随着计算机硬件的发展,编程语言无法充分利用CPU多核特性,并且缺乏一个简洁高效的语言,因此2007 年,谷歌工程师 Rob Pike, Ken Thompson 和 Robert Griesemer 设计了Go语言 ,它有以下特点:
- 静态类型+编译型语言,运行速度快
- 脚本化编程语言,易于编写
- 从 C 语言中继承了很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等,也保留了和 C 语言一样的编译执行方式及弱化的指针
- 引入包的概念,用于组织程序结构,Go 语言的一个文件都要归属于一个包,而不能单独存在
- 垃圾回收机制,内存自动回收,不需开发人员管理
- 从语言层面支持并发
- 吸收了管道通信机制,形成 Go 语言特有的管道 channel 通过管道 channel , 可以实现不同的 goroute之间的相互通信。
- 函数可以返回多个值
- 新的创新:比如切片 slice、延时执行 defer
Quick Start
如下所示为一个hello.go文件
go
// 每个文件都必须归属于一个包
package main
// 引入一个包 fmt
import "fmt"
// 主程序入口
func main(){
// 调用 fmt 包的函数 Println 输出
fmt.Println("hello world!")
}通过命令go build hello.go可以对源代码进行编译,生成可执行文件然后允许;也可以直接go run hello.go,会自动编译运行代码
Go 语言严格区分大小写;
编译器是按行进行编译的,一行只能由一条语句,且结尾不需要用分号;
go 语言定义的变量或者 import 的包如果没有使用到,代码不能编译通过;
go函数体的{需要放在行尾,下面写法会报错
go
func main()
{
fmt.Println("hello world!")
}1 基本数据类型
变量
变量声明
有三种方式:
go
//第一种:指定变量类型,Go中声明后若不赋值,编译器会赋默认值例如int 的默认值是0
var i int
fmt.Println("i=", i)
//第二种:根据值自行判定变量类型(类型推导)
var num = 10.11
fmt.Println("num=", num)
//第三种:省略var
name := "tom"
fmt.Println("name=", name)
//一次性声明多个变量的方式2
var n1, name , n3 = 100, "tom", 888
fmt.Println("n1=",n1, "name=", name, "n3=", n3)
//一次性声明多个变量的方式3, 同样可以使用类型推导
n1, name , n3 := 100, "tom~", 888
fmt.Println("n1=",n1, "name=", name, "n3=", n3)
// 一次性声明全局变量
var (
n3 = 300
n4 = 900
name2 = "mary"
)变量类型
和其它语言一样,可以理解为基本和复杂数据类型
基本数据类型:
- 整数类型(Integer Types):Go语言提供不同大小的整数类型,如int、int8(1字节)、int16、int32和int64。无符号整数类型有uint、uint8、uint16、uint32和uint64。整数类型的大小取决于计算机的架构,例如32位或64位。
- 浮点数类型(Floating-Point Types):Go语言提供float32和float64两种浮点数类型,分别对应单精度和双精度浮点数。
- 复数类型(Complex Types):Go语言提供complex64和complex128两种复数类型,分别对应由两个浮点数构成的复数。
- 布尔类型(Boolean Type):布尔类型用于表示真(true)和假(false)的值,用于条件判断和逻辑运算。
- 字符类型(Rune Type):用byte来保存单个字母字符
- 字符串类型(String Type):字符串类型表示一系列字符。字符串是不可变的,可以使用双引号"或反引号`来定义。
复杂数据类型:
- 数组类型(Array Types):数组是具有固定大小的同类型元素集合。声明数组时需要指定元素类型和大小。
- 切片类型(Slice Types):切片是对数组的一层封装,是动态长度的可变序列。切片不保存元素,只是引用底层数组的一部分。
- 映射类型(Map Types):映射是键值对的无序集合,用于存储和检索数据。键和值可以是任意类型,但键必须是可比较的。
- 结构体类型(Struct Types):结构体是一种用户定义的复合数据类型,可以包含不同类型的字段,每个字段有一个名字和类型。
- 接口类型(Interface Types):接口是一种抽象类型,用于定义一组方法。类型实现了接口的方法集合即为实现了该接口。
- 函数类型(Function Types):函数类型表示函数的签名,包括参数和返回值类型。函数可以作为参数传递和返回。
- 通道类型(Channel Types):通道是用于在协程之间进行通信和同步的一种机制。通道有发送和接收操作。
- 指针类型(Pointer Types):指针类型表示变量的内存地址。通过指针可以直接访问和修改变量的值。
go
var n1 = 100
// 查看某个变量的数据类型
fmt.Printf("n1 的 类型 %T \n", n1)
// 查看某个变量的占用字节大小和数据类型
var n2 int64 = 10
fmt.Printf("n2 的 类型 %T n2占用的字节数是 %d ", n2, unsafe.Sizeof(n2))
//Golang 的浮点型默认声明为float64 类型
var num5 = 1.1
fmt.Printf("num5的数据类型是 %T \n", num5)字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。对于传统的字符串是由字符组成的,而 Go 的字符串不同,它是由字节组成的.
