Hive搭建完成后 可以配置JDBC连接
1.修改Hadoop配置文件
cd /usr/local/soft/hadoop-2.7.6/etc/hadoopvim core-site.xml添加<property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>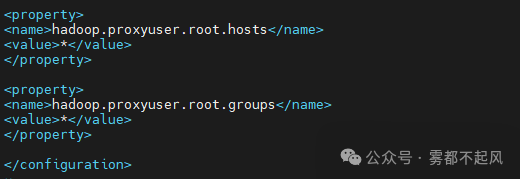
2.启动Hive的JDBC连接
start-all.shzkServer.sh start (三台机器)master启动hiveserver2hive --service hiveserver2查看进程 netstat -nplt | grep 10000HIVE连接JDBCbeeline -u jdbc:hive2://master:10000 -n root
