kubeadm容器化部署(一) |k8s部署安装1.28版 |本人已部署两次,方案可用 |Kubernetes容器编排
文章目录
- [kubeadm容器化部署(一) |k8s部署安装1.28版 |本人已部署两次,方案可用 |Kubernetes容器编排](#kubeadm容器化部署(一) |k8s部署安装1.28版 |本人已部署两次,方案可用 |Kubernetes容器编排)
- 1、kubernetes组件信息
-
- [1.1 Master节点组件](#1.1 Master节点组件)
- [1.2 Node节点组件](#1.2 Node节点组件)
- 2、安装初始化
-
- [2.1 所有节点中都需要执行(初始化环境)](#2.1 所有节点中都需要执行(初始化环境))
- [2.2 安装cri-dockerd插件及配置(Master01)](#2.2 安装cri-dockerd插件及配置(Master01))
- [2.3 所有master节点安装keepalived及haproxy](#2.3 所有master节点安装keepalived及haproxy)
-
- [2.3.1 所有master节点haproxy配置文件修改](#2.3.1 所有master节点haproxy配置文件修改)
- [2.3.2 所有master节点keepalived配置文件修改](#2.3.2 所有master节点keepalived配置文件修改)
-
- [2.3.2.1 k8s-master01配置文件修改](#2.3.2.1 k8s-master01配置文件修改)
- [2.3.2.2 k8s-master02配置文件修改](#2.3.2.2 k8s-master02配置文件修改)
- [2.3.2.3 k8s-master03配置文件修改](#2.3.2.3 k8s-master03配置文件修改)
- [2.3.2.4 所有master节点配置apiserver健康检查脚本](#2.3.2.4 所有master节点配置apiserver健康检查脚本)
- [2.3.2.5 所有master节点启动keepalived及haproxy](#2.3.2.5 所有master节点启动keepalived及haproxy)
- [2.4 安装kubernetes组件(v1.28 Master and Node)](#2.4 安装kubernetes组件(v1.28 Master and Node))
- [2.5 集群初始化](#2.5 集群初始化)
-
- [2.5.1 初始化yaml文件(Master01)](#2.5.1 初始化yaml文件(Master01))
- [2.6 拉取kubernetes组件镜像](#2.6 拉取kubernetes组件镜像)
- [2.7 Calico网络插件安装(Master01)](#2.7 Calico网络插件安装(Master01))
-
-
- 1.calico起不来解决办法
- [2. **CoreDNS Pod 未就绪**](#2. CoreDNS Pod 未就绪)
-
- [2.8 生成新的token key值(Master01)](#2.8 生成新的token key值(Master01))
- [2.9 Metrics server部署(Master01)](#2.9 Metrics server部署(Master01))
-
- [2.9.1 什么是Metrics server?](#2.9.1 什么是Metrics server?)
- [2.9.2 Metrics server使用场景?](#2.9.2 Metrics server使用场景?)
- [2.10 修改Kube-proxy改为ipvs模式(master01)](#2.10 修改Kube-proxy改为ipvs模式(master01))
- -----未完待续-----
1、kubernetes组件信息
1.1 Master节点组件
- **APIServer **:是整个集群的控制中枢,提供集群中各个模块之间的数据交换,并将集群状态和信息存储到分布式键-值(key-value)存储系统Etcd集群中。同时它也是集群管理、资源配额、提供完备的集群安全机制的入口,为集群各类资源对象提供增删改查以及watch的REST API接口。
- Scheduler - Scheduler:是集群Pod的调度中心,主要是通过调度算法将Pod分配到最佳的Node节点,它通过APIServer监听所有Pod的状态,一旦发现新的未被调度到任何Node节点的Pod( PodSpec.NodeName为空),就会根据一系列策略选择最佳节点进行调度。
- Controller Manager :是集群状态管理器,以保证Pod或其他资源达到期望值。当集群中某个Pod的副本数或其他资源因故障和错误导致无法正常运行,没有达到设定的值时,Controller Manager会尝试自动修复并使其达到期望状态。
- Etcd -Etcd:由Coreos开发,用于可靠地存储集群的配置数据,是一种持久性、轻量型、分布式的键-值(key-value)数据存储组件,作为Kubernetes集群的持久化存储系统。
1.2 Node节点组件
- Kubelet:负责与Master通信协作,管理该节点上的Pod,对容器进行健康检查及监控,同时负责报节点和节点上面Pod的状态。
- Kube-Proxy:负责各Pod之间的通信和负载均衡,将指定的流量分发到后端正确的机器上。Runtime:负责容器的管理。
- CoreDNS:用于Kubernetes集群内部Service的解析,可以让Pod把Service名称解析成Service的IP,然后通过service的IP地址进行连接到对应的应用上。
- Calico:符合CNI标准的一个网络插件,它负责给每个Pod分配一个不会重复的IP,并且把每个节点当做一各"路由器",这样一个节点的Pod就可以通过IP地址访问到其他节点的Pod。
2、安装初始化
⚠️:生产环境当中一般选择3台master。
Master节点和Worker节点的IP地址网段区分开;防止后期由于业务增长,节点资源需要扩充,方便运维管理。
| role | ipaddress | configure |
|---|---|---|
| k8s-lb | 192.168.174.99 | VIP |
| k8s-master01(etcd ) | 192.168.174.30 | 4 core, 4Gb; 50GBS, CentOS 7.9 |
| k8s-master02(etcd ) | 192.168.174.31 | 4 core, 4Gb; 50GBS, CentOS 7.9 |
| k8s-master03(etcd ) | 192.168.174.32 | 4 core, 4Gb; 50GBS, CentOS 7.9 |
| k8s-node01 | 192.168.174.40 | 4 core, 16Gb; 100GBS, CentOS 7.9 |
| k8s-node02 | 192.168.174.41 | 4 core, 16Gb; 100GBS, CentOS 7.9 |
