LongDiff:Training-Free Long Video Generation in One Go
-
原文摘要
-
视频扩散模型的现状
-
取得成果:视频扩散模型在视频生成方面最近取得了显著成果。
-
存在挑战:大多数此类模型主要针对短视频生成进行设计和训练,在长视频生成中存在问题,难以保持时间一致性和视觉细节。
-
-
提出的方法------LongDiff
-
组成部分:
- 位置映射(PM):精心设计的组件之一。
- 信息帧选择(IFS):精心设计的另一个组件。
-
解决挑战:旨在解决阻碍短到长视频生成泛化的两个关键挑战,即时间位置模糊和信息稀释问题。
-
-
方法的优势
- 能够解锁现成视频扩散模型的潜力,一次性实现高质量的长视频生成。
-
1. 介绍
1.1 长视频生成面临的挑战及现有方法
- 现有方法的局限性
- 多数为短视频生成设计:大多数现有方法主要针对**短视频(通常少于24帧)**生成进行设计和训练,无法满足许多现实应用(如电影制作、游戏开发和动画创作等)对长视频的需求。
- 训练方法的不足
- 资源密集 :
- 基于重新训练视频模型的方法(如在长视频数据集上训练、采用自回归或分层范式等),由于模型复杂,需要大量资源和时间
- 长视频数据集稀缺,难以满足训练需求,难以获得最佳参数。
- 无训练方法的局限 :
- 直接适应现成短视频生成模型进行长视频生成的无训练方法,虽无需标注数据和重新训练资源,但存在一些问题。
- 滑动窗口方案限制长距离帧之间的全局时间一致性
- 一次性生成长视频的方法虽在频域混合时空信息提高质量,但仍不理想
- 直接适应现成短视频生成模型进行长视频生成的无训练方法,虽无需标注数据和重新训练资源,但存在一些问题。
- 资源密集 :
- 时间相关技术的应用及问题
- 常用技术:为生成具有时间连贯性的视频,先前工作中常结合**时间卷积和时间变换器(temporal transformer)**来捕捉帧间的位置关系,其中带相对位置编码技术的时间变换器越来越受欢迎,并广泛应用于近期的视频扩散模型中。
- 存在的问题:直接使用短视频模型进行长视频生成会导致低质量结果,包括时间一致性差(如帧间过渡突兀)和缺乏视觉细节(如纹理模糊、关键细节缺失)。

1.2 长视频生成挑战的根源分析
-
时间位置模糊:
- 基于伪维度分析,随着生成视频长度增加,视频模型难以准确区分帧的相对位置,破坏模型维持帧顺序的能力,导致时间一致性受损。
-
信息稀释:
- 基于信息熵分析 ,随着视频序列长度增加,帧间的时间相关熵呈上升趋势,表明生成过程中每帧的信息内容减少,导致长视频输出中视觉细节缺失和质量下降。
- 信息熵 :衡量一个随机变量不确定性的程度。
- 熵越高,表示随机变量的不确定性越大,包含的信息量也越多
- 熵越低,表示随机变量的不确定性越小,信息量也越少
- 信息熵 :衡量一个随机变量不确定性的程度。
- 基于信息熵分析 ,随着视频序列长度增加,帧间的时间相关熵呈上升趋势,表明生成过程中每帧的信息内容减少,导致长视频输出中视觉细节缺失和质量下降。
1.3 LongDiff方法的提出
-
方法概述:提出LongDiff方法,这是一种简单而有效的方法,能以无训练的方式解锁预训练短视频扩散模型的长视频生成能力,生成具有全局时间一致性和视觉细节的高质量长视频。
-
关键组件
- 位置映射(PM) :通过简单的GROUP和SHIFT操作,将大量不同的相对帧位置映射到一个可管理的范围 ,确保视频模型能准确区分帧位置,解决时间位置模糊问题,增强时间一致性。
- 信息帧选择(IFS) :限制每个帧与相邻帧 和一组选定的关键帧的时间相关性,减少生成过程中时间相关熵过高的风险,从而更好地捕捉细节,解决信息稀释问题。
-
研究贡献
-
