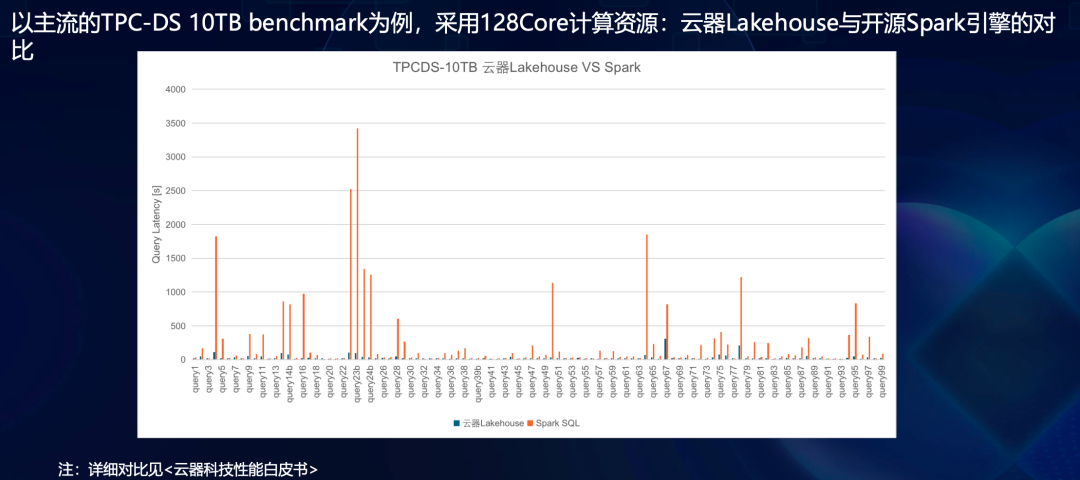
云器科技与2024年末发布TPC-DS基准测试报告:性能超Spark十倍。
在今年1月举行的GA产品发布会上,CTO关涛首次系统解读了此前发布的性能测试报告,详细阐释了云器Lakehouse引擎如何实现"10倍"的技术路径。
本报道对云器的技术解读进行总结呈现,帮助业内人士了解这一性能突破背后的技术细节。

云器Lakehouse公布的性能报告显示比开源Spark引擎快约10倍,具体测试对比在TPC-DS 10TB基准测试使用128核计算资源,同时保持相同的数据准确性和兼容性。详情请见性能测试报告。
(https://www.yunqi.tech/resource/blogs/lakehouse-performance)
十倍性能提升从何而来?
在技术竞争的喧嚣中,我们常见各种性能指标的发布和对比,甚至争吵。然而,正如云器首席架构师CTO关涛所言:"指标是表面的,背后技术是真实的。"指标可以通过多种手段进行"优化",包括测试方法调整、特定场景优化甚至选择性展示。本文希望通过解读这些表面数字背后的技术点,真正帮读者拆解了解实现这些改进点的差异价值。
