很多人觉得做一件事付出了10分的努力,却只能得到5分的汇报,其实剩下的5分,是在填补你过往的懒惰,只有将过往的懒惰填满,努力才会有正向成果
------ 25.3.14
一、生成式任务
输出 Y 没有预设的范围,受输入 X 影响
生成式任务在人工智能的各个领域都有,包括很多跨领域任务
**图像领域:**图像/视频生成, 图像补全等
**语音领域:**语音合成等
**文本领域:**机器翻译、大模型聊天等
二、seq2seq任务
生成式任务也被称为 Seq2Seq任务
Seq2Seq(Sequence to Sequence) 模型,通常也被称为序列到序列模型,是一种用于处理序列数据的深度学习模型架构,在自然语言处理(NLP)、语音识别等多个领域都有广泛应用
1.模型结构
编码器(Encoder) :其作用是将输入序列进行编码,把输入序列中的信息压缩成一个固定长度的向量表示,也叫上下文向量(Context Vector)。编码器通常是一个循环神经网络(RNN)或其变体,如长短期记忆网络(LSTM)、门控循环单元(GRU)等。在处理输入序列时,编码器会逐个读取输入序列中的元素,并将当前的输入和上一时刻的隐藏状态结合起来,更新当前的隐藏状态。最后,编码器的最终隐藏状态就作为整个输入序列的上下文向量。
解码器(Decoder) :解码器的任务是根据编码器得到的上下文向量来生成目标序列。它也是一个 RNN 或其变体。解码器在生成输出序列时,从一个起始符号(如 "<sos>")开始,根据当前的输入(通常是上一时刻生成的输出以及上下文向量)和上一时刻的隐藏状态,预测下一个输出符号的概率分布。然后从这个概率分布中采样得到下一个输出符号,将其作为当前时刻的输出,并更新隐藏状态,用于生成下一个符号,直到遇到结束符号(如 "<eos>")或者达到预设的最大输出长度。
2.工作原理
生成式任务输入输出均为不定长的序列
序列标注任务输入输出为等长序列
如: 机器翻译 机器作诗 自动摘要等
训练过程:在训练阶段,给定输入序列和对应的目标输出序列,模型通过最小化预测输出与真实输出之间的损失函数来调整模型的参数。常用的损失函数是交叉熵损失,它衡量了模型预测的概率分布与真实标签之间的差异。在反向传播过程中,误差会从解码器传播到编码器,使得编码器和解码器的参数都能够得到更新,以更好地捕捉输入序列和输出序列之间的映射关系。
推理过程:在推理阶段,将输入序列输入到编码器中得到上下文向量,然后将上下文向量输入到解码器中。解码器从起始符号开始,逐步生成输出序列。在生成每个输出符号时,根据当前的概率分布选择概率最大的符号作为输出,或者根据一定的策略进行采样。这个过程不断重复,直到生成结束符号或者达到最大输出长度。
3.局限性
长序列问题:对于长输入序列,编码器难以有效地捕捉和记忆所有信息,可能会出现信息丢失或遗忘的情况,导致生成的输出质量下降。
固定长度向量表示的局限性:将整个输入序列编码为一个固定长度的向量可能无法充分表示复杂的输入信息,特别是当输入序列很长或者包含丰富的语义和结构信息时。
生成的多样性和准确性权衡:在生成输出序列时,为了提高生成的多样性,可能会采用采样等策略,但这可能会导致生成结果的准确性下降;而如果过于追求准确性,只选择概率最大的输出符号,可能会使生成的结果过于单一,缺乏多样性。
为了克服这些局限性,研究人员提出了许多改进方法,**如:**引入注意力机制(Attention Mechanism)、多头注意力机制(Multi-Head Attention)、增加模型的深度和宽度等,这些改进使得 Seq2Seq 模型在各种任务上的性能得到了显著提升。
三、自回归语言模型训练 Decoder only
自回归语言模型:由前文预测下文 (前几个字预测之后的字),更适合生成式任务
自回归语言模型的损失函数为:逐字计算交叉熵
自编码:通过序列两边的词 预测被掩盖的中心词(如Bert)
自回归:自回归模型通过序列中已生成的词预测下一个词,属于生成式模型。其核心是单向注意力机制,仅利用上文信息(如GPT)
| 维度 | 自回归模型 | 自编码器 |
|---|---|---|
| 预测目标 | 下一个词(如GPT的NTP) | 被掩盖的中心词(如BERT的MLM) |
| 上下文利用 | 单向(仅左侧已生成内容) | 双向(左侧+右侧完整上下文) |
| 应用场景 | 文本生成、对话系统 | 语义理解、实体识别、下游任务微调 |
| 典型代表 | GPT、Llama、XLNet(部分模式) | BERT、RoBERTa、ELECTRA |
文本生成任务更适合使用自回归语言模型,训练方式更接近任务目标

Bert: 自编码语言模型,这里的Bert是指一种模型结构,Bert作为一种训练目标的话,是以自编码的模式 目标进行训练,训练bert可以有多种训练方式,自编码和自回归都是其中的两种
词表上的概率分布是指词表长维度的向量,其中每一维的值代表词表上该字出现的概率
四、自回归模型结构:文本生成任务 ------ Embedding + LSTM
基于语言模型和一段"引言",利用自回归语言模型,生成后续文本