提出一种新颖的无训练方法LongDiff,包含精心设计的位置映射和信息帧选择两个组件,缓解阻碍高质量长视频生成的两个关键挑战。
-
LongDiff能使预训练的短视频模型一次性生成高质量长视频,并在评估基准上达到最先进性能。
-
2. 相关工作
2.1 Text-to-Video Diffusion Model
- 模型构建基础
- 基于文本到图像扩散模型,加入时间模块建立视频帧关联。
- 捕捉帧位置关系方法
- Temporal Convolution:捕捉局部帧关系,但难以构建长距离关联。
- Temporal Transformer:结合位置编码捕捉精确帧关系。其中相对位置编码应用广泛,能助力捕捉帧间关系,提升生成质量。
- 本论文研究聚焦
- 关注结合相对位置编码 的Temporal Transformer视频模型,提出LongDiff方法解决相关问题。
2.2 Long Sequence Generalization
- 面临挑战
- 长序列泛化在多AI任务中常见,长视频生成需兼顾时间内容一致性与视觉细节,难度更大。
- 现有方法局限
- 基于扩散技术:如Nuwa-XL、StreamingT2V等,虽提升质量但需大量计算资源和大规模数据集。
- 无训练方法:如Gen-LVideo、FreeNoise、Freelong等,通过不同方式生成长视频,但各有不足。
- 本文方法优势
- 聚焦理论分析揭示的挑战,提出LongDiff,简单修改Temporal Transformer即可一次性生成高质量长视频 。
3. 准备工作
3.1 短视频扩散模型的整体架构
-
基于3D U-Net架构:大多数现有的短视频扩散模型是基于3D U-Net架构构建的。
-
空间和时间变换器层的作用:在该架构中,空间变换器层和时间变换器层在视频生成过程中都起着重要作用。
plaintext
3D U-net结构
输入: T×H×W×C 视频帧序列
│
▼
[3D卷积层] → [空间变换器] → [时间变换器] → [下采样]
│ │ │
│ ▼ ▼
│ (帧内特征处理) (帧间关系建模)
│
▼
[多级编码器-解码器结构]
│
▼
[上采样] → [时间变换器] → [空间变换器] → [3D卷积层]
│ │ │
│ ▼ ▼
│ (帧间一致性) (帧内细节修复)
│
▼
输出: T×H×W×C 生成视频-
空间变换器层的特性
-
输入:
-
形状 :
(B, T, H, W, C)- 每个帧独立处理,因此实际计算时会对
T维度展开(等效为B*T个独立的(H,W,C)图像)。
- 每个帧独立处理,因此实际计算时会对
-
内容: 单帧的空间特征(例如物体形状、纹理、颜色分布)
-
-
独立处理视频特征:
- 空间变换器层对视频特征(即采样视频的隐藏状态)进行独立于帧的处理。
- 这意味着它在处理视频时,不会受到视频长度的影响。
-
-
聚焦时间变换器层的原因
- 时间变换器:聚焦于帧间的关系
- 处理长视频生成挑战的关键:由于空间变换器层的特性,本文主要关注时间变换器层,因为它在处理长视频生成所面临的挑战方面发挥着重要作用。
3.2 时间变换器的计算方式
-
注意力权重计算
- 公式 :通过公式 w i , j = exp ( a i , j ) ∑ k = 1 N exp ( a i , k ) w_{i,j}=\frac{\exp(a_{i,j})}{\sum_{k = 1}^{N}\exp(a_{i,k})} wi,j=∑k=1Nexp(ai,k)exp(ai,j) 计算注意力权重 w i , j w_{i,j} wi,j,
- 其中 a i , j a_{i,j} ai,j 是查询帧 i i i 和关键帧 j j j 之间的注意力对数(attention logit), N N N 是视频中的帧数。