之前的硬件配置如上
目前我重配了一下如下
(其实3核也行但是会偶尔假死我在装图形化时,两种图形化方案(自带+kuboard)都出问题了只能强删k8s资源清单的kaboard,使用纯docker的方式部署)
| role | ipaddress | configure |
|---|---|---|
| k8s-lb | 192.168.28.199 | VIP |
| k8s-master01(etcd ) | 192.168.28.130 | 4 core, 4.7Gb; 30GBS, CentOS 7.9 |
| k8s-master02(etcd ) | 192.168.28.131 | 4 core, 4.7Gb; 30GBS, CentOS 7.9 |
| k8s-master03(etcd ) | 192.168.28.132 | 4 core, 4.7Gb; 30GBS, CentOS 7.9 |
| k8s-node01 | 192.168.28.140 | 4 core, 3.5Gb; 30GBS, CentOS 7.9 |
| k8s-node02 | 192.168.28.141 | 4 core, 3.5Gb; 30GBS, CentOS 7.9 |
之所以是30G的原因是后续使用rook管理ceph+高可用的方式弹性扩容(后续另一个文档如果不做这个建议50G起步)。缺多少就加多少G,其实20G每个就行但是加载会稍微比较慢。
2.1 所有节点中都需要执行(初始化环境)
bash
#>>> 所有节点修改主机名 1
$ hostnamectl set-hostname k8s-master01
$ hostnamectl set-hostname k8s-master02
$ hostnamectl set-hostname k8s-master03
$ hostnamectl set-hostname k8s-node01
$ hostnamectl set-hostname k8s-node02
#>>> 关闭防火墙及安全策略1
$ systemctl disable --now firewalld NetworkManager
$ sed -ri "s/^SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
$ setenforce 0
#>>> 禁用swap分区1
$ swapoff -a && sysctl -w vm.swappiness=0 && sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
#>>> 所有节点修改本地解析 1
$ cat <<-EOF >>/etc/hosts
192.168.174.99 k8s-lb
192.168.174.30 k8s-master01
192.168.174.31 k8s-master02
192.168.174.32 k8s-master03
192.168.174.40 k8s-node01
192.168.174.41 k8s-node02
EOF
我的是 192.168.28.130 1
# 需要注意的是192.168.28.2是我的网关·
192.168.28.199 k8s-lb
192.168.28.130 k8s-master01
192.168.28.131 k8s-master02
192.168.28.132 k8s-master03
192.168.28.140 k8s-node01
192.168.28.141 k8s-node02
#
#>>> 修改YUM源并且安装epel源(中国科技大学或者阿里源) 1
$ rm -rf /etc/yum.repos.d/*
$ curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
$ curl -o /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
#>>> 安装docker-ce源
$ yum install -y yum-utils
$ yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
$ yum makecache fast
#>>> 安装kubernetes的YUM源(阿里云)(v1.23+) 1
$ cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
EOF
#>>> 更新系统内rpm软件包(除内核外) 1
$ yum -y update --exclude=kernel*
#>>> 生成公钥和私钥,传送公钥(k8s-master01操作)
$ ssh-keygen -t rsa
$ for i in k8s-master02 k8s-master03 k8s-node01 k8s-node02;do ssh-copy-id -i .ssh/id_rsa.pub $i;done
#>>> 传输内核包(k8s-master01操作)
$ for i in k8s-master02 k8s-master03 k8s-node01 k8s-node02;do scp kernel-ml-4.19.12-1.el7.elrepo.x86_64.rpm kernel-ml-devel-4.19.12-1.el7.elrepo.x86_64.rpm $i:/root/ ; done
#>>> 升级所有节点的内核(v4.19+),Kubernetes官网推荐内核版本
uname -r 查看内核版本
$ yum -y localinstall kernel-m*
$ grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
$ grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
$ grubby --default-kernel
/boot/vmlinuz-4.19.12-1.el7.elrepo.x86_64
#>>> 安装所需要的服务及依赖(安装Docker是需到github.com/kubernetes中查看当版本适应什么版本的Docker)
$ yum -y install wget jq psmisc vim net-tools telnet yum-utils \
device-mapper-persistent-data lvm2 git ntpdate \
ipvsadm ipset sysstat conntrack libseccomp \
docker-ce-20.10.* docker-ce-cli-20.10.* containerd
#>>> 校准时间修改上海时区并且加到开机自启
$ echo "*/5 * * * * ntpdate -b ntp.aliyun.com" >>/var/spool/cron/root
[root@k8s-master01 ~]# date
