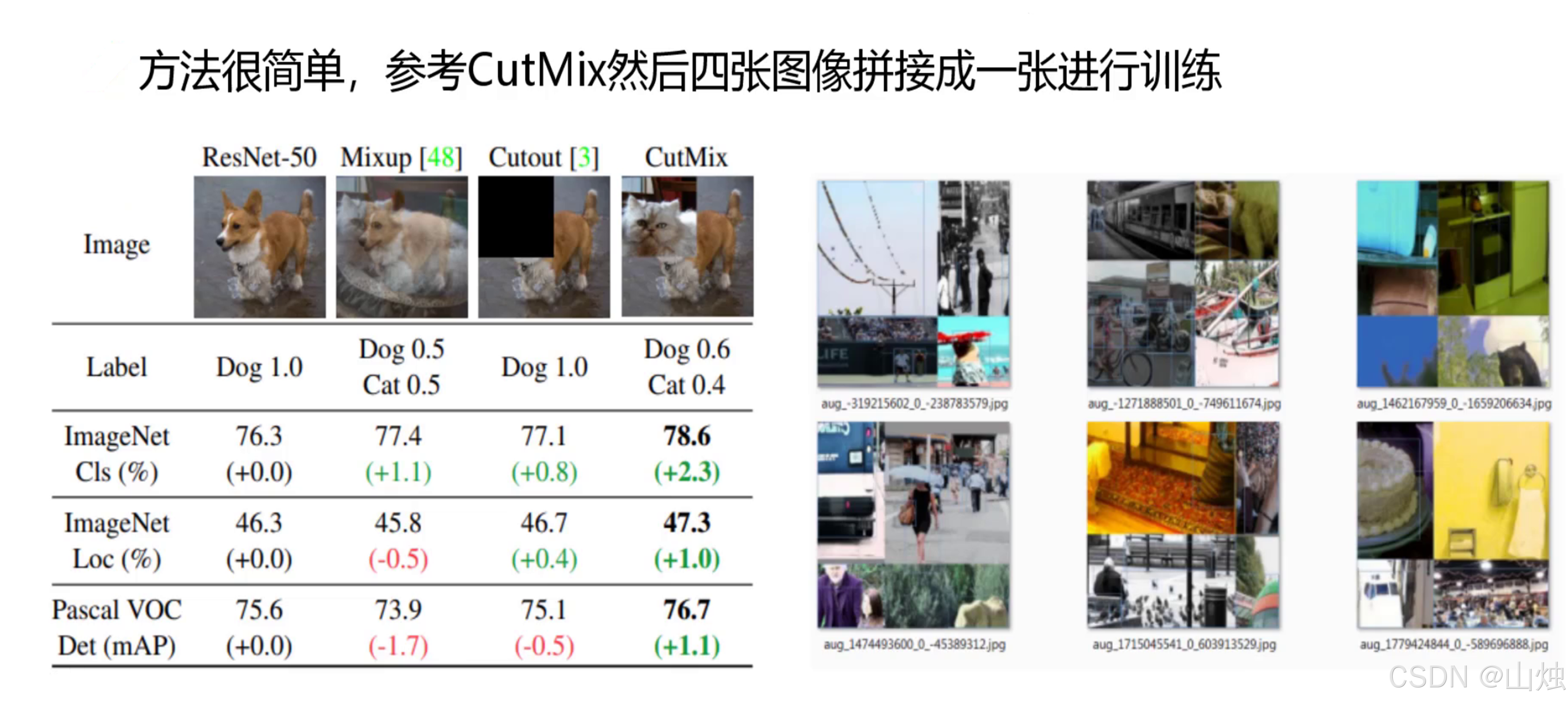
借鉴了 CutMix 的思路,把 4 张不同场景的训练图按随机比例拼合成 1 张新图,同时调整目标标签的位置。这种方式能让模型一次性接触多种场景的目标特征,尤其对小目标检测帮助很大 ------ 比如检测远处的行人时,模型能通过拼接图中不同尺寸的行人样本,学得更全面的特征。实验显示,相比传统增强方法,Mosaic 能让 ImageNet 数据集上的分类精度提升 2.3%,Pascal VOC 数据集的检测精度(mAP)提升 1.1%。
2.1.2 随机擦除与隐藏搜索
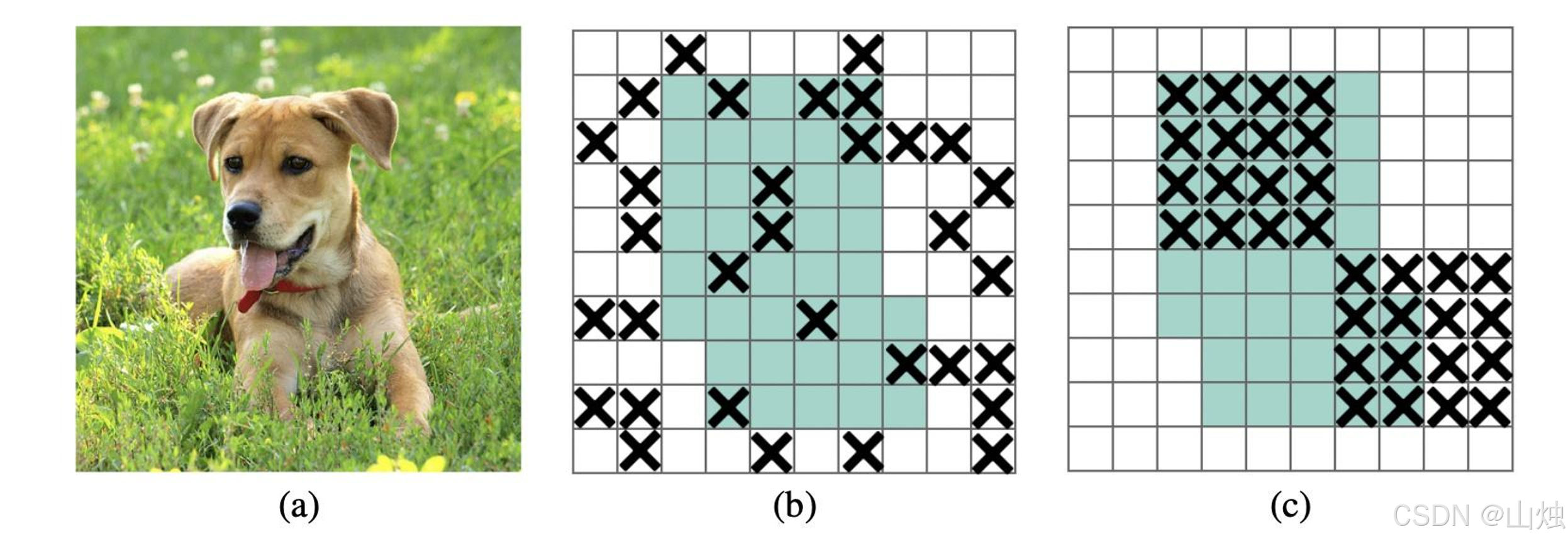
随机擦除:用数据集的平均像素值或随机值替换图像的局部区域,避免模型过度依赖目标的局部细节(比如只认 "车的轮子" 而不认整体),迫使模型关注目标的完整特征;
