预测好坏的判断标准:
三个公设(对f(X)函数值修饰后进行判断):
- 间隔最大
- 似然值(w变化,不是x)(概率)最大<-->交叉熵最大
- 方差最小
激活函数是为了得出结果,损失函数是为了让结果最佳
机器学习三大要素:
- 模型(隐藏层)
- 策略(公设)(输出层)
- 算法(反向传播,关键为梯度下降法)
ps:梯度下降法的步长(学习率lr)是一个超参数
神经网络:
1. 可看做数据升维
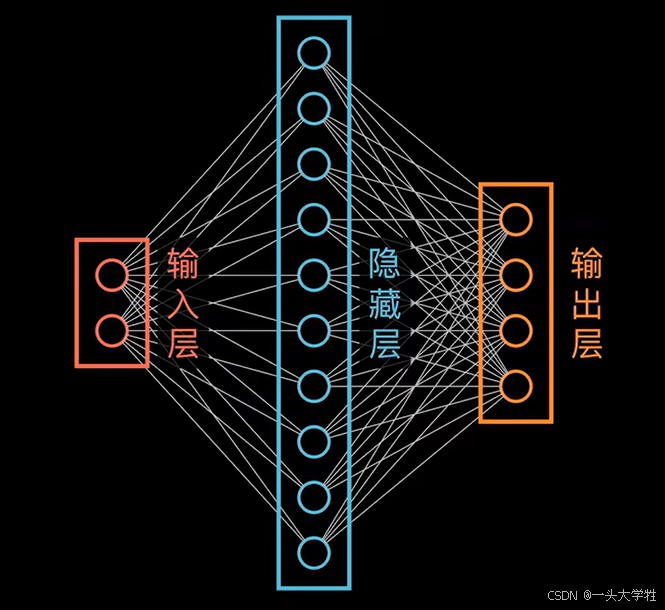
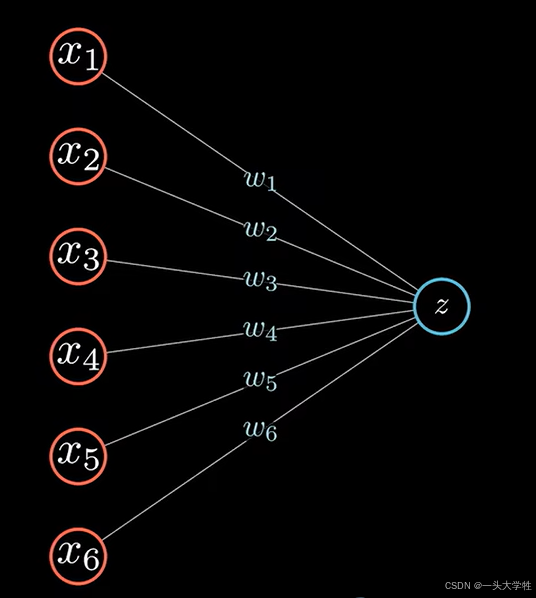
- 输入层(数据处理)数据的维度
一个平面的原因是,没激活函数的情况下,w1x1+w2x2+b=z是个线性函数
分界线:二维平面里的线到n维空间里的超平面
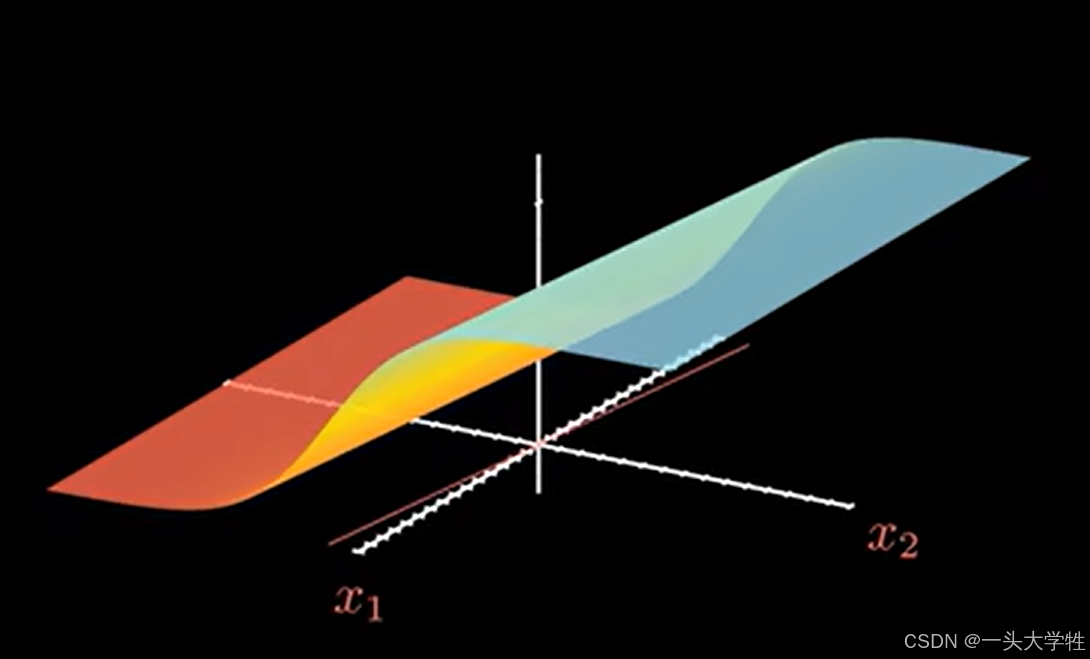