2025年 03月 09日 星期日 18:01:13 CST
$ ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
$ echo 'ASia/Shanghai' > /etc/timezone
#>>> 设置最大文件打开数
$ ulimit -SHn 65535
$ cat <<-EOF >>/etc/security/limits.conf
soft nofile 655360
hard nofile 131072
soft nproc 655350
hard nproc 655350
soft memlock unlimited
hard memlock unlimited
EOF
#>>> 生成ipvs内核配置
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
$ cat <<-EOF >>/etc/modules-load.d/ipvs.conf
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_fo
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
#>>> k8s内核配置项
$ cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
net.ipv4.conf.all.route_localnet = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
EOF
$ sysctl --system
#>>> 启动docker
$ systemctl enable --now docker.service
#>>> 设置Docker镜像加速器并且修改systemd作为cgroug的驱动
$ cat <<-EOF >/etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
# 我的配置
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"http://tz.hmdzg.cn",
"https://ukblsmil.mirror.aliyuncs.com",
"https://irq6vzci.mirror.aliyuncs.com",
"http://hub-mirror.c.163.com",
"https://docker.m.daocloud.io",
"https://docker.anyhub.us.kg"
]
}
#>>> 重新加载Docker的配置文件且重启
$ systemctl daemon-reload && systemctl restart docker
#>>> 重启查看调优参数是否加载
$ reboot
$ lsmod | grep --color=auto -e ip_vs -e nf_conntrack2.2 安装cri-dockerd插件及配置(Master01)
bash
#>>>> 下载cri-dockerd驱动(Master01)
$ wget -c https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.14/cri-dockerd-0.3.14.amd64.tgz
#>>> 解压安装包(Master01)
$ tar -xvf cri-dockerd-0.3.14.amd64.tgz --strip-components=1 -C /usr/local/bin/
#>>> 下载cri-docker.service和cri-docker.socket文件(Master01)
# 挂梯子手动下载文件到本地在使用xftp传入服务器。
$ wget -O cri-docker.service https://github.com/Mirantis/cri-dockerd/blob/master/packaging/systemd/cri-docker.service
$ wget -O cri-docker.socket https://github.com/Mirantis/cri-dockerd/blob/master/packaging/systemd/cri-docker.socket
#>>> 拷贝文件至指定目录(Master01)
$ mv cri-docker.service /etc/systemd/system/cri-docker.service
$ mv cri-docker.socket /etc/systemd/system/cri-docker.socket
#>>> 修改cri-docker.service和cri-docker.socket文件(Master01)
$ vim /etc/systemd/system/cri-docker.service
ExecStart=/usr/local/bin/cri-dockerd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --cri-dockerd-root-directory=/var/lib/dockershim --cri-dockerd-root-directory=/var/lib/docker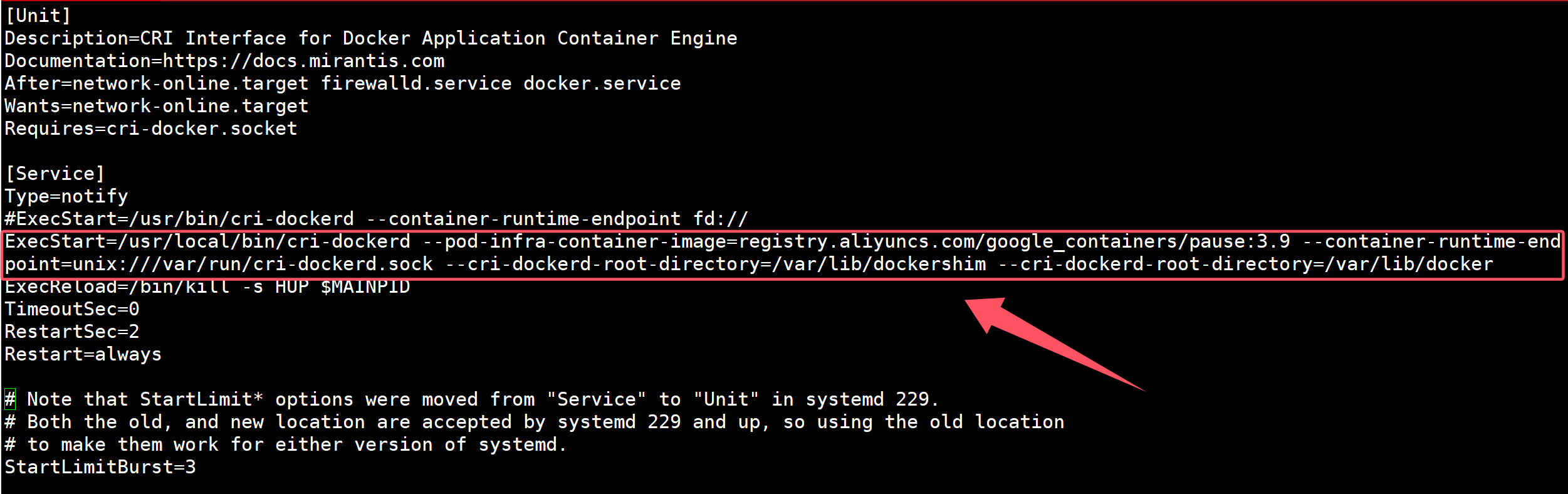
bash
$ vim /etc/systemd/system/cri-docker.socket
ListenStream=/var/run/cri-dockerd.sock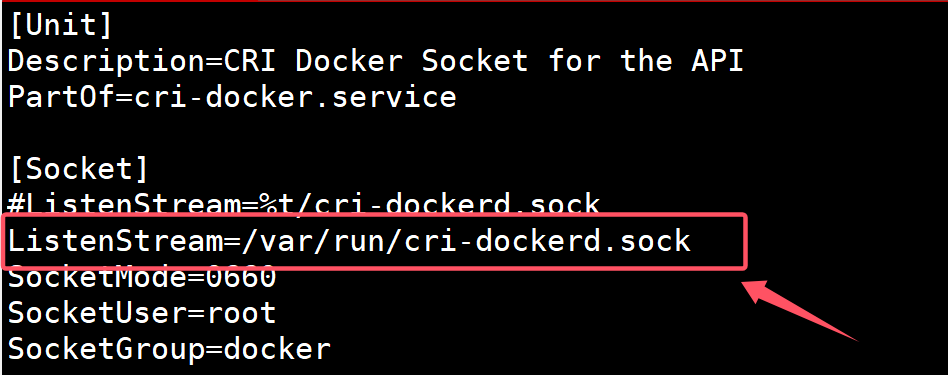
bash
#>>> 将 cri-dockerd-0.3.14.amd64.tgz 拷贝至其他全部节点(Master01)
$ Nodes='k8s-master02 k8s-master03 k8s-node01 k8s-node02'
$ for NODE in $Nodes; do echo $NODE; scp cri-dockerd-0.3.14.amd64.tgz $NODE:~; done
#>>> 其他所有的节点将 cri-dockerd-0.3.14.amd64.tgz 解压到指定目录(Master01)
$ tar -xvf cri-dockerd-0.3.14.amd64.tgz --strip-components=1 -C /usr/local/bin/
#>>> 将 cri-docker.service 和 cri-docker.socket 文件拷贝至其他所有主机(Master01)
$ for NODE in $Nodes; do echo $NODE; scp /etc/systemd/system/cri-docker.service $NODE:/etc/systemd/system/; scp /etc/systemd/system/cri-docker.socket $NODE:/etc/systemd/system; done