代码示例 🚀
数据文件
通过网盘分享的文件:文本生成
链接: https://pan.baidu.com/s/1Az9WLH1LfEyk_5ih8db7jw?pwd=6uv6 提取码: 6uv6
--来自百度网盘超级会员v3的分享
代码流程
python
│
├── 词表构建 → 语料加载 → 滑动窗口采样 → 序列编码 → 数据集封装
│
├── 模型初始化 → 嵌入层 → LSTM层 → 分类层 → Dropout层
│
├── 训练循环 → 梯度清零 → 前向传播 → 损失计算 → 反向传播 → 参数更新
│
└── 文本生成 → 采样策略 → 困惑度计算 → 模型保存Ⅰ、模型初始化
① 嵌入层 ------> ② LSTM层 ------> ③ 分类层 ------> ④ 正则化与损失函数
**nn.Embedding():**将离散的类别索引(如词索引)映射为稠密向量表示,常用于词嵌入或特征编码
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
num_embeddings |
int |
词汇表大小(索引的最大值+1) | num_embeddings=10000 |
embedding_dim |
int |
词向量维度 | embedding_dim=300 |
padding_idx |
int(可选) |
指定填充索引,其对应向量在训练中不更新,默认初始化为全零 | padding_idx=0 |
max_norm |
float(可选) |
若设置,嵌入向量范数超过该值时会被裁剪 | max_norm=2.0 |
norm_type |
float(默认2.0) |
裁剪时使用的范数类型(L2范数) | norm_type=2.0 |
scale_grad_by_freq |
bool(默认False) |
若为True,梯度会根据索引出现频率缩放 |
scale_grad_by_freq=True |
sparse |
bool(默认False) |
是否使用稀疏梯度(适用于大词汇表节省内存) | sparse=True |
**nn.LSTM():**长短时记忆网络,用于捕捉序列数据的长期依赖关系
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
input_size |
int |
输入特征的维度(如词向量维度) | input_size=128 |
hidden_size |
int |
隐藏状态的维度(输出特征维度) | hidden_size=256 |
num_layers |
int(默认1) |
LSTM堆叠层数(纵向深度) | num_layers=2 |
bias |
bool(默认True) |
是否使用偏置项 | bias=False |
batch_first |
bool(默认False) |
若为True,输入/输出张量形状为(batch, seq_len, feature) |
batch_first=True |
dropout |
float(默认0) |
层间丢弃率(仅当num_layers>1时生效) |
dropout=0.3 |
bidirectional |
bool(默认False) |
是否使用双向LSTM | bidirectional=True |
**nn.Linear():**全连接层,执行线性变换(y = xA^T + b)
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
in_features |
int |
输入特征维度 | in_features=256 |
out_features |
int |
输出特征维度 | out_features=10 |
bias |
bool(默认True) |
是否启用偏置项 | bias=False |
**nn.Dropout():**通过随机丢弃神经元防止过拟合(仅训练时生效)
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
p |
float(默认0.5) |
神经元丢弃概率(0 ≤ p < 1) | p=0.3 |
inplace |
bool(默认False) |
是否原地修改输入张量以节省内存 | inplace=True |
**nn.functional.cross_entropy():**计算交叉熵损失(结合Softmax和负对数似然),适用于分类任务
| 参数名 | 类型/可选值 | 描述 | 示例 |
|---|---|---|---|
input |
Tensor |
模型输出的未归一化概率(logits) | input=logits |
target |
Tensor |
真实标签(类别索引或概率分布) | target=labels |
weight |
Tensor(可选) |
类别权重(用于类别不平衡) | weight=class_weights |
ignore_index |
int(默认-100) |
指定忽略的标签值(不参与损失计算) | ignore_index=-1 |
reduction |
str(默认'mean') |
损失汇总方式:'none'(不汇总)、'mean'(平均)、'sum'(求和) |
reduction='sum' |
label_smoothing |
float(默认0.0) |
标签平滑系数(0 ≤ value ≤ 1) | label_smoothing=0.1 |
python
def __init__(self, input_dim, vocab):
super(LanguageModel, self).__init__()
self.embedding = nn.Embedding(len(vocab), input_dim)
self.layer = nn.LSTM(input_dim, input_dim, num_layers=1, batch_first=True)
self.classify = nn.Linear(input_dim, len(vocab))
self.dropout = nn.Dropout(0.1)
self.loss = nn.functional.cross_entropyⅡ、前向计算
代码运行流程
python
forward 方法流程
├── 1. 输入数据预处理
│ └── 操作: `x = self.embedding(x)`
│ └── 作用: 将输入数据 `x` 通过嵌入层转换为嵌入向量,输出形状为 `(batch_size, sen_len, input_dim)`
│
├── 2. 通过模型层处理数据
│ └── 操作: `x, _ = self.layer(x)`
│ └── 作用: 将嵌入向量通过模型层(如 LSTM、GRU 等)处理,输出形状仍为 `(batch_size, sen_len, input_dim)`
│
├── 3. 分类器处理
│ └── 操作: `y_pred = self.classify(x)`
│ └── 作用: 将模型层的输出通过分类器(如全连接层)处理,输出形状为 `(batch_size, vocab_size)`
│
├── 4. 判断是否输入真实标签
│ └── 操作: `if y is not None:`
│ ├── 4.1 计算损失值
│ │ └── 操作: `return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))`
│ │ ├── 作用: 如果输入了真实标签 `y`,则计算预测值 `y_pred` 与真实标签 `y` 之间的损失值
│ │ └── 输出: 返回损失值
│ └── 4.2 返回预测值
│ └── 操作: `return torch.softmax(y_pred, dim=-1)`
│ ├── 作用: 如果未输入真实标签 `y`,则返回预测值的 softmax 结果
│ └── 输出: 返回预测值的概率分布
│
└── 5. 方法结束
└── 操作: 无
└── 作用: 方法执行完毕,返回结果**x:**输入数据,通常是经过预处理后的张量,表示一批数据(batch)
**y:**真实标签(ground truth),用于计算损失值。如果未提供,则函数返回预测值
**y_pred:**模型的预测输出,通常是分类器的结果
**view():**调整张量形状而不改变数据,返回与原始张量共享内存的新视图
| 参数/属性 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
*shape |
整数元组 | 目标形状,元素总数需与原张量一致。若含 -1,自动计算该维度大小 |
x.view(3, -1) → 自动计算列数 |
| 共享数据 | bool(默认True) |
修改视图或原张量会互相影响 | 修改 x.view() 会影响原张量 |
| 连续性要求 | bool(默认需连续) |
仅适用于连续存储的张量,否则需先调用 .contiguous() |
x.contiguous().view(...) |
**.shape():**返回张量的维度信息(与 size() 方法等价)
**torch.softmax():**将输入 logits 转换为概率分布(和为1),适用于多分类任务输出
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
input |
Tensor |
模型输出的未归一化 logits | logits = torch.tensor([...]) |
dim |
int |
指定计算维度(必须显式声明,否则警告) | dim=1 表示按行计算概率 |
| 输出特性 | Tensor |
输出值范围为 (0, 1),且沿 dim 维度和为1 |
sum(softmax(x, dim=1)) = 1 |
python
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.layer(x) #output shape:(batch_size, sen_len, input_dim)
y_pred = self.classify(x) #output shape:(batch_size, vocab_size)
if y is not None:
return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))
else:
return torch.softmax(y_pred, dim=-1)Ⅲ、加载数据
① 加载字表
代码运行流程
python
build_vocab 方法流程
├── 1. 初始化词汇表
│ └── 操作: `vocab = {"<pad>":0}`
│ └── 作用: 初始化词汇表,并为 `<pad>` 分配索引 0
│
├── 2. 打开词汇表文件
│ └── 操作: `with open(vocab_path, encoding="utf8") as f:`
│ └── 作用: 以 UTF-8 编码打开词汇表文件
│
├── 3. 遍历文件中的每一行
│ └── 操作: `for index, line in enumerate(f):`
│ ├── 3.1 去掉结尾换行符
│ │ └── 操作: `char = line[:-1]`
│ │ └── 作用: 去掉每行结尾的换行符,得到字符
│ ├── 3.2 为字符分配索引
│ │ └── 操作: `vocab[char] = index + 1`
│ │ └── 作用: 为字符分配索引,索引从 1 开始(0 保留给 `<pad>`)
│ └── 3.3 将字符和索引添加到词汇表
│ └── 操作: 无(隐式操作)
│ └── 作用: 将字符和索引添加到词汇表 `vocab` 中
│
└── 4. 返回词汇表
└── 操作: `return vocab`
└── 作用: 返回构建好的词汇表**vocab_path:**词汇表文件的路径,函数会从该文件中读取词汇
**vocab:**用于存储词汇表的字典,初始化为 {"<pad>": 0},其中 <pad> 是一个特殊标记,索引为 0。
**f:**打开的文件对象,用于逐行读取词汇表文件
**index:**当前行的索引,从 0 开始,用于为每个词汇分配唯一的索引
**line:**从文件中读取的每一行内容
**char:**去掉行尾换行符后的字符,即词汇表中的每个词汇
**open():**打开文件并返回文件对象,支持读写操作。
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
file |
str(必选) |
文件路径(绝对或相对路径) | file="data.txt" |
mode |
str(可选) |
文件打开模式,默认为 'r'(只读) |
mode='w'(覆盖写入) |
buffering |
int(可选) |
缓冲策略: - 0:无缓冲 - 1:行缓冲 - -1:系统默认缓冲 |
buffering=1(行缓冲) |
encoding |
str(可选) |
文件编码方式,如 'utf-8'、'gbk' |
encoding='utf-8' |
errors |
str(可选) |
编码错误处理方式: - 'strict'(报错) - 'ignore'(忽略) |
errors='ignore' |
newline |
str(可选) |
控制换行符解析,如 '\n'、'\r\n' |
newline='\n' |
**enumerate():**将可迭代对象转换为索引-值对序列,常用于循环中获取元素及其索引。
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
iterable |
可迭代对象(必选) | 支持列表、元组、字符串等 | iterable=['a', 'b', 'c'] |
start |
int(可选,默认 0) |
索引的起始值 | start=1(索引从1开始) |
python
#加载字表
def build_vocab(vocab_path):
vocab = {"<pad>":0}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
char = line[:-1] #去掉结尾换行符
vocab[char] = index + 1 #留出0位给pad token
return vocab② 加载语料
代码运行流程
python
load_corpus 方法流程
├── 1. 初始化语料变量
│ └── 操作: `corpus = ""`
│ └── 作用: 初始化一个空字符串,用于存储加载的语料内容
│
├── 2. 打开语料文件
│ └── 操作: `with open(path, encoding="gbk") as f:`
│ └── 作用: 以 GBK 编码打开语料文件,确保文件读取后自动关闭
│
├── 3. 逐行读取文件
│ └── 操作: `for line in f:`
│ ├── 3.1 去除行首尾空白字符
│ │ └── 操作: `line.strip()`
│ │ └── 作用: 去除每行首尾的空白字符(如换行符、空格等)
│ ├── 3.2 将行内容追加到语料中
│ │ └── 操作: `corpus += line.strip()`
│ │ └── 作用: 将处理后的行内容追加到 `corpus` 中
│ └── 3.3 更新语料内容
│ └── 操作: 无(隐式操作)
│ └── 作用: 逐步构建完整的语料内容
│
└── 4. 返回语料内容
└── 操作: `return corpus`
└── 作用: 返回加载的语料内容**corpus:**用于存储加载的语料内容,初始化为空字符串
**path:**语料文件的路径
**f:**打开的文件对象,用于逐行读取语料内容
**line:**从文件中读取的每一行内容
**open():**打开文件并返回文件对象,支持读写操作。
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
file |
str(必选) |
文件路径(绝对或相对路径) | file="data.txt" |
mode |
str(可选) |
文件打开模式,默认为 'r'(只读) |
mode='w'(覆盖写入) |
buffering |
int(可选) |
缓冲策略: - 0:无缓冲 - 1:行缓冲 - -1:系统默认缓冲 |
buffering=1(行缓冲) |
encoding |
str(可选) |
文件编码方式,如 'utf-8'、'gbk' |
encoding='utf-8' |
errors |
str(可选) |
编码错误处理方式: - 'strict'(报错) - 'ignore'(忽略) |
errors='ignore' |
newline |
str(可选) |
控制换行符解析,如 '\n'、'\r\n' |
newline='\n' |
**str.strip():**去除字符串开头和结尾的指定字符(默认去除空白符)
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
chars |
str(可选) |
指定要删除的字符集合,默认为空白符(\n、\t、空格等) |
chars='*#'(去除*和#) |
python
#加载语料
def load_corpus(path):
corpus = ""
with open(path, encoding="gbk") as f:
for line in f:
corpus += line.strip()
return corpusⅣ、随机生成一个样本
代码运行流程
python
build_sample 方法流程
├── 1. 随机生成起始位置
│ └── 操作: `start = random.randint(0, len(corpus) - 1 - window_size)`
│ └── 作用: 随机选择一个起始位置,确保窗口不会超出语料范围
│
├── 2. 计算窗口结束位置
│ └── 操作: `end = start + window_size`
│ └── 作用: 根据起始位置和窗口大小计算结束位置
│
├── 3. 截取窗口文本
│ └── 操作: `window = corpus[start:end]`
│ └── 作用: 从语料中截取窗口文本,作为输入数据
│
├── 4. 截取目标文本
│ └── 操作: `target = corpus[start + 1:end + 1]`
│ └── 作用: 从语料中截取目标文本,作为输出数据,与窗口文本错开一位
│
├── 5. 将字符转换为索引
│ ├── 5.1 转换窗口文本
│ │ └── 操作: `x = [vocab.get(word, vocab["<UNK>"]) for word in window]`
│ │ └── 作用: 将窗口文本中的字符转换为索引,生成输入序列 `x`
│ └── 5.2 转换目标文本
│ └── 操作: `y = [vocab.get(word, vocab["<UNK>"]) for word in target]`
│ └── 作用: 将目标文本中的字符转换为索引,生成输出序列 `y`
│
└── 6. 返回输入和输出序列
└── 操作: `return x, y`
└── 作用: 返回生成的输入序列 `x` 和输出序列 `y`**vocab:**词汇表字典,将字符映射为唯一索引(含<UNK>)
**window_size:**窗口大小,表示每个样本的输入长度。
**corpus:**语料文本,函数会从中随机截取样本。
**start:**随机起始位置,用于确定窗口的起始索引
**end:**窗口的结束索引,end = start + window_size
**window:**从语料中截取的窗口文本,作为输入数据
**target:**从语料中截取的目标文本,作为输出数据。与 window 错开一位
**x:**将 window 中的字符转换为索引后的输入序列
**y:**将 target 中的字符转换为索引后的输出序列
**random.randint():**生成指定范围内的随机整数(包含两端值),适用于模拟随机事件或生成随机数据
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
a |
int(必选) |
随机数范围的下界(包含) | a=1(最小生成值为1) |
b |
int(必选) |
随机数范围的上界(包含) | b=10(最大生成值为10) |
**len():**返回容器或序列对象的元素数量(如字符串、列表、字典等)
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
object |
任意容器对象(必选) | 支持字符串、列表、元组、字典、集合等 | object="hello" → 返回5 |
**字典.get():**安全获取字典中键对应的值,避免 KeyError,支持默认值返回
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
key |
任意可哈希类型(必选) | 要查找的键 | key="age" |
default |
任意类型(可选) | 键不存在时的返回值,默认 None |
default=0 → 键缺失返回0 |
python
#随机生成一个样本 采样部分
#从文本中截取随机窗口,前n个字作为输入,最后一个字作为输出
def build_sample(vocab, window_size, corpus):
start = random.randint(0, len(corpus) - 1 - window_size)
end = start + window_size
window = corpus[start:end]
target = corpus[start + 1:end + 1] #输入输出错开一位
# print(window, target)
x = [vocab.get(word, vocab["<UNK>"]) for word in window] #将字转换成序号
y = [vocab.get(word, vocab["<UNK>"]) for word in target]
return x, yⅤ、批量生成训练样本
代码运行流程
python
build_dataset 方法流程
├── 1. 初始化空列表
│ ├── 1.1 `dataset_x = []`
│ │ └── 作用: 创建一个空列表,用于存储所有样本的输入序列
│ └── 1.2 `dataset_y = []`
│ └── 作用: 创建一个空列表,用于存储所有样本的输出序列
│
├── 2. 生成样本
│ └── 操作: `for i in range(sample_length):`
│ ├── 2.1 生成单个样本
│ │ └── 操作: `x, y = build_sample(vocab, window_size, corpus)`
│ │ └── 作用: 调用 `build_sample` 生成单个样本的输入序列 `x` 和输出序列 `y`
│ ├── 2.2 将输入序列加入数据集
│ │ └── 操作: `dataset_x.append(x)`
│ │ └── 作用: 将当前样本的输入序列 `x` 加入 `dataset_x`
│ └── 2.3 将输出序列加入数据集
│ └── 操作: `dataset_y.append(y)`
│ └── 作用: 将当前样本的输出序列 `y` 加入 `dataset_y`
│
└── 3. 返回数据集
├── 3.1 转换为张量
│ ├── 操作: `torch.LongTensor(dataset_x)`
│ │ └── 作用: 将输入序列列表转换为 PyTorch 张量
│ └── 操作: `torch.LongTensor(dataset_y)`
│ └── 作用: 将输出序列列表转换为 PyTorch 张量
└── 3.2 返回数据集
└── 操作: `return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)`
└── 作用: 返回转换后的输入和输出张量**sample_length:**数据集的大小,即需要生成的样本数量