Go字符采用UTF-8编码,如果字符在 ASCII 表的,比如0-1, a-z,A-Z...直接可以保存到 byte;如果字符对应码值大于 255,可以考虑使用 int 类型保存
go
var c1 byte = 'a'
//当我们直接输出byte值,就是输出了的对应的字符的码值
fmt.Println("c1=", c1)
//如果我们希望输出对应字符,需要使用格式化输出
fmt.Printf("c1=%c\n", c2)GO中的String字符串一旦定义不支持修改,
go
// 可以使用双引号、反引号包裹字符串
str3 := `
package main
import (
"fmt"
"unsafe"
)
`
// 可以使用 + 拼接字符串,注意换行时 + 在行尾
str4 := "hello " + "world" + "hello " + "world" + "hello " +
"world" + "hello " + "world" + "hello " + "world" +
"hello " + "world"Go 在不同类型的变量之间赋值时需要显式转换,转换是把i值赋值给n,i本身数据类型并不会变
go
var i int32 = 100
var n float32 = float32(i)
fmt.Printf("i type is %T\n", i) // int32
var n1 int32 = 12
var n2 int64
var n3 int8
// go不会进行自动类型转换,下面n2是int64,n1是int32,会编译报错
n2 = n1 + 20 可以使用fmt.Sprintf函数或者strconv包来实现基本类型转字符串
go
import (
"fmt"
_ "unsafe"
"strconv"
)
func main() {
var num1 int = 99
var num2 float64 = 23.456
var b bool = true
var myChar byte = 'h'
var str string //空的str
// fmt.Sprintf方法
str = fmt.Sprintf("%d", num1)
str = fmt.Sprintf("%f", num2)
str = fmt.Sprintf("%t", b)
str = fmt.Sprintf("%c", myChar)
//第二种方式 strconv 函数
var num3 int = 99
var num4 float64 = 23.456
var b2 bool = true
str = strconv.FormatInt(int64(num3), 10)
str = strconv.Itoa(num3)
// 'f' 格式 10:表示小数位保留10位 64 :表示这个小数是float64
str = strconv.FormatFloat(num4, 'f', 10, 64)
str = strconv.FormatBool(b2)
}使用strconv包实现str向其他数据类型的转换
go
var str string = "true"
var b bool
// 函数会返回两个值 (value bool, err error)略
b , _ = strconv.ParseBool(str)
var str2 string = "1234590"
var n1 int64
var n2 int
n1, _ = strconv.ParseInt(str2, 10, 64)
n2 = int(n1)
var str3 string = "123.456"
var f1 float64
f1, _ = strconv.ParseFloat(str3, 64)
// 如果转换失败,会返回该类型变量的默认值
var str4 string = "hello"
var n3 int64 = 11
n3, _ = strconv.ParseInt(str4, 10, 64)
fmt.Printf("n3 type %T n3=%v\n", n3, n3)Go中指针类型的用法和C语言一样:
- 基本数据类型,变量存的就是值,也叫值类型
- 指针类型:指针变量存的是一个地址,这个地址指向的空间存的才是值,
var ptr *int = &num - 用
&获取变量的地址,比如: var num int, 获取 num 的地址:&num - 用
*获取指针类型所指向的值,var ptr int, 使用ptr 获取 ptr 指向的值
go
var i int = 10
fmt.Println("i的地址=", &i)
var ptr *int = &i
fmt.Printf("ptr 本身=%v\n", ptr)
fmt.Printf("ptr 的地址=%v", &ptr)
fmt.Printf("ptr 指向的值=%v", *ptr)值类型:变量直接存储值,内存通常在栈中分配,包括基本数据类型 int 系列, float 系列, bool, string 、数组和结构体 struct
引用类型:变量存储的是一个地址,这个地址对应的空间才真正存储数据(值),内存通常在堆上分配,指针、slice 切片、map、管道 chan、interface 等都是引用类型
Go语言中通常使用fmt包中的scan函数获取标准输入
go
var name string
var age byte
var sal float32
var isPass bool
fmt.Println("请输入姓名 ")
// 1 使用Scanln获取一行输入
fmt.Scanln(&name)
// 2:fmt.Scanf,可以按指定的格式输入
fmt.Println("请输入你的姓名,年龄,薪水, 是否通过考试, 使用空格隔开")
fmt.Scanf("%s %d %f %t", &name, &age, &sal, &isPass)
fmt.Printf("名字是 %v \n年龄是 %v \n 薪水是 %v \n 是否通过考试 %v \n", name, age, sal, isPass)数组与切片
数组是多个相同类型数据的组合,一旦声明/定义了,其长度是固定的,不能动态变化。如下所示为数组的定义和使用
go
// 几种初始化数组的方式
var numArr01 [3]int = [3]int{1, 2, 3} // var 数组名 [数组大小]数据类型
var numArr02 = [3]int{5, 6, 7} // 省略变量类型
var numArr03 = [...]int{8, 9, 10} // 自动推导元素个数
var score = [...]int{1: 800, 0: 900, 2:999} // 定义各个元素
strArr05 := [...]string{1: "tom", 0: "jack", 2:"mary"} // 类型推导
// 遍历各个元素
for i := 0; i < len(score); i++ {
fmt.Printf("请输入第%d个元素的值\n", i+1)
fmt.Scanln(&score[i])
}
score[0] = 200
//变量数组打印
for i := 0; i < len(score); i++ {
fmt.Printf("score[%d]=%v\n", i, score[i])
}
for i, v := range score { // 也可以使用for range的方式遍历数组
fmt.Printf("i=%v v=%v\n", i , v)
}
// 定义/声明二维数组
var arr [4][6]int
// 赋初值
arr[1][2] = 1
arr[2][3] = 3
arr3 := [2][3]int{{1,2,3}, {4,5,6}}数组在内存中的分布是一整块地址空间,地址可以通过数组名来获取 &scorei,第一个元素的地址,就是数组的首地址,各个元素的地址间隔是依据数组的类型决定,比如 int64 -> 8个字节
数组创建后会为每个元素赋默认值
Go 的数组属值类型, 在默认情况下是值传递, 因此会进行值拷贝,数组间不会相互影响,如想在其它函数中,去修改原来的数组,可以使用引用传递(指针方式)
go
func test02(arr *[3]int) {
fmt.Printf("arr指针的地址=%p", &arr)
(*arr)[0] = 88 //!!
