本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
大型语言模型(LLMs)如ChatGPT和Llama在回答问题方面表现出色,但它们的知识仅限于训练时所使用的数据。它们无法访问私人数据,也无法在训练截止日期之后学习新知识。那么,主要问题是......我们如何扩展它们的知识呢?
答案就在于检索增强生成(RAG)。今天,我们将探讨RAG的流程,并展示如何使用Llama Index构建一个RAG系统。
让我们开始吧!
检索增强生成(RAG):基础知识
LLMs是当今最先进的自然语言处理模型,在翻译、写作和通用问答方面表现出色。然而,它们在处理特定领域的查询时会遇到困难,常常会生成错误的信息。
在这种情况下,每个查询可能只有少数文档包含相关的上下文。为了解决这个问题,我们需要一个高效的系统,能够在生成回答之前检索并整合相关信息------这就是RAG的核心。
预训练的LLMs通过三种主要方式获取知识,但每种方式都有其局限性:
- 训练:从头开始构建一个LLM需要对庞大的神经网络进行训练,处理数万亿个标记,成本高达数亿美元------这使得大多数情况下都难以实现。
- 微调:这种方式可以将预训练的模型适应新的数据,但在时间和资源方面成本较高。除非有特定需求,否则并不总是实用。
- 提示:这是最易于访问的方法,通过将新信息插入LLM的上下文窗口中,使其能够根据提供的数据回答问题。然而,由于文档大小通常会超出上下文限制,仅靠这种方法是不够的。
RAG通过在查询时高效地处理、存储和检索相关的文档片段,克服了这些限制。这确保了LLMs能够生成更准确、更具上下文感知能力的回答,而无需进行昂贵的重新训练或微调。
RAG流程的关键组件
一个RAG系统由几个关键组件组成:
-
文本分割器:将大型文档分解为适合LLM上下文窗口的小块。
-
嵌入模型:将文本转换为向量表示,以便进行高效的相似性搜索。
-
向量存储:一种专门的数据库,用于存储和检索文档嵌入向量及其元数据。
-
LLM:基于检索到的信息生成回答的核心语言模型。
-
实用工具函数:包括网络检索器和文档解析器等工具,用于预处理和增强数据检索。
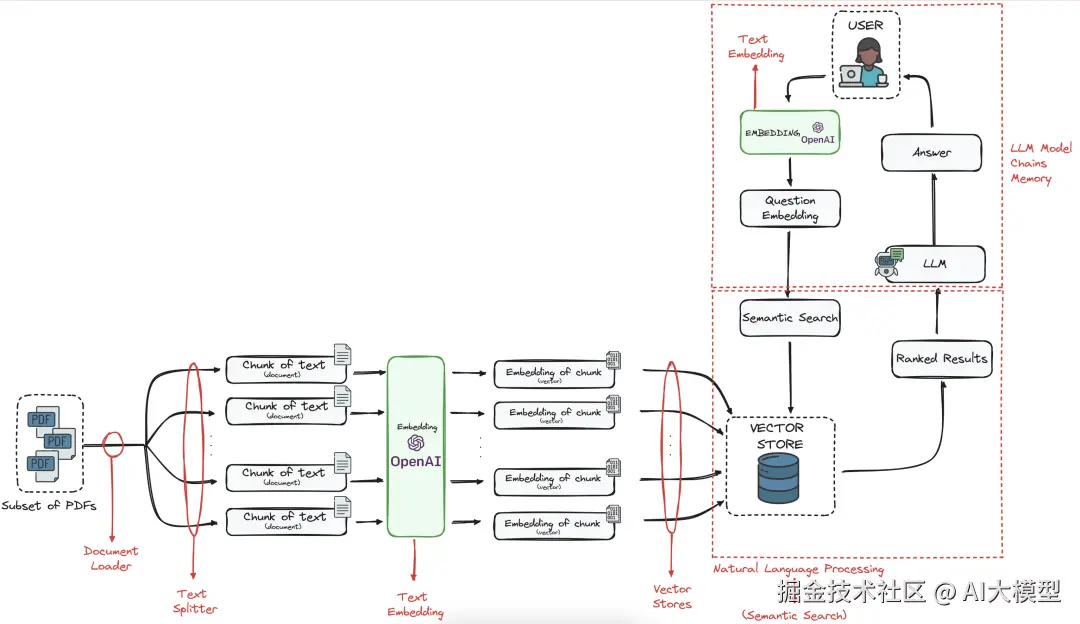
这些组件在使RAG系统准确且高效方面都发挥着关键作用。
什么是LlamaIndex?