ps:
-
激活函数,非线性
-
权重weight和偏置bias
-
神经网络的复杂性来源于激活函数
- 隐藏层(让模型更复杂)
中间的神经元个数可以对数据进行升维操作,再找到一个超平面对数据进行划分
ps:升维操作,完成维度的映射
- 输出层
神经网络可以有多个输出节点,处理多分类问题
多分类问题,本质上是多个二分类问题,每个节点都在进行二分类判断
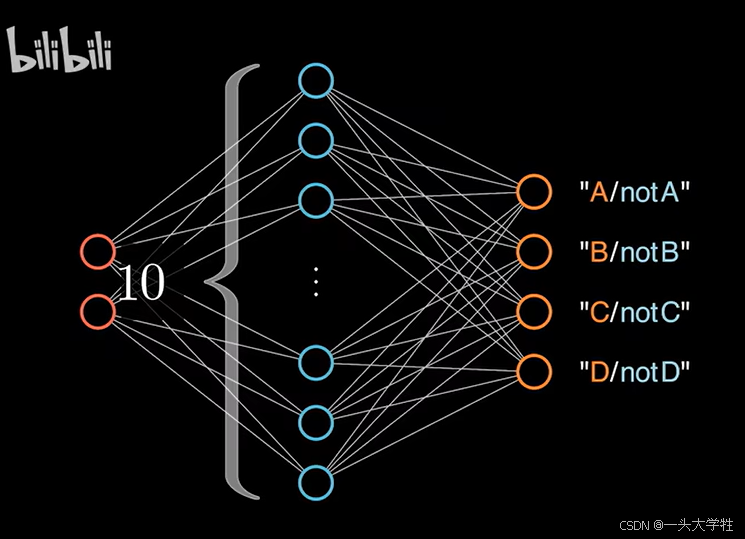
输出结果使用softmax描述,进行归一处理(各分类的概率分布)
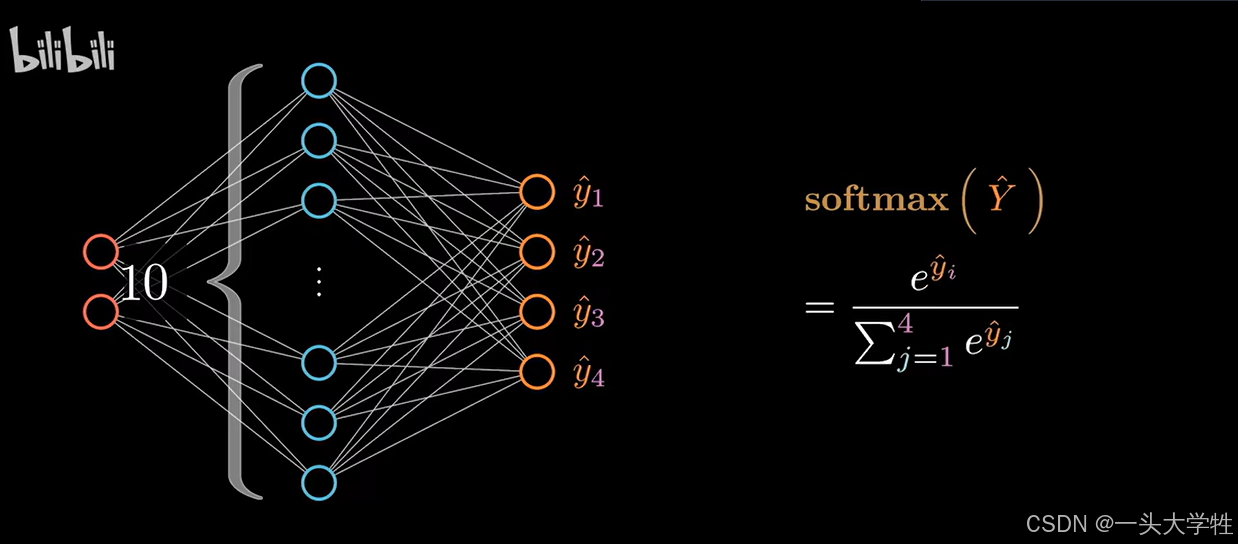
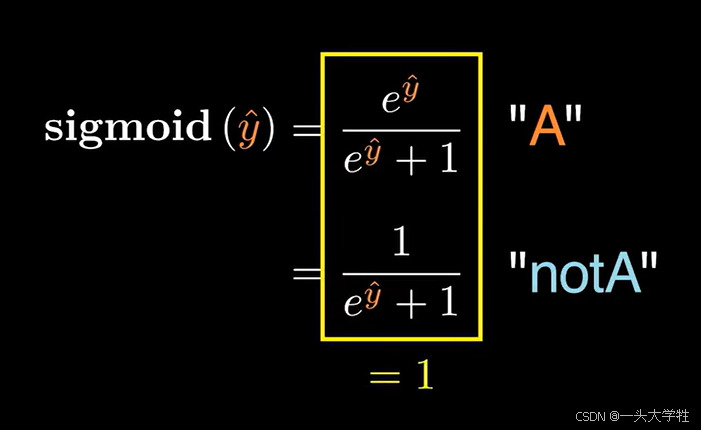
softmax可以看做是sigmoid函数的扩展和升级