} 长度是数组类型的一部分,不同长度的数组可以认为是不同类型,因此在参数传递时需要注意。
切片Slice是数组的一个引用,因此切片是引用类型。切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度都一样。不同的是切片的长度是可以变化的,因此切片是一个可以动态变化数组
切片有两种定义方式
- 第一种是通过截取数组的一部分成为切片,由于切片是引用,其地址指向截取数组的开头;这时切片和数组其实指向同一块内存地址,对切片进行修改后,数组内容也会生效。
通过`var 切片名 []type = make([]type, len, [cap])`手动创建一个新的切片,type 就是数据类型, len 切片长度, cap 可选,指定切片容量。也可以省略make直接定义一个slice,其实现原理相同可以把切片看作一个结构体,包含指向首地址的指针、长度len和cap容量。容量是分配的地址空间指总共可容纳元素个数,比如一个slice虽然只有三个元素,但其空间容量为5;在slice长度动态增加超过容量时,会按照一定的规则扩容。slice扩容时会分配一片新的地址空间,然后把原有的值拷贝过去。
go
var arr [5]int = [...]int{10, 20, 30, 40, 50}
slice := arr[1:4] // 如果省略为arr[:4]代表从头开始,arr[1:]代表直到结尾
//使用常规的for循环遍历切片
for i := 0; i < len(slice); i++ {
fmt.Printf("slice[%v]=%v ", i, slice[i])
}
//使用for--range 方式遍历切片
for i, v := range slice {
fmt.Printf("i=%v v=%v \n", i, v)
}
slice2 := slice[1:2] // slice [ 20, 30, 40] [30]
slice2[0] = 100 // 因为arr , slice 和slice2 指向的数据空间是同一个,因此slice2[0]=100,其它的都变化
//用append内置函数,可以对切片进行动态追加
slice3 = append(slice, 400, 500, 600)
//通过append将切片slice3追加给slice3
slice3 = append(slice3, slice3...) // 100, 200, 300,400, 500, 600 100, 200, 300,400, 500, 600
//切片使用copy内置函数完成拷贝,举例说明
var slice4 []int = []int{1, 2, 3, 4, 5}
var slice5 = make([]int, 10)
copy(slice5, slice4)由于slice时引用,因此参数传递时是进行引用传递
go
func test(slice []int) {
slice[0] = 100 //这里修改slice[0],会改变实参
}
func main() {
var slice = []int {1, 2, 3, 4} // 省略make直接定义,有长度声明为数组,没有为slice
fmt.Println("slice=", slice) // [1,2,3,4]
test(slice)
fmt.Println("slice=", slice) // [100, 2, 3, 4]
}string 底层是一个 byte 数组,因此 string 也可以进行切片处理。由于string是不可变的,因此不能通过 str0 = 'z' 方式来修改字符串,可以先将其转为slice,然后进行修改
go
str := "hello@你好"
slice := str[6:] // 使用切片获取到子串
arr1 := []byte(str)
arr1[0] = 'z'
str = string(arr1)
// 如果需要处理中文,转为rune按字符处理切片
arr1 := []rune(str)
arr1[0] = '北'
str = string(arr1)Map
Go中集合map的 key 可以是很多种类型,比如 bool, 数字,string, 指针, channel , 还可以是只包含前面几个类型的 接口, 结构体, 数组。需要注意的是声明不会分配内存,初始化需要 make 分配内存后才能赋值和使用
go
var a map[string]string
a = make(map[string]string, 10) // 给map分配数据空间
a["no1"] = "value1"
cities := make(map[string]string) // 直接申请空间
heroes := map[string]string{ // 定义并初始化
"hero1" : "宋江",
}
heroes["hero2"] = "林冲"map的增删改查操作
go
cities := make(map[string]string)
cities["no1"] = "北京" // 新增
cities["no1"] = "上海~" // 修改
fmt.Println(cities)
delete(cities, "no1") // 删除元素
cities = make(map[string]string) // 如果希望一次性删除所有,make 一个新的,让原来的成为垃圾,被 gc 回收
fmt.Println(cities)
val, ok := cities["no2"] // 查找
if ok {
fmt.Printf("有no1 key 值为%v\n", val)
} else {
fmt.Printf("没有no1 key\n")
}map可以进行嵌套定义
go
studentMap := make(map[string]map[string]string)