#>>> 所有节点启动cri-dockerd
$ systemctl daemon-reload
$ systemctl enable --now cri-docker.service
$ systemctl status cri-docker.service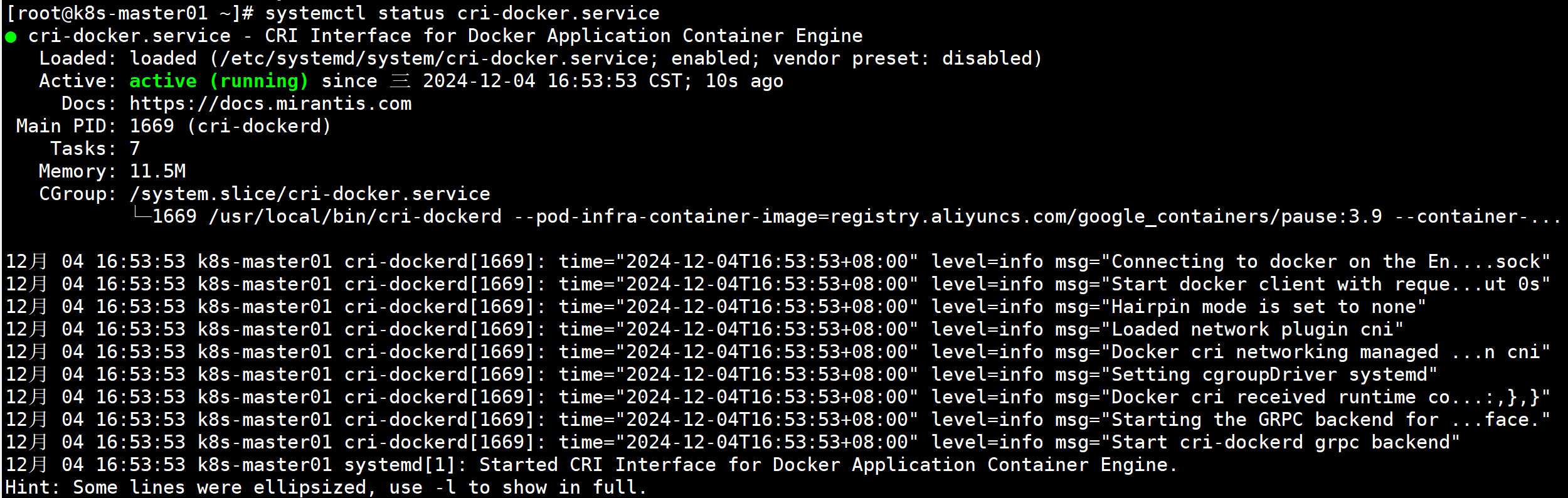
2.3 所有master节点安装keepalived及haproxy
bash
$ yum install -y keepalived haproxy注意:进行下面2.3.2配置时,
bash
$问题$1:`state` 和 `priority` 的配置
- 第一个配置是 `state MASTER`,优先级为 `101`。
- 第二个和第三个配置是 `state BACKUP`,优先级为 `100`。
这种配置是典型的主备模式,`MASTER` 的优先级高于 `BACKUP`,因此 `MASTER` 会抢占 VIP。这是正确的配置方式。
$问题 $2:`mcast_src_ip` 的配置
- 第一个配置的 `mcast_src_ip` 是 `192.168.28.130`。
- 第二个和第三个配置的 `mcast_src_ip` 是 `192.168.28.131`。
`mcast_src_ip` 是用于发送 VRRP 广播的源 IP 地址。确保这些 IP 地址是节点的实际 IP 地址,并且在同一个网络中。如果 `192.168.28.130` 和 `192.168.28.131` 是不同的节点,那么这种配置没有问题。
问题 $3:`virtual_ipaddress` 的配置
所有配置都使用了同一个虚拟 IP 地址 `192.168.28.199`。这是正确的,因为 VIP 是共享的,用于高可用性。
问题 $4:`check_apiserver.sh` 脚本
确保 `/etc/keepalived/check_apiserver.sh` 脚本存在且具有可执行权限。如果脚本不存在或不可执行,Keepalived 会报错。
问题 $5:`interface` 的配置
所有配置都使用了 `interface ens32`。确保这个网卡接口在所有节点上都存在,并且是正确的网络接口。
问题 $6:`authentication` 的配置
所有配置都使用了相同的认证方式和密码:
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
# 总结
确保 /etc/keepalived/check_apiserver.sh 脚本存在且可执行。
确保 mcast_src_ip 和 interface 的配置与实际节点的网络配置一致。
确保所有节点的认证信息一致。
确保 VIP 192.168.28.199 没有被其他服务占用2.3.1 所有master节点haproxy配置文件修改
bash
$ mv /etc/haproxy/haproxy.cfg haproxy.cfg.bak
$ vim /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server k8s-master01 192.168.28.130:6443 check
server k8s-master02 192.168.28.131:6443 check
server k8s-master03 192.168.28.132:6443 check2.3.2 所有master节点keepalived配置文件修改
2.3.2.1 k8s-master01配置文件修改
bash
$ mv /etc/keepalived/keepalived.conf keepalived.conf.bak
$ vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface ens32
mcast_src_ip 192.168.28.130
virtual_router_id 51
priority 101
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.28.199
}
track_script {
chk_apiserver
}
}2.3.2.2 k8s-master02配置文件修改
bash
$ vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens32
mcast_src_ip 192.168.28.131
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.28.199
}
track_script {
chk_apiserver
}
}2.3.2.3 k8s-master03配置文件修改
bash
$ vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP
interface ens32
mcast_src_ip 192.168.28.132
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.28.199
}
track_script {
chk_apiserver
}
}2.3.2.4 所有master节点配置apiserver健康检查脚本
bash
$ vim /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
$ chmod +x /etc/keepalived/check_apiserver.sh2.3.2.5 所有master节点启动keepalived及haproxy
bash
$ systemctl daemon-reload
$ systemctl enable --now keepalived haproxy
$ ping 192.168.28.199
PING 192.168.28.199 (192.168.28.199) 56(84) bytes of data.
64 bytes from 192.168.28.199: icmp_seq=1 ttl=64 time=0.031 ms
64 bytes from 192.168.28.199: icmp_seq=2 ttl=64 time=0.065 ms
64 bytes from 192.168.28.199: icmp_seq=3 ttl=64 time=0.073 ms
64 bytes from 192.168.28.199: icmp_seq=4 ttl=64 time=0.067 ms
$ telnet 192.168.28.199 16443
Trying 192.168.28.199...
Connected to 192.168.28.199.
Escape character is '^]'.
Connection closed by foreign host.