隐藏搜索:按概率随机遮挡图像中的部分区域,模拟现实中目标被遮挡的情况(比如行人被树木挡住),让模型在遮挡场景下也能准确识别目标。

2.1.3 自对抗训练(SAT)
训练时给输入图像加一点微小噪声,制造出 "对抗样本"------ 比如原本是 "熊猫" 的图,加噪声后让模型暂时误判为 "线虫",再通过调整模型参数,让模型学会应对这种干扰。这样训练出的模型,在真实场景中遇到图像模糊、光线干扰时,检测效果更稳定。

2.1.4 标签平滑与 DropBlock
标签平滑:把传统的 "硬标签"(比如给 "猫" 标 1、"狗" 标 0)改成 "软标签"(比如 "猫" 标 0.95、"狗" 标 0.05),避免模型对单一标签过度 "自信",减少过拟合;
DropBlock:不再像传统方法那样随机删除孤立的特征点,而是删除特征图中的连续区域(比如删掉 "人脸" 特征中的 "眼睛" 区域),迫使模型学习更全面的特征,进一步抑制过拟合。
2.2 损失函数优化
传统的 IOU 损失(通过计算预测框与真实框的重叠面积来衡量误差)有明显缺陷:如果两个框没有重叠,模型就没法通过损失调整参数;而且就算重叠度一样,也区分不了框的位置好坏。
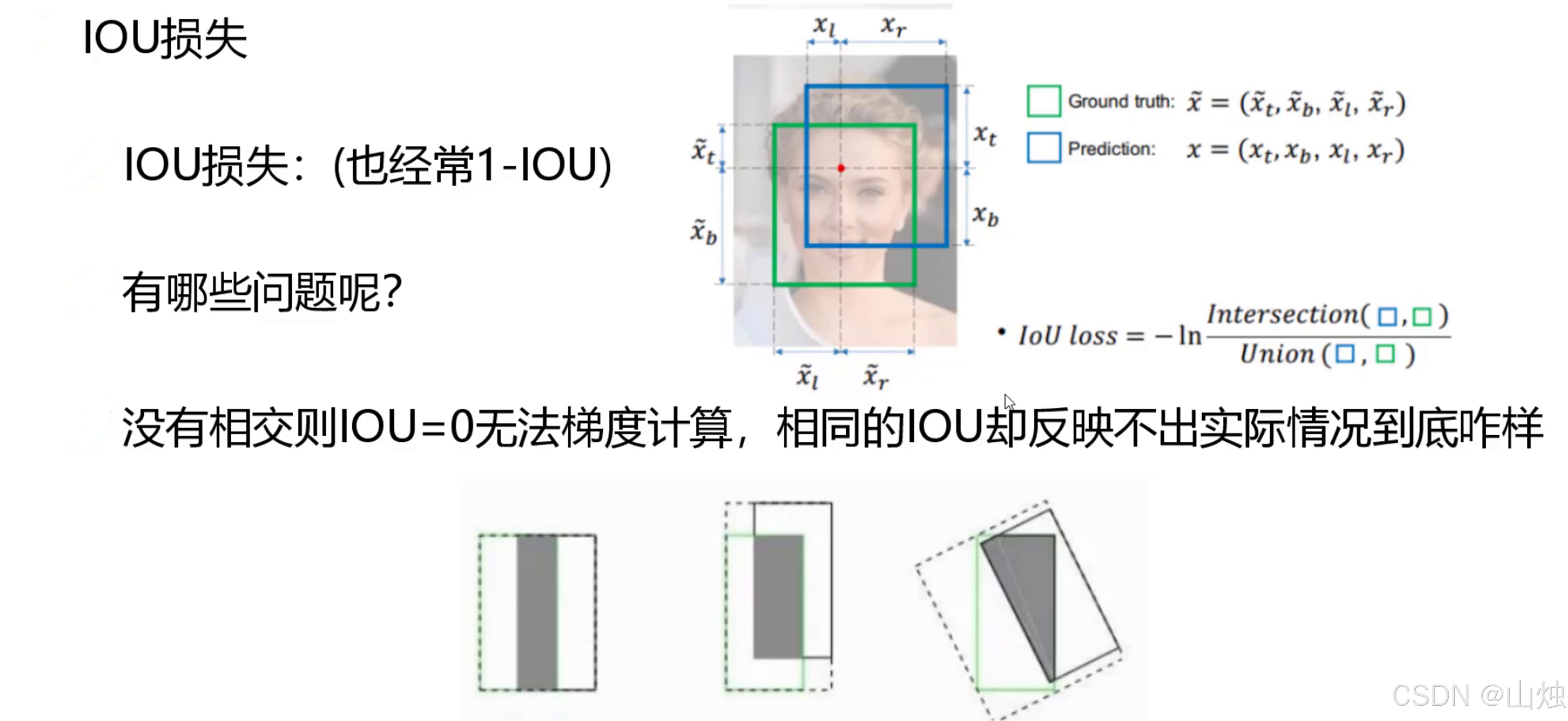
YOLOv4 通过三代损失函数迭代,逐步解决了这些问题:
- GIOU 损失:引入 "最小外接矩形" 的概念 ------ 不仅看两个框的重叠面积,还看它们在最小外接矩形里的位置,就算没有重叠,也能通过外接矩形的面积差计算损失,让模型能继续学习调整。
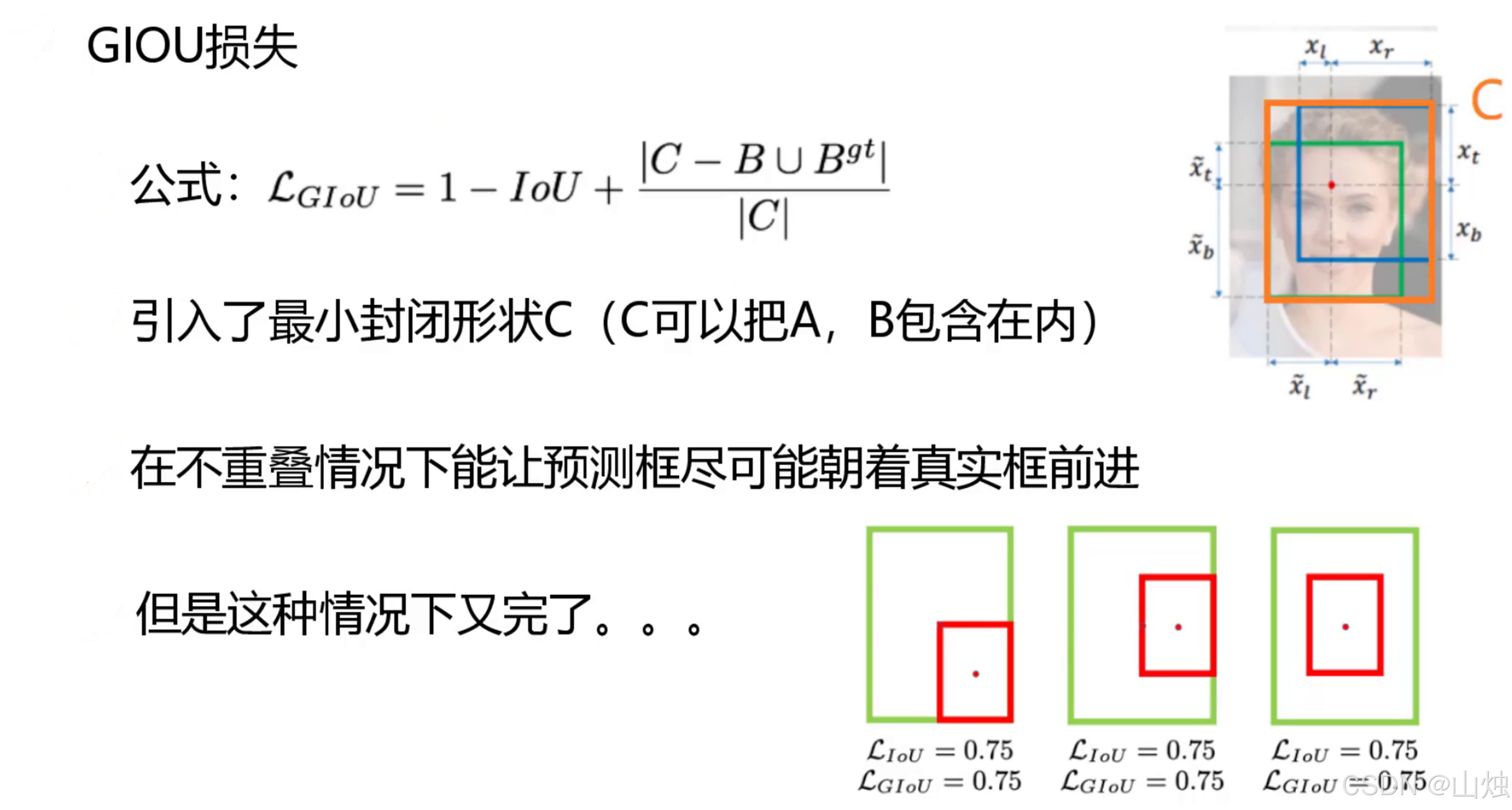
- DIOU 损失:在 GIOU 的基础上,直接优化两个框中心点的距离 ------ 比如预测框离真实框中心点太远,损失就会变大,这样模型能更快把框调整到正确位置,尤其适合处理重叠度高的目标。