studentMap["stu01"] = make(map[string]string, 3) // map的元素还是一个map
studentMap["stu01"]["name"] = "tom"
studentMap["stu01"]["sex"] = "男"
studentMap["stu02"] = make(map[string]string, 3)
studentMap["stu02"]["name"] = "mary"
studentMap["stu02"]["sex"] = "女"
for k1, v1 := range studentMap { // 使用for range进行遍历
fmt.Println("k1=", k1)
for k2, v2 := range v1 {
fmt.Printf("\t k2=%v v2=%v\n", k2, v2)
}
fmt.Println()
}切片的数据类型如果是 map,即map 切片,这样使用则 map 个数就可以动态变化了
go
var monsters []map[string]string //1. 声明一个map切片
monsters = make([]map[string]string, 2)
//2. 增加第一个妖怪的信息
if monsters[0] == nil {
monsters[0] = make(map[string]string, 2)
monsters[0]["name"] = "老张"
monsters[0]["age"] = "50"
}
newMonster := map[string]string{
"name" : "小李",
"age" : "20",
}
monsters = append(monsters, newMonster) // append函数动态的增加注意
- map 是引用类型,遵守引用类型传递的机制,在一个函数接收 map,修改后,会直接修改原来的 map
- map 的容量达到后,再想 map 增加元素,会自动扩容
2 流程控制
标识符
Golang 对各种变量、方法、函数等命名时使用的字符序列称为标识符。其命名规则如下:
- 由 26 个英文字母大小写,0-9 ,_ 组成
- 数字不可以开头
- Golang 中严格区分大小写。
- 标识符不能包含空格
- 下划线"_"本身在 Go 中是一个特殊的标识符,称为空标识符。可以代表任何其它的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能被作为占位符使用,不能作为标识符使用
- 不能以系统保留关键字作为标识符
- 变量名、函数名、常量名采用驼峰法命名
- 如果变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果小写,则只能在本包中使用。Go中没有可见性关键字,首字母大写是公开的,首字母小写是私有的
运算符
算术运算符:包含:+, - , * , / , %, ++, -- ,需要注意的是Go中的自增、自减运算符没有返回值,因此不能将结果进行赋值或者进行运算
go
var i int = 1;
var j = i++ // 错误,不能赋值
if i++ > 10 { // 错误,不能参与比较
fmt.Println("ok")
}关系运算符:==、!=、>、<、>=、<=,用于比较数值,结果为bool值
逻辑运算符:用于连接逻辑表达式进行逻辑运算,与&&、或||、非!
位运算符:对二进制数据进行的运算(如加、减、乘、除)被称为位运算,即对二进制数的每一位进行操作的运算
| 运算 | 符号 | 规则 |
|---|---|---|
| 与 | & | 两个位都为1时,结果才为1 |
| 或 | 两个位都为0时,结果才为0 | |
| 异或 | ^ | 两个位相同为0,相异为1 |
| 取反 | ~ | 0变1,1变0 |
| 左移 | << | 各二进位全部左移若干位,高位丢弃,低位补0 |
| 右移 | >> | 各二进位全部右移若干位,高位补0或符号位补齐 |
赋值运算符就是将某个运算后的值,赋给指定的变量,包括=、+=、-=、*=、/=、%=,还有位运算相关的左移赋值<<=、右移赋值>>=、按位与赋值&=、 按位异或赋值^=、按位或赋值|=
分支语句
顺序分支,从上向下执行
单、双、多分支,通过if进行分支判断,需要注意的是:
- golang支持在if中,直接定义一个变量
- 单分支不能省略大括号
- else不要换行
go
if age := 20; age > 18 {
fmt.Println("已成年!")
} else {
fmt.Println("未成年!")
}
//多分支判断
var score int
fmt.Println("请输入成绩:")
fmt.Scanln(&score)
if score == 100 {
fmt.Println("奖励一辆BMW")
} else if score > 80 && score <= 99 {
fmt.Println("奖励一台iphone7plus")
} else {
fmt.Println("什么都不奖励")
}Switch的使用,注意
- go中不需要
break - switch\case后面可以跟常量、变量、表达式
- case后面可以同时匹配多个条件
- 通过关键字fallthrough实现穿透,执行下一个条件
go
var key byte
fmt.Println("请输入一个字符 a,b,c,d,e,f,g")
fmt.Scanf("%c", &key)
switch test(key)+1 {
case 'a':
fmt.Println("周一, 穿新衣")
fallthrough // 执行到这里会向下穿透一层,执行下面的一个case
case 'b':
fmt.Println("周二,当小二")
case 'c','d':
fmt.Println("周三,爬雪山")
//...
default:
fmt.Println("输入有误...")