本文旨在揭开表象看本质,直接审视支撑这些性能的核心技术创新。通过解析云器Lakehouse系统架构的关键技术点,我们将看到这些十倍性能提升究竟源自何处,以及这些技术如何在实际业务场景中转化为真实价值。只有理解了技术本质,才能真正判断性能提升的含金量和可持续性。
一、从技术进步说起:硬件、软件与网络技术的协同进化
🚀 在详解具体的技术优化点之前,让我们先从宏观上分析哪些大的技术进步带来性能红利。这些技术进步包括:硬件的进步,以及硬件供应链的提升。
1. 近年来硬件与基础设施的进步
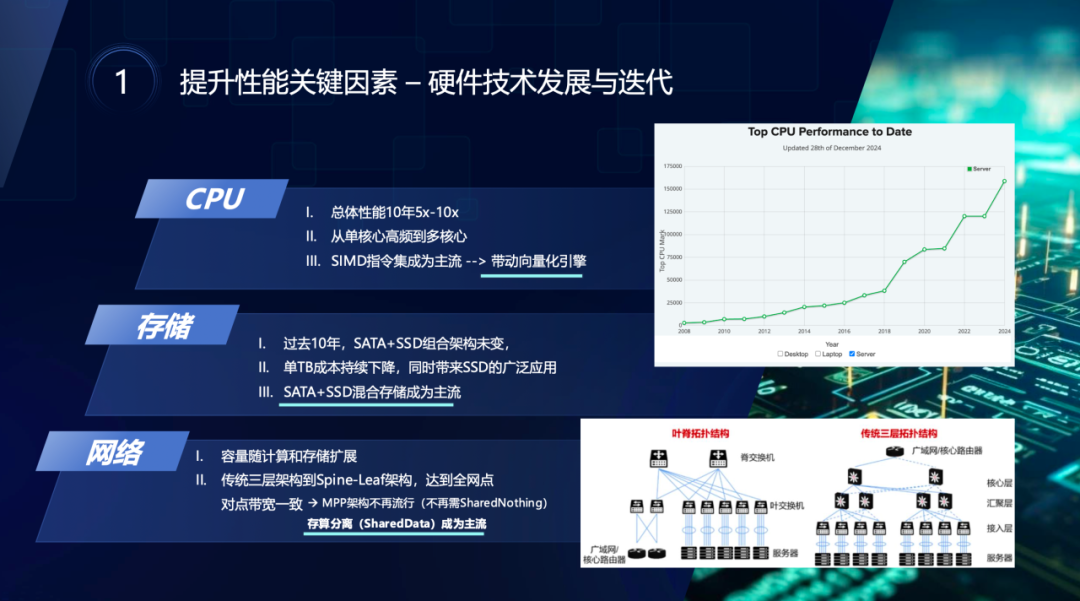
数据处理性能的提升离不开底层硬件与基础设施的革新。关涛分享了过去十年间,计算环境经历了几项关键变革:
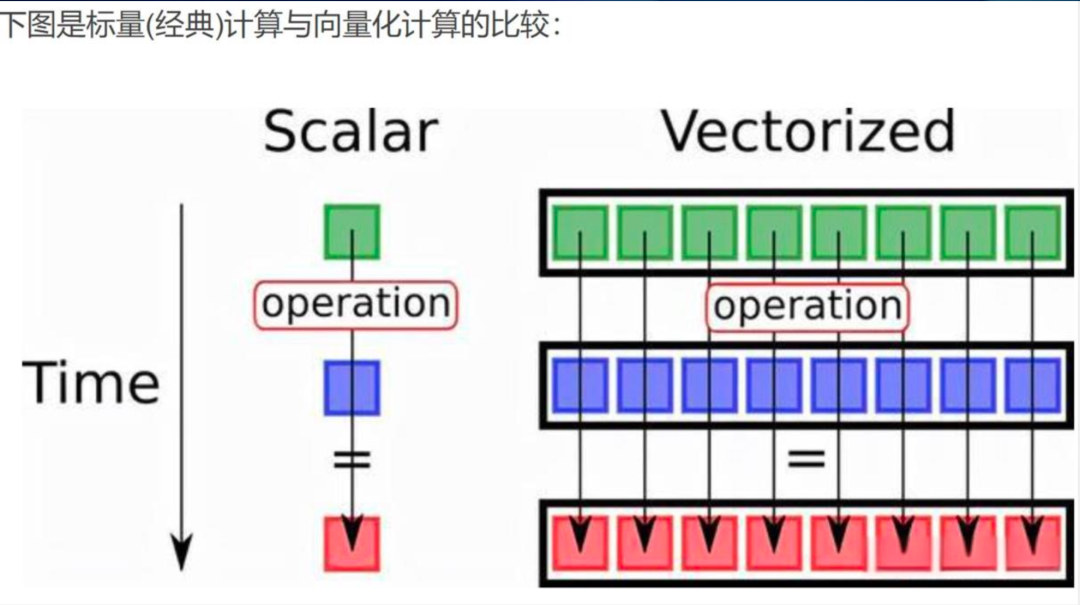
计算能力显著增强:服务器CPU从单核高频向多核架构演进,现代处理器可集成数百核心。同时,SIMD指令集(如AVX-512)提供了强大的向量化计算能力,使数据引擎从"一次处理一个值"转向"一次处理一批值"。这种向量化趋势已成为主流,几乎所有现代分析引擎都采用此技术。