**vocab:**词汇表字典,将字符映射为唯一索引,含<UNK>
**window_size:**窗口大小,表示每个样本的输入长度
**corpus:**原始语料字符串或字符列表,作为数据源
**x:**单个样本的输入序列,由 build_sample 生成
**y:**单个样本的输出序列,由 build_sample 生成
**range():**生成整数序列,常用于循环控制或生成数字区间
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
start |
int(可选,默认0) |
起始值(包含) | range(2,5) 从2开始 |
stop |
int(必选) |
结束值(不包含) | range(5) 生成0-4 |
step |
int(可选,默认1) |
步长(正数递增,负数递减) | range(1,10,3) 生成1,4,7 |
**列表.append():**在列表末尾添加单个元素,修改原列表但不返回新列表
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
element |
任意类型(必选) | 要添加的元素(可以是数值、字符串、列表等) | list.append([1,2]) 添加列表 |
**torch.LongTensor():**创建64位整数类型的张量,适用于深度学习中的索引或整数运算
| 参数名 | 类型/可选值 | 描述 | 示例/说明 |
|---|---|---|---|
data |
列表/元组/数组(必选) | 输入数据(支持多维结构) | torch.LongTensor([1,2,3]) |
dtype |
torch.dtype(自动推断) |
数据类型(固定为 torch.int64) |
不可修改 |
python
#建立数据集
#sample_length 输入需要的样本数量。需要多少生成多少
#vocab 词表
#window_size 样本长度
#corpus 语料字符串
def build_dataset(sample_length, vocab, window_size, corpus):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, window_size, corpus)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)Ⅵ、建立模型
代码运行流程
python
build_model 方法流程
├── 1. 初始化语言模型
│ └── 操作: `model = LanguageModel(char_dim, vocab)`
│ ├── 1.1 传入字符嵌入维度
│ │ └── 作用: 指定字符嵌入的维度 `char_dim`
│ └── 1.2 传入词汇表
│ └── 作用: 提供词汇表 `vocab`,用于字符到索引的映射
│
└── 2. 返回语言模型
└── 操作: `return model`
└── 作用: 返回构建好的语言模型实例**vocab:**词汇表字典 ,将字符映射为唯一整数索引(如 {"<UNK>":0, "A":1})
**char_dim:**字符嵌入维度,定义每个字符的向量表示维度(如256维)
**model:**语言模型实例,神经网络模型,用于处理和理解文本数据
python
#建立模型
def build_model(vocab, char_dim):
model = LanguageModel(char_dim, vocab)
return modelⅤ、选择采样策略
代码运行流程
python
sampling_strategy 方法流程
├── 1. 随机生成策略
│ └── 操作: `if random.random() > 0.1:`
│ ├── 1.1 采用贪婪策略
│ │ └── 操作: `strategy = "greedy"`
│ └── 1.2 采用采样策略
│ └── 操作: `strategy = "sampling"`
│
├── 2. 根据策略选择类别
│ ├── 2.1 贪婪策略
│ │ └── 操作: `return int(torch.argmax(prob_distribution))`
│ │ └── 作用: 返回概率最大的类别索引
│ └── 2.2 采样策略
│ ├── 2.2.1 转换概率分布为 NumPy 数组
│ │ └── 操作: `prob_distribution = prob_distribution.cpu().numpy()`
│ └── 2.2.2 根据概率分布随机选择类别
│ └── 操作: `return np.random.choice(list(range(len(prob_distribution))), p=prob_distribution)`
│ └── 作用: 返回根据概率分布随机选择的类别索引
│
└── 3. 返回选择的类别索引
└── 操作: 返回 `int` 类型的类别索引**prob_distribution:**模型输出的概率分布,表示每个 token 作为下一个生成目标的概率。
**strategy:**控制采样策略的类型,可选值为 "greedy"(贪心)或 "sampling"(随机采样)。
**random.random():**生成一个 [0.0, 1.0) 范围内的随机浮点数(包含 0 但不包含 1)
**torch.argmax():**返回张量中最大值所在的索引,支持沿指定维度计算
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
input |
torch.Tensor |
必填 | 输入张量 |
dim |
int |
None |
指定维度(例如 dim=0 按列计算最大值索引) |
keepdim |
bool |
False |
是否保留原张量维度(设为 True 时输出与输入维度相同) |
**cpu():**将张量从 GPU 显存迁移到 CPU 内存,便于与 NumPy 交互
**numpy():**将 PyTorch 张量转换为 NumPy 数组(需确保张量在 CPU 上)
**np.random.choice():**从一维数组中按概率分布随机抽取元素,支持重复采样或非重复采样
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
a |
int/array-like |
必填 | 输入数组或整数(整数时等价于 np.arange(a)) |
size |
int/tuple |
None |
输出形状(如 (2,3) 生成 2 行 3 列的随机样本) |
replace |
bool |
True |
是否允许重复采样(True 为可重复,False 为无放回) |
p |
array-like |
None |
每个元素的概率分布(需与 a 长度相同且和为 1) |
**list():**将可迭代对象(如 range、map)转换为列表,支持索引和修改
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
iterable |
可迭代对象 | 必填 | 输入对象(如 range(5)、生成器等) |
**range():**生成整数序列,常用于循环控制或列表生成
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
start |
int |
0 |
起始值(包含) |
stop |
int |
必填 | 结束值(不包含) |
step |
int |
1 |
步长(可为负数,如 step=-1 生成反向序列) |
python
def sampling_strategy(prob_distribution):
if random.random() > 0.1:
strategy = "greedy"
else:
strategy = "sampling"
if strategy == "greedy":
return int(torch.argmax(prob_distribution))
elif strategy == "sampling":
prob_distribution = prob_distribution.cpu().numpy()
return np.random.choice(list(range(len(prob_distribution))), p=prob_distribution)Ⅵ、 基于字符级语言模型生成文本
代码运行流程
python
generate_sentence 方法流程
├── 1. 初始化反向词汇表
│ └── 操作: `reverse_vocab = dict((y, x) for x, y in vocab.items())`
│ └── 作用: 创建从索引到字符的映射
│
├── 2. 设置模型为评估模式
│ └── 操作: `model.eval()`
│ └── 作用: 禁用 dropout 和 batch normalization
│
├── 3. 禁用梯度计算
│ └── 操作: `with torch.no_grad():`
│ └── 作用: 减少内存消耗,加快计算速度
│
├── 4. 初始化预测字符
│ └── 操作: `pred_char = ""`
│ └── 作用: 用于存储模型预测的下一个字符
│
├── 5. 生成文本
│ └── 操作: `while pred_char != "\n" and len(openings) <= 30:`
│ ├── 5.1 更新生成文本
│ │ └── 操作: `openings += pred_char`
│ │ └── 作用: 将预测字符添加到生成文本中
│ ├── 5.2 构建输入张量
│ │ └── 操作: `x = [vocab.get(char, vocab["<UNK>"]) for char in openings[-window_size:]]`
│ │ └── 作用: 将窗口内的字符转换为索引
│ ├── 5.3 转换为张量
│ │ └── 操作: `x = torch.LongTensor([x])`
│ │ └── 作用: 将列表转换为 PyTorch 张量
│ ├── 5.4 检查 GPU 可用性
│ │ └── 操作: `if torch.cuda.is_available(): x = x.cuda()`
│ │ └── 作用: 如果 GPU 可用,将张量移动到 GPU
│ ├── 5.5 模型预测
│ │ └── 操作: `y = model(x)[0][-1]`
│ │ └── 作用: 获取模型输出的概率分布
│ ├── 5.6 选择字符索引
│ │ └── 操作: `index = sampling_strategy(y)`
│ │ └── 作用: 根据策略选择下一个字符的索引
│ └── 5.7 获取预测字符
│ └── 操作: `pred_char = reverse_vocab[index]`
│ └── 作用: 将索引转换为字符
│
└── 6. 返回生成文本
└── 操作: `return openings`
└── 作用: 返回生成的文本openings:初始输入文本,作为生成起点
model:预训练的语言模型,用于预测下一个字符的概率分布
vocab:词汇表字典,将字符映射为唯一索引,含<UNK>
window_size:输入序列长度,控制模型每次预测的上下文窗口大小
reverse_vocab:反向词汇表,将索引映射回字符,用于解码预测结果
pred_char:当前预测的字符 ,每次迭代更新并追加到 openings
**x:**输入张量,表示当前窗口内的字符索引
**y:**模型的输出,表示下一个字符的概率分布
**index:**根据 sampling_strategy 选择的字符索引
**dict():**创建字典对象,支持通过多种参数形式(关键字参数、映射对象、可迭代对象)初始化
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
**kwargs |
关键字参数(可选) | 键值对形式,如 dict(name='Alice', age=25) |
mapping |
映射对象(如字典,可选) | 复制现有映射对象的键值对到新字典 |
iterable |
可迭代对象(可选) | 元素为键值对(如元组或列表),如 dict([('name', 'Alice'), ('age', 25)]) |
**model.eval():**将模型切换为评估模式,关闭 Dropout 和 BatchNorm 层的训练行为,适用于推理阶段
**torch.no_grad():**上下文管理器,禁用自动梯度计算,减少内存占用并加速推理
**字典.get():**安全获取字典中指定键的值,避免因键不存在抛出 KeyError 异常
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
key |
必选(任意可哈希类型) | 要查找的键 |
default |
可选(任意类型) | 键不存在时返回的默认值(默认为 None) |
**torch.LongTensor():**创建 64 位整数类型的张量,适用于索引或整数运算
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
data |
列表/元组/数组(必选) | 输入数据(如 [1, 2, 3]) |
**torch.cuda.is_available():**检查当前系统是否支持 CUDA(即 GPU 加速是否可用)
**cuda():**将张量或模型移动到 GPU 上进行计算(需 CUDA 可用)
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
device |
int 或 torch.device(可选) |
目标 GPU 设备(如 0 或 torch.device('cuda:0')) |
python
#文本生成测试代码
def generate_sentence(openings, model, vocab, window_size):
reverse_vocab = dict((y, x) for x, y in vocab.items())
model.eval()
with torch.no_grad():
pred_char = ""
#生成了换行符,或生成文本超过30字则终止迭代
while pred_char != "\n" and len(openings) <= 30:
openings += pred_char
x = [vocab.get(char, vocab["<UNK>"]) for char in openings[-window_size:]]
x = torch.LongTensor([x])
if torch.cuda.is_available():
x = x.cuda()
y = model(x)[0][-1]
index = sampling_strategy(y)
pred_char = reverse_vocab[index]
return openingsⅦ、计算文本ppl困惑度
代码运行流程
python
calc_perplexity 方法流程
├── 1. 初始化对数概率值
│ └── 操作: `prob = 0`
│ └── 作用: 用于累加对数概率值
│
├── 2. 设置模型为评估模式
│ └── 操作: `model.eval()`
│ └── 作用: 禁用 dropout 和 batch normalization
│
├── 3. 禁用梯度计算
│ └── 操作: `with torch.no_grad():`
│ └── 作用: 减少内存消耗,加快计算速度
│
├── 4. 遍历句子中的每个字符
│ └── 操作: `for i in range(1, len(sentence)):`
│ ├── 4.1 计算窗口起始位置
│ │ └── 操作: `start = max(0, i - window_size)`
│ │ └── 作用: 确保窗口不会超出句子范围
│ ├── 4.2 截取窗口文本
│ │ └── 操作: `window = sentence[start:i]`
│ │ └── 作用: 从句子中截取窗口文本,作为模型的输入
│ ├── 4.3 构建输入张量
│ │ └── 操作: `x = [vocab.get(char, vocab["<UNK>"]) for char in window]`
│ │ └── 作用: 将窗口内的字符转换为索引
│ ├── 4.4 转换为张量
│ │ └── 操作: `x = torch.LongTensor([x])`
│ │ └── 作用: 将列表转换为 PyTorch 张量
│ ├── 4.5 获取目标字符
│ │ └── 操作: `target = sentence[i]`
│ │ └── 作用: 获取模型需要预测的下一个字符
│ ├── 4.6 获取目标字符索引
│ │ └── 操作: `target_index = vocab.get(target, vocab["<UNK>"])`
│ │ └── 作用: 获取目标字符的索引
│ ├── 4.7 检查 GPU 可用性
│ │ └── 操作: `if torch.cuda.is_available(): x = x.cuda()`
│ │ └── 作用: 如果 GPU 可用,将张量移动到 GPU
│ ├── 4.8 模型预测
│ │ └── 操作: `pred_prob_distribute = model(x)[0][-1]`
│ │ └── 作用: 获取模型输出的概率分布
│ ├── 4.9 获取目标字符概率
│ │ └── 操作: `target_prob = pred_prob_distribute[target_index]`
│ │ └── 作用: 获取目标字符的概率值
│ └── 4.10 累加对数概率值
│ └── 操作: `prob += math.log(target_prob, 10)`
│ └── 作用: 累加以 10 为底的对数概率值
│
├── 5. 计算困惑度
│ └── 操作: `return 2 ** (prob * ( -1 / len(sentence)))`
│ └── 作用: 计算困惑度(Perplexity)
│
└── 6. 返回困惑度
└── 操作: 返回 `float` 类型的困惑度值**sentence:**输入的句子,用于计算困惑度(Perplexity)
**model:**训练好的语言模型,用于预测字符的概率分布
**prob:**累积的目标字符对数概率(以10为底)
**vocab:**词汇表字典,包含字符及其对应的索引
**start:**滑动窗口的起始位置,动态计算当前截取文本段的起点
window_size:模型输入的上下文窗口大小
window:从完整文本中截取的局部上下文片段 ,长度不超过 window_size
**x:**输入张量,表示窗口内的字符索引
**target:**下一个待预测的字符,即当前窗口的下一个时序目标。
**target_index:**目标字符的索引
**pred_prob_distribute:**模型输出的概率分布(最后一个时间步)
**target_prob:**目标字符在预测分布中的概率值
**model.eval():**将模型切换为评估模式,关闭 Dropout 和 BatchNorm 层的训练行为(如随机丢弃神经元、使用固定统计量),确保推理结果的稳定性和一致性
torch.no_grad():上下文管理器,禁用自动梯度计算,减少内存占用并加速推理(适用于模型验证、预测或参数冻结场景)
**max():**返回可迭代对象或多个参数中的最大值,支持自定义比较逻辑(如根据对象的属性或复杂条件判断)
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
iterable |
列表/元组/字典等(必选) | 输入数据(如 [1, 3, 2] 或 {"a": 10, "b": 20}) |
key |
函数(可选) | 指定比较依据的函数(如 key=lambda x: x["price"]) |
default |
任意类型(可选) | 当可迭代对象为空时返回的默认值(避免 ValueError) |
字典.get():安全获取字典中指定键的值 ,避免因键不存在抛出 KeyError 异常
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
key |
必选(任意可哈希类型) | 要查找的键 |
default |
可选(任意类型) | 键不存在时返回的默认值(默认为 None) |
torch.LongTensor():创建 64 位整数类型张量 (已弃用,推荐使用 torch.tensor(..., dtype=torch.long))
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
data |
列表/元组/数组(必选) | 输入数据(如 [1, 2, 3]) |
**torch.cuda.is_available():**检测当前系统是否支持 CUDA(即 GPU 加速),返回布尔值
cuda():将张量或模型迁移到 GPU 上进行计算(需 CUDA 可用)
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
device |
int 或 torch.device(可选) |
目标 GPU 设备(如 0 或 torch.device('cuda:0')) |
math.log():计算对数,支持自然对数(底数 e)或自定义底数
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
x |
float(必选) |
输入值(需 > 0) |
base |
float(可选) |
对数的底数(默认 e) |
len():返回对象的长度或元素个数(适用于字符串、列表、字典、集合等可迭代对象)
| 参数名 | 类型/可选值 | 描述 |
|---|---|---|
object |
可迭代对象(必选) | 输入对象(如 "hello"、[1, 2, 3]) |
python
#计算文本ppl
def calc_perplexity(sentence, model, vocab, window_size):
prob = 0
model.eval()
with torch.no_grad():
for i in range(1, len(sentence)):
start = max(0, i - window_size)
window = sentence[start:i]
x = [vocab.get(char, vocab["<UNK>"]) for char in window]
x = torch.LongTensor([x])
target = sentence[i]
target_index = vocab.get(target, vocab["<UNK>"])
if torch.cuda.is_available():
x = x.cuda()
pred_prob_distribute = model(x)[0][-1]
target_prob = pred_prob_distribute[target_index]
prob += math.log(target_prob, 10)
return 2 ** (prob * ( -1 / len(sentence)))Ⅷ、模型训练
代码运行流程 ⭐
python
train 方法流程
├── 1. 初始化训练参数
│ ├── 1.1 设置训练轮数: `epoch_num = 20`
│ ├── 1.2 设置批次大小: `batch_size = 64`
│ ├── 1.3 设置每轮样本数: `train_sample = 50000`
│ ├── 1.4 设置字符维度: `char_dim = 256`
│ └── 1.5 设置窗口大小: `window_size = 10`
│
├── 2. 加载词汇表和语料
│ ├── 2.1 构建词汇表: `vocab = build_vocab("vocab.txt")`
│ └── 2.2 加载语料: `corpus = load_corpus(corpus_path)`
│
├── 3. 构建模型
│ └── 3.1 构建语言模型: `model = build_model(vocab, char_dim)`
│
├── 4. 检查 GPU 可用性
│ └── 4.1 将模型移动到 GPU: `if torch.cuda.is_available(): model = model.cuda()`