}循环
golang中通过for来实现循环,有如下几种灵活的形式
go
for i := 1; i <= 10; i++ {
fmt.Println("你好,尚硅谷", i)
}
//for循环的第二种写法
j := 1 //循环变量初始化
for j <= 10 { //循环条件
fmt.Println("你好,尚硅谷~", j)
j++ //循环变量迭代
}
//for循环的第三种写法, 通常会配合break跳出循环
k := 1
for { // 这里也等价 for ; ; {
if k <= 10 {
fmt.Println("ok~~", k)
} else {
break
}
k++
}
// 通过for range遍历字符串和数组
str = "abc~ok"
for index, val := range str { // 遍历获取各个位置的字符
fmt.Printf("index=%d, val=%c \n", index, val)
}Go中的break默认跳出最近的一层循环;break和continue可以使用一个label指定跳出多层循环
go
lable2:
for i := 0; i < 4; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break lable2 // 跳转到最外层
}
fmt.Println("j=", j)
}
here:
for i:=0; i<2; i++ {
for j:=1; j<4; j++ {
if j==2 {
continue here
}
fmt.Println("i=",i,"j=",j)
}Golang中也支持使用goto跳转到代码的指定位置,但是这样会造成程序混乱可读性差,一般不支持使用。
3 函数
3.1 基本定义和使用
Go中函数的基本格式为
go
func 函数名 (形参列表)(返回值列表){
执行语句
return 返回值
}如下所示定义一个四则运算的函数,注意函数首字母需要大写才能被其他包使用
go
package utils
import (
"fmt"
)
func Cal(n1 float64, n2 float64, operator byte) float64 {
var res float64
switch operator {
case '+':
res = n1 + n2
case '-':
res = n1 - n2
case '*':
res = n1 * n2
case '/':
res = n1 / n2
default:
fmt.Println("操作符号错误...")
}
return res
}Go中也是用包对项目文件进行管理,通过package定义包名,每个文件都必须属于一个包下面;通过包还可以对函数和变量的作用域进行控制。如下所示通过引入上面包中定义的函数并进行调用,路径从 环境变量定义的$GOPATH 的 src 下开始;引入的时候可以为包取别名
go
package main
import (
"fmt"
util "go_code/chapter06/fundemo01/utils"
)
func main() {
var n1 float64 = 1.2
var n2 float64 = 2.3
var operator byte = '+'
result := util.Cal(n1, n2 , operator)
fmt.Println("result~=", result)
}如果要编译成一个可执行程序文件,就需要将这个包声明为 main , 即 package main 。如果是写一个库 ,包名可以自定义,在编译main文件时相关的库函数会被编译为以.a结尾的库文件
Go语言中的基本数据类型一般分配在内存中的栈区,引用数据类型分配在堆区。在调用一个函数时,会给该函数分配一个新的堆栈,不同的堆栈之间彼此不可见,因此函数变量彼此隔离。当一个函数调用完毕(执行完毕)后,程序会销毁这个函数对应的栈空间。因此在函数调用传递形参时需要注意传递的值仅在当前函数中可见。
基本数据类型和数组默认都是值传递的,即进行值拷贝,在函数内修改,不会影响到原来的值。如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。从效果上看类似引用
Go 函数不支持函数重载
在 Go 中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量。函数既然是一种数据类型,因此在 Go 中,函数可以作为形参,并且调用
go
func getSum(n1 int, n2 int) int {
return n1 + n2
}
func myFun(funvar func(int, int) int, num1 int, num2 int ) int { // 入参是一个函数类型
return funvar(num1, num2)
}
func main() {
res2 := myFun(getSum, 50, 60) // 将函数getSum作为参数传递
fmt.Println("res2=", res2)
}为了简化数据类型定义,Go 支持自定义数据类型
go
// 给int取了别名后, go认为myInt和int是两个类型
type myInt int go支持对返回参数进行命名
go
func getSumAndSub(n1 int, n2 int) (sum int, sub int){
sub = n1 - n2
sum = n1 + n2
// 返回值的顺序按照函数定义,与这里写的前后无关
return sub,sum
}Go 支持可变参数,可变参数需要放在形参列表最后
go
func sum(n1 int, args... int) int {
sum := n1
// 遍历可变参数列表args
for i := 0; i < len(args); i++ {
sum += args[i] //args[0] 表示取出args切片的第一个元素值,其它依次类推
}
return sum
}3.2 函数机制
init函数
每一个源文件都可以包含一个 init 函数,该函数会在 main 函数执行前,被 Go 运行框架调用;注意,import包中的函数优先于本文件执行,即执行顺序为:外部包、全局变量、init、main
go
var age = test()
// 全局变量是先被初始化的,我们这里先写函数
func test() int {
fmt.Println("test()") //1
return 90
}
// init函数,通常可以在init函数中完成初始化工作
func init() {
fmt.Println("init()...") //2