- 注意力对数计算 : a i , j = f ( q i , k j , i − j ) a_{i,j}=f(q_i,k_j,i - j) ai,j=f(qi,kj,i−j),其中 q i q_i qi、 k j k_j kj 和 v j v_j vj 分别是查询向量、关键向量和值向量, f f f 是一个函数,用于计算注意力对数,它考虑了查询帧 i i i、关键帧 j j j 以及它们的相对位置 ( i − j ) (i - j) (i−j)。
- 公式 :通过公式 w i , j = exp ( a i , j ) ∑ k = 1 N exp ( a i , k ) w_{i,j}=\frac{\exp(a_{i,j})}{\sum_{k = 1}^{N}\exp(a_{i,k})} wi,j=∑k=1Nexp(ai,k)exp(ai,j) 计算注意力权重 w i , j w_{i,j} wi,j,
-
信息聚合计算
- 公式 :通过公式 o i = ∑ j = 1 N w i , j v j o_i=\sum_{j = 1}^{N}w_{i,j}v_j oi=∑j=1Nwi,jvj 计算第 i i i 帧的聚合信息 o i o_i oi,即对所有帧的信息进行加权求和,权重为 w i , j w_{i,j} wi,j。
-
相对位置编码机制
- 相对位置的表示 :函数 f f f 的形式因不同的相对编码机制而异,这里将 f ( q i , k j , i − j ) f(q_i,k_j,i - j) f(qi,kj,i−j) 表示为 f ( q , k , p ) f(q,k,p) f(q,k,p),其中相对位置 p = i − j p = i - j p=i−j。
- 相对位置的取值范围 :在生成具有 N N N 帧的视频时,查询帧和关键帧的位置通常在 0 , N − 1 0, N - 1 0,N−1 范围内,因此查询帧和关键帧之间的相对位置 p p p 的取值范围是 − ( N − 1 ) , N − 1 -(N - 1), N - 1 −(N−1),N−1。
4. 方法
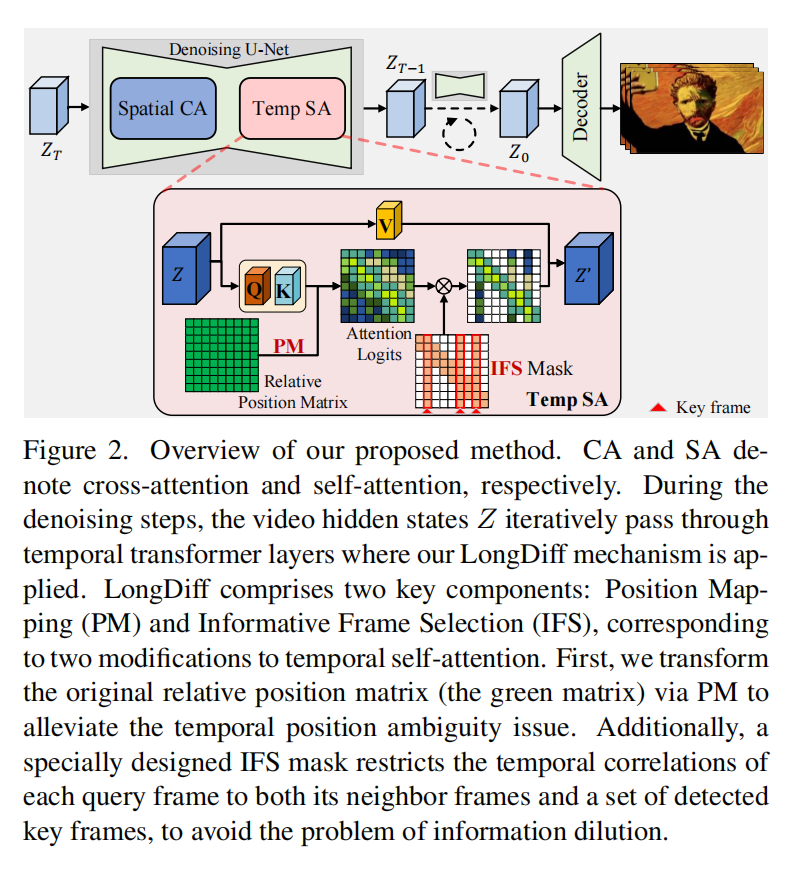
4.1 Temporal Position Ambiguity
-
问题背景
-
时间一致性的重要性:视频生成中,保持帧间时间一致性对生成流畅、真实的视频至关重要。
-
相对位置编码(RPE)的作用:现有视频生成模型,使用RPE技术编码帧间相对位置,以维持时间连贯性。但RPE在生成长视频时可能失效。
-
-
现有方法的局限性
-
固定范围编码问题:
- 当前RPE机制、仅对固定范围内的相对位置进行编码。
- 当视频长度超过最大编码范围时,超出的相对位置会被截断、到同一边界值,导致模型无法正确识别帧顺序。
-
长序列编码的不足:
- 即使采用更先进的RPE技术,理论上支持更长的序列编码,但实际视频生成模型仍难以保持长视频的时间一致性。
-
4.1.1 理论分析
-
伪维度技术 :评估非线性函数类表达能力的metric(度量)
-
定理1的核心结论:
-
定义时间注意力中的注意力对数函数 f ( q , k , p ) f(q,k,p) f(q,k,p),模型将 2 N − 1 2N-1 2N−1 个相对位置(1-n~n-1)分为 g ( N ) g(N) g(N) 组。
-
若模型无法区分同一组内的相对位置 (即 d_f(p,p') \\leq \\epsilon , , ,d_f 是一个与注意力对数函数 是一个与注意力对数函数 是一个与注意力对数函数f相关的距离函数 ),则注意力对数的上界需满足(定力3解释为什么):