- CIOU 损失:最终采用的方案,除了重叠面积、中心点距离,还加入了 "长宽比" 的考量 ------ 比如真实框是 "瘦长的",预测框却是 "矮胖的",损失会相应增加,让模型预测的框形状更贴合真实目标,定位精度大幅提升。

2.3 非极大值抑制(NMS)改进
NMS 是目标检测的 "后处理关键步骤"------ 模型检测时会输出很多重叠的框,NMS 的作用就是过滤掉冗余的框,只保留最准确的。YOLOv4 针对传统 NMS 的缺陷做了两处改进:
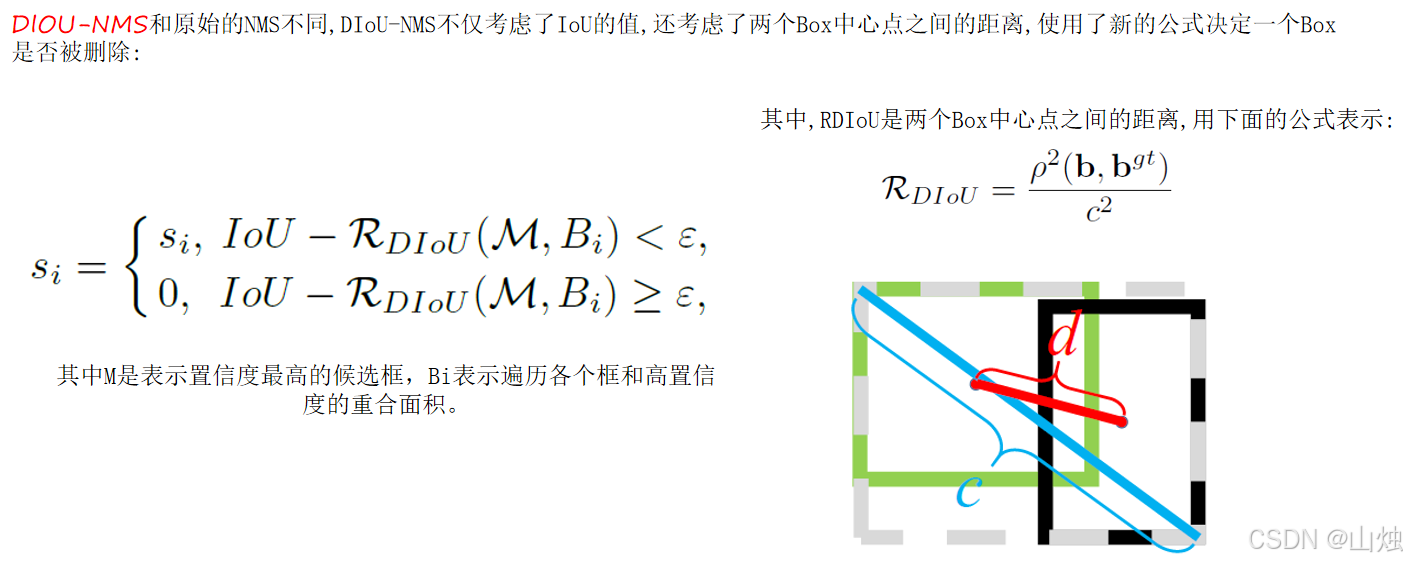
- DIOU-NMS:传统 NMS 只看框的重叠度(IOU),比如两个行人框重叠多,就会删掉分数低的那个,容易漏检。DIOU-NMS 还会看两个框中心点的距离 ------ 如果中心点离得远,就算重叠度高,也不会轻易删除,有效解决了重叠目标漏检的问题。
- Soft-NMS:不再像传统方法那样 "硬删除"------ 比如遇到重叠框,不直接删掉分数低的,而是按重叠度降低它的分数(重叠度越高,分数降得越多),这样既能过滤冗余框,又能保留可能有用的框,提升复杂场景下的检测召回率。

