
由于近期项目需求,我们计划在机器狗上部署对话大模型,并结合具体业务场景进行定制化回答。在技术选型过程中,我们对比了RAG(Retrieval-Augmented Generation)和模型微调两种策略。RAG虽然在知识检索方面表现优异,但需要额外部署文本嵌入模型,增加了部署复杂性和资源开销。相比之下,模型微调能够直接针对特定场景优化模型性能,避免了冗余组件的引入,因此我们最终选择了微调策略。
在微调框架的选择上,我们采用了LLaMA-Factory。这是一款开源的低代码大模型微调框架,集成了当前业界广泛使用的微调技术,能够显著简化微调流程。其核心优势在于支持通过Web UI界面实现零代码微调,大幅降低了技术门槛,同时保留了高度的灵活性。通过该框架,我们能够快速将业务场景数据注入模型,实现高效的知识定制化,最终满足项目对对话大模型的实际需求。
1. 环境配置
默认anaconda、cuda都已经安装完毕!
conda create -n Llama-Factory python=3.10
python 推荐3.10
torch推荐2.4
torch在阿里云直接下载离线版的cuda版本安装,链接
微调Deepseek-r1:1.5b需要8G左右的显存

git llama factory项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory pip install -e ".[torch,metrics]"
验证安装
llamafactory-cli version

2. 准备数据集
bash
[
{
"instruction": "人类指令",
"input": "人类输入",
"output": "模型回答"
}
]
3. 开始训练
启动llamafactory
llamafactory-cli webui
运行以上命令会自动跳转一个gradio的界面,如果报错可以尝试升级gradio
pip install --upgrade gradio

