在机器学习领域,我们常常需要在多个模型之间进行比较,以选择最适合特定任务的模型。
模型比较检验为此提供了科学的依据和方法。
本文将探讨比较检验 的概念、方法、区别与适用范围,并结合scikit-learn库给出具体的代码示例。
1. 什么是比较检验
比较检验 ,又称比对检验,是指通过比较不同模型(或算法)在相同或相似数据集上的表现,来研究它们之间的性能差异。
它基于模型在测试集上的表现,运用各种检验技术来判断模型之间的性能差异是否具有统计学意义。
它的主要作用是:
- 模型选择:在多个候选模型中,通过比较检验找出性能最优的模型,为实际应用提供最佳选择。
- 性能评估:客观、准确地评估模型的泛化能力,避免因随机因素导致的片面结论。
- 统计可靠性:确保模型性能的比较结果具有统计学上的可靠性,增强研究和实践的可信度。
- 指导优化:明确模型之间的优势和不足,为模型的进一步优化和改进提供方向。
通过比较检验,我们可以科学地评估不同模型的优劣,为模型的选择和优化提供有力支持。
2. 常用的比较检验方法
常用的比较检验方法有以下四种。
2.1. 假设检验
假设检验是统计学中用于判断样本之间是否存在显著差异的方法。
在模型比较中,常用于比较两个模型的性能。
python
import numpy as np
from scipy.stats import ttest_ind
# 假设有两个模型的性能指标(如准确率)
model_a_performance = np.random.rand(100) * 100 # 模拟模型A的性能指标
model_b_performance = np.random.rand(100) * 100 # 模拟模型B的性能指标
# 进行t检验
t_statistic, p_value = ttest_ind(model_a_performance, model_b_performance)
print(f'T statistic: {t_statistic:.2f}')
print(f'P value: {p_value:.2f}')
## 输出结果:
'''
T statistic: -0.05
P value: 0.96
'''在上述代码中,模拟了两个模型的性能指标,并使用ttest_ind函数进行独立样本t检验。
通过输出的T统计量 和P值,可以判断两个模型的性能是否存在显著差异。
这里补充说明一下T统计量 和P值的含义。
t 统计量是衡量两个样本均值差异相对于样本数据变异性的统计量,它表示两个样本均值之间的差异与样本均值变异性的比值。
t 统计量绝对值越大,表示两个样本均值之间的差异相对于数据的变异性越大,越有可能认为这种差异是显著的,而不是由随机因素引起的。
而p 值是在假设检验中,在原假设成立的前提下,观察到当前统计量(如 t 统计量)或更极端情况的概率。
p 值用于判断是否拒绝原假设:
- p 值 < 显著性水平(如 0.05):拒绝原假设,认为两个模型的性能存在显著差异。此时,t 统计量的绝对值较大,表明两个模型的性能差异相对于数据的变异性是显著的。
- p 值 ≥ 显著性水平(如 0.05):不拒绝原假设,认为两个模型的性能无显著差异。此时,t 统计量的绝对值较小,表明两个模型的性能差异可能是由随机因素引起的。
2.2. 交叉验证t检验
交叉验证 t 检验 结合了交叉验证和** t 检验**的优点,能够在多次交叉验证的基础上,对模型性能进行更可靠的比较。
python
from sklearn.model_selection import KFold, cross_val_score
from scipy.stats import ttest_ind
# 假设有两个模型
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 加载数据集
from sklearn.datasets import load_iris
data = load_iris()
X, y = data.data, data.target
# 定义模型
model_a = LogisticRegression()
model_b = SVC()
# 进行k折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores_a = cross_val_score(model_a, X, y, cv=kf)
scores_b = cross_val_score(model_b, X, y, cv=kf)
# 进行t检验
t_statistic, p_value = ttest_ind(scores_a, scores_b)
print(f'Model A 得分: {scores_a}')
print(f'Model B 得分: {scores_b}')
print(f'T statistic: {t_statistic:.2f}')
print(f'P value: {p_value:.2f}')
## 输出结果:
'''
Model A 得分: [1. 1. 0.93333333 0.96666667 0.96666667]
Model B 得分: [1. 1. 0.93333333 0.93333333 0.96666667]
T statistic: 0.34
P value: 0.74