│
├── 5. 初始化优化器
│ └── 5.1 使用 Adam 优化器: `optim = torch.optim.Adam(model.parameters(), lr=0.01)`
│
├── 6. 开始训练
│ └── 6.1 遍历每轮训练: `for epoch in range(epoch_num):`
│ ├── 6.1.1 设置模型为训练模式: `model.train()`
│ ├── 6.1.2 初始化损失列表: `watch_loss = []`
│ ├── 6.1.3 遍历每批次样本: `for batch in range(int(train_sample / batch_size)):`
│ │ ├── 6.1.3.1 构建训练样本: `x, y = build_dataset(batch_size, vocab, window_size, corpus)`
│ │ ├── 6.1.3.2 将数据移动到 GPU: `if torch.cuda.is_available(): x, y = x.cuda(), y.cuda()`
│ │ ├── 6.1.3.3 梯度归零: `optim.zero_grad()`
│ │ ├── 6.1.3.4 计算损失: `loss = model(x, y)`
│ │ ├── 6.1.3.5 反向传播: `loss.backward()`
│ │ └── 6.1.3.6 更新权重: `optim.step()`
│ ├── 6.1.4 计算平均损失: `print("第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))`
│ ├── 6.1.5 生成示例句子: `print(generate_sentence("让他在半年之前,就不能做出", model, vocab, window_size))`
│ └── 6.1.6 生成示例句子: `print(generate_sentence("李慕站在山路上,深深的呼吸", model, vocab, window_size))`
│
├── 7. 保存模型权重
│ └── 7.1 保存模型: `if save_weight: torch.save(model.state_dict(), model_path)`
│
└── 8. 返回
└── 8.1 返回: `return`① 初始化配置
**corpus_path:训练语料文件路径(如data/novel.txt),指向包含原始文本的文件,需通过load_corpus**函数加载文本,用于构建训练样本
**train_sample:**定义每个训练轮次(epoch)中使用的总样本数量
**epoch_num:设定训练轮次,每轮遍历train_sample**个样本(
**batch_size:**单次梯度更新的样本量,影响内存占用与训练稳定性。
**char_dim:**字符嵌入向量维度,决定模型对字符语义的编码能力
**window_size:**上下文窗口长度,控制模型单次可见的字符数
**vocab:**构建字符到索引的映射字典,含<UNK>处理未登录词
**corpus:**作为原始语料库,从中动态截取窗口生成训练样本(输入-目标对)
**optim:**从Pytorch库中加载的优化器
**torch.cuda.is_available():**检查当前系统是否支持 CUDA(即是否安装了 NVIDIA GPU 及配套驱动)。返回布尔值(True/False),用于判断能否使用 GPU 加速
**model.cuda():**将模型参数及缓冲区迁移到 GPU 显存中。若未指定设备,默认使用第一个可用 GPU(device=0)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
device |
int 或 torch.device |
None |
指定目标 GPU 设备(如 0、1 或 torch.device('cuda:0')) |
**torch.optim.Adam():**实现 Adam 优化算法,结合动量(Momentum)和自适应学习率(RMSProp)的优点,适用于大规模参数优化
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
params |
Iterable |
必填 | 待优化参数(如 model.parameters()) |
lr |
float |
0.001 |
学习率 |
betas |
Tuple[float, float] |
(0.9, 0.999) |
一阶(动量)和二阶(方差)衰减系数 |
eps |
float |
1e-8 |
数值稳定性常数,防止除零 |
weight_decay |
float |
0 |
L2 正则化系数(权重衰减) |
amsgrad |
bool |
False |
是否使用 AMSGrad 变体(改进梯度方差估计) |
**model.parameters():**返回模型所有可训练参数的生成器,用于优化器初始化或参数统计。递归遍历所有子模块(如卷积层、全连接层)的参数
python
def train(corpus_path, save_weight=True):
epoch_num = 20 #训练轮数
batch_size = 64 #每次训练样本个数
train_sample = 50000 #每轮训练总共训练的样本总数
char_dim = 256 #每个字的维度
window_size = 10 #样本文本长度
vocab = build_vocab("vocab.txt") #建立字表
corpus = load_corpus(corpus_path) #加载语料
model = build_model(vocab, char_dim) #建立模型
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=0.01) #建立优化器
print("文本词表模型加载完毕,开始训练")② 模型训练主流程
**loss:**损失值
**optim:**从Pytorch库中加载的优化器
**watch_loss:**记录当前轮次所有批次的损失值,用于计算平均训练损失
**range():**在 Python 中生成整数序列,常用于循环控制或列表生成。
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
start |
int |
0 |
起始值(包含) |
stop |
int |
必填 | 结束值(不包含) |
step |
int |
1 |
步长,可为负数(反向序列) |
**model.train():**将模型设置为训练模式,启用 Dropout 和 BatchNorm 的训练逻辑(如按批次统计均值和方差)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
mode |
bool |
True |
True 为训练模式,False 为评估模式 |
**optim.zero_grad():**将模型设置为训练模式,启用 Dropout 和 BatchNorm 的训练逻辑(如按批次统计均值和方差)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
mode |
bool |
True |
True 为训练模式,False 为评估模式 |
**backward():**反向传播计算梯度,基于计算图自动求导
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
gradient |
Tensor |
None |
指定梯度张量(非标量输出时需手动传入) |
**optim.step():**根据梯度更新模型参数,执行优化算法(如 SGD、Adam)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
closure |
callable |
None |
重新计算损失的闭包函数(如 LBFGS 优化器需使用) |
**列表.append():**在列表末尾添加一个元素(直接修改原列表)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
element |
任意类型 | 必填 | 要添加的元素 |
**item():**从张量中提取 Python 标量值(仅适用于单元素张量)
**np.mean():**计算数组的平均值,可指定轴和数据类型
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
a |
array_like |
必填 | 输入数组 |
axis |
int/tuple |
None |
计算均值的轴 |
dtype |
data-type |
None |
输出数据类型 |
python
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, window_size, corpus) #构建一组训练样本
if torch.cuda.is_available():
x, y = x.cuda(), y.cuda()
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
print(generate_sentence("让他在半年之前,就不能做出", model, vocab, window_size))
print(generate_sentence("李慕站在山路上,深深的呼吸", model, vocab, window_size))③ 模型保存
**save_weight:**布尔标志,控制是否保存训练后的模型权重。若为False,训练完成后直接返回
**base_name:**文件名(含拓展名)
**model_path:**模型保存的路径
**os.path.basename():**从文件路径中提取文件名(含扩展名)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
path |
str |
必填 | 文件路径(如 "/data/novel.txt") |
**replace():**替换字符串中的子串,或文件扩展名替换
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
old |
str |
必填 | 被替换的子串 |
new |
str |
必填 | 替换后的子串 |
count |
int |
-1 |
替换次数(默认全部替换) |
**os.path.join():**拼接多个路径组件为完整路径(自动处理斜杠)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
*paths |
str |
必填 | 多个路径组件(如 "model", "novel.pth") |
**torch.save():**保存模型权重或张量到文件(支持 .pth 格式)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
obj |
dict/Tensor |
必填 | 待保存对象(如 model.state_dict()) |
f |
str/IO |
必填 | 文件路径或文件句柄 |
**model.state_dict():**返回模型参数的字典(键为层名,值为权重张量)
python
if not save_weight:
return
else:
base_name = os.path.basename(corpus_path).replace("txt", "pth")
model_path = os.path.join("model", base_name)
torch.save(model.state_dict(), model_path)
return④ 完整代码
python
def train(corpus_path, save_weight=True):
epoch_num = 20 #训练轮数
batch_size = 64 #每次训练样本个数
train_sample = 50000 #每轮训练总共训练的样本总数
char_dim = 256 #每个字的维度
window_size = 10 #样本文本长度
vocab = build_vocab("vocab.txt") #建立字表
corpus = load_corpus(corpus_path) #加载语料
model = build_model(vocab, char_dim) #建立模型
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=0.01) #建立优化器
print("文本词表模型加载完毕,开始训练")
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, window_size, corpus) #构建一组训练样本
if torch.cuda.is_available():
x, y = x.cuda(), y.cuda()
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
print(generate_sentence("让他在半年之前,就不能做出", model, vocab, window_size))
print(generate_sentence("李慕站在山路上,深深的呼吸", model, vocab, window_size))
if not save_weight:
return
else:
base_name = os.path.basename(corpus_path).replace("txt", "pth")
model_path = os.path.join("model", base_name)
torch.save(model.state_dict(), model_path)
returnⅨ、整体代码
python
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import re
"""
基于pytorch的LSTM语言模型
"""
class LanguageModel(nn.Module):
def __init__(self, input_dim, vocab):
super(LanguageModel, self).__init__()
self.embedding = nn.Embedding(len(vocab), input_dim)
self.layer = nn.LSTM(input_dim, input_dim, num_layers=1, batch_first=True)
self.classify = nn.Linear(input_dim, len(vocab))
self.dropout = nn.Dropout(0.1)
self.loss = nn.functional.cross_entropy
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.layer(x) #output shape:(batch_size, sen_len, input_dim)
y_pred = self.classify(x) #output shape:(batch_size, sen_len,vocab_size)
if y is not None:
return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))
else:
return torch.softmax(y_pred, dim=-1)
#加载字表
def build_vocab(vocab_path):
vocab = {"<pad>":0}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
char = line[:-1] #去掉结尾换行符
vocab[char] = index + 1 #留出0位给pad token
return vocab
#加载语料
def load_corpus(path):
corpus = ""
with open(path, encoding="gbk") as f:
for line in f:
corpus += line.strip()
return corpus
#随机生成一个样本 采样部分
#从文本中截取随机窗口,前n个字作为输入,最后一个字作为输出
def build_sample(vocab, window_size, corpus):
start = random.randint(0, len(corpus) - 1 - window_size)
end = start + window_size
window = corpus[start:end]
target = corpus[start + 1:end + 1] #输入输出错开一位
# print(window, target)
x = [vocab.get(word, vocab["<UNK>"]) for word in window] #将字转换成序号
y = [vocab.get(word, vocab["<UNK>"]) for word in target]
return x, y
#建立数据集
#sample_length 输入需要的样本数量。需要多少生成多少
#vocab 词表
#window_size 样本长度
#corpus 语料字符串
def build_dataset(sample_length, vocab, window_size, corpus):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, window_size, corpus)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)
#建立模型
def build_model(vocab, char_dim):
model = LanguageModel(char_dim, vocab)
return model
#文本生成测试代码
def generate_sentence(openings, model, vocab, window_size):
reverse_vocab = dict((y, x) for x, y in vocab.items())
model.eval()
with torch.no_grad():
pred_char = ""
#生成了换行符,或生成文本超过30字则终止迭代
while pred_char != "\n" and len(openings) <= 30:
openings += pred_char
x = [vocab.get(char, vocab["<UNK>"]) for char in openings[-window_size:]]
x = torch.LongTensor([x])
if torch.cuda.is_available():
x = x.cuda()
y = model(x)[0][-1]
index = sampling_strategy(y)
pred_char = reverse_vocab[index]
return openings
def sampling_strategy(prob_distribution):
if random.random() > 0.1:
strategy = "greedy"
else:
strategy = "sampling"
if strategy == "greedy":
return int(torch.argmax(prob_distribution))
elif strategy == "sampling":
prob_distribution = prob_distribution.cpu().numpy()
return np.random.choice(list(range(len(prob_distribution))), p=prob_distribution)
#计算文本ppl
def calc_perplexity(sentence, model, vocab, window_size):
prob = 0
model.eval()
with torch.no_grad():
for i in range(1, len(sentence)):
start = max(0, i - window_size)
window = sentence[start:i]
x = [vocab.get(char, vocab["<UNK>"]) for char in window]
x = torch.LongTensor([x])
target = sentence[i]
target_index = vocab.get(target, vocab["<UNK>"])
if torch.cuda.is_available():
x = x.cuda()
pred_prob_distribute = model(x)[0][-1]
target_prob = pred_prob_distribute[target_index]
prob += math.log(target_prob, 10)
return 2 ** (prob * ( -1 / len(sentence)))
def train(corpus_path, save_weight=True):
epoch_num = 20 #训练轮数
batch_size = 64 #每次训练样本个数
train_sample = 50000 #每轮训练总共训练的样本总数
char_dim = 256 #每个字的维度
window_size = 10 #样本文本长度
vocab = build_vocab("vocab.txt") #建立字表
corpus = load_corpus(corpus_path) #加载语料
model = build_model(vocab, char_dim) #建立模型
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=0.01) #建立优化器
print("文本词表模型加载完毕,开始训练")
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, window_size, corpus) #构建一组训练样本
if torch.cuda.is_available():
x, y = x.cuda(), y.cuda()
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
print(generate_sentence("让他在半年之前,就不能做出", model, vocab, window_size))
print(generate_sentence("李慕站在山路上,深深的呼吸", model, vocab, window_size))
if not save_weight:
return
else:
base_name = os.path.basename(corpus_path).replace("txt", "pth")
model_path = os.path.join("model", base_name)
torch.save(model.state_dict(), model_path)
return
if __name__ == "__main__":
# build_vocab_from_corpus("corpus/all.txt")
train("corpus.txt", False)
五、自编码模型结构:Encoder - Decoder(编码器 - 解码器)结构
Encoder - Decoder 结构是一种基于神经网络完成 seq2seq 任务的常用方案
Encoder 将输入转化为向量或矩阵,其中包含了输入中的信息
Decoder 利用过Encoder后转化的向量或矩阵包含的这些信息输出目标值
Encoder - Decoder 结构旨在将一个输入序列转换为另一个输出序列,输入和输出序列的长度可以不同。该结构的核心思想 是:通过编码器将输入序列的信息进行编码和压缩,得到一个固定长度的上下文向量,然后解码器根据这个上下文向量生成目标输出序列