2.4 网络结构升级
YOLOv4 采用 "骨干网络 + Neck 网络" 的架构,融合了多种先进设计,既保证特征提取的完整性,又不拖慢推理速度:
2.4.1 骨干网络:CSPDarknet53
在经典的 Darknet53 基础上,加入了 CSPNet 结构 ------ 把每个残差块的特征图按通道拆成两部分,一部分通过残差网络仔细提取特征,另一部分直接 "跳过" 复杂计算拼到输出端。这样既让模型能学到更丰富的特征,又减少了内存占用和计算量,轻量化的同时保持了性能。
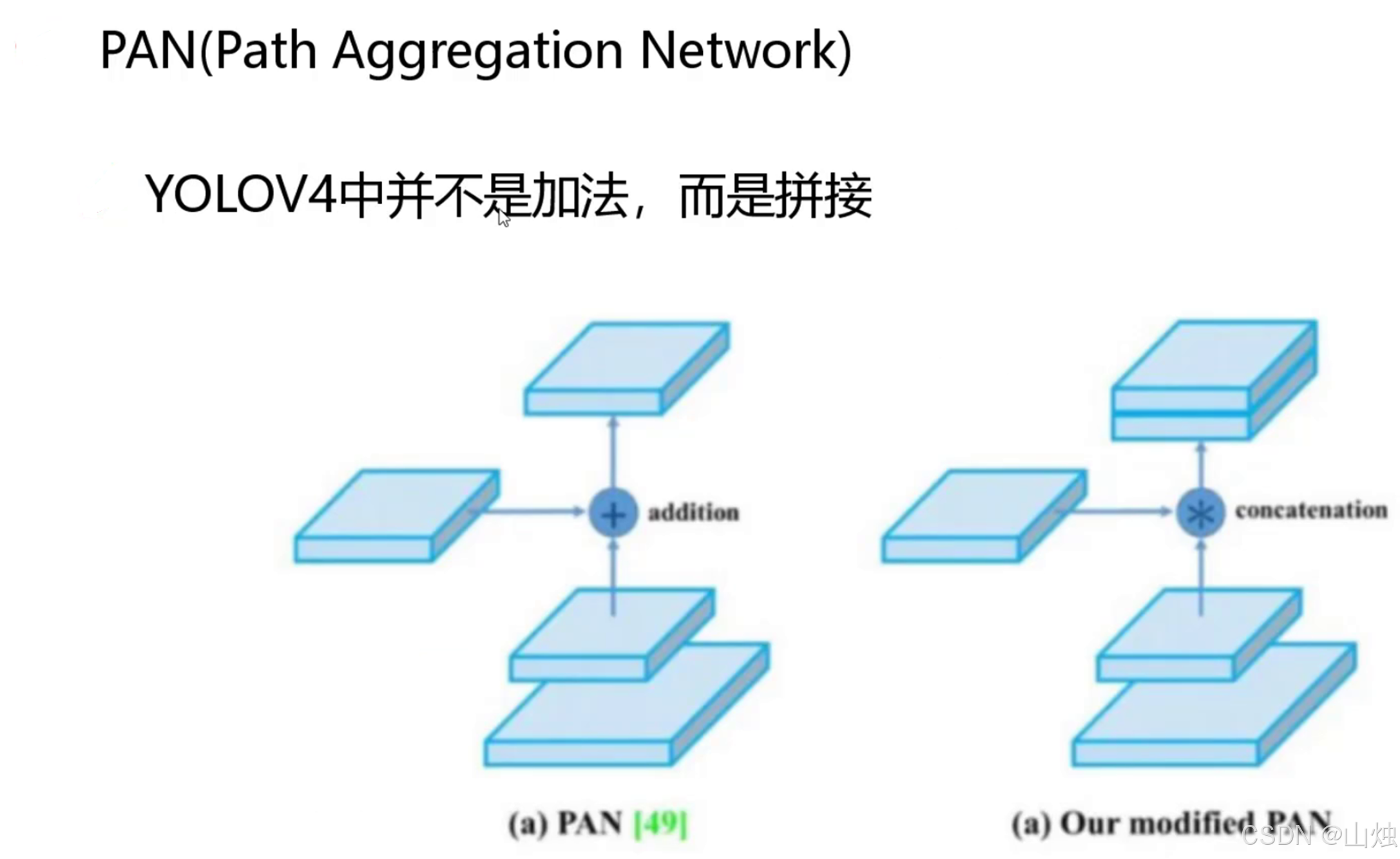
2.4.2 Neck 网络:SPP+PAN
SPP(空间金字塔池化):解决了传统模型对输入图像尺寸敏感的问题 ------ 不管输入图是大是小,SPP 都能通过多尺度池化,把特征转换成固定长度的向量,让模型能适应不同尺寸的目标,尤其对大目标的特征提取更鲁棒。