sup − ( N − 1 ) ≤ p ≤ N − 1 ∣ f ( q , k , p ) ∣ ≥ ( g ( N ) 2 ) 1 2 r ϵ 4 e \sup_{-(N-1)\leq p \leq N-1} |f(q,k,p)| \geq (\frac{g(N)}{2})^{\frac{1}{2r}} \frac{\epsilon}{4e} −(N−1)≤p≤N−1sup∣f(q,k,p)∣≥(2g(N))2r14eϵ- 其中 r r r 为函数类 H = { f ( ⋅ , ⋅ , p ) ∣ p ∈ Z } H=\{f(·,·,p)|p\in \mathbb{Z}\} H={f(⋅,⋅,p)∣p∈Z} 的伪维度, e e e 为自然常数。
-
-
关键推论:
- 理想情况下,模型应满足 g ( N ) = 2 N − 1 g(N)=2N-1 g(N)=2N−1(即能区分所有相对位置)。
- 若 g ( N ) g(N) g(N) 增长不足(如长视频中 N N N 增大时),会导致时间位置模糊性(Temporal Position Ambiguity),即模型无法区分某些帧的顺序。
-
实验验证
-
观测结果:
- 在生成长视频(如128帧)时,少于40%的查询-关键帧特征满足定理1的不等式(要求 g ( N ) = 2 N − 1 g(N)=2N−1 g(N)=2N−1)。
- 视频越长,满足条件的比例越低。
-
结论:
- 现成的短视频模型难以区分长序列中的大量相对位置,必然导致长视频生成的时间一致性退化。
-
-
问题本质
-
根本原因:
- 注意力对数函数 f ( q , k , p ) f(q,k,p) f(q,k,p) 的表达能力有限(受伪维度 r r r 约束)。
- 当视频序列长度 N N N 增加时,现有模型无法同步提升 g ( N ) g(N) g(N)(分组区分能力),导致帧顺序混淆。
-
影响:
- 生成的长视频可能出现帧顺序错误、动作跳变等时间不一致问题。
-
4.1.2 Solution:Position Mapping
-
问题背景与现有方法缺陷
- 时间位置模糊性(Temporal Position Ambiguity)
- 长视频生成中,相对位置编码(RPE)需区分 O ( N ) O(N) O(N) 个位置( N N N 为帧数),但注意力对数函数 f ( q , k , p ) f(q,k,p) f(q,k,p)的伪维度有限,导致模型无法区分所有位置。
- 时间位置模糊性(Temporal Position Ambiguity)
-
现有方法局限性
-
Clipping(截断):
- 将超出预训练范围的位置截断为边界值(如 p max p_{\text{max}} pmax)。
- 缺点 :丢失长距离位置信息(如 p = 100 p=100 p=100 和 p = 200 p=200 p=200 均映射为 p max p_{\text{max}} pmax)。
-
Interpolation(插值):
- 缩放位置索引至预训练范围(如将 p ∈ 0 , 200 p \in 0,200 p∈0,200 线性映射到 \[0,100\] )。
- 缺点 :密集位置挤压导致区分度下降(如 p = 1 p=1 p=1 和 p = 2 p=2 p=2 可能被映射到同一值)。
-
-
PM的提出
- 通过组索引来引用对应的位置编码以进行时间注意力计算:
- 这种分组(GROUP)操作通过将大量难以区分的相对位置映射到更小的索引集合中
- 减少了模型的管理负担,同时仍能近似保留视频序列的整体位置关系
- 但是模型无法区分同一组内的相对位置
- 位移(SHIFT)操作以恢复细粒度的位置区分性
- 通过组索引来引用对应的位置编码以进行时间注意力计算:
-
Position Mapping (PM) 的组成
-
Group
-
数学定义:
-
输入:原始相对位置 p ∈ − ( N − 1 ) , N − 1 p \in -(N-1), N-1 p∈−(N−1),N−1