原理图
Encoder - Decoder 结构的运行流程:
① 输入信息 ------> 过Embedding层编码 ------> 过若干层的神经网络 ------> 得到一些向量 / 矩阵
② 将由 编码器Encoder 得到的这些向量 / 矩阵 ,送入专门的 解码器Decoder
③ 解码器 Decoder: 先传入一个起始符,由起始符预测第一个字,再由前几个字预测后一个字,不断迭代,预测出最大长度的序列


六、Attention 注意力机制
1.基本概念
在处理大量信息时,人类大脑会自动将注意力集中在重要的部分,忽略次要信息。 注意力机制在深度学习中模拟了这一过程,允许模型在处理输入数据时,动态地分配不同的注意力权重给输入的各个部分,从而有选择性地关注重要信息,提高模型的性能和效率。
Attention的本质可以看作是一种权重


2.Soft Attention机制 ⭐
软注意力(Soft Attention) :计算得到的注意力权重是一个概率分布,模型可以同时关注输入的多个部分,每个部分都有一定的权重贡献。软注意力具有可微性,因此可以通过反向传播算法进行端到端的训练。

公式
Ⅰ、计算相似度
计算查询(Query) 和 键(Key)之间的相似度,通过 f(qi, kj) 衡量查询和键之间的相关性:

其中,q_i 是查询向量,k_j是键向量,f是相似度函数,常见的有点积、加性(MLP)等。
Ⅱ、归一化
使用Softmax函数将相似度归一化为权重,确保权重之和为 1,从而表示每个键的重要性:

其中,α_ij 表示第i 个查询对第 j 个键的注意力权重
Ⅲ、加权求和
将权重与值(Value)向量加权求和,得到上下文向量c_i,它融合了所有键的信息,但更关注与查询相关的部分:

其中,α_ij 表示第i 个查询对第 j 个键的注意力权重,v_j 是值向量,c_i 是最终的上下文向量
代码实现
Ⅰ、初始化模块
代码运行流程
python
AttnDecoderRNN.__init__(hidden_size, output_size, dropout_p, max_length)
├── super(AttnDecoderRNN, self).__init__() # 调用父类的初始化方法
├── self.hidden_size = hidden_size # 设置隐藏层大小
├── self.output_size = output_size # 设置输出层大小
├── self.dropout_p = dropout_p # 设置 Dropout 概率
├── self.max_length = max_length # 设置最大序列长度
├── self.embedding = nn.Embedding( # 定义嵌入层
│ self.output_size, self.hidden_size)
├── self.attn = nn.Linear( # 定义注意力线性层
│ self.hidden_size * 2, self.max_length)
├── self.attn_combine = nn.Linear( # 定义注意力组合线性层
│ self.hidden_size * 2, self.hidden_size)
├── self.dropout = nn.Dropout(self.dropout_p) # 定义 Dropout 层
├── self.gru = nn.GRU( # 定义 GRU 层
│ self.hidden_size, self.hidden_size)
└── self.out = nn.Linear( # 定义输出线性层
self.hidden_size, self.output_size)**self.hidden_size:**隐藏层的大小,表示GRU单元中隐藏状态的维度。它决定了模型在处理序列数据时,每个时间步的隐藏状态的维度大小
**self.output_size:**输出层的大小,通常表示词汇表的大小。它决定了模型输出的维度,即模型最终预测的词汇数量
**self.dropout_p:**Dropout层的丢弃概率,用于防止模型过拟合。在训练过程中,Dropout层会随机将一些神经元的输出设置为0,概率由 dropout_p决定
**self.max_length:**输入序列的最大长度,通常用于限制模型处理的序列长度
**self.embedding:**嵌入层,用于将输入的词汇索引映射到连续的稠密向量空间中。
**self.attn:**线性层,用于计算注意力权重。它的输入是隐藏状态和嵌入向量的拼接,输出是注意力权重,维度为 max_length
**self.attn_combine:**另一个线性层,用于将注意力权重与嵌入向量结合,生成新的输入向量。它的输入是隐藏状态和嵌入向量的拼接,输出是新的输入向量,维度为hidden_size
**self.dropout:**Dropout层,用于在训练过程中随机丢弃一些神经元的输出,以防止过拟合
**self.gru:**GRU层,用于处理序列数据。它的输入和输出维度都是hidden_size
**self.out:**线性层,用于将GRU的输出映射到词汇表的大小,即output_size,以便进行最终的预测
F:torch.nn.functional 模块的别名。这是一个包含了许多神经网络相关函数的模块,例如激活函数(如 F.relu、F.sigmoid)、损失函数(如 F.cross_entropy)、池化操作(如 F.max_pool2d)等。
**nn.Embedding():**将离散的索引(如单词索引)映射到连续的稠密向量空间中,常用于自然语言处理(NLP)中的词嵌入
| 数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
num_embeddings |
int |
无 | 嵌入字典的大小,即不同类别的总数(如词汇表大小)。 |
embedding_dim |
int |
无 | 每个嵌入向量的维度。 |
padding_idx |
int |
None |
如果指定,该索引对应的嵌入向量在训练中不会被更新,通常用于填充。 |
max_norm |
float |
None |
如果指定,嵌入向量的范数超过该值时会重新归一化。 |
norm_type |
float |
2.0 |
用于计算范数的类型(默认为 L2 范数)。 |
scale_grad_by_freq |
bool |
False |
如果为 True,梯度会根据索引的频率进行缩放。 |
sparse |
bool |
False |
如果为 True,梯度会变为稀疏张量,适用于大型词汇表。 |
_weight |
Tensor |
None |
用于初始化嵌入矩阵的权重。 |
**nn.Linear():**对输入数据进行线性变换,常用于神经网络的全连接层。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
in_features |
int |
无 | 输入特征的数量。 |
out_features |
int |
无 | 输出特征的数量。 |
bias |
bool |
True |
如果为 True,则添加偏置项。 |
device |
device |
None |
指定张量所在的设备(如 cpu 或 cuda)。 |
dtype |
dtype |
None |
指定张量的数据类型。 |
**nn.Dropout():**在训练过程中随机将输入张量的部分元素置零,用于防止过拟合。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
p |
float |
0.5 |
元素被置零的概率。 |
inplace |
bool |
False |
如果为 True,则直接在输入张量上进行修改,否则返回新的张量。 |
**nn.GRU():**门控循环单元(GRU),一种改进的 RNN 结构,用于处理序列数据,能够捕捉长距离依赖关系。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input_size |
int |
无 | 输入特征的维度。 |
hidden_size |
int |
无 | 隐藏状态的维度。 |
num_layers |
int |
1 |
GRU 的层数。 |
bias |
bool |
True |
如果为 True,则添加偏置项。 |
batch_first |
bool |
False |
如果为 True,则输入和输出的形状为 (batch_size, seq_len, feature)。 |
dropout |
float |
0.0 |
如果非零,则在除最后一层外的每层 GRU 后添加 Dropout 层。 |
bidirectional |
bool |
False |
如果为 True,则使用双向 GRU。 |
python
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)Ⅱ、前向传播
代码运行流程
python
forward(input, hidden, encoder_outputs)
├── embedded = self.embedding(input).view(1, 1, -1) # 将输入嵌入为稠密向量
├── embedded = self.dropout(embedded) # 对嵌入向量应用 Dropout
├── attn_weights = F.softmax( # 计算注意力权重
│ self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
├── attn_applied = torch.bmm( # 应用注意力权重到编码器输出
│ attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
├── output = torch.cat((embedded[0], attn_applied[0]), 1) # 拼接嵌入向量和注意力向量
├── output = self.attn_combine(output).unsqueeze(0) # 通过线性层组合
├── output = F.relu(output) # 应用 ReLU 激活函数
├── output, hidden = self.gru(output, hidden) # 通过 GRU 层
├── output = F.log_softmax(self.out(output[0]), dim=1) # 应用 log_softmax 输出概率
└── return output, hidden, attn_weights # 返回输出、隐藏状态和注意力权重**input:**当前时间步的输入,通常是一个单词的索引或嵌入向量。
hidden: 当前时间步的隐藏状态,通常是从上一个时间步传递过来的。
**encoder_outputs:**编码器的输出,通常是一个包含所有时间步的隐藏状态的张量,用于计算注意力权重。
embedded: 输入的嵌入表示。
**attn_weights:**当前时间步对编码器输出的注意力权重,通过F.softmax函数计算得出
**attn_applied:**注意力权重与编码器输出的加权和,表示当前时间步的上下文信息
output: 将嵌入向量和上下文向量拼接后的结果,通过torch.cat((embedded[0], attn_applied[0]), 1)实现。
F:****torch.nn.functional 模块的别名 。这是一个包含了许多神经网络相关函数的模块,例如激活函数(如 F.relu、F.sigmoid)、损失函数(如 F.cross_entropy)、池化操作(如 F.max_pool2d)等。
**.view():**用于改变张量的形状,而不改变其数据。返回一个新的张量,与原始张量共享数据存储。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
*shape |
int 或 tuple |
无 | 目标形状,可以是一个或多个整数。总元素数必须与原始张量相同。 |
-1 |
int |
无 | 自动计算该维度的大小,确保总元素数不变。 |
**torch.cat():**将给定的张量序列沿着指定的维度连接起来
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
tensors |
sequence of tensors |
无 | 要连接的张量序列。张量必须在除了连接维度以外的所有维度上大小匹配。 |
dim |
int |
0 |
要连接的维度。如果为负数,表示从最后一个维度开始的索引。 |
out |
Tensor |
None |
输出张量。如果为 None,则使用新分配的张量。 |
**torch.bmm():**执行批量矩阵乘法,用于处理两个 3D 张量的矩阵乘法。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
Tensor |
无 | 第一个 3D 张量,形状为 (batch_size, n, m)。 |
mat2 |
Tensor |
无 | 第二个 3D 张量,形状为 (batch_size, m, p)。 |
out |
Tensor |
None |
输出张量。如果为 None,则使用新分配的张量。 |
**unsqueeze():**在指定位置插入一个大小为 1 的维度,扩展张量的维度。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
Tensor |
无 | 输入张量。 |
dim |
int |
无 | 插入维度的索引位置。 |
out |
Tensor |
None |
输出张量。如果为 None,则使用新分配的张量。 |
python
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
# 通过解码过程算出
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1) #1, max_length
# 将对应位置的权重乘在对应向量上
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
# 将context vector和attention vector拼接
output = torch.cat((embedded[0], attn_applied[0]), 1)
# 加一层线性层进行输出
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weightsⅢ、隐藏状态(中间层)初始化
代码运行流程
python
initHidden(self)
├── 调用 torch.zeros(1, 1, self.hidden_size, device=device)
│ ├── 创建一个形状为 (1, 1, self.hidden_size) 的张量
│ ├── 将张量的所有元素初始化为 0
│ └── 将张量存储在指定的设备(CPU 或 GPU)上
└── 返回初始化后的张量**hidden_size:**隐藏层的维度,用于定义模型的隐藏状态大小。
**device:**用于指定张量存储和计算设备的参数,支持 CPU 或 GPU。
**torch.zeros():**用于创建一个全零张量,张量的形状由参数指定,数据类型和设备可以自定义。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
size |
int 或 tuple |
无 | 定义输出张量的形状。可以是一个整数或一个包含多个整数的元组。 |
out |
Tensor |
None |
指定输出的张量。如果指定,函数会将结果存储在这个张量中。 |
dtype |
torch.dtype |
None |
指定返回张量的数据类型。如果未指定,使用默认值(通常为 torch.float32)。 |
layout |
torch.layout |
torch.strided |
指定返回张量的内存布局。默认为 strided(密集型张量)。 |
device |
torch.device |
None |
指定返回张量所处的设备(如 cpu 或 cuda)。如果未指定,使用默认设备。 |
requires_grad |
bool |
False |
指定返回的张量是否需要梯度。默认为 False。 |
1,1,hidden_size: 表示创建一个三维张量,其形状为 (1×1×hidden_size)。
python
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)Ⅳ、完整代码
代码运行流程
python
AttnDecoderRNN
├── __init__
│ ├── 初始化参数
│ │ ├── hidden_size
│ │ ├── output_size
│ │ ├── dropout_p
│ │ └── max_length
│ ├── 定义网络层
│ │ ├── embedding
│ │ ├── attn
│ │ ├── attn_combine
│ │ ├── dropout
│ │ ├── gru
│ │ └── out
│ └── initHidden
│ └── 初始化隐藏状态
└── forward
├── 输入处理
│ ├── embedded = embedding(input)
│ └── embedded = dropout(embedded)
├── 计算注意力权重
│ ├── attn_weights = softmax(attn(cat(embedded, hidden)))
│ └── attn_applied = bmm(attn_weights, encoder_outputs)
├── 拼接向量
│ └── output = cat(embedded, attn_applied)
├── 线性变换
│ └── output = attn_combine(output)
├── 激活函数
│ └── output = relu(output)
├── GRU处理
│ └── output, hidden = gru(output, hidden)
├── 输出处理
│ └── output = log_softmax(out(output))
└── 返回结果
└── return output, hidden, attn_weights**torch.device():**用于指定张量或模型所在的设备(如 CPU 或 GPU)。设备可以是 cpu 或 cuda,并且可以指定具体的 GPU 编号。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
device |
str 或 torch.device |
无 | 指定设备的字符串或设备对象。可以是 "cpu"、"cuda" 或 "cuda:X"(X 为 GPU 编号)。 |
**torch.cuda.is_available():**用于检查当前系统是否支持 CUDA(Compute Unified Device Architecture)。CUDA 是 NVIDIA 提供的并行计算平台和编程模型,能够利用 GPU 加速计算。该函数返回一个布尔值
python
from __future__ import unicode_literals, print_function, division
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
# softmax归一化函数不会改变向量的形状
attn_weights = F.softmax(
# 通过解码过程算出
# 1 × 256 cat 1 × 256 = 1 × 512
# attn:512 × max_length
# (1, 512) × (512, max_length) = 1 × max_length
# 这个1 × max_length的矩阵,就是原始文本中每一个字的attn_weights
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1) #1, max_length
# 将对应位置的权重乘在过encoder后每个字的对应向量上
# 得到权重后进行加权
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
# 将context vector和attention vector拼接
output = torch.cat((embedded[0], attn_applied[0]), 1)
# 加一层线性层进行输出
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)3.Attention可视化
Attention weight 权重可视化: 矩阵中每个字对于其他每个字的预测概率值越高图像点越接近于白色,预测概率值越低图像点越接近于黑色

4.Attention机制的应用
判断情感倾向

一句话的文本中每个词对于结果的影响是不同的,可以认为他们应当被赋予不同的权重,这种权重 也可以称为:attention
5.Attention的思想
将输入看做 key, value 组成的键值对,待输出的信息为query
编码器(Encoder):
- 输入:由**
key** 和**query**组成的键值对。- 通过
word2id和embedding层处理,生成**key**。- 编码器将输入序列编码为一系列**
key**向量。解码器(Decoder):
- 输入:
query,通常是解码器当前时间步的输入(例如,上一个时间步的输出)。- 通过
Embedding + word2id层处理,生成query向量。软注意力机制:
- 计算注意力权重:
- 使用**
key** 和**query** 进行交互,通常通过点积或其他相似度度量计算得分。- 将得分通过Softmax函数归一化,得到注意力权重。
- 生成**
value** :
- 使用注意力权重对**
key** 进行加权求和,得到**value**(上下文向量)。- 将**
value**传递给解码器,用于生成当前时间步的输出。输出:
- 解码器结合**
value** 和**query**,生成当前时间步的输出。

- 编码器生成**
key** ,解码器生成**query**。- **
key和query**进行交互,计算注意力权重。- 使用注意力权重生成**
value**。- **
value**被传递给解码器,用于生成输出。