}
func main() {
fmt.Println("main()...age=", age) //3
}匿名函数
Go 支持匿名函数,匿名函数就是没有名字的函数,如下所示有三种使用场景
go
package main
import (
"fmt"
)
var (
// 定义全局匿名函数
Fun1 = func (n1 int, n2 int) int {
return n1 * n2
}
)
func main() {
// 定义匿名函数时就直接调用,只调用一次
res1 := func (n1 int, n2 int) int {
return n1 + n2
}(10, 20)
fmt.Println("res1=", res1)
// 将匿名函数赋给变量,通过a完成调用
a := func (n1 int, n2 int) int {
return n1 - n2
}
res2 := a(10, 30)
fmt.Println("res2=", res2)
// 全局匿名函数的使用
res4 := Fun1(4, 9)
fmt.Println("res4=", res4)
}闭包
闭包就是一个函数和与其相关的引用环境组合的一个整体
go
func AddUpper(n int) func (int) int {
return func (x int) int {
n = n + x
return n
}
}
func main() {
f := AddUpper(10)
fmt.Println(f(1))// 10 + 1 = 11
fmt.Println(f(2))// 11 + 2 = 13
}如上面代码所示,AddUpper返回一个匿名函数,其中用到了变量n,这样匿名函数和它用到的变量n就形成了一个闭包。这里的变量n是闭包的一个变量,只会初始化一次n=10,第一次调用结果n为11,第二次调用的时候n在11的基础上进行累加。
可以看到,使用闭包可以灵活定制并返回一个基数n为10的函数f
defer
Go中的延时执行机制,当执行到defer时,暂时不执行,会将defer的语句压入到独立的栈中;当函数执行完毕后,再按照先入后出的方式出栈执行。通常用于在函数执行完毕后,进行释放资源。在 defer 将语句放入到栈时,也会将相关的值拷贝同时入栈
go
func sum(n1 int, n2 int) int {
defer fmt.Println("ok1 n1=", n1) //defer 3. ok1 n1 = 10
defer fmt.Println("ok2 n2=", n2) //defer 2. ok2 n2= 20
n1++ // n1 = 11
n2++ // n2 = 21
res := n1 + n2 // res = 32
fmt.Println("ok3 res=", res) // 1. ok3 res= 32
return res
}
func main() {
res := sum(10, 20)
fmt.Println("res=", res) // 4. res= 32
}内置函数
- len:用来求长度,比如 string、array、slice、map、channel
- new:用来分配内存,主要用来分配值类型,比如 int、float32,struct...返回的是指针
- make:用来分配内存,主要用来分配引用类型,比如 channel、map、slice。
3.3 字符串
Go中常见的字符串处理相关函数
go
str2 := "hello北京"
// 字符串的长度,golang的编码统一为utf-8 ,字母和数字占一个字节,汉字占用3个字节,用rune(str)处理
r := []rune(str2)
for i := 0; i < len(r); i++ {
fmt.Printf("字符=%c\n", r[i])
}
//字符串转整数
n, err := strconv.Atoi("123")
if err != nil {
fmt.Println("转换错误", err)
}else {
fmt.Println("转成的结果是", n)
}
//4)整数转字符串
str = strconv.Itoa(12345)
//5)字符串 转 []byte
var bytes = []byte("hello go")
str = string([]byte{97, 98, 99})
fmt.Printf("str=%v\n", str)
//10进制转 2, 8, 16进制,返回对应的字符串
str = strconv.FormatInt(123, 16)
fmt.Printf("123对应的16进制是=%v\n", str)
//查找子串是否在指定的字符串中
b := strings.Contains("seafood", "mary")
//统计一个字符串有几个指定的子串 4
num := strings.Count("ceheese", "e")
// 不区分大小写的字符串比较(==是区分字母大小写的)
b = strings.EqualFold("abc", "Abc")
fmt.Println("结果","abc" == "Abc") // false 区分字母大小写
// 返回子串在字符串第一次出现的index值,如果没有返回-1 :
index := strings.Index("NLT_abcabcabc", "abc") // 4
// 返回子串在字符串最后一次出现的index
index = strings.LastIndex("go golang", "go") //3
//将指定的子串替换成 另外一个子串,n可以指定你希望替换几个,如果n=-1表示全部替换
str2 = "go go hello"
str = strings.Replace(str2, "go", "北京", -1)
// 按照指定的某个字符分割字符串
strArr := strings.Split("hello,wrold,ok", ",")
for i := 0; i < len(strArr); i++ {
fmt.Printf("str[%v]=%v\n", i, strArr[i])
}
//15)将字符串的字母进行大小写的转换:
str = "goLang Hello"
str = strings.ToLower(str)
str = strings.ToUpper(str)
//将字符串左右两边的空格去掉
str = strings.TrimSpace(" tn a lone gopher ntrn ")
// 将字符串左右两边指定的字符去掉
str = strings.Trim("! he!llo! ", " !")
