本文使用的环境:linux、无网离线环境
一、环境配置
1. 代码下载
bash
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git2. 依赖安装
bash
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
# pip install -e ..[torch,metrics]是可选依赖包,如果环境中包含了这些依赖包,就不用安装- setup.py中可以查看有哪些依赖选项
- requirements.txt是必须要安装的依赖
- 离线环境中可以
pip download xxx下载编译好的whl包进行离线安装
3.验证
bash
llamafactory-cli version 安装成功后会输出版本号
二、运行
LLaMA Factory有web页面,也可以命令行运行。web页面的本质是图形化设置各项训练参数,生成训练命令进行执行。
1. 启动web页面
bash
llamafactory-cli webui- 如果是多卡环境,要注意之间的通信内存是多大,如果内存很小,多卡训练是会报错的
- 指定一张卡进行训练用该命令启动webui:
FORCE_TORCHRUN=2 CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli webui
2.设置预训练模型

- 模型名称:预训练模型名称,会从指定的模型下载源下载该模型。
- 如果是本地的预训练模型,将模型名称设置为
Custom,然后在模型路径处设置本地模型的相对路径。
3.设置数据集
- 使用自己的数据集需要现在
dataset_info.json中添加数据集描述,然后将该数据集放到data目录。
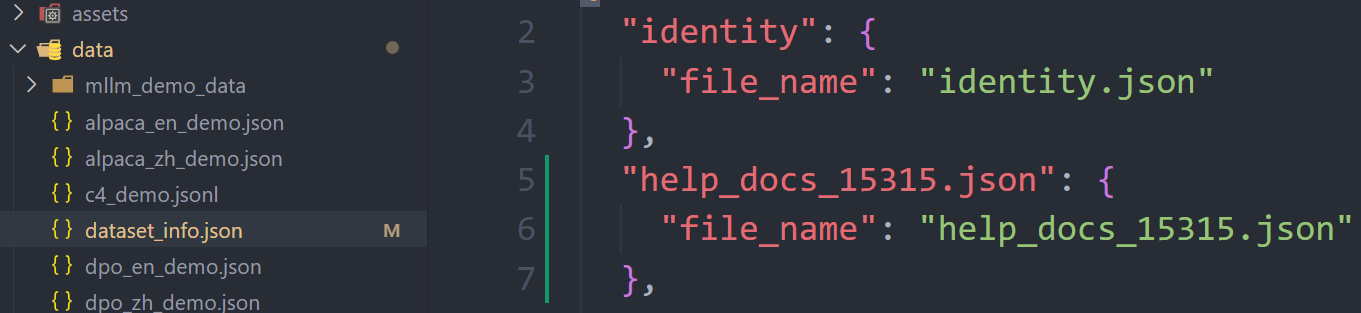
- 在
dataset_info.json中配置好后,数据集路径选择data,数据集中就可以看到添加的数据集名称了。

- 对话模板要选择和自己数据集类型匹配的(Alpaca、ShareGPT等)

4.训练参数设置
可以直接在面板中设置LoRA参数、训练超参数、训练过程参数、硬件配置相关等。
5.模型输出位置
设置输出目录,保存在项目的saves文件夹中。

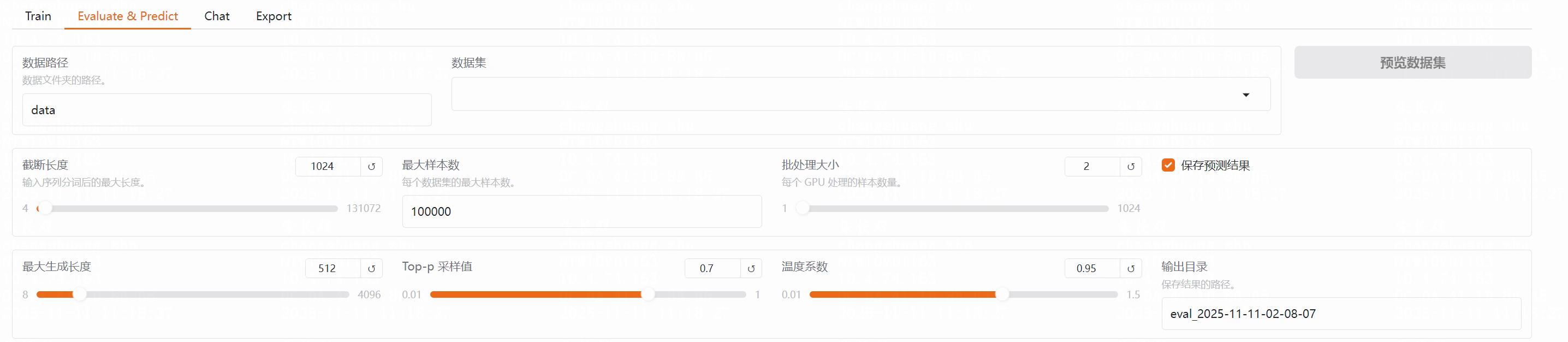
6.模型评估和验证
- 加载测试数据集进行模型评估,需要设置好数据集路径,这个test数据集也需要在
dataset_info.json中添加
- 加载模型进行对话,先加载,再对话

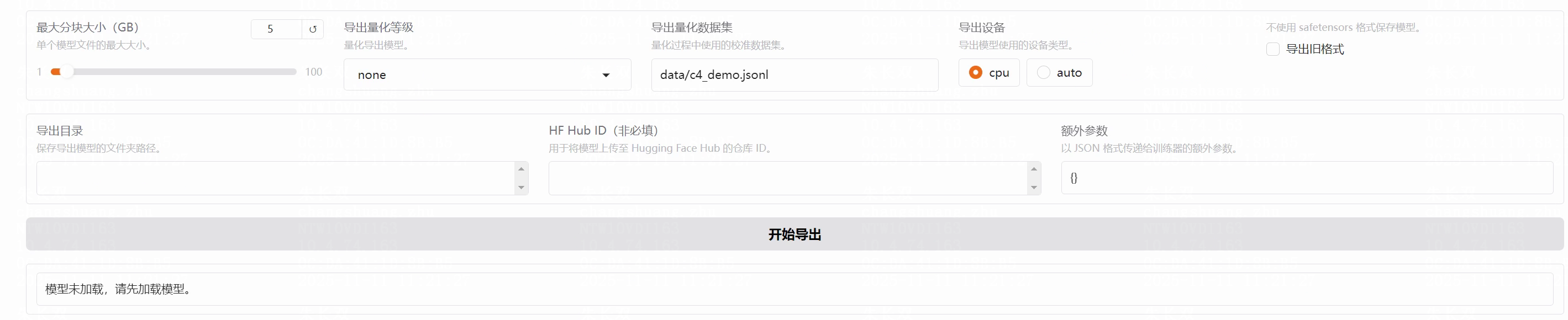
7.导出模型
设置好参数直接导出