# ==
$从node-01开始依次挂起所有节点集群做$镜像$备份,因为下面容易出错,有了这个,可以回滚到目前状态,减少配置所浪费时间2.4 安装kubernetes组件(v1.28 Master and Node)
bash
#>>> Master节点执行
$ yum install kubeadm-1.28* kubelet-1.28* kubectl-1.28* -y
#>>> Node节点执行
$ yum install kubeadm-1.28* kubelet-1.28* -y
#>>> 查看kubeadm版本(Master01)
$ kubeadm version
#>>> 将所有kubelet配置成systemd作为cgroug驱动,保持系统稳定。(Docker亦是如此)
$ cat <<-EOF >/etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
EOF
#>>> 启动kubelet
$ systemctl daemon-reload && systemctl enable --now kubelet⚠️#为什么将kubelet配置成systemd作为cgroug驱动?
Kubernetes默认设置cgroup驱动(cgroupdriver) 为"systemd",而Docker服务的cgroup驱动默认值为"cgroupfs",建议将其修改为"systemd",与Kubernetes保持一致。
2.5 集群初始化
2.5.1 初始化yaml文件(Master01)
kubeadm的初始化控制平面(init)命令和加入节点(join)命令均可以通过指定的配置文件修改默认参数的值。kubeadm将配置文件以 ConfigMap形式保存到集群中,便于后续的查询和升级工作。
kubeadm config子命令提供了对这组功能的支持。
- kubeadm config print init-defaults:输出kubeadm init命令默认参数的内容。
- kubeadm config print join-defaults:输出kubeadm join命令默认参数的内容。
- kubeadm config migrate:在新旧版本之间进行配置转换。
- kubeadm config images list:列出所需的镜像列表。
- kubeadm config images pull:拉取镜像到本地。
bash
[root@k8s-master01 ~]# vim /root/kubeadm-config.yaml
---
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 7t2weq.bjbawausm0jaxury
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.28.130
bindPort: 6443 #本来两个端口应该都是16443,但是负载均衡+高可用占用了,这里用6443进行端口转发。
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
---
apiServer:
certSANs:
- 192.168.28.199
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.28.199:16443
controllerManager: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.28.15
networking:
dnsDomain: cluster.local
podSubnet: 172.16.0.0/16
serviceSubnet: 10.96.0.0/16
scheduler: {}
⚠️:配置文件参数需要修改,修改前备份,或者直接用命令行直接生成新的配置文件,但是仍需要修改配置文件中的参数
⚠️配置文件需改参数
advertiseAddress: 192.168.174.30 # Master01 的ip地址
name: k8s-master01 # Master01 的主机名
- 192.168.174.99 # VIP ip地址
controlPlaneEndpoint: 192.168.174.99:16443 # VIP ip地址:端口
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #镜像仓库地址(阿里)
kubernetesVersion: v1.28.15 # kubernetes的版本号
podSubnet: 172.16.0.0/16 # Pod 的网段地址
serviceSubnet: 10.96.0.0/16 # service 的网段地址
172.16.0.0/16 要确定
该网段未被其他服务或设备占用。
配置正确的路由规则以支持跨网络通信。
Kubernetes 和 CNI 插件的配置一致。
之后就可以用了
#>>> 更新的初始化文件(Master01)
$ kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml
#>>> 将new.yaml 拷贝至其他master节点(Master01)
$ for i in k8s-master02 k8s-master03; do scp new.yaml $i:/root/; done
以下时对yaml文件的讨论:
问题 1:advertiseAddress 和 controlPlaneEndpoint 的端口不一致
localAPIEndpoint.advertiseAddress 是 192.168.28.130,端口是 6443。
controlPlaneEndpoint 是 192.168.28.199:16443,端口是 16443。
建议:确保 controlPlaneEndpoint 的端口与 localAPIEndpoint.bindPort 一致,即改为 192.168.28.199:6443。否则可能会导致集群初始化时出现端口冲突或连接问题。
问题 2:criSocket 的路径
criSocket 配置为 unix:///var/run/cri-dockerd.sock。
建议:确保 cri-dockerd 已正确安装并运行,且该 Socket 文件存在。如果使用的是默认的 Docker CRI,路径应该是 unix:///var/run/docker.sock。如果你确实使用了 cri-dockerd,则需要确保它已正确安装并启动。
第二部分:
问题 3:controlPlaneEndpoint 的端口
controlPlaneEndpoint 配置为 192.168.28.199:16443,端口是 16443。
建议:如前面提到的,端口应与 localAPIEndpoint.bindPort 一致,改为 192.168.28.199:6443。
问题 4:certSANs 配置
certSANs 中只包含了一个 IP 地址 192.168.28.199。
建议:如果集群需要通过域名或其他 IP 地址访问,建议将这些地址也加入到 certSANs 中。例如:
certSANs:
- 192.168.28.199
- k8s-master.example.com
问题 5:podSubnet 和 serviceSubnet 的配置
$ 将 Kubernetes 的 podSubnet 设置为 172.17.0.0/16,但你的 Docker 默认网段也是 172.17.0.0/16,这会导致冲突
podSubnet 配置为 172.17.0.0/16。
serviceSubnet 配置为 10.96.0.0/16。
建议:
确保这两个网段不与其他网络冲突,例如宿主机的网络、其他服务的网络等。
如果你计划使用 CNI 插件(如 Calico、Flannel 等),需要确保 podSubnet 与 CNI 插件的配置一致。例如,Flannel 默认使用 10.244.0.0/16,而 Calico 默认使用 192.168.0.0/16。
如果已经确定 podSubnet 和 serviceSubnet,则无需修改。否则,可以根据你的网络规划调整。
$举例:
inet 192.168.28.131/24 brd 192.168.28.255 scope global ens33
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
我的目前网段,而且我计划使用calico
ens33 是我的主要网络接口,IP 地址为 192.168.28.131/24,网关是 192.168.28.2
docker0 是 Docker 自动创建的虚拟网络接口,使用了 172.17.0.0/16 网段。
计划使用 Calico 作为 CNI 插件,Calico 默认使用 192.168.0.0/16 网段。但这个网段可能会与宿主机网络(192.168.28.0/24)冲突。为了避免冲突,我直接重新规划 Pod 网络
选择一个与宿主机网络、服务网络(serviceSubnet)和其他已用网段不冲突的网段。
例如:
Pod 网段:10.244.0.0/16(这是 Flannel 默认使用的网段,也可以用于 Calico)。
服务网段:10.96.0.0/16(保持不变)。
末位配置改为:
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 # 修改为新的 Pod 网段
serviceSubnet: 10.96.0.0/16
然后安装并 自定义 Calico 的配置,下载 calico.yaml 文件并修改其中的网段配置:
wget https://docs.projectcalico.org/manifests/calico.yaml