// 判断字符串是否以指定的字符串开头:
b = strings.HasPrefix("ftp://192.168.10.1", "hsp") //true3.4 时间相关
如下所示为Go中时间有关函数的使用
go
//1. 获取当前时间
now := time.Now()
fmt.Printf("now=%v now type=%T\n", now, now)
//获取到年月日,时分秒
fmt.Printf("年=%v\n", now.Year())
fmt.Printf("月=%v\n", now.Month())
fmt.Printf("月=%v\n", int(now.Month()))
fmt.Printf("日=%v\n", now.Day())
fmt.Printf("时=%v\n", now.Hour())
fmt.Printf("分=%v\n", now.Minute())
fmt.Printf("秒=%v\n", now.Second())
//格式化日期时间
dateStr := fmt.Sprintf("当前年月日 %d-%d-%d %d:%d:%d \n", now.Year(),
now.Month(), now.Day(), now.Hour(), now.Minute(), now.Second())
fmt.Printf("dateStr=%v\n", dateStr)
//格式化日期时间,Go设计者规定了用2006-01-02 15:04:05这个常量来指代时间格式
fmt.Printf(now.Format("2006-01-02 15:04:05"))
fmt.Println()
fmt.Printf(now.Format("2006-01-02"))
fmt.Println()
// 休眠100毫秒
time.Sleep(time.Millisecond * 100)
// 获取秒和纳秒的时间戳
fmt.Printf("unix时间戳=%v unixnano时间戳=%v\n", now.Unix(), now.UnixNano())3.5 异常处理
Go 语言不支持传统的 try...catch...finally 这种处理,而是通过抛出一个 panic 的异常,然后在 defer 中通过 recover 捕获这个异常
go
func test() {
defer func() {
err := recover() // recover()内置函数,可以捕获到异常
if err != nil {
fmt.Println("err=", err)
}
}() // 定义并调用匿名函数
num1 := 10
num2 := 0
res := num1 / num2 // 除0异常
fmt.Println("res=", res)
}也可以使用errors.New抛出自定义异常;使用panic 内置函数可以接收 error 类型的变量,输出错误信息,并退出程序
go
func readConf(name string) (errInfo error) {
if name == "config.ini" {
return nil
} else {
return errors.New("读取文件错误..") // 抛出一个自定义错误
}
}
func test02() {
errInfo := readConf("config2.ini")
if errInfo != nil {
panic(errInfo) // 输出这个错误,并终止程序
}
}3.6 单元测试
Go 语言中自带有一个轻量级的测试框架 testing 和自带的 go test 命令来实现单元测试和性能测试
go
import (
"fmt"
"testing" //引入go 的testing框架包
)
func TestAddUpper(t *testing.T) { // 测试addUpper是否正确
res := addUpper(10) //调用
if res != 55 {
t.Fatalf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n", 55, res)
}
t.Logf("AddUpper(10) 执行正确...")
}- 测试用例文件名必须以 xxx_test.go 结尾。 比如 cal_test.go
- 测试用例函数必须以 Test 开头,一般来说就是 Test+被测试的函数名,比如 TestAddUpper
- TestAddUpper(t *tesing.T) 的形参类型必须是 *testing.T
- 一个测试用例文件中,可以有多个测试用例函数,比如 TestAddUpper、TestSub
- 运行测试用例指令
go test只有运行错误时会输出日志,go test -v运行正确或是错误,都输出日志 - 当出现错误时,可以使用 t.Fatalf 来格式化输出错误信息,并退出程序
- t.Logf 方法可以输出相应的日志
- 测试单个文件,一定要带上被测试的原文件
go test -v cal_test.go cal.go - 测试单个方法
go test -v -test.run TestAddUpper
4 面向对象
结构体
Golang 没有类(class),而是通过结构体(struct)来实现 OOP 特性的,它去掉了传统 OOP 语言的继承、方法重载、构造函数和析构函
数、隐藏的 this 指针等。
它仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其它 OOP 语言不一样,比如继承:Golang 没有 extends 关键字,继承是通过匿名字段来实现。
在创建一个结构体变量后,如果没有给字段赋值,都对应一个默认值,指针、slice、和 map 都是 nil ,即还没有分配空间,使用前记得手动make空间
如下所示为结构体四种声明和使用方式
go
type Person struct{
Name string
Age int
}
func main() {
var person Person // 1 直接声明
p2 := Person{"mary", 20} // 2 声明并初始化
p2.Name = "tom"
var p3 *Person= new(Person) // 3 使用指针
//p3是一个指针,标准赋值方式(*p3).Name = "smith",Go底层进行了处理,可以简写成 p3.Name = "smith"
(*p3).Name = "smith"
p3.Name = "john"
var person *Person = &Person{} //方式4-{}
(*person).Name = "scott"
person.Name = "scott~~"
}
// 返回结构体变量
var stu1 = Stu{"小明", 19} // stu1---> 结构体数据空间
var stu3 = Stu{ // 把字段名和字段值写在一起, 不依赖字段的定义顺序.