-
输出:组索引 p g ∈ − ( G − 1 ) , G − 1 p_g \in -(G-1), G-1 pg∈−(G−1),G−1,其中 G G G 为超参数( G < = N G<=N G<=N)。
-
分组公式:
p g = { ⌈ p S ⌉ ,if p ≥ 0 , ⌊ p S ⌋ ,if p < 0 , S = ⌈ N − 1 G − 1 ⌉ . p_g = \begin{cases} \left\lceil \frac{p}{S} \right\rceil & \text{,if } p \geq 0, \\ \left\lfloor \frac{p}{S} \right\rfloor & \text{,if } p < 0, \end{cases} \quad S = \left\lceil \frac{N-1}{G-1} \right\rceil. pg={⌈Sp⌉⌊Sp⌋,if p≥0,,if p<0,S=⌈G−1N−1⌉.
-
-
示例 ( N = 9 , G = 3 N=9, G=3 N=9,G=3)如下图:
- S = ⌈ 8 2 ⌉ = 4 S = \lceil \frac{8}{2} \rceil = 4 S=⌈28⌉=4,分组结果为:
p ∈ { − 8... − 1 , 0 , 1...8 } → p g ∈ { − 2...2 } . p \in \{-8...-1,0,1...8\} \rightarrow p_g \in \{-2...2\}. p∈{−8...−1,0,1...8}→pg∈{−2...2}.
- S = ⌈ 8 2 ⌉ = 4 S = \lceil \frac{8}{2} \rceil = 4 S=⌈28⌉=4,分组结果为:
-
作用:
- 将 O ( N ) O(N) O(N) 位置压缩为 O ( G ) O(G) O(G)组,降低模型区分负担。

-
-
Shift
-
输入 :分组后的位置矩阵 G ( 0 ) ∈ R N × N G^{(0)} \in \mathbb{R}^{N \times N} G(0)∈RN×N
-
操作步骤:
-
初始分组矩阵 : G i , j ( 0 ) G^{(0)}_{i,j} Gi,j(0) 存储分组操作后的矩阵
-
位移规则 (保持反对称性):
G i , j ( m + 1 ) = { G i , j − 1 ( m ) if i < j ( 上三角 ) , G i , j ( m ) if i = j ( 对角线 ) , G i − 1 , j ( m ) if i > j ( 下三角 ) . G^{(m+1)}{i,j} = \begin{cases} G^{(m)}{i,j-1} & \text{if } i < j \ (\text{上三角}), \\ G^{(m)}{i,j} & \text{if } i = j \ (\text{对角线}), \\ G^{(m)}{i-1,j} & \text{if } i > j \ (\text{下三角}). \end{cases} Gi,j(m+1)=⎩ ⎨ ⎧Gi,j−1(m)Gi,j(m)Gi−1,j(m)if i<j (上三角),if i=j (对角线),if i>j (下三角). -
位移次数 : M = S − 1 M = S-1 M=S−1 次( S S S为每组的原始位置数--和Group中是一个同一个S)。
-
-
示例 (接上例 N = 9 , G = 3 N=9, G=3 N=9,G=3):
-
第1次位移后, G i , j ( 1 ) G^{(1)}{i,j} Gi,j(1) 下三角向下平移1行,上三角同步更新:
G 5 , 1 ( 1 ) = G 4 , 1 ( 0 ) = 1 ( 原 G 5 , 1 ( 0 ) = 1 ) . G^{(1)}{5,1} = G^{(0)}{4,1} = 1 \quad (\text{原 } G^{(0)}{5,1}=1). G5,1(1)=G4,1(0)=1(原 G5,1(0)=1). -
第2次位移后, G 5 , 1 ( 2 ) = G 4 , 1 ( 1 ) = 1 G^{(2)}{5,1} = G^{(1)}{4,1} = 1 G5,1(2)=G4,1(1)=1。
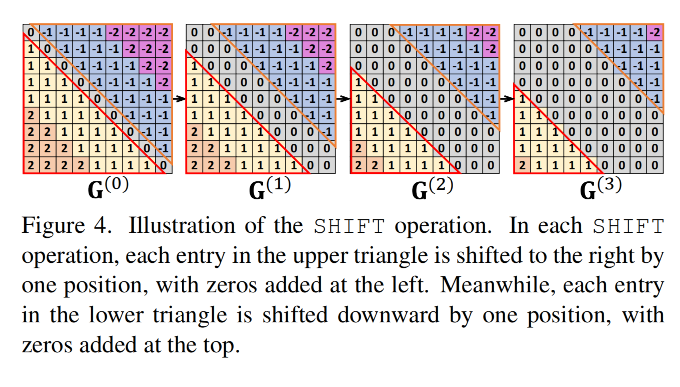
-
-
输出:
-
对 M + 1 M+1 M+1个位移矩阵分别计算注意力权重
A i , j ( m ) = softmax ( f ( q i , k j , G i , j ( m ) ) ) A^{(m)}{i,j} = \text{softmax}(f(q_i,k_j,G^{(m)}{i,j})) Ai,j(m)=softmax(f(qi,kj,Gi,j(m))) -
最终注意力:
A i , j = 1 M + 1 ∑ m = 0 M A i , j ( m ) A_{i,j} = \frac{1}{M+1} \sum_{m=0}^M A^{(m)}_{i,j} Ai,j=M+11m=0∑MAi,j(m)
-
-
关键作用:
- 通过位移记录的独特性(如 p = 1 p=1 p=1 和 p = 4 p=4 p=4 的位移记录不同),恢复组内位置区分性。
-
-
4.2 Information Dilution
-
问题描述
-
现象:
- 直接使用短视频模型生成长视频时,除时间一致性差外,还会出现视觉细节缺失(如纹理模糊、关键物体消失)。
-
本质原因:
- 随着视频帧数 N 增加,时间注意力机制的信息熵上升,导致每帧的有效信息量下降。
-
4.2.1 理论分析
-
信息熵的定义
-
时间相关性熵 ( H ):
- 衡量视频帧间时间注意力权重的信息混乱程度。熵越高,表示帧间关系越模糊,信息传递效率越低。
-
公式表达 :
H ( e a i ∑ j = 1 N e a j ∣ 1 ≤ i ≤ N ) ≥ ln N − 2 B , H\left( \frac{e^{a_i}}{\sum_{j=1}^N e^{a_j}} |{1 \leq i \leq N} \right) \geq \ln N - 2B, H(∑j=1Neajeai∣1≤i≤N)≥lnN−2B,-
其中:
-
{ a i } i = 1 N \{a_i\}_{i=1}^N {ai}i=1N是注意力对数(attention logits),取值范围 − B , B -B, B −B,B。
-
e a i ∑ j = 1 N e a j \frac{e^{a_i}}{\sum_{j=1}^N e^{a_j}} ∑j=1Neajeai是Softmax归一化后的注意力权重。
-
-
-
-
定理2关键结论
-
熵的下界:
- H ≥ ln N − 2 B H \geq \ln N - 2B H≥lnN−2B 表明,当视频长度 N N N增加时,信息熵 H H H 必然增长
-
信息稀释效应:
- 熵越高,注意力权重分布越均匀,导致每帧的有效信息被稀释(即模型难以聚焦关键帧的细节)。
-
4.2.2 Solution:Informative Frame Selection
-
问题背景(信息稀释)
-
现象:
- 长视频生成中,时间注意力机制需处理大量帧(如128帧),导致注意力权重分布过于均匀(高信息熵),每帧的有效信息被稀释
-
理论依据(定理2):
- 信息熵 H ≥ ln N − 2 B H \geq \ln N - 2B H≥lnN−2B,随帧数 N N N 增加,熵必然上升,降低信息传递效率。
-
-