在 calico.yaml 文件中,找到 CALICO_IPV4POOL_CIDR 的配置,确保它与 podSubnet 一致: 我的是172.16.0.0/16 查询发现也是172.16.0.0/16 /root/kubernetes_install/calico/calico.yaml
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
kubectl apply -f calico.yaml
安装完成后,验证 Pod 网络是否正常工作:
kubectl get pods -n kube-system
在 Kubernetes 集群中,controlPlaneEndpoint 和 localAPIEndpoint.bindPort 的配置非常重要,它们分别代表了集群的控制平面入口和本地 API 服务器的绑定端口。确保这两个端口一致(或正确配置)的原因主要有以下几点:
1. 集群通信的正确性
controlPlaneEndpoint 是集群中所有节点(包括工作节点和控制平面节点)用来访问 Kubernetes API Server 的统一入口地址。它通常是一个负载均衡的虚拟 IP(如 Keepalived 提供的 VIP)。
localAPIEndpoint.bindPort 是控制平面节点上本地 API Server 绑定的端口,用于节点内部通信。
如果这两个端口不一致,会导致集群内部通信混乱,节点无法正确访问 API Server,进而影响集群的正常运行。
2. 负载均衡和高可用性
在高可用集群中,controlPlaneEndpoint 通常指向一个负载均衡器(如 HAProxy 或 Keepalived)的虚拟 IP。这个 IP 和端口会被集群中的所有节点用来访问 API Server。
如果 controlPlaneEndpoint 的端口与 localAPIEndpoint.bindPort 不一致,负载均衡器可能无法正确转发请求到后端的 API Server,导致连接失败。
3. 证书和安全配置
Kubernetes 使用 TLS 证书来保护 API Server 的通信。证书中通常会包含 controlPlaneEndpoint 的 IP 和端口信息。
如果端口不一致,证书验证可能会失败,因为证书中的 SAN(Subject Alternative Name)字段会与实际访问的端口不匹配。
4. 客户端访问
客户端(如 kubectl)通过 controlPlaneEndpoint 来访问集群。如果端口不一致,客户端无法正确连接到 API Server,导致命令执行失败。2.6 拉取kubernetes组件镜像
bash
#>>> 拉取初始化所需要的镜像文件(根据当前配置文件拉去所需要的配置文件)(Master01)
$ kubeadm config images pull --config new.yaml
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.28.15
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.28.15
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.28.15
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.28.15
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.15-0
[config/images] Pulled registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.10.1
#>>> 初始化集群(生成安全证书并且生成node节点加入集群中的哈希码)(Master01)
$ kubeadm init --config new.yaml --upload-certs
W1204 17:37:58.055549 16185 endpoint.go:57] [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.174.99:16443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:b4c1d15a47bfe254eb95b161cb5f59243df6e859c5d5a6aafd9d47691cd1d748 \
--control-plane --certificate-key 5076b518ae709ccfd8f6a397947557e481e4f93f429237b2bf7d414429b51257
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.174.99:16443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:b4c1d15a47bfe254eb95b161cb5f59243df6e859c5d5a6aafd9d47691cd1d748
#>>> 如果初始化失败,重置后再次初始化,命令如下(没有失败不要执行)
$ kubeadm reset -f ; ipvsadm --clear ; rm -rf ~/.kube
#>>> 另外两个 master 节点执行注意:sha256:b4那个密钥是刚刚初始化产生的每个人的都不一致,用你自己的。 You can now join any number 那个
$ kubeadm join 192.168.28.199:16443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:b4c1d15a47bfe254eb95b161cb5f59243df6e859c5d5a6aafd9d47691cd1d748 \
--control-plane --certificate-key 5076b518ae709ccfd8f6a397947557e481e4f93f429237b2bf7d414429b51257 --cri-socket=unix:///var/run/cri-dockerd.sock
#>>> 所有Node节点执行
$ kubeadm join 192.168.174.99:16443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:b4c1d15a47bfe254eb95b161cb5f59243df6e859c5d5a6aafd9d47691cd1d748 --cri-socket=unix:///var/run/cri-dockerd.sock
#>>> k8s-master01执行
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
#>>> Master01执行查看node状态(Master01)
$ kubectl get nodeskubeadm init命令在执行具体的安装操作之前,会执行一系列被称 为pre-flight checks的系统预检查,以确保主机环境符合安装要求,如果检查失败就直接终止,不再进行init操作。
2.7 Calico网络插件安装(Master01)
Calico网站:https://projectcalico.docs.tigera.io
⚠️ :注意kubernetes和calico之间的版本关联;详细信息去官网查看
bash
$ cd /root/ && git clone https://gitee.com/BRWYZ/kubernetes_install.git
$ cd /root/kubernetes_install && git checkout v1.28+ && cd calico/
#>>> 修改calico配置文件中Pod的网段
$ POD_SUBNET=`cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr= | awk -F= '{print $NF}'`
$ sed -i "s#POD_CIDR#${POD_SUBNET}#g" calico.yaml
#>>> 创建calico容器
$ kubectl apply -f calico.yaml
#>>> 查看Pod的信息
$ kubectl get po -n kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-79fd456594-f4ztd 1/1 Running 0 5m26s
kube-system calico-node-6w255 1/1 Running 0 5m26s
kube-system calico-node-c9zqq 1/1 Running 0 5m26s
kube-system calico-node-h4cbw 1/1 Running 0 5m26s
kube-system calico-node-hlv7f 1/1 Running 0 5m26s
kube-system calico-node-j54n7 1/1 Running 0 5m26s
kube-system coredns-6554b8b87f-4ljn8 1/1 Running 0 10m
kube-system coredns-6554b8b87f-wt8zf 1/1 Running 0 10m
kube-system etcd-k8s-master01 1/1 Running 0 10m
kube-system etcd-k8s-master02 1/1 Running 0 8m17s
kube-system etcd-k8s-master03 1/1 Running 0 8m