存储性能迭代升级:存储系统经历了从机械硬盘到固态硬盘再到持久化内存的演进。虽然机械硬盘仍未被完全取代,但混合存储架构已成为标准配置。单盘容量持续增加,同时价格持续下降,为大规模数据处理创造了条件。
网络架构全面革新:数据中心网络完成了向Spine-Leaf架构的升级,实现了全网点对点高带宽且一致的连接特性。这解决了传统网络带宽不平衡的问题,使存算分离架构成为可能,数据能够更加自由地流动。
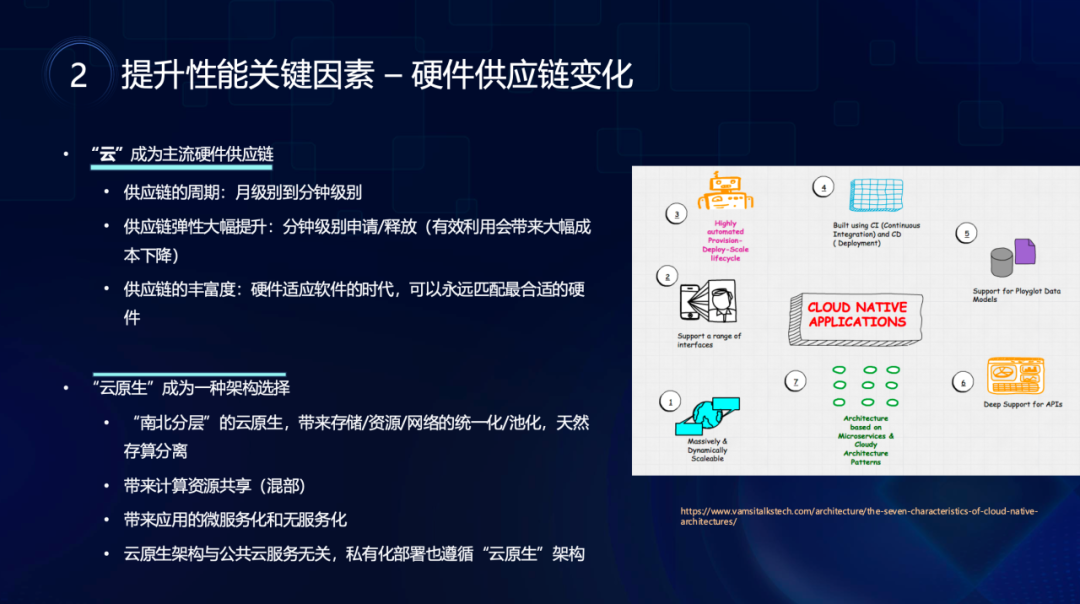
2. 云计算带来的基础设施变革
云计算的普及彻底重塑了硬件供应链,为数据处理系统创造了新的优化空间:
资源弹性显著提升:硬件供应周期从"月"级别压缩到"分钟"级别,企业可以根据实际需求快速调整资源配置,大幅提高资源利用效率。
硬件选择多样化:云平台提供了丰富的硬件组合选项,数据系统可以为不同工作负载匹配最适合的硬件,实现"软件适应硬件"的灵活部署模式。
云原生架构兴起:基于云的"南北分层"架构逐渐成熟,通过合理利用按需实例、Spot实例等资源模型,系统可以在保持高性能的同时优化成本结构。
这些变化为软件系统优化创造了新机会。
除了乘上了软硬件网络的技术红利,云器采用了哪些特别的技术方案优化性能呢?