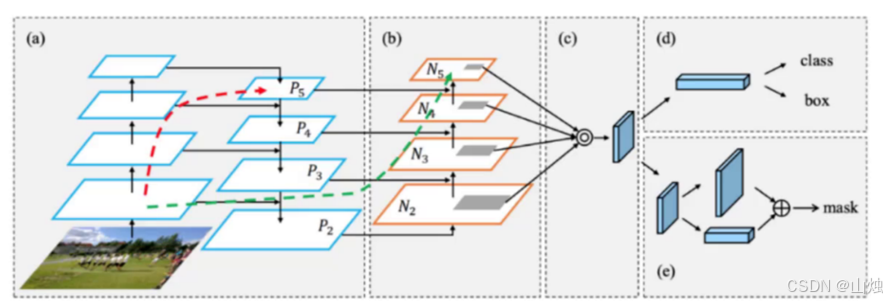
PAN(路径聚合网络):在 FPN(特征金字塔网络)的基础上,加了 "自底向上的路径"------ 比如底层特征(包含小目标的细节信息)能更顺畅地传递到顶层,而且用 "拼接" 代替传统的 "加法" 融合特征,保留更多细节,小目标检测能力显著提升。
2.4.3 注意力机制与激活函数
注意力机制:用 CBAM(卷积块注意力模块)让模型 "聚焦关键区域"------ 比如检测猫时,模型会自动把注意力放在 "猫的头部" 而非背景,在不增加太多计算的前提下提升精度;同时简化了空间注意力模块(SAM),让推理速度更快。
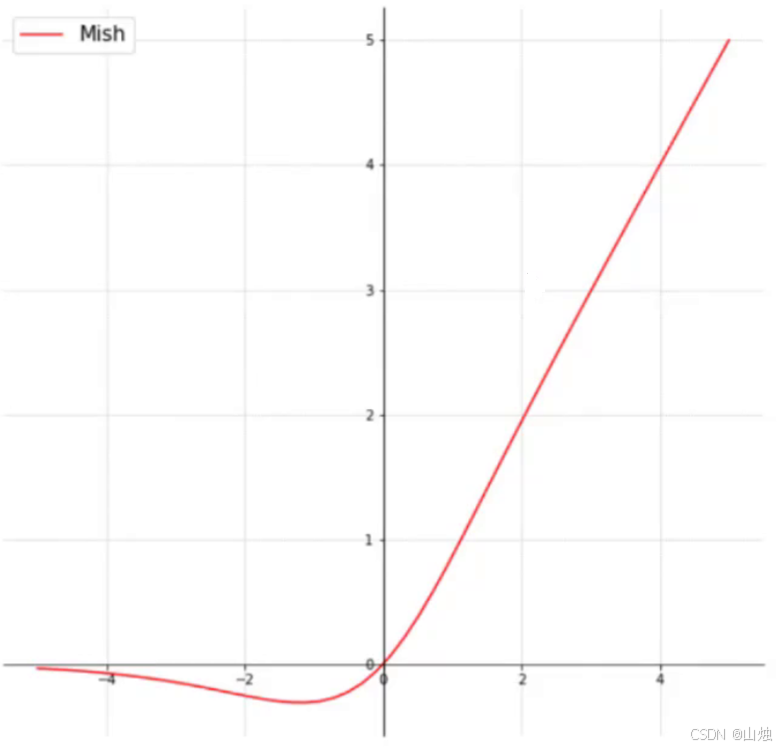
