一、删除公共字符
题目解析

题目给了两个字符串(其中包含空格),让我们在第一个字符串中删除第二个字符串中的字符。
我们要输出删除后的字符串。
算法思路
这道题,如果直接按照题目中的要求去第一个字符串中删除字符,那还是有一点难度的。
我们通过观察题目可以发现,第二个字符串
str2中的所有字符,我们都要在str1中删除;那我们不妨记录一下
str2中出现的字符 ,这样再遍历str1,再将str2中出现的字符进行删除;这里还可以进行一下优化:我们知道在一个字符串中删除一个字符,代价是很大的 ,所以我们重新定义一个字符串
ret,如果str1中字符在str2中没有出现,就放到ret中去。
大致思路就如上所示,现在来梳理一下整个过程
遍历
str2记录其中所有的字符: 首先要记录str2中出现的所有字符,这里定义一个数组即可(大小200左右应该就够用);遍历
str1,将str2中没有出现的字符放到新的字符串中: 这里也可以不定义新的字符串,直接输出字符即可。
代码实现
cpp
#include <iostream>
#include <string>
using namespace std;
int main() {
string s,t;
getline(cin,s);
getline(cin,t);
bool hash[200] ={false};
for(auto& e:t)
{
hash[e] = true;
}
string ret;
for(auto& e:s)
{
if(hash[e] == false)
ret+=e;
}
cout<<ret<<endl;
return 0;
}二、两个链表的第一个公共结点
题目解析
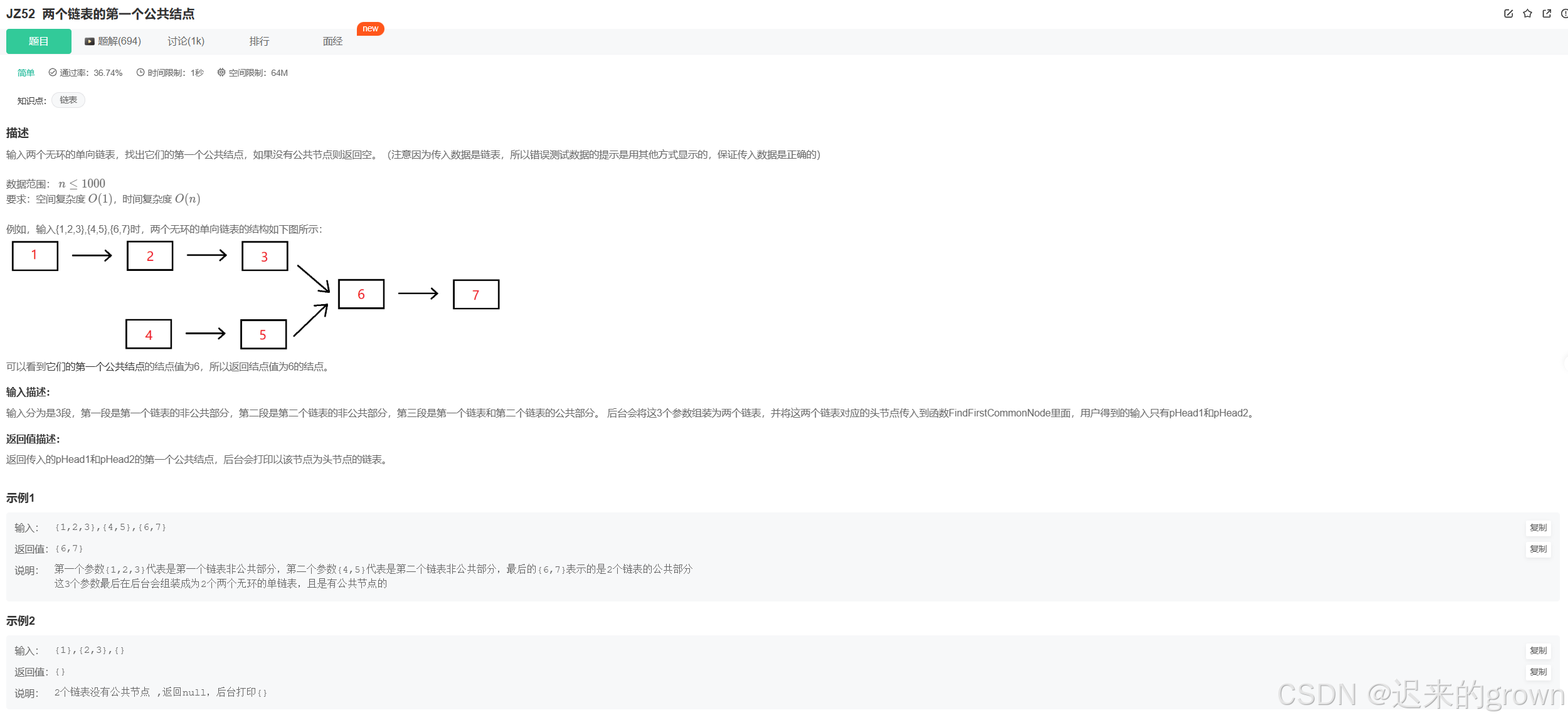
这两道题可以说
老朋友了,在之前初学链表时,就做过这道题了;题目还是给了两个链表,让我们找出来它们相交的第一个节点并返回;如果不相交就返回
nullptr
算法思路
对于这道题,先来看思路一(也是之前做这道题的思路)
分别遍历两个链表,记录分别有多少个节点;
让指向长链表的指针先走(两个链表节点数的差值 )
x步。然后再同时遍历,直到两个指针相等(如果链表不相交,两个链表遍历到
nullptr。返回当前两个指针相等的位置即可。
这里就不过多叙述了,现在来看思路二:
它们给了两个链表,我们将这两个链表分为以下三个部分
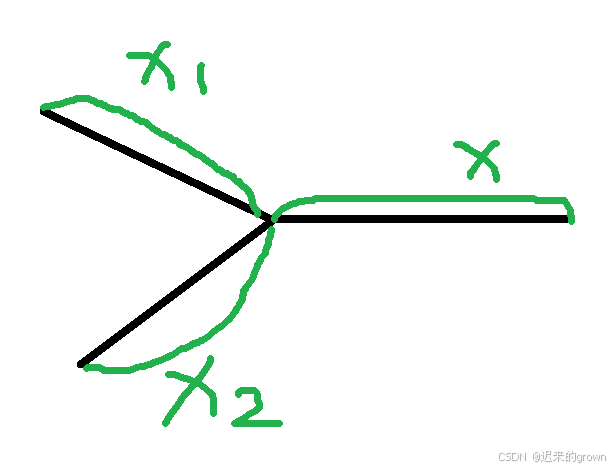
观察上图,我们可以得到一个等式关系:
x1 + x + x2 = x2 + x + x1。(看到这,这不肯定相等吗,就换了一个位置)那我们如果这样来理解呢:
- 我们让
cur1先遍历x1 + x的部分 ,遍历完后再让cur1去遍历x2部分。- 同时让
cur2遍历x2 + x的部分 ,遍历完后再让cur2去遍历x1部分。- 因为
x1 + x + x2 = x2 + x + x1,所以我们cur1和cur2会同时遍历到两个链表相交的第一个节点的位置。那如果两个链表不相交怎么办?
这个就很好说了,没有相交部分
x = 0,那cur1和cur2就会同时遍历到nullptr位置,最后返回即可。
代码实现
cpp
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