二、核心技术解析:云器性能优化的四个乘数
10倍性能的详细拆解
云器Lakehouse的性能提升来自多个技术共同作用。关涛用一个简单公式说明:2×3×1.3×1.3≈10.14,把10倍性能分成四部分:
-
C++向量化引擎:约3倍性能提升
-
高级查询优化器:约2倍性能提升
-
直连调度优化:约1.3倍性能提升
-
自适应缓存系统:约1.3倍性能提升
特别的,两个系统在测试中都应用了相同的数据组织优化策略,包括适当的分桶、排序处理以及统计信息增强(Analyze)。
1. C++向量化引擎:3倍提升的核心引擎
C++向量化引擎是云器Lakehouse性能提升的最大来源,单独带来约3倍性能提升。关涛展示了数据对比:同一查询在传统引擎需要15秒,在C++向量化引擎只需5秒,资源用量减少60%。这是由于云器采用了全Native C++实现的Columnar与Codegen结合的执行引擎,充分利用现代CPU的AVX512向量化指令集。------在上一段我们提到CPU架构从单核心高频向多核心转变,SIMD指令集成为主流,这正是向量化引擎的技术基础。
下表展示了基于JVM的Spark引擎与C++向量化引擎在处理大规模数据时的主要差异:
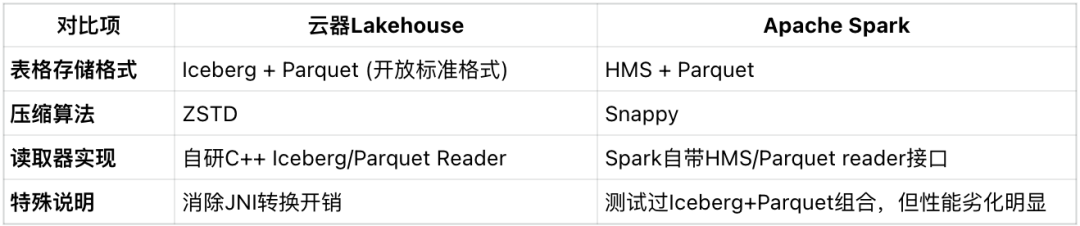
存储层设计与优化
同时,云器Lakehouse在存储层采用了现代湖仓一体化设计,基于自研的C++ Iceberg/Parquet读取器,直接消除了Java原生接口带来的JNI转换开销。
2. 高级查询优化器:2倍提升
关涛介绍的另一个关键技术是云器的高级查询优化器,这部分单独贡献了约2倍性能提升。
"查询优化本质上是个NP完全问题,"关涛解释,"一个包含10个表的Join查询,理论上有超过17万种可能的Join顺序。这种复杂性使得寻找最优执行计划异常困难,尤其在统计信息不足的情况下。"
传统大数据引擎如Spark和Flink主要依赖规则基础优化器(RBO),预定义转换规则如谓词下推、列裁剪等。"规则优化在简单查询上效果尚可,但面对复杂SQL时完全无法胜任。它不能根据数据特征动态调整策略,无法评估不同执行路径的实际成本差异。"