在机器翻译任务中,key和value一致
6.attention的种类
Ⅰ、soft-attention

Ⅱ、hard attention
在one-hot的基础上,将attention 向量转换成one-hot形式

Ⅲ、local attention
Local Attention 结合了 Soft Attention 的可微性和 Hard Attention 的计算效率,使用部分隐向量计算attention ,Local Attention 只关注输入序列的一个局部窗口,从而减少计算量并提高效率

7.Teacher Forcing
训练过程:
s1: x1, x2, x3 ... xn, <sos> - > y1
s2: x1, x2, x3 ... xn, <sos>, y1 - > y2
s3: x1, x2, x3 ... xn, <sos>, y1, y2 -> y3
不管前文的预测结果,在预测下一个字时强制使用真实的标签(红字部分使用真实标签 ),叫做:Teacher Forcing
用前一个预测结果来预测下一个字的结果,则称作:非Teacher Forcing
现在我们普遍使用 Teacher Forcing 的做法,因为效率较高,忽略其信息泄露(告知了真实标签)的问题(exposure bias),在训练数据足够多时,Teacher Forcing 信息泄露的影响可以忽略不计
python
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device=device)
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# Teacher forcing: Feed the target as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length七、self attention(自注意力机制)
Self-Attention(自注意力机制)是一种在自然语言处理等领域广泛应用的技术,用于计算文本序列中每个位置与其他位置之间的关联程度
1.核心原理
通过计算输入序列中各个元素之间的相关性,来动态地分配每个元素在不同位置的重要性权重。它能够在处理序列数据时,自动捕捉长序列中的依赖关系,而无需像传统的循环神经网络(RNN)或卷积神经网络(CNN)那样依赖于顺序处理或局部卷积操作。简单来说,就是让模型能够在处理某个位置的信息时,同时考虑到序列中其他位置的信息,从而更好地理解文本的全局语义
2.存在问题
在训练过程中,Self-Attention 会计算输入序列中各个位置之间的关联
Self - Attention可能导致信息泄露,一是训练数据隐私泄露,因样本信息关联与过拟合,使敏感信息可被攻击者推断;二是语义信息泄露,表现为跨样本信息传播及对对抗攻击敏感。可通过隐私保护技术、改进模型结构及构建安全环境来缓解。
3.Encoder - Decoder架构

架构组成
**Encoder(编码器):**主要负责对输入序列进行编码,将输入数据(如文本句子、图像等)映射到一个固定长度的语义向量表示。它会对输入信息进行压缩和抽象,提取其中的关键特征,忽略一些无关紧要的细节。在处理文本时,编码器会依次读取每个单词或字符,通过神经网络层(如循环神经网络 RNN、长短期记忆网络 LSTM、门控循环单元 GRU 或 Transformer 中的 Self-Attention 等)来学习输入序列的语义结构和长期依赖关系,最终输出一个能代表整个输入序列的语义向量。
**Decoder(解码器):**以编码器输出的语义向量为基础,逐步生成目标序列。在生成过程中,解码器会根据已经生成的部分输出以及编码器的语义向量,预测下一个可能的输出元素。它同样使用神经网络层来进行计算,通过不断地预测和输出,逐步构建出完整的目标序列,如生成翻译后的句子、图像描述等。
工作原理
编码阶段: 输入序列依次进入编码器,编码器的每一步都会根据当前输入和之前的隐藏状态更新隐藏状态,最终得到一个综合了整个输入序列信息的固定长度向量表示,这个向量包含了输入序列的语义、结构等关键信息。
解码阶段: 解码器从一个初始状态开始,将编码器的输出向量作为初始输入,结合上一步的隐藏状态和输出,预测当前位置的输出。然后将当前的输出和隐藏状态作为下一次预测的输入,不断重复这个过程,直到生成完整的目标序列。在生成过程中,通常会使用一些概率分布来选择最可能的输出元素,例如通过 Softmax 函数计算每个可能输出的概率,选择概率最高的元素作为当前的输出。
现在基本使用Decoder-Only结构

八、改良方式:Mask Attention(掩码注意力机制)
1.基本概念
在标准的注意力机制里,模型会计算输入序列中每个元素与其他元素之间的相关性,进而为每个元素分配注意力权重。然而,在某些场景下,我们不希望模型关注输入序列中的某些部分,比如在处理序列填充(padding)、生成序列时避免看到未来信息等情况。Mask Attention 就是为解决这类问题而设计的,它通过掩码(mask) 来限制注意力的计算范围,使得模型在计算注意力权重时忽略特定位置的元素。
规避了从前直接"剧透"看到后面的问题
2.Mask步骤
① 先进行Mask对后面的预测值置为无效
在计算注意力分数之后,应用预先定义好的掩码矩阵。掩码矩阵是一个与注意力分数矩阵形状相同的二进制矩阵,其中值为 0 的位置表示该位置的注意力分数需要被保留,值为 1 的位置表示该位置的注意力分数需要被屏蔽。通常的做法是将掩码位置的注意力分数设置为一个非常大的负数(如负无穷),这样在后续使用 softmax 函数进行归一化时,这些位置的注意力权重就会趋近于 0。

② 再过softmax层,将经过Mask后的矩阵进行归一化

3.通过Mask控制训练方式
根据Mask的形状不同,将训练方式更改,用同一套transformer的架构
如果Mask形状为空 ,完全能看到自身,则训练方式为:Encoder only**【Bert】**
如果Mask形状为上三角 ,则训练方式为:Decoder only**【GPT】**
如果Mask形状为首句话可以看到自己的整体,第二句只能看到首句话整体和第二句话的上三角矩阵 ,则训练方式为:Encoder - Decoder**【Soft Attention】**

如果为了节省资源,多个文本进行拼接一起送入模型进行mask,每句话与前一句话无关,且每句话中的每个字mask形状都是上三角,即只能看到前面的字,则Mask的形状应该是沿主对角线的锯齿块形状,锯齿块部分代表模型可以看到 的文本信息,也就是沿对角线有多个Decorder-only矩阵,如图:

三者的区别只是在于Mask的形状不同
九、文本生成任务的评价指标和常见问题
1.常见的评价指标
Ⅰ、BLEU
① 基本概念
BLEU 是由 Kishore Papineni 等人在 2002 年提出的一种用于评估机器翻译质量的指标。其核心思想是: 比较机器翻译生成的译文与一组参考译文之间的相似度,通过统计 n - 元语法(n - gram)的匹配情况来衡量翻译的准确性。
② 计算方法
n - 元语法匹配 :统计生成文本中与参考文本匹配的 n-gram 数量,并计算其占生成文本总 n-gram 的比例
修正的 n - 元语法精度 :为了避免重复匹配的影响,需要对 n - 元语法的匹配次数进行修正。修正的方法是取每个 n - 元语法在参考译文中出现的最大次数与在生成译文中出现次数的最小值。
几何平均 :计算不同阶 n - 元语法的修正精度的几何平均值,并根据阶数赋予不同的权重。通常,阶数越高,权重越低。
长度惩罚 :为了惩罚生成译文过短的情况,引入长度惩罚因子,该因子与生成译文和参考译文的长度比例有关。

最终的 BLEU 得分是经过长度惩罚后的 n - 元语法精度的几何平均值,取值范围在 0 到 1 之间,得分越高表示翻译质量越好。
③ 优缺点
优点:计算简单、速度快,可以快速评估大量翻译结果的质量;具有一定的客观性,不依赖于人工主观判断。
缺点 :BLEU 得分与人类对翻译质量的主观评价存在一定差距,它更侧重于词汇层面的匹配,而忽略了语义(不考虑语义信息)和语法的正确性;对短文本敏感,可能因重复词导致高分(需结合修正机制)
Ⅱ、ROUGE
① 基本概念
ROUGE 是由 Chin - Yew Lin 在 2004 年提出的一组用于评估文本摘要质量的指标。它主要关注生成摘要与参考摘要之间的重叠程度,通过计算召回率来衡量摘要的质量。
② 计算方法
ROUGE 有多种变体,常见的有 ROUGE - N、ROUGE - L 和 ROUGE - S 等。
ROUGE - N :与 BLEU 类似,统计生成摘要和参考摘要中 n - 元语法的重叠情况,计算召回率。**例如:**ROUGE - 1 表示一元语法的召回率,ROUGE - 2 表示二元语法的召回率。

ROUGE - L :基于最长公共子序列(LCS)来计算召回率,它考虑了生成摘要和参考摘要中单词的顺序信息,更能反映摘要的语义连贯性。

ROUGE - S :考虑了 skip - bigram(跳过的二元语法)的重叠情况,能够捕捉到单词之间的非连续关系。
③ 优缺点
优点:ROUGE 指标在文本摘要任务中与人类的主观评价具有较高的相关性,能够较好地反映摘要的内容完整性和信息覆盖率;可以根据不同的任务需求选择不同的 ROUGE 变体。
缺点:ROUGE 主要关注文本的重叠程度,对于摘要的语法正确性、可读性和连贯性等方面的评估能力有限;计算复杂度相对较高,尤其是 ROUGE - L 需要计算最长公共子序列。
Ⅲ、应用场景
BLEU :主要应用于机器翻译任务,用于评估不同翻译模型或翻译系统的性能,帮助研究人员和开发者选择最优的翻译方案。
ROUGE :广泛应用于文本摘要任务,包括自动文本摘要、新闻摘要等领域,用于评估生成摘要的质量,指导摘要算法的优化和改进。
Ⅳ、BLEU 与 ROUGE 对比
| 指标 | 侧重点 | 适用任务 | 优势 | 局限性 |
|---|---|---|---|---|
| BLEU | 精确率(Precision) | 机器翻译、代码生成 | 计算高效,标准化程度高 | 忽略语义,对短文本敏感 |
| ROUGE | 召回率(Recall) | 文本摘要、问答 | 捕捉信息完整性,适合长文本 | 忽略同义词,依赖参考文本质量 |
2.常见问题
语言模型文本生成结果有时会出现段落不断重复 的现象【因为有些词会同时出现,导致互相引用的现象不断出现】
解决这个问题:① 改进模型本身 ② 选择合适的采样策略
十、采样策略相关参数
1.Beam Size(束宽)
含义 :Beam Size 是**束搜索(Beam Search)**算法中的一个关键参数。束搜索是一种启发式搜索算法,用于在序列生成任务(如机器翻译、文本生成)中寻找最优的输出序列。束宽指的是在每一步搜索过程中,保留的候选序列的数量。
Beam Seach(束搜索)算法的时间复杂度取决于**Beam Size(束宽)**的大小
作用机制 :在生成序列的每一个时间步,模型会计算所有可能的下一个词的概率。普通的贪心搜索会在每一步都选择概率最高的词,但这样可能会错过全局最优解。而束搜索会在每一步保留概率最高的 Beam Size 个候选序列。随着生成过程的推进,这些候选序列会不断扩展,每一步都会根据新生成的词更新候选序列的概率,最终从所有候选序列中选择概率最高的作为最终输出。
影响: Beam Size数目与效果成正比,但与计算复杂度及内存开销成反比,较大的 Beam Size 可以增加找到更优序列的可能性,因为它考虑了更多的候选路径,但会增加计算复杂度和内存开销;较小的 Beam Size 则会减少计算量,但可能会错过一些潜在的好序列,导致生成结果的质量下降。