激活函数:用 Mish 替换传统的 ReLU------ReLU 遇到负值会直接输出 0,容易导致 "神经元死亡"(没法再学习),而 Mish 在负值区域仍能输出小数值,能捕捉更细微的特征,虽然计算量略有增加,但检测精度提升明显。
2.4.4 网格敏感性优化
模型预测目标位置时,容易在图像的网格边界处出现偏差 ------ 比如目标中心点刚好在两个网格中间,传统方法很难精准定位。YOLOv4 在激活函数前加了一个大于 1 的系数,缓解了边界区域的定位敏感问题,让预测的框更贴合真实目标。
三、YOLOv4 的性能优势
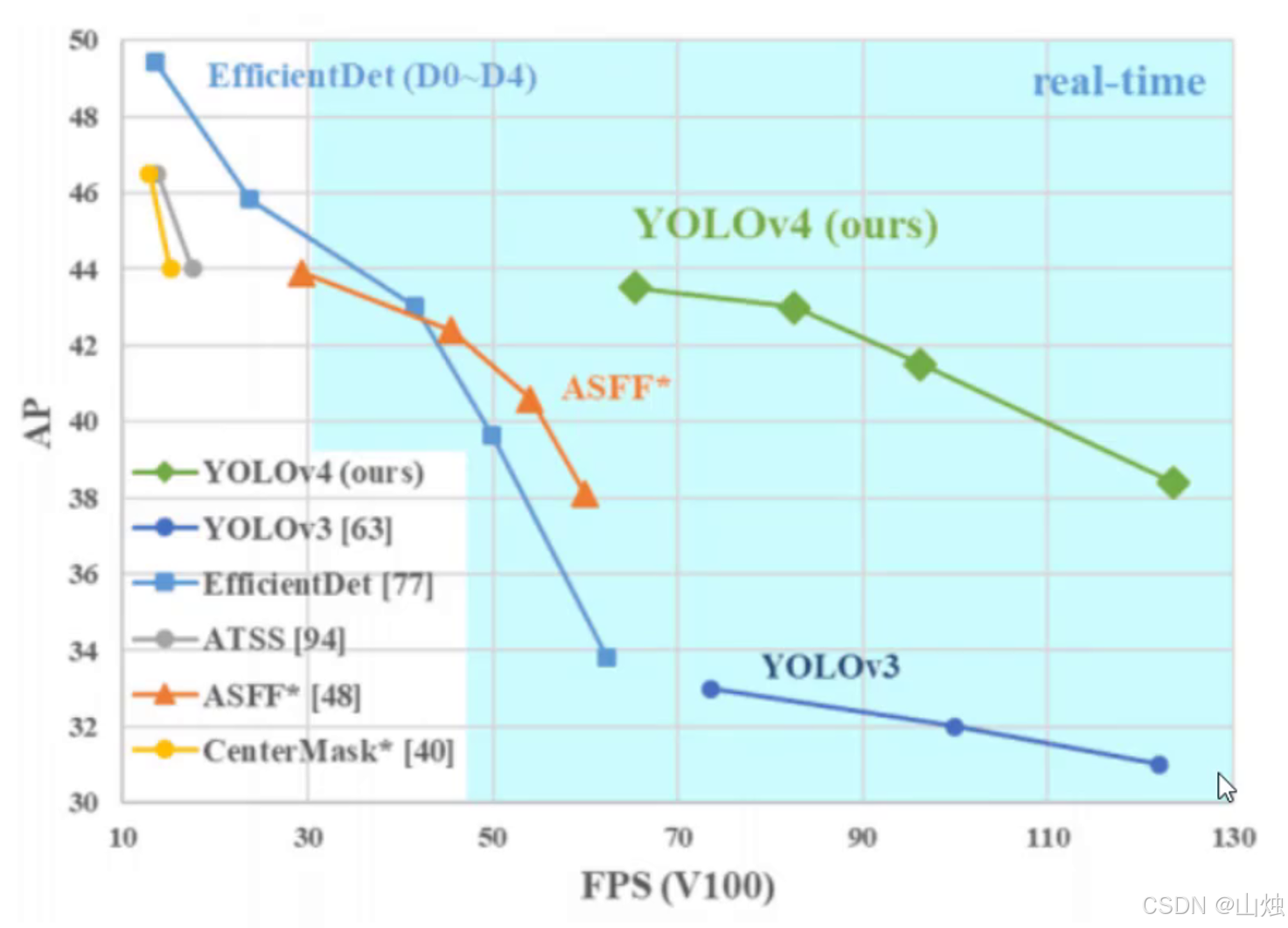
YOLOv4 的核心价值在于 "既快又准",在权威数据集上的表现充分验证了这一点:
- 精度方面:在 COCO 数据集(目标检测领域常用的权威数据集)上,YOLOv4 的 mAP50(即 IOU 阈值设为 0.5 时的平均精度)达到 82.3%,远超前代 YOLOv3 的 65.7%,在小目标、重叠目标的检测上优势尤其明显;
- 速度方面:在 Tesla V100 显卡上,用 608×608 尺寸的图像测试,YOLOv4 每秒能处理 65 张图(FPS=65),完全满足实时检测的需求 ------ 相比两阶段检测算法(比如 Faster R-CNN 每秒只能处理 5 张图),速度优势巨大,能适配对实时性要求高的场景。
四、总结
YOLOv4 并非依赖单一技术的 "单点突破",而是目标检测领域 "技术融合" 的典范 ------ 它把数据增强、损失计算、网络结构等方向的先进设计系统性整合,既解决了前代模型的定位不准、漏检、速度慢等问题,又保持了工业场景需要的实用性,最终实现了检测精度与推理速度的完美平衡。
这种 "模块化整合、按需优化" 的思路,不仅让 YOLOv4 成为当时的经典模型,也为后续目标检测算法的发展提供了重要参考 ------ 后续的 YOLOv5、YOLOv6 等版本,都在 YOLOv4 的技术基础上进一步优化,推动目标检测技术向更高效、更精准的方向发展。