'''在上述代码中,我们使用了LogisticRegression和SVC两个模型,并对Iris数据集进行了5折交叉验证。
通过比较两个模型在交叉验证中的性能差异,我们可以使用t检验来判断它们的性能是否存在显著差异。
2.3. McNemar 检验
McNemar 检验适用于比较两个相关样本的比例差异,常用于评估两个模型在相同测试集上的分类错误率。
python
from statsmodels.stats.contingency_tables import mcnemar
import numpy as np
# 示例数据:二分类问题的预测结果
# 行为实际分类,列为预测分类
# 预测: 1 预测: 0
# 实际: 1 [10, 5]
# 实际: 0 [3, 12]
data = np.array([[10, 5],
[3, 12]])
# 执行 McNemar 检验
result = mcnemar(data, exact=True)
print("McNemar 检验统计量:", result.statistic)
print("p 值:", result.pvalue)
## 运行结果:
'''
McNemar 检验统计量: 3.0
p 值: 0.7265625
'''上面的代码直接使用了statsmodels库的mcnemar方法。
2.4. Friedman 检验和 Nemenyi 检验
Friedman检验是一种非参数检验方法,用于比较多个算法在多个数据集上的整体表现性能。
如果Friedman检验结果显示算法之间存在显著差异,则可以使用Nemenyi检验进行后续比较,以确定哪些算法之间存在显著差异。
代码示例如下:
python
import numpy as np
from scipy.stats import friedmanchisquare
# 示例数据:每个子列表表示一个被试的不同条件下的观测值
# 例如,三种不同的处理 (A, B, C) 对于每个个体的效果
data = [
[100, 25, 30], # 第一位被试的观测值
[200, 35, 15], # 第二位被试的观测值
[300, 20, 25], # 第三位被试的观测值
[250, 10, 35], # 第四位被试的观测值
[150, 30, 20], # 第五位被试的观测值
[350, 15, 20], # 第六位被试的观测值
]
# 转换为 NumPy 数组
data = np.array(data)
# Friedman 检验
statistic, p_value = friedmanchisquare(
data[:, 0],
data[:, 1],
data[:, 2],
)
print("Friedman 检验统计量:", statistic)
print("Friedman 检验 p 值:", p_value)
# 如果 Friedman 检验显著,进行 Nemenyi 检验(或 Tukey HSD 作为替代)
if p_value < 0.05:
print("Friedman 检验显著,进行后续比较...")
# 使用 Tukey HSD 进行后续多重比较
from statsmodels.stats.multicomp import MultiComparison
# 创建 MultiComparison 对象
mc = MultiComparison(
data=[data[:, 0], data[:, 1], data[:, 2]], groups=["A", "B", "C"]
)
# 执行 Tukey HSD 检验
result = mc.tukeyhsd()
# 输出结果
print(result.summary())
else:
print("Friedman 检验不显著,无需进行后续比较。")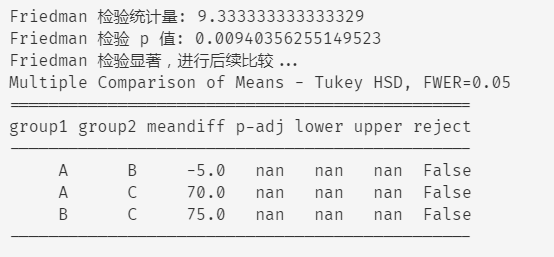
运行上述代码后,会看到一个较小的** p 值**(小于 0.05),这表明 Friedman 检验检测到不同条件之间存在显著差异。
随后,代码会执行 Tukey HSD 检验来进一步比较哪些条件之间存在显著差异,并输出结果。
3. 各种比较检验方法的比较
这几种比较检验方法的优缺点和适用范围对比如下表:
| 检验方法 | 优点 | 缺点 | 适用范围 |
|---|---|---|---|
| 假设检验 | 简单易用,适用于比较两个模型 | 假设数据服从正态分布,对样本量有一定要求 | 比较两个模型在单一数据集上的性能 |
| 交叉验证 t 检验 | 结合了交叉验证,结果更可靠 | 计算量较大,仍假设数据服从正态分布 | 比较两个模型在多个数据集上的性能 |
| McNemar 检验 | 适用于比较两个模型在相同测试集上的分类错误率 | 只考虑错误分类的情况,信息利用不充分 | 比较两个模型在单一数据集上的性能 |
| Friedman 检验和 Nemenyi 检验 | 能够比较多个模型在多个数据集上的性能,适用于非参数数据 | 计算复杂,解释结果需要一定的统计学知识 | 比较多个模型在多个数据集上的性能 |
4. 总结
本文系统地介绍了模型比较检验的概念、作用、常用方法及其适用场景,并通过 scikit-learn 代码示例详细演示了每种方法的实现过程。
在实际应用中,应根据具体的数据特点、模型数量和比较需求,灵活选择合适的比较检验方法,以确保模型评估结果的准确性和可靠性。