云器团队选择了自研基于Cascades模型的成本优化器(Cost Based Optimzer)方案。"这是一直以来很有挑战的题目"关涛表述,"我们团队花了两年时间才打造出生产级实现,支持精确成本评估和优化。"
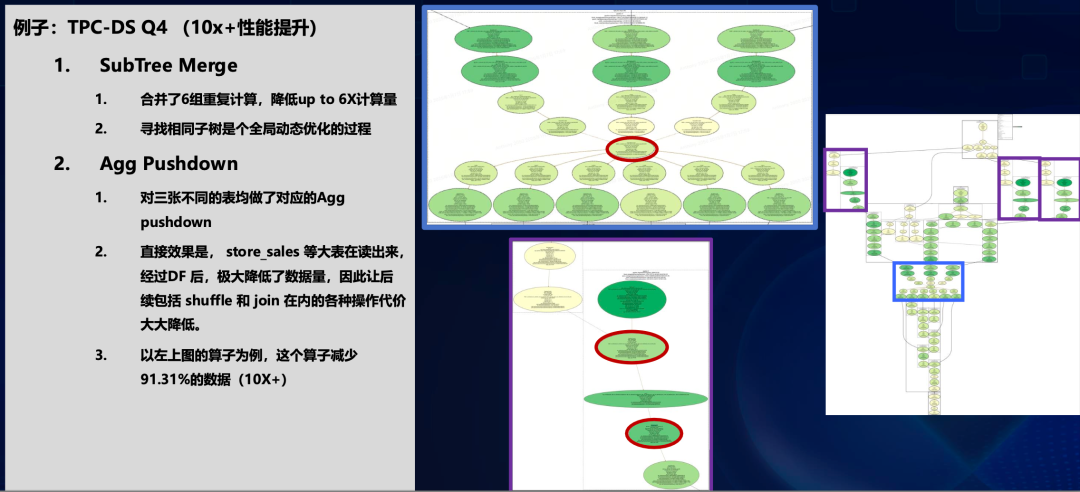
云器的Cascades优化器将查询处理分为逻辑优化和物理优化两阶段,使用特殊的备忘录结构高效探索庞大的计划空间。关涛展示了部分TPC-DS中的实际测试效果:
在Q4查询中,优化器通过SubTree Merge合并了6组重复计算,降低了6倍计算量;通过Agg Pushdown将聚合操作下推,减少了91.31%的数据量,带来10倍以上加速。
在Q51查询中,Shuffle Removal技术合并并节省了5个Shuffle过程,贡献了约5倍性能提升。
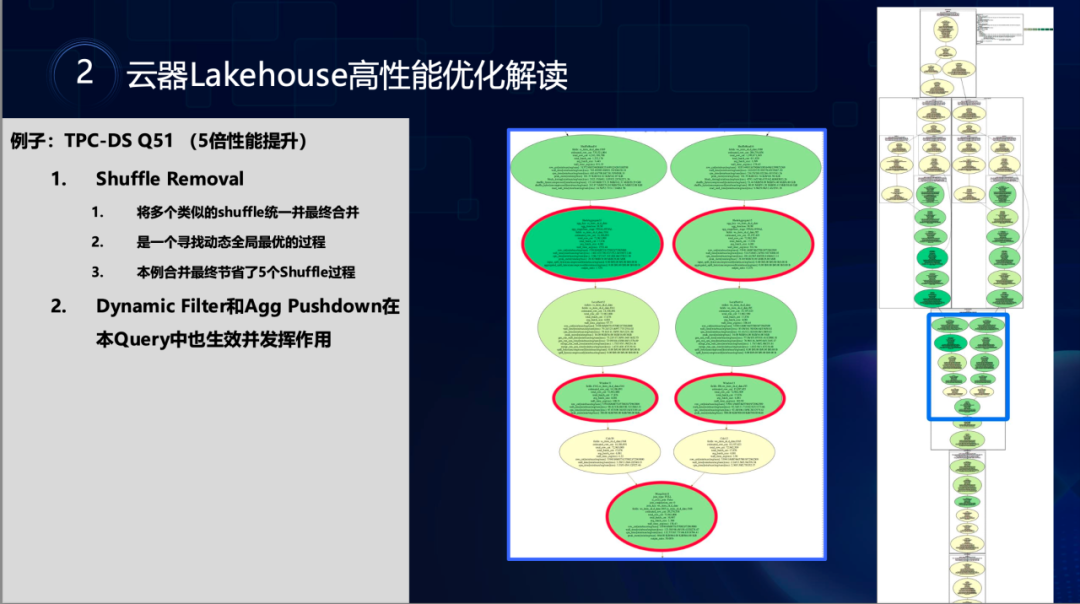
"我们实现了动态过滤的四种算法和五种过滤函数组合,能针对不同数据特征选择最优方案。"相比之下,即使启用AQE功能,Apache Spark的优化器在执行计划层面仍然无法进行这种深度优化,经常出现多读和重复读的情况,导致性能差距明显。
最后,面对复杂多变的实际环境,云器还引入了学习型优化(LBO)作为补充。"当统计信息不够准确时,基于历史执行的学习模型可以弥补缺陷,"。
3. DAG直连调度:系统效率的精细优化,1.3倍提升
直连调度和自适应缓存技术各自为系统性能带来约1.3倍的提升。
直连调度模式
传统Spark采用BSP(Bulk Synchronous Parallel)模式,每个阶段完成后才开始下一阶段,中间结果需写入磁盘。直连调度引入了MPP架构的数据流特性,使数据能够在节点间直接流动,避免不必要的落盘操作。
该技术实现了三个关键优化:
-
流水线执行:多个算子可并行工作
-
直接内存传输:减少数据序列化/反序列化开销
-
异步I/O处理:提高CPU利用率
云器Lakehouse同时支持BSP和MPP两种调度架构并可灵活切换。BSP模式(GP模式)适合大作业,具有更好的故障恢复能力;MPP模式(AP模式)适合小作业,性能更高。在TPCDS-10TB测试中,通过网络直连实现的MPP模式显著降低了shuffle读写操作,相比BSP模式单独提升了约30%的性能。