现有方法的局限性
-
固定窗口注意力:
- 仅允许每帧与邻近 L L L 帧交互,虽保留局部细节,但割裂全局时序关联(如远距离动作连贯性差)。
-
插值或截断:
- 挤压或丢弃远距离帧,导致信息丢失或扭曲。
-
-
IFS的提出
- 采用关键帧检测机制,用于识别可能反映视频中场景变化和重要事件的帧。
- 构建伪视频 :由于在生成过程完成前并不存在真实视频数据,将每个时间变换器层的输入序列特征转换为伪视频(pseudo-video),以确保与关键帧检测流程的兼容性
-
IFS的核心设计
-
核心思想
-
双向约束:
-
每帧仅与两类帧交互:
-
邻近帧 ( ∣ i − j ∣ ≤ L |i-j| \leq L ∣i−j∣≤L):保留局部细节。
-
关键帧(动态选择):维持全局一致性。
-
-
-
-
优势:
- 通过减少参与计算的帧数 N ′ ≪ N N' \ll N N′≪N,直接降低熵的下界( \\ln N' \\ll \\ln N)。
- 关键帧作为"信息枢纽",传递全局上下文。
-
-
IFS实现
-
伪视频构建(Pseudo-Video Construction)
-
输入 :时间变换层的特征 F ∈ R N × C × h w F \in \mathbb{R}^{N \times C \times hw} F∈RN×C×hw
-
操作:
-
通道压缩 :沿通道维度进行最大,平均,最小池化 ,得到 F ′ ∈ R N × 3 × h w F' \in \mathbb{R}^{N \times 3 \times hw} F′∈RN×3×hw
- 即适配关键帧检测过程,又保留了重要的语义信息
-
归一化 :映射到 0,255 模拟真实视频:
V = round ( F ′ − min ( F ′ ) max ( F ′ ) − min ( F ′ ) × 255 ) V = \text{round}\left( \frac{F' - \min(F')}{\max(F') - \min(F')} \times 255 \right) V=round(max(F′)−min(F′)F′−min(F′)×255)
-
-
-
关键帧检测(Key-Frame Detection)
-
视频分割 :将伪视频 V V V 均匀分为 n n n个片段(shots)。
-
评分机制(每片段选1关键帧):
-
图像熵 (信息量):反应一张图片的复杂度和信息内容
H ( k ) = − ∑ x p ( x , k ) log 2 ( p ( x , k ) ) H(k) = -\sum_x p(x,k) \log_2 (p(x,k)) H(k)=−x∑p(x,k)log2(p(x,k))- p ( x , k ) p(x,k) p(x,k):第 k k k 帧亮度值 x x x 的分布概率。
-
帧间差异 (运动显著性):
SAD ( k ) = ∑ i , j ∣ I ( i , j , k ) − I ( i , j , k − 1 ) ∣ \text{SAD}(k) = \sum_{i,j} |I(i,j,k) - I(i,j,k-1)| SAD(k)=i,j∑∣I(i,j,k)−I(i,j,k−1)∣- I ( i , j , k ) I(i,j,k) I(i,j,k) 表示第 k k k帧,像素 ( i , j ) (i,j) (i,j)的值
-
综合评分 :
Score ( k ) = α H ( k ) + SAD ( k ) \text{Score}(k) = \alpha H(k) + \text{SAD}(k) Score(k)=αH(k)+SAD(k)- 选择每片段中得分最高的帧作为关键帧。
-
-
-
-
IFS掩码(IFS Mask)
-
定义 :