kube-system kube-apiserver-k8s-master01 1/1 Running 0 10m
kube-system kube-apiserver-k8s-master02 1/1 Running 0 8m17s
kube-system kube-apiserver-k8s-master03 1/1 Running 0 8m
kube-system kube-controller-manager-k8s-master01 1/1 Running 0 10m
kube-system kube-controller-manager-k8s-master02 1/1 Running 0 8m11s
kube-system kube-controller-manager-k8s-master03 1/1 Running 0 8m
kube-system kube-proxy-2b4mv 1/1 Running 0 2m54s
kube-system kube-proxy-7jczf 1/1 Running 0 3m
kube-system kube-proxy-bklvb 1/1 Running 0 2m56s
kube-system kube-proxy-q7qrj 1/1 Running 0 2m59s
kube-system kube-proxy-r9x2p 1/1 Running 0 2m57s
kube-system kube-scheduler-k8s-master01 1/1 Running 0 10m
kube-system kube-scheduler-k8s-master02 1/1 Running 0 8m17s
kube-system kube-scheduler-k8s-master03 1/1 Running 0 8m1.calico起不来解决办法
[root@k8s-master01 calico]# kubectl get po -n kube-system
NAME READY STATUS RESTRTS AGE
calico-kube-controllers-79fd456594-bx826 0/1 ContainerCreating 0 44s
calico-node-55cl2 0/1 Init:2/3 0 44s
calico-node-d824g 0/1 Init:2/3 0 44s
calico-node-fd2n6 0/1 Init:2/3 0 44s
calico-node-xr9h2 0/1 Init:2/3 0 44s
calico-node-zzv5r 0/1 Init:2/3 0 44s
coredns-6554b8b87f-q8g65 0/1 ContainerCreating 0 38m
coredns-6554b8b87f-r9dkf 0/1 ContainerCreating 0 38mCalico 是 Kubernetes 的网络插件,用于管理 Pod 网络。calico-node 和 calico-kube-controllers 的 Pod 处于 Init:2/3 或 ContainerCreating 状态,这可能由以下原因之一引起:
可能的原因:
- 网络问题 :
- Calico 需要正确配置的网络插件和 CNI(Container Network Interface)配置。如果网络配置不正确,Calico Pod 可能无法正常启动。
- 检查 Calico 的配置文件(通常在
/etc/cni/net.d/目录下)是否正确。
- 依赖未满足 :
- Calico Pod 的初始化容器可能在等待某些依赖(如 etcd 或其他 Calico 节点)就绪。
- 检查 Calico 的日志,确认是否有错误信息。
- 权限问题 :
- Calico 需要特定的权限(如访问 etcd 或其他资源)。如果权限不足,可能会导致初始化失败。
解决方法:
-
检查 Calico 日志: 查看 Calico Pod 的日志,了解具体问题:
bashkubectl logs -f calico-node-<PodName> -n kube-system -c <ContainerName>例如:
bashkubectl logs -f calico-node-55cl2 -n kube-system -c calico-node -
检查 Calico 配置 : 确保 Calico 的配置文件(如
calico-config.yaml)正确无误,特别是网络范围、etcd 配置等。 -
检查网络插件状态: 确保 CNI 插件已正确安装,并且网络配置文件已加载:
bashls /etc/cni/net.d/ -
检查 etcd 状态: Calico 使用 etcd 存储网络配置,确保 etcd 集群正常运行:
bashkubectl get pods -n kube-system | grep etcd
2. CoreDNS Pod 未就绪
[root@k8s-master01 calico]# kubectl get po -n kube-system
NAME READY STATUS RESTRTS AGE
[root@k8s-master01 calico]# kubectl get po -n kube-system
NAME READY STATUS RESTRTS AGE
calico-kube-controllers-79fd456594-bx826 1/1 Running 0 3m24s
calico-node-55cl2 1/1 Running 0 3m24s
calico-node-d824g 1/1 Running 0 3m24s
calico-node-fd2n6 1/1 Running 0 3m24s
calico-node-xr9h2 1/1 Running 0 3m24s
calico-node-zzv5r 1/1 Running 0 3m24s
coredns-6554b8b87f-q8g65 0/1 ContainerCreating 0 38m
coredns-6554b8b87f-r9dkf 0/1 ContainerCreating 0 38m
coredns-6554b8b87f-q8g65 0/1 ContainerCreating 0 38m
coredns-6554b8b87f-r9dkf 0/1 ContainerCreating 0 38mCoreDNS 是 Kubernetes 的默认 DNS 服务,用于解析 Pod 和服务的域名。coredns 的 Pod 处于 ContainerCreating 状态,这可能表明它们在启动过程中遇到了问题。
可能的原因:
- 网络问题 :
- CoreDNS 需要访问集群网络,如果网络配置不正确,可能会导致启动失败。
- 权限问题 :
- CoreDNS 需要访问 Kubernetes API Server,如果 RBAC(Role-Based Access Control)配置不正确,可能会导致权限不足。
- 配置问题 :
- CoreDNS 的配置文件(如
coredns.yaml)可能存在问题。
- CoreDNS 的配置文件(如
解决方法:
-
检查 CoreDNS 日志: 查看 CoreDNS Pod 的日志,了解具体问题:
bashkubectl logs -f coredns-6554b8b87f-q8g65 -n kube-system -
检查 CoreDNS 配置 : 确保 CoreDNS 的配置文件(通常在
coredns.yaml中定义)正确无误。 -
检查网络插件状态: 确保网络插件(如 Calico)已正确安装并运行,因为 CoreDNS 依赖于集群网络。
-
检查 RBAC 配置: 确保 CoreDNS 的 RBAC 配置正确,允许其访问 Kubernetes API Server。
-
其他注意事项
-
检查节点状态 : 确保所有节点都处于
Ready状态:bashkubectl get nodes -
检查网络连通性: 确保所有节点之间可以正常通信,特别是控制平面节点和工作节点。
-
检查存储类(StorageClass): 如果集群中使用了动态存储卷,确保存储类已正确配置。
2.8 生成新的token key值(Master01)
⚠️:由于生成的token值有效期较短,或者有新的master或者node节点需要添加集群当中,所以需要获取新的token值
bash
#>>> 生成新的master的token值(一般不需要,三台master足够支撑)
$ kubeadm init phase upload-cers --upload-certs
#>>> 生成新的node的token值
$ kubeadm token create --print-join-command
#>>> 查看token值过期时间(在/root/new.yaml文件中token: abcdef.0123456789abcdef对应bootstrap-token-abcdef)
$ kubectl get secret -n kube-system
bootstrap-token-abcdef
$ kubectl get secret bootstrap-token-abcdef -n kube-system -oyaml
找到 expiration: MjAyMi0xMS0yM1QxNDowNjowOFo=
$ echo "MjAyMi0xMS0yM1QxNDowNjowOFo=" | base64 --decode2.9 Metrics server部署(Master01)
在当今快速发展的云原生环境中,Kubernetes已成为容器编排的事实标准。随着越来越多的应用被迁移到Kubernetes平台上,有效地管理和优化这些应用的性能变得至关重要。而在这个过程中,有一个不可或缺的工具------Metrics Server,它扮演着至关重要的角色。
2.9.1 什么是Metrics server?