LlamaIndex(前身为GPTIndex)是一个用于构建LLM驱动应用程序的Python框架。它充当自定义数据源和大型语言模型之间的桥梁,简化了数据的摄取、索引和查询过程。
LlamaIndex支持多种数据源、向量数据库和查询接口,是RAG应用程序的全能解决方案。它还可以无缝集成LangChain、Flask和Docker等工具,使其在实际应用中具有高度灵活性。
你可以在这里探索LlamaIndex的官方GitHub仓库。
使用LlamaIndex实现一个简单的RAG系统
第一步:设置环境
在开始实现之前,我们需要设置Python环境并安装必要的依赖项。使用虚拟环境有助于高效管理依赖项:
bash
python -m venv rag_env
source rag_env/bin/activate # 在Windows上,使用:rag_env\Scripts\activate现在,你可以安装所需的库。LlamaIndex、OpenAI和FAISS是构建我们的RAG系统所必需的:
perl
pip install llama-index openai faiss-cpu为了使LlamaIndex能够查询OpenAI模型,别忘了配置你的OpenAI API密钥:
lua
import os
os.environ["OPENAI_API_KEY"] = "your-api-key-here"第二步:加载文档
为了使检索能够工作,我们首先需要将文档加载到系统中。LlamaIndex提供了SimpleDirectoryReader来高效处理这一过程。在我的例子中,我将使用"Attention Is All You Need"这篇论文来扩展我的LLM的知识。
python
from llama_index import SimpleDirectoryReader
# 从目录中加载文本文件
documents = SimpleDirectoryReader("./data").load_data()
print(f"已加载 {len(documents)} 个文档")第三步:创建文本分割
LLMs有一个上下文窗口限制,因此我们不能一次性传递整个文档。相反,我们将它们分割成更小的、结构化的块,以便高效检索。
python
from llama_index.text_splitter import SentenceSplitter
# 定义基于句子的文本分割器
text_splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
# 对文档应用文本分割
nodes = text_splitter.split_text([doc.text for doc in documents])
print(f"分割成 {len(nodes)} 个块")第四步:用嵌入向量索引文档
为了执行语义搜索,我们需要将文档块转换为向量嵌入,并将它们存储在索引中。
ini
from llama_index import VectorStoreIndex
# 创建索引
index = VectorStoreIndex(nodes)
# 持久化索引(可选)
index.storage_context.persist(persist_dir="./storage")第五步:用RAG查询索引
这就是RAG(终于)发挥作用的地方。我们将查询索引的文档,以检索相关信息并生成由LLM驱动的回答。
ini
from llama_index.query_engine import RetrieverQueryEngine
query_engine = RetrieverQueryEngine.from_args(index.as_retriever())
response = query_engine.query("什么是注意力机制?")
print(response)如果我们执行上述代码,我们将得到以下结果:
"注意力机制是深度学习模型中用于在处理数据时专注于输入序列的相关部分的一种机制。在论文《Attention Is All You Need》中,Vaswani等人引入了Transformer架构,该架构完全依赖自注意力机制,而不是循环或卷积。关键创新是自注意力机制,它允许模型根据彼此之间的关系来衡量句子中不同单词的重要性,从而实现更好的并行化和长距离依赖。"
我们做到了!
最后的思考
使用LlamaIndex构建RAG系统为利用LLMs超越其训练数据开辟了令人兴奋的可能性。通过整合文档检索、基于嵌入的索引和实时查询,RAG提高了准确性并减少了错误信息的生成,使其成为特定领域应用的强大解决方案。
通过本指南中的分步实现,你现在拥有一个可以扩展的RAG流程,我们将其余的扩展方式留给读者作为练习:
- 使用OpenAI、Cohere或Hugging Face等模型自定义嵌入。
- 集成Pinecone、Weaviate或ChromaDB等向量数据库以实现可扩展的检索。
- 通过Flask、FastAPI或聊天机器人界面部署系统。
- 优化文本分块策略以提高检索质量。
现在轮到你了------实验、迭代并突破LlamaIndex的可能边界!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。