测试需求
用python写一个脚本,批量把excel 中的文件链接对应的文件下载到本地目录
前提
pipenv管理python版本,在电脑上提前安装好pipenv
测试过程
1、在Trae中输入需求,先让Trae生成对应的脚本。
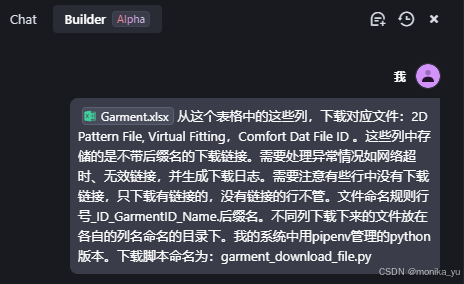
Trae会进行思考,创建虚拟环境,下载对应依赖:
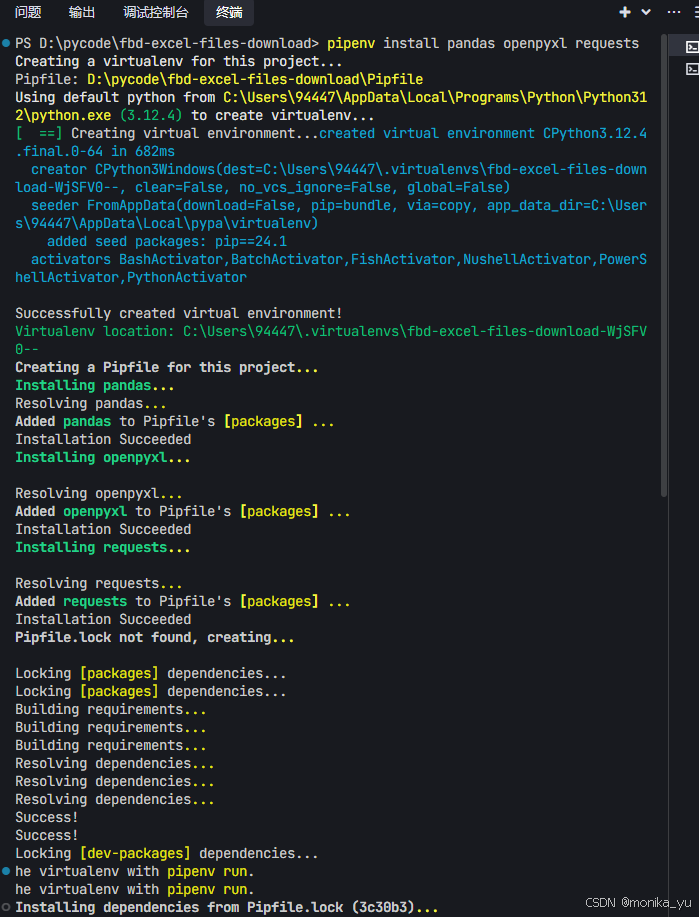
2、在Pycharm中打开同一个项目目录,打开刚刚Trae生成的脚本,初步看看有什么问题:(Trae中用pipenv创建的虚拟环境,在pycharm中会自动引用,所以能够保证运行环境一致。)
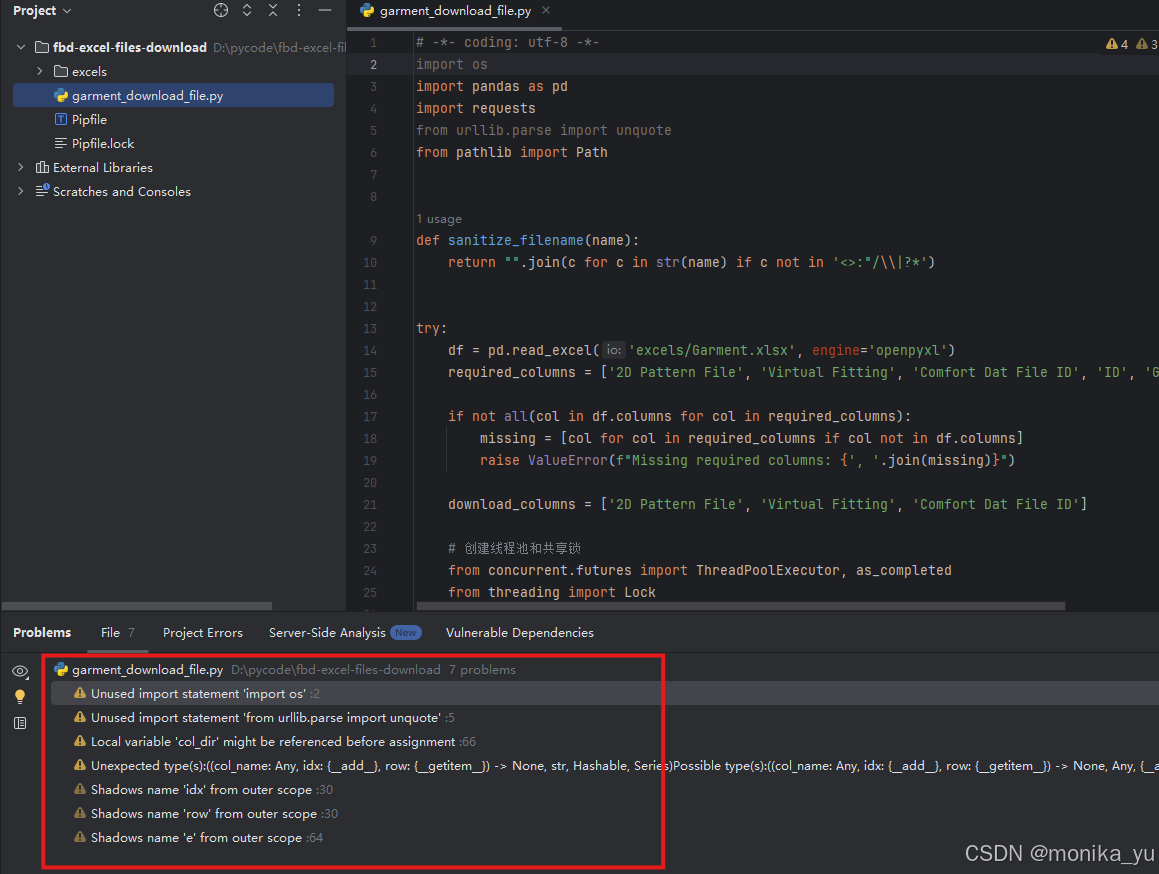
3、把pycharm中提示的错误和警告等信息复制到Trae中,让Trae修改试试(也可以直接在Pycharm中修改运行测试)

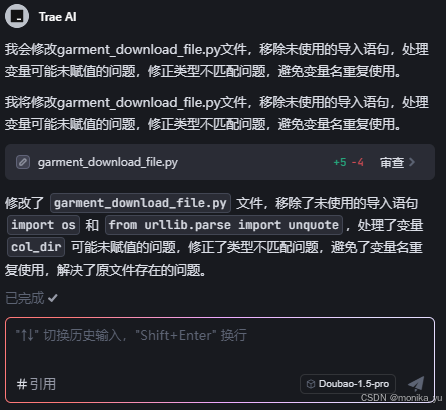
Trae中会在对应的行上标记有哪些修改,点击"接受"即可。然后在Pycharm中查看,发现还是正确修改,无效的引用都还在。。。目前是用的Doubao-1.5-pro模型,看起来效果并不理想,换一个模型试试,直接点击模型切换DeepSeek R1:

 发现问题更多了,连基本缩进都是错误的:
发现问题更多了,连基本缩进都是错误的:
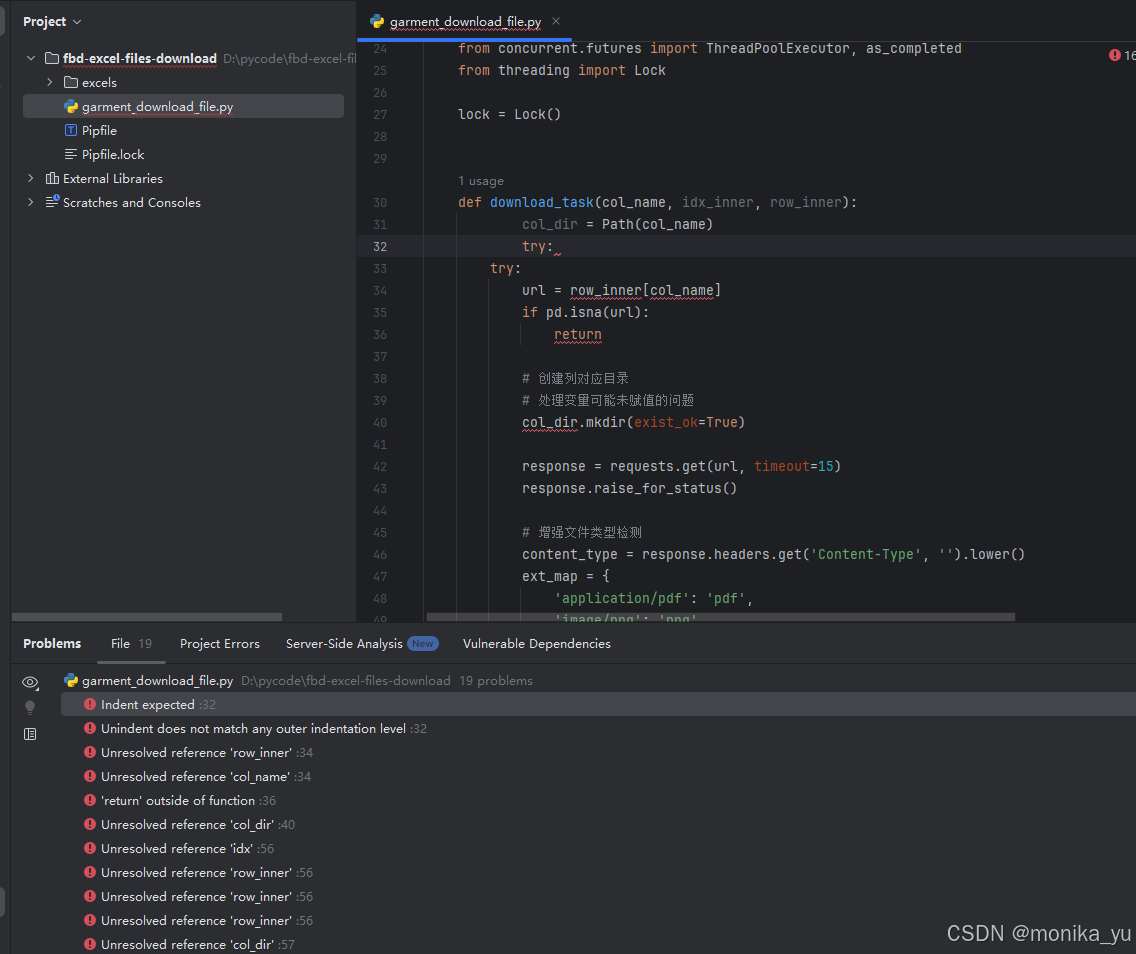
再试几次:
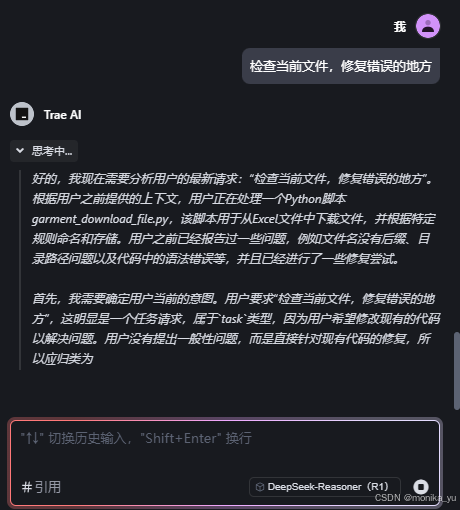

这次的效果还不错,没有明显的错误:
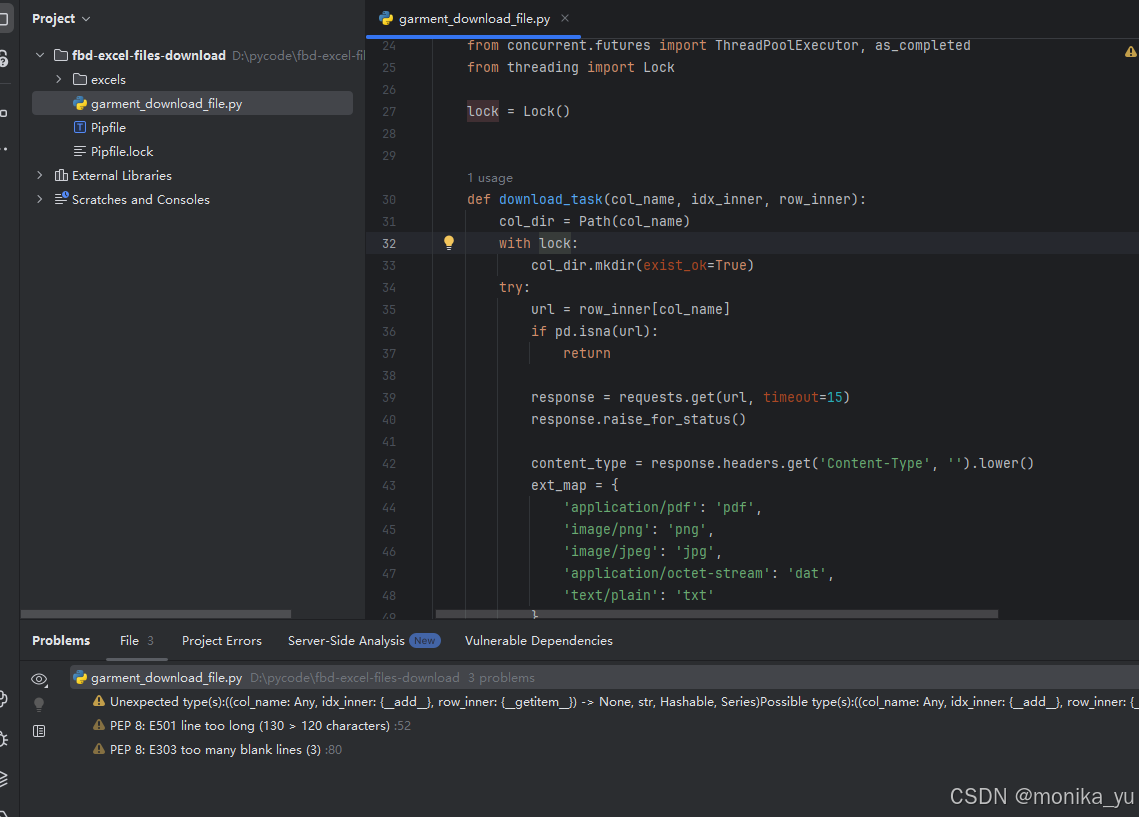
运行试试:
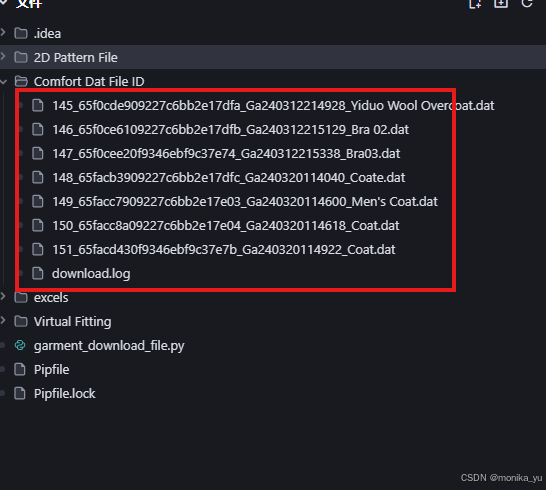