Metrics Server 是 Kubernetes 内置自动扩展管道的可扩展、高效的容器资源指标来源。
Metrics Server 从Kubelet收集资源指标,并通过Metrics API在 Kubernetes apiserver 中公开它们,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler 使用。Metrics API 也可以通过访问kubectl top,从而更轻松地调试自动缩放管道。
Metrics Server是Kubernetes内置自动扩展管道的可扩展、高效的容器资源指标来源。Metrics Server从Kubelet收集资源指标,并通过Metrics API在Kubernetes apiserver中公开它们,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用。Metrics API也可以通过访问kubectl top,从而更轻松地调试自动缩放管道。
2.9.2 Metrics server使用场景?
- 自动伸缩 :结合
Horizontal Pod Autoscaler (HPA)使用时,可以根据实时负载动态调整副本数量。 - 健康检查:定期检查关键服务的资源消耗是否正常,帮助识别潜在问题。
- 成本优化:分析长期运行的工作负载,找出可以减少资源请求的地方以节省成本。
bash
#>>> 将Master01节点的front-proxy-ca.crt复制到所有节点(master01)
$ scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node01:/etc/kubernetes/pki/front-proxy-ca.crt
$ scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node02:/etc/kubernetes/pki/front-proxy-ca.crt
$ scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-master02:/etc/kubernetes/pki/front-proxy-ca.crt
$ scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-master03:/etc/kubernetes/pki/front-proxy-ca.crt
#>>> 安装Metrics server(master01)
$ cd ~/kubernetes_install/kubeadm-metrics-server/
[root@k8s-master01 kubeadm-metrics-server]# kubectl create -f comp.yaml
#>>> 查看Metrics server状态(master01)
$ kubectl get po -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-58b7c66876-zrc5l 0/1 Running 0 27s
$ kubectl get po -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-58b7c66876-zrc5l 1/1 Running 0 31s
#>>> 查看节点状态(master01)
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 301m 10% 1436Mi 50%
k8s-master02 299m 9% 1377Mi 48%
k8s-master03 278m 9% 1272Mi 44%
k8s-node01 112m 3% 852Mi 29%
k8s-node02 132m 4% 953Mi 33%
#>>> 查看pod的状态(master01)
$ kubectl get pods -n kube-system | grep metrics-server
metrics-server-58b7c66876-zrc5l 1/1 Running 0 6m14s
$ kubectl top po -A | grep metrics-server
kube-system metrics-server-58b7c66876-zrc5l 7m 27Mi
$ 以上两个命令都可以不筛选,看全部是否运行,有无挂了的2.10 修改Kube-proxy改为ipvs模式(master01)
初始化集群的时注释了ipvs配置(Master01),将 kube-proxy 模式从 iptables 修改为 ipvs 是为了提升性能和功能。
详解:
- 性能优势 :
ipvs可以更有效地处理大量并发连接。这使得它在高流量场景下表现更佳。更好地扩展以处理更多的服务和后端 pod,而iptables在规则数量非常多时,性能可能会显著下降。 - 低延迟和高吞吐量 :
ipvs通过在内核空间处理数据包,减少了用户空间和内核空间之间的切换,从而提高了数据包处理的效率,带来更低的延迟和更高的吞吐量。 - 快速规则应用 :
ipvs在处理和应用网络规则时速度更快,特别是在规则变更频繁的情况下。 - 多种调度算法 :
ipvs提供了多种负载均衡算法(如轮询、最小连接、最短延迟等),可以根据具体需求选择最合适的算法,而iptables则缺乏这种灵活性。 - 稳定性 :
ipvs的实现更加稳定,尤其是在大型集群中,它能更好地应对复杂的网络环境和高负载。 - 简化的规则管理 :
ipvs使用专用的内核模块管理规则,相比iptables更加简洁和高效。iptables规则在处理和管理上会更加复杂,特别是当规则数量增多时。 - 维护方便 :
ipvs的规则结构更清晰,维护起来更为方便,不像iptables那样需要处理大量的规则链和复杂的规则匹配逻辑。
bash
$ kubectl edit cm kube-proxy -n kube-system
# 找到mode字段添加ipvs,如下
mode: "ipvs"
#>>> 更新Kube-Proxy的Pod
$ kubectl patch daemonset kube-proxy -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"date\":\"`date +'%s'`\"}}}}}" -n kube-system
#>>> 验证Kube-Proxy模式 出现ipvs 四个字的输出
[root@k8s-master01 kubeadm-metrics-server]# curl 127.0.0.1:10249/proxyMode
ipvs[root@k8s-master01 kubeadm-metrics-server]#
[root@k8s-master01 kubeadm-metrics-server]# -----未完待续-----
主页:
------------- ---------三分云计算----------------------------------
--------------- -------三分云计算----------------------------------
------------- ---------三分云计算----------------------------------
写文不易 给我点点关注 和点点赞 点点收藏吧
评论区有红包