2.Temperature(温度)
输出每个字的概率分布时,通过调整温度参数T ,对softmax****部分做特殊处理
temperature越大,结果越随机;反之则越固定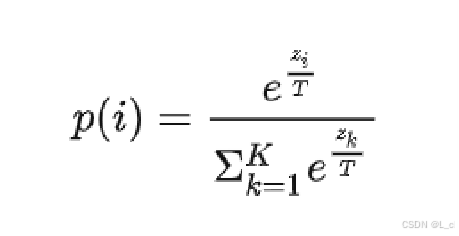
含义:Temperature 用于控制生成文本时的随机性程度,它是一个大于 0 的实数,通常用于 softmax 函数中对模型输出的 logits(未归一化的概率得分)进行调整。
作用机制 :在生成下一个词时,模型会输出每个词的 logits,通过 softmax 函数将其转换为概率分布。Temperature 参数通过对 logits 进行缩放来改变这个概率分布的形状,公式为: 
当 Temperature 较小 时(接近 0),概率分布会变得更尖锐,高概率的词被选中的可能性大大增加,生成的文本更加确定、保守;
当 Temperature 较大 时,概率分布会变得更平滑,各个词被选中的概率差异变小,生成的文本更具随机性和多样性。
应用场景 :在需要生成规范、准确文本的场景,如正式文档撰写、翻译,可使用较小 的 Temperature;在需要创意和多样性的场景,如故事创作、诗歌生成,可使用较大的 Temperature。
一般在实际使用中,设置为 0.7 ~ 1.5 之间

3.Top-P / Top-K
Top-K 采样
采样时从概率最高的K个字中选择
含义 :Top K 是一种采样策略,在生成下一个词时,只考虑概率最高的 K 个词,将其他词的概率设为 0,然后在这 K 个词中进行采样。
作用机制:模型在每个时间步输出所有可能词的概率分布后,对这些概率进行排序,选取概率最高的 K 个词构成一个候选集合。接着对候选集合内的词的概率进行重新归一化,使其总和为 1,最后从这个归一化后的概率分布中采样得到下一个词。
影响 :较小 的 K 值会使模型更倾向于选择高概率的词,生成的文本更加保守、准确,但可能缺乏多样性;较大 的 K 值会增加采样的范围,使生成的文本更具多样性,但也可能引入一些低质量或不合理的词。
Top-P 采样(动态)
采样时,先按概率从高到低排序,从累加概率在P的范围内选择,放弃概率过小的样本
含义 :Top P 也是一种采样策略,它根据词的概率进行排序,然后选择概率累计和达到阈值 P (通常是一个 0 到 1 之间的小数)的最小词集合,只在这个集合中进行采样。
作用机制 :首先将所有词按照概率从高到低排序,然后依次累加概率,当累加概率达到 P 时,停止累加,选取此时包含的所有词组成一个候选集合。之后将候选集合外的词的概率设为 0,对候选集合内的词的概率进行归一化处理,最后从这个归一化后的概率分布中采样得到下一个词。
优势:Top P 能够自适应地动态调整采样范围,避免了 Top K 可能固定选取过多或过少词的问题。它在保证生成文本多样性的同时,也能一定程度上控制生成文本的质量。

4.Repetition Penalty(重复惩罚)
Frequency Penalty、Presence Penalty类似
用于限制语言模型输出重复的内容
取值范围 > 1
含义:Repetition Penalty 是一个用于控制生成文本中重复内容的参数,通常是一个大于 0 的实数。
logits是未经归一化的预测得分向量
作用机制:在生成文本过程中,如果某个词已经在之前生成的文本中出现过,会对该词的 logits 进行调整。当 Repetition Penalty 大于 0 时,会将该词的 logits 除以 Repetition Penalty,从而降低其概率;当 Repetition Penalty 小于 0 时,会将该词的 logits 乘以 Repetition Penalty,提高其概率(不过这种情况较少使用)。通过这种方式,对重复出现的词进行惩罚或奖励,以控制文本的重复程度。
应用场景 :在需要生成内容丰富、避免重复的文本场景中,如文章写作、对话生成,设置合适的 Repetition Penalty 可以提高生成文本的质量。
代码实现
代码运行流程
python
RepetitionPenaltyLogitsProcessor流程树状图
├── 1. 输入参数
│ ├── input_ids: [batch_size, seq_len] → 已生成token的ID序列[1](@ref)
│ └── scores: [batch_size, vocab_size] → 原始未调整的logits张量
├── 2. 提取已生成token的logits(核心操作)
│ ├── torch.gather(scores, 1, input_ids)
│ │ ├── 作用: 沿dim=1(列方向)索引,收集input_ids对应的logits值[1](@ref)
│ │ └── 示例: 若input_ids=[[2,0]], 则提取第2列和第0列的值[1](@ref)
│ └── 输出score: [batch_size, seq_len] → 已生成token对应的logits
├── 3. 惩罚系数调整
│ ├── torch.where(score < 0, score * θ, score / θ)
│ │ ├── 正logits: 通过除法降低概率(如0.7 → 0.7/1.2≈0.58)
│ │ └── 负logits: 通过乘法抑制(如-0.5 → -0.5 * 1.2=-0.6)
│ └── 输出score: [batch_size, seq_len] → 调整后的惩罚logits
└── 4. 写回原张量(原地操作)
├── scores.scatter_(1, input_ids, score)
│ ├── 作用: 沿dim=1(列方向)将调整值写入input_ids指定位置
│ └── 示例: 将[[0.58, -0.6]]写入input_ids对应的词汇表位置
└── 输出scores: [batch_size, vocab_size] → 完成惩罚的logits**inputs_id:**表示当前已生成的token序列
**scores:**模型输出的未归一化logits,表示下一个token的预测得分分布
**self.penalty:**惩罚系数,通常设置为1.1~1.2
**score:**沿维度1(列方向)从scores中提取input_ids对应的logits值。
**torch.gather():**沿指定维度dim,根据index张量从输入张量input中收集数据,返回与index形状相同的输出张量
| 参数 | 类型 | 说明 |
|---|---|---|
input |
Tensor | 源张量,从中收集数据 |
dim |
int | 操作的维度(如dim=0表示按行索引) |
index |
LongTensor | 索引张量,形状需与input除dim维度外一致 |
out (可选) |
Tensor | 输出张量(通常省略) |
**torch.where():**根据布尔条件张量condition,从 x 和 y 中选择元素生成新张量
| 参数 | 类型 | 说明 |
|---|---|---|
condition |
BoolTensor | 条件张量,决定选择x或y的元素 |
x |
Tensor/Scalar | 条件为True时选择的元素 |
y |
Tensor/Scalar | 条件为False时选择的元素 |
out (可选) |
Tensor | 输出张量(通常省略) |
**scatter_():**将src或value中的数据按index沿维度dim分散到目标张量中(原地操作)
| 参数 | 类型 | 说明 |
|---|---|---|
input |
Tensor | 目标张量(被修改的源张量) |
dim |
int | 分散的维度 |
index |
LongTensor | 索引张量,形状需与src一致 |
src (可选) |
Tensor | 提供数据的源张量(与value互斥) |
value (可选) |
Scalar | 标量值(与src互斥) |
reduce (可选) |
str | 重复索引时的聚合方式(如"sum"或"multiply") |
python
class RepetitionPenaltyLogitsProcessor:
def __call__(self, input_ids, scores):
score = torch.gather(scores, 1, input_ids) # 提取已生成token的logits
# 调整logits:正logits除以θ,负logits乘以θ
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
scores.scatter_(1, input_ids, score) # 将调整后的logits写回原张量
return scores
score分数取决于在之前的预测中有没有出现过,或出现过几次
5.Max Memory(最大内存)
从后向前,截断送入模型文本,到指定长度
含义 :Max Memory 指的是在生成文本过程中允许模型使用的最大内存量。在处理大规模数据或复杂模型时,生成过程可能会消耗大量的内存,通过设置 Max Memory 可以限制内存的使用,避免因内存不足导致程序崩溃。
作用机制:当模型在生成过程中使用的内存接近或达到 Max Memory 时,会触发相应的内存管理机制。可能会采取一些措施,如释放一些不再使用的中间变量、对数据进行压缩等,以减少内存占用。
影响:合理设置 Max Memory 可以保证程序的稳定运行,但如果设置得过小,可能会影响模型的性能,导致生成速度变慢或无法生成完整的文本;如果设置得过大,可能会使系统资源过度占用,影响其他程序的运行。
例:
max memory = 3
a -> model -> b
ab -> model -> c
abc -> model -> d
bcd -> model -> e
cde -> model -> f
十一、指针网络 pointer-network
**指针网络是解决摘要问题的主要方法:**一种用于解决输出是输入序列子集问题的神经网络架构,与传统的序列到序列(Seq2Seq)模型不同,指针网络不生成固定词汇表中的输出,而是直接从输入序列中选择元素作为输出。这种设计使其特别适合处理输出字典大小随输入序列长度变化的任务,如组合优化问题和文本摘要
**指针网络的核心思想:**使用注意力机制(Attention Mechanism)来计算输入序列中每个元素的重要性,并将注意力权重作为选择输出元素的概率。
**摘要问题的特点:**生成的摘要在原文本中一定出现过

十二、seq2seq预训练
基于seq2seq也可进行模型预训练
bert是一个 encoder
seq2seq训练可以得到 encoder + decoder
**代表:**T5
T5(Text-to-Text Transfer Transformer)
**T5(Text-to-Text Transfer Transformer)**是一种基于 Transformer 架构的序列到序列(Seq2Seq)模型,其训练方式有诸多独特之处
Ⅰ、整体架构
T5 采用了标准的 Encoder - Decoder 架构 ,不过其特别之处在于将所有的自然语言处理任务都统一转化为文本到文本的形式。无论任务是文本分类、机器翻译、问答系统还是摘要生成,输入和输出都被视为文本序列,这使得模型可以使用单一的架构和训练方式处理多种不同类型的任务。
Ⅱ、预训练阶段
1. 预训练目标
T5 的预训练采用了 "填空" 任务,也就是 "文本跨度掩码语言建模(Text Span Masking Language Modeling)"。具体操作如下:
随机选择输入文本中的一些连续文本片段(跨度),将这些片段用特殊的掩码标记(如<extra_id_0>、<extra_id_1>等)替换。
模型的任务是预测被掩码的文本片段,根据预测结果和真实的文本片段计算损失,通过反向传播更新模型参数。
2. 数据来源
使用大规模的无监督文本数据进行预训练,这些数据来源广泛,包括网页文本、书籍、新闻文章等。丰富的数据可以让模型学习到通用的语言知识和语义表示。
3. 训练过程
输入文本经过编码器进行编码,将文本转化为一系列的特征表示。
解码器根据编码器的输出和当前已经生成的部分输出,预测下一个要生成的词。在预训练阶段,解码器的目标是生成被掩码的文本片段。
采用交叉熵损失函数来衡量模型预测结果和真实文本之间的差异,通过优化算法(如 Adam)不断调整模型的参数,使得损失函数最小化。
Ⅲ、微调阶段
1. 任务转化
将具体的下游任务转化为文本到文本的形式。例如:
文本分类:输入为文本和分类任务的描述,输出为分类标签。如输入 "对以下文本进行情感分类:这部电影太棒了!",输出 "积极"。
机器翻译:输入为源语言句子和翻译任务的提示,输出为目标语言句子。如输入 "将以下中文翻译成英文:我爱你",输出 "I love you"。
2. 微调数据集
使用针对具体任务的有监督数据集进行微调。这些数据集包含输入文本和对应的正确输出,用于指导模型学习特定任务的模式和规律。
3. 微调过程
加载预训练好的 T5 模型权重。
在微调数据集上对模型进行训练,同样使用交叉熵损失函数,根据任务的不同调整学习率等超参数。在微调过程中,模型会根据具体任务的特点进一步调整参数,以适应新的任务需求。
Ⅳ、优势
通用性:统一的文本到文本框架使得 T5 可以方便地应用于多种不同类型的自然语言处理任务,无需为每个任务设计专门的模型架构。
迁移学习能力:通过大规模的预训练,模型学习到了丰富的语言知识和语义表示,在微调阶段可以快速适应新的任务,提高了模型的性能和训练效率。