加载模型

加载数据集

查看数据集

调整参数
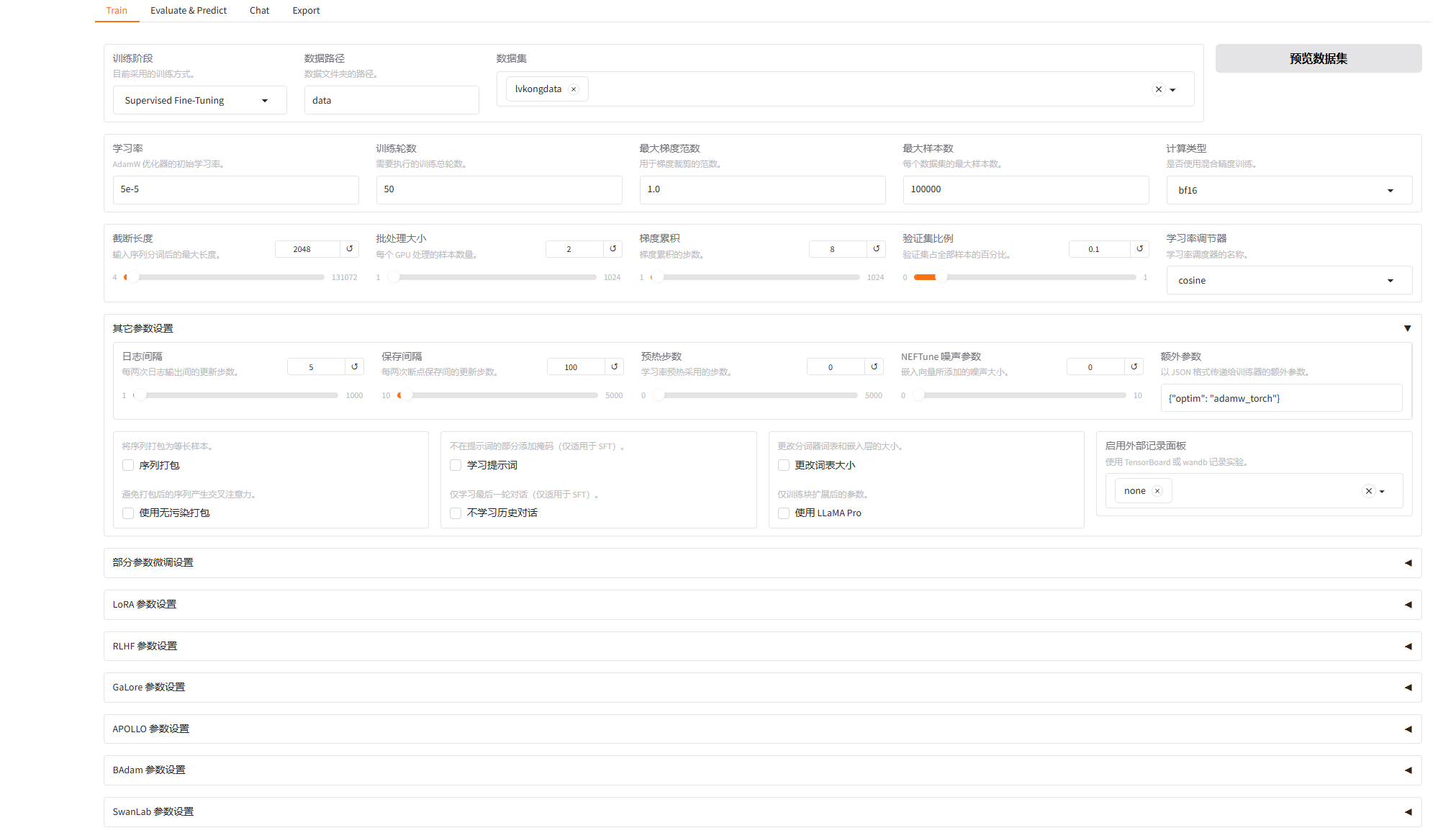
设置权重保存路径

开始训练

4. 测试模型
训练结束后,会绘制loss曲线


加载训练的权重,开始对话
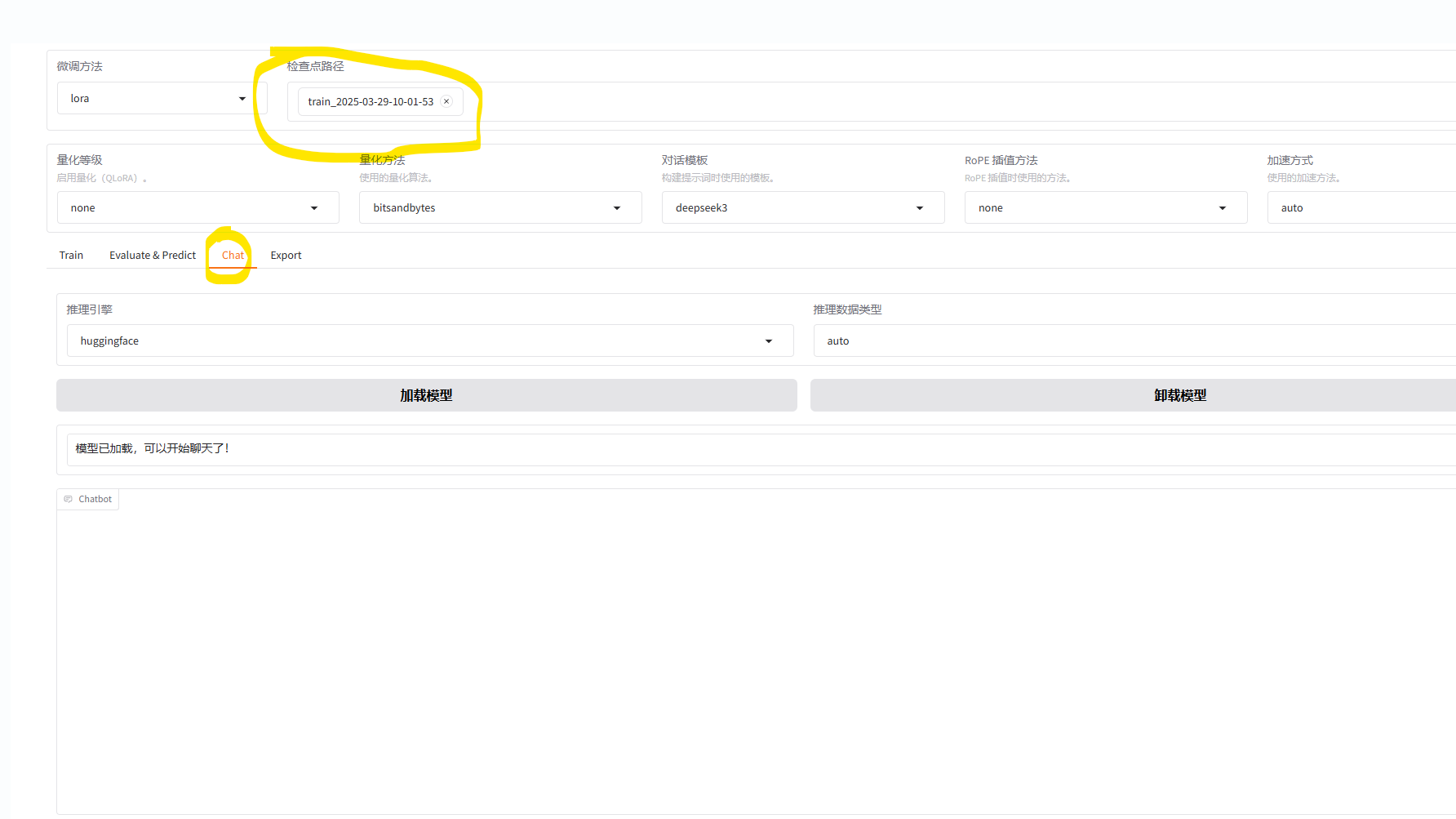

测试完成,微调成功
用于微调的数据集很关键!!!