ListNode* cur1 = pHead1;
ListNode* cur2 = pHead2;
while (cur1 != cur2) {
cur1 = cur1 == nullptr ? pHead2 : cur1->next;
cur2 = cur2 == nullptr ? pHead1 : cur2->next;
}
return cur1;
}
};三、mari和shiny
题目解析

题目给了一个字符串,让我们找出这个字符串中一个有多少个
shy子序列这里要注意,是子序列而不是子数组,这里子序列可以是不连续的;
通过示例一也可以看出来。
算法思路
这道题让我们找出shy子序列,虽然说是不连续的,但是shy相对位置是固定的;(也就是说hsy、yhs这些是不算shy子序列的)
首先来看我们这道题暴力解法:
遍历字符串,遇到
s就在s后面找hy;找
hy是,遍历到h再在后面找y;
这要通过多层循环,可以说非常麻烦的。
现在来进行一下优化:
我们要找
shy,那就要先找到sh;找sh就要先找到s;(这里我们定义数组s,h,y)
s[i]:表示区间[0,i]中s的数量。h[i]:表示区间[0,i]中sh的数量。y[i]:表示区间[0,i]中shy的数量
现在我们来尝试去推到一下状态转移方程。
如果
i位置是s,那**s[i] = s[i-1]+1;否则s[i] = s[i-1]。**如果
i位置是h,那区间[0,i]中sh就可以分成两部分(一部分在区间[0,i-1]中的sh,另一部分就是区间[0,i-1]中的s和i位置的h组成的sh)那我们的**h[i] = h[i-1] + s[i-1];否则h[i] = h[i-1](i位置不是h**)。如果
i位置是y,那区间[0,i]中的shy就可以分为两部分(一部分是区间[0,i-1]中的shy,另一部分是区间[0,i-1]中的sh和i位置的y组成的shy)那我们的**y[i] = y[i-1] + h[i-1];否则y[i] = y[i-1](i位置不是y**)。
状态转移方程如上,现在来进行一下优化:
如果我们真的创建三个
dp表s,h,y;那未免一些太浪费空间了,我们可以使用三个变量来代替s,h,y
- 遍历字符串
str:- 遇到
s:s++;(表示区间[0,i]内s的数量)- 遇到
h:h+=s(表示区间[0,i]内sh的数量)- 遇到
y:y+=h(表示区间[0,i]内shy的数量)最后我们输出
y即可。
代码实现
这里要注意数据的范围,
1 <= n <= 300000,我们如果使用int来计数会超出范围的,要是有long long。
cpp
#include<iostream>
#include<string>
using namespace std;
int main()
{
int n;
string str;
cin>>n>>str;
long long s = 0,h = 0,y = 0;
for(int i=0;i<n;i++)
{
if(str[i] == 's') s++;
else if(str[i] == 'h') h+=s;
else if(str[i] == 'y') y+=h;
}
cout<<y<<endl;
return 0;
}到这里本篇博客就结束了,感谢支持
继续加油哇!!!