分母是所有分类数值的和,分子是各个分类自己的数值,计算出的是各分类的概率(归一)
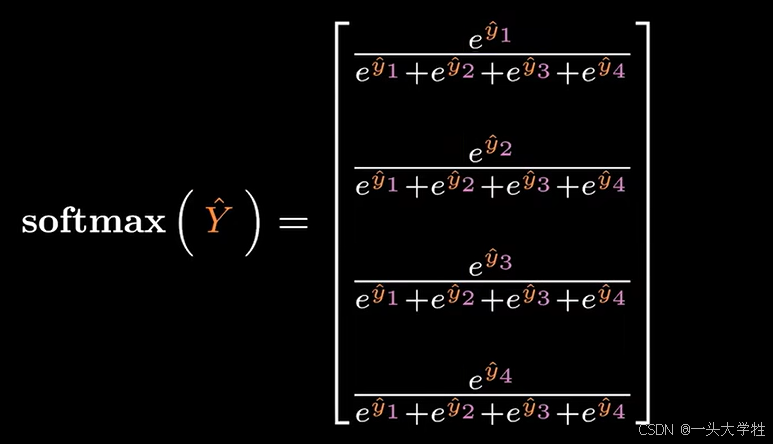
可看做数据降维
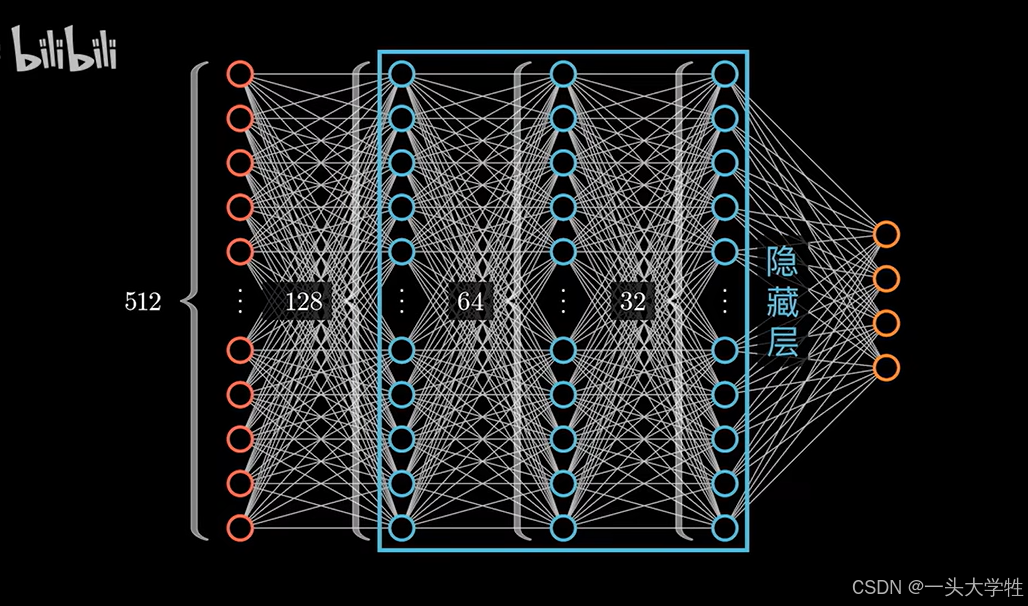
进行数据的降维操作,提取特征,不需要原始数据的所有维度
隐藏层越深,抽象程度越高
王木头up主哔站视频:
梯度消失是由于深层神经网络在链式求导时,连乘项的绝对值小于1导致的(例如使用sigmoid激活函数时,远离原点处的梯度接近于0),不是由于学习率的高次方导致的。
梯度消失是由于深层神经网络在链式求导时,连乘项的绝对值小于1导致的(例如使用sigmoid激活函数时,远离原点处的梯度接近于0),不是由于学习率的高次方导致的。
并且在梯度下降过程中更新梯度时,每一层参数的梯度项乘的是同一个学习率,不存在次方的情况。