Mask i j = { 1 , if ∣ i − j ∣ ≤ L or j is key frame , 0 , otherwise . \text{Mask}_{ij} = \begin{cases} 1, & \text{if } |i-j| \leq L \text{ or } j \text{ is key frame}, \\ 0, & \text{otherwise}. \end{cases} Maskij={1,0,if ∣i−j∣≤L or j is key frame,otherwise. -
作用:
- 在时间注意力计算中,仅保留邻近帧和关键帧的权重(其余置零)。
- 示例 :若 L = 5 L=5 L=5,第10帧可与第5-15帧及所有关键帧交互。
5. 实验
-
实验设置(Implementation Details)
-
基准模型选择:
- 使用开源视频扩散模型 LaVie (基于RoPE位置编码)和 VideoCrafter-512(基于T5-style RPE),两者均针对16帧短视频(320×512分辨率)训练。
- 扩展目标:通过LongDiff生成128帧长视频。
-
兼容性设计 :
LongDiff无需修改模型结构,直接适配不同RPE机制(如RoPE和40的RPE)。
-
-
评估指标(Evaluation Metrics)
-
评估体系 :采用 VBench 的6项指标:
- Subject Consistency (SC):主体一致性
- Background Consistency (BC):背景一致性
- Motion Smoothness (MS):运动平滑度
- Temporal Flickering (TF):时间闪烁(越低越好)
- Imaging Quality (IQ):图像质量
- Overall Consistency (OC):整体一致性
-
测试数据:使用VBench的200条文本提示(与FreeLong32相同)。
-
5.1 对比实验
- 基线
| 方法 | 核心策略 | 预期缺陷 |
|---|---|---|
| Direct | 直接扩展初始噪声序列生成长视频 | 时间模糊+细节丢失(未处理长序列问题) |
| Sliding35 | 滑动窗口处理固定数量帧(局部注意力) | 割裂全局时序依赖 |
| FreeNoise35 | 滑动窗口+噪声重调度 | 局部连贯但长程运动不自然 |
| FreeLong32 | 频域融合时空信息 | 细节保留不足(高频信息损失) |
-
定量结果
-
LongDiff优势:
- 全指标领先:在SC、BC、MS、IQ、OC上均超越所有基线,TF显著降低。
- 关键提升 :
- SC提高22%:PM(位置映射)有效维持主体连贯性。
- TF降低35%:IFS(关键帧选择)减少注意力权重震荡。
-
基线表现:
- Direct:所有指标最差(验证长视频生成的固有挑战)。
- FreeLong:频域融合导致细节模糊(IQ低于LongDiff 15%)。
-
-
定性对比
-
案例1(场景切换):
- LongDiff生成的128帧视频中,人物动作和背景过渡自然,而Sliding出现"跳跃式"运动。
-
案例2(细节保留):
- FreeLong生成的"乐器演奏"视频中鼓槌模糊,LongDFF则清晰保留纹理(得益于IFS的关键帧机制)。
-
5.2 消融实验(Ablation Study)
- PM与IFS的贡献 :
- 仅使用PM:SC提升但TF仍高(缺乏信息筛选)。
- 仅使用IFS:TF降低但SC不足(位置模糊未解决)。
- 联合使用:指标全面优化,验证协同效应。
- 超参数分析 :
- 分组数 G G G 和邻域窗口 L L L 的平衡: G = 8 G=8 G=8 , L = 5 L=5 L=5 时取得最优权衡。