所有需要的文件都很快下载下来了!
代码:
python
# -*- coding: utf-8 -*-
import pandas as pd
import requests
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor, as_completed
from threading import Lock
def sanitize_filename(name):
return "".join(c for c in str(name) if c not in '<>:"/\\|?*')
def download_task(col_name: str, idx_inner: int, row_inner: pd.Series, thread_lock: Lock):
col_dir = Path(col_name)
with thread_lock:
col_dir.mkdir(exist_ok=True)
try:
url = row_inner[col_name]
if pd.isna(url):
return
response = requests.get(url, timeout=15)
response.raise_for_status()
content_type = response.headers.get('Content-Type', '').lower()
ext_map = {
'application/pdf': 'pdf',
'image/png': 'png',
'image/jpeg': 'jpg',
'application/octet-stream': 'dat',
'text/plain': 'txt'
}
ext = next((v for k, v in ext_map.items() if k in content_type), 'bin')
filename = f"{idx_inner + 1}_{row_inner['ID']}_{row_inner['Garment ID']}_{sanitize_filename(row_inner['Name'])}.{ext}"
filepath = col_dir / filename
with open(filepath, 'wb') as f:
f.write(response.content)
log_message(thread_lock, col_dir, 'download.log', f"Success: {filename}\n")
except Exception as ex:
log_message(thread_lock, col_dir, 'errors.log', f"Row {idx_inner + 1} [{col_name}] error: {str(ex)}\n")
def log_message(thread_lock: Lock, col_dir: Path, log_file: str, message: str):
with thread_lock:
with open(col_dir / log_file, 'a', encoding='utf-8') as log:
log.write(message)
try:
df = pd.read_excel('excels/Garment.xlsx', engine='openpyxl')
required_columns = ['2D Pattern File', 'Virtual Fitting', 'Comfort Dat File ID', 'ID', 'Garment ID', 'Name']
if not all(col in df.columns for col in required_columns):
missing = [col for col in required_columns if col not in df.columns]
raise ValueError(f"Missing required columns: {', '.join(missing)}")
download_columns = ['2D Pattern File', 'Virtual Fitting', 'Comfort Dat File ID']
main_lock = Lock()
with ThreadPoolExecutor(max_workers=8) as executor:
futures = []
for col in download_columns:
for idx_outer, row_outer in df.iterrows():
futures.append(
executor.submit(download_task, col_name=col, idx_inner=int(idx_outer), row_inner=row_outer,
thread_lock=main_lock))
for future in as_completed(futures):
future.result()
print("所有下载任务已完成,请检查各目录下的日志文件")
print("Download completed. Check logs for details")
except Exception as e:
print("Error: {}".format(str(e)))总结
1、Trae中模型选择DeepSeek R1优于Doubao。
2、复杂项目可以在pycharm中断点调试,可以快速查看错误信息。