
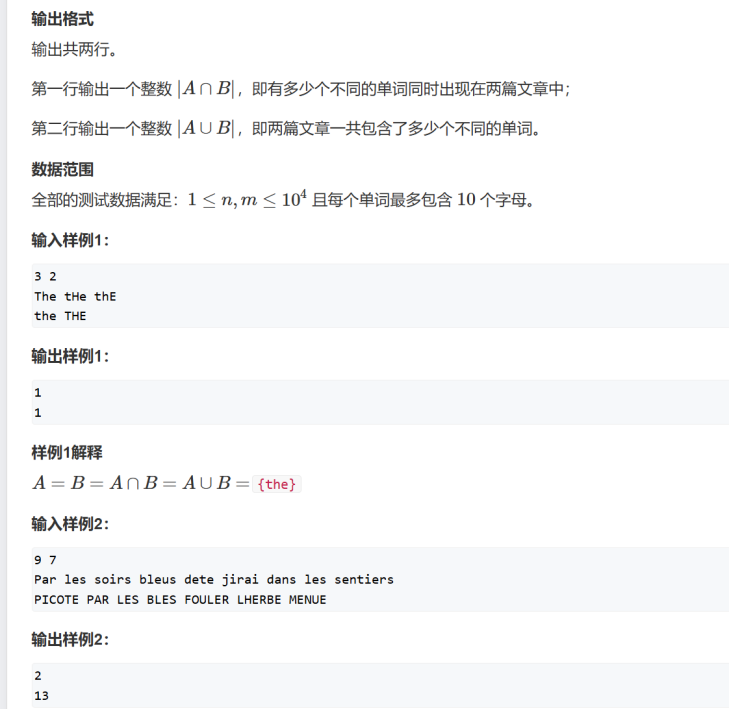
#include<bits/stdc++.h>
using namespace std;
int main() {
// 定义两个变量 n 和 m,分别用于存储两篇文章的单词个数
int n, m;
// 从标准输入读取 n 和 m 的值
cin >> n >> m;
// 定义三个 map 容器,A 用于存储并集,T 用于标记第一篇文章中的单词,B 用于存储交集
map<string, int>A, T, B;
// 循环读取第一篇文章的 n 个单词
for (int i = 0; i < n; i++) {
// 定义一个字符串变量 t 用于存储当前读取的单词
string t;
// 从标准输入读取一个单词到 t
cin >> t;
// 遍历单词 t 的每个字符
for (int j = 0; j < t.length(); j++) {
// 如果字符是大写字母
if (t[j] >= 'A' && t[j] <= 'Z') {
// 将大写字母转换为小写字母
t[j] = t[j] - 'A' + 'a';
}
}
// 将转换后的单词 t 加入到集合 A 中,标记为存在
A[t] = 1;
// 将转换后的单词 t 加入到集合 T 中,标记为第一篇文章中的单词
T[t] = 2;
}
// 循环读取第二篇文章的 m 个单词
for (int i = 0; i < m; i++) {
// 定义一个字符串变量 t 用于存储当前读取的单词
string t;
// 从标准输入读取一个单词到 t
cin >> t;
// 遍历单词 t 的每个字符
for (int j = 0; j < t.length(); j++) {
// 如果字符是大写字母
if (t[j] >= 'A' && t[j] <= 'Z') {
// 将大写字母转换为小写字母
t[j] = t[j] - 'A' + 'a';
}
}
// 如果该单词在第一篇文章中出现过
if (T[t]) {
// 将该单词加入到交集集合 B 中
B[t] = 3;
}
// 将该单词加入到并集集合 A 中
A[t] = 1;
}
// 输出交集集合 B 的大小,即同时出现在两篇文章中的不同单词的个数
cout << B.size() << endl;
// 输出并集集合 A 的大小,即两篇文章一共包含的不同单词的个数
cout << A.size() << endl;
return 0;
}