关涛认为,"一套引擎融合两种调度模式的架构有望成为行业未来的主流方向。"
自适应缓存:
通过在存储层之上,构建自适应的缓存层,提升IO吞吐和响应速度,能在一定程度提升性能。云器Lakehouse自带基于NVME存储的缓存系统,该系统自动根据负载加载和释放缓存。实践证明,大多数数据访问都遵循二八原则,高速缓存热数据,能有效提升性能。
本次基准测试,数据并未预先加载到缓存(cold run),而是在测试运行过程中,随数据访问逐步加载。实验结果表明,相比完全关闭缓存,上述自适应缓存能带来30%的提升。
技术发展与未来方向
回顾本文对云器Lakehouse各层优化的剖析,我们可以清晰看到其十倍性能提升并非源自单一技术突破,而是全栈式创新的综合结果。从存储层的格式优化与自研读取器,到智能数据缓存机制,再到运行时的多项关键改进,每一环节都经过精心设计与调优。
如果将这一性能突破放在大数据技术演进的历史背景中,"我们认为这是Lambda架构范式向Kappa架构,传统批处理到更有时效数据的处理------基于通用增量计算范式的转变。关涛谈到"之前,从Hadoop到Spark的演进带来了约10倍性能提升。如今,从Spark到新一代引擎同样实现了10倍提升,但路径更加多元化,涉及全栈优化。这反映了大数据技术的成熟度提升,创新不再来自单一突破,而是系统工程的整体提升。"
据关涛透露,云器团队正在研发更多性能优化技术,包括GPU加速、自适应执行计划、机器学习辅助优化等方向,预计未来两年内将带来额外2-3倍的性能提升。
"性能优化是永无止境的旅程,云器Lakehouse的10倍性能只是一个里程碑,而非终点。"
最后,就像关涛在演讲中引用Clickhouse的报告中的一段话,"TLDF: All Benchmarks are Liars"。性能指标是针对特定场景的测试。而真正重要的是在用户实际场景中体现的性能。云器Lakehouse在国内外多云上提供服务,欢迎大家试用,用自己的场景和数据,验证上述性能优化。