Name :"jack",
Age : 20,
}
// 返回结构体的指针类型
var stu5 *Stu = &Stu{"小王", 29} // stu5--> 地址 ---》 结构体数据[xxxx,xxx]
var stu7 = &Stu{
Name : "小李",
Age :49,
}
fmt.Println(stu1, stu3, *stu5, *stu7) //结构体是值类型,变量直接是值拷贝,修改不会传递;但是如果使用指针指向结构体地址,则修改的是同一个内容
go
var p1 Person
p1.Age = 10
p1.Name = "小明"
var p2 *Person = &p1 // 定义指针指向p1代表的结构体
p2.Name = "tom~" // 会同步修改p1的结构体
fmt.Printf("p2.Name=%v p1.Name=%v \n", (*p2).Name, p1.Name) // 注意.运算顺序比价高,(*p2)要括起来- 不同类型结构体之间进行强制类型转换时需要有完全相同的字段。
- 使用type关键字可以为变量赋别名,Go认为其是一种新的类型,但是可以通过类型转换
- struct 的每个字段上,可以写上一个 tag, 该 tag 可以通过反射机制获取,常用于序列化和反序列化。
go
type Monster struct{
Name string `json:"name"` // `json:"name"` 就是 struct的 tag
Age int `json:"age"` // 为了使外部包可见,变量名首字母大写
}
func main() {
//1. 创建一个Monster变量
monster := Monster{"小牛", 500}
//2. 将monster变量序列化为 json格式字串
jsonStr, err := json.Marshal(monster)
if err != nil {
fmt.Println("json 处理错误 ", err)
}
fmt.Println("jsonStr", string(jsonStr)) // 序列化输出为name,而不是Name
}方法
Golang 中的方法是作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型都可以有方法,不仅 struct
go
// 定义结构体和变量
type Person struct{
Name string
}
/*
func (recevier type) methodName(参数列表) (返回值列表){
方法体
return 返回值
}
*/
func (p Person) speak() { // 给Persion类型添加一个方法
fmt.Println(p.Name, "是一个goodman~") // 形参p是值传递
}
func main() {
var p Person
p.Name = "tom"
p.test() // test 方法只能通过 Person 类型的变量来调用
fmt.Println("main() p.Name=", p.Name) //输出 tom
}变量调用方法时,该变量本身也会作为一个参数传递到方法,如果变量是值类型则进行值拷贝,如果是引用类型则进行地址拷贝。因此需要修改变量本身需要传递指针类型。
如下需要注意函数和方法在使用方式上的不同:
go
//对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
func test01(p Person) {
fmt.Println(p.Name)
}
func test02(p *Person) {
fmt.Println(p.Name)
}
func main() {
p := Person{"tom"}
test01(p) // 只能传递值类型
test02(&p) // 只能传递指针
}
//对于方法,接收者为值类型时,可以直接用指针类型的变量调用方法,效果是值拷贝;反过来同样也可以。主要是看方法的定义是什么类型
func (p Person) test03() { // 接收值类型
p.Name = "jack"
fmt.Println("test03() =", p.Name)
}
func main() {
p := Person{"tom"}
p.test03() // 可以直接用值调用
(&p).test03() // 也可以用指针调用,但是本质仍然是值拷贝
}封装
Golang 的结构体没有构造函数,通常可以使用工厂模式来解决这个问题,并通过get/set方法对属性进行设置,这就是Go中对象封装的特性
go
type student struct{
Name string
score float64
}
//因为student结构体首字母是小写,因此是只能在model使用,通过定义外部可见的方法来提供初始化变量
func NewStudent(n string, s float64) *student {
return &student{
Name : n,
score : s,
}
}
func (s *student) GetScore() float64{ // 由于结构体score是小写,这里提供一个get方法供其他包获取查询
return s.score
}继承
在 Golang 中,如果一个 struct 嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性
go
type Student struct { // 父类
Name string
Age int
Score int
}
func (stu *Student) ShowInfo() { // 父类的公共方法
fmt.Printf("学生名=%v 年龄=%v 成绩=%v\n", stu.Name, stu.Age, stu.Score)
}
func (stu *Student) setScore(score int) {
stu.Score = score
}
type Pupil struct {
Student // 在子类中嵌入了Student匿名结构体
}
func (p *Pupil) testing() { // 定义子类的特有方法
fmt.Println("小学生正在考试中.....")
}
func main() {
pupil := &Pupil{}
pupil.Student.Name = "tom~" // 访问父类的属性
pupil.Age = 8 // 可以省略父类路径,编译器会自动进行属性查找
pupil.testing() // 调用子类方法
pupil.Student.setScore(70) // 调用父类方法,不论大小写都可以
pupil.Student.ShowInfo()
}通过子类对象访问父类字段、属性时,父类名可以省略,当子类和父类有相同的字段或者方法时,编译器采用就近原则先访问子类的;如希望访问父类的字段和方法,可以加上父类匿名结构体名来区分。
结构体嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错
如果一个 struct 嵌套了一个有名结构体,这种模式就是组合,在访问组合的结构体的字段或方法时,必须带上结构体的名字
go
type D struct {
a A //有名结构体
}
var d D
d.a.Name = "jack"嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
go
type Goods struct {
Name string
Price float64
}
type Brand struct {
Name string
Address string
}
type TV struct {
Goods // 多重继承
Brand
}
func main() {
tv2 := TV{
Goods{
Price : 5000.99,
Name : "电视机002",
},
Brand{
Name : "夏普",
Address :"北京",
},
}
}接口
interface 类型可以定义一组方法,但是不需要实现,并且不包含任何变量。当使用的时候,再根据具体情况进行实现
多态是面向对象的第三大特征,在 Go 语言,多态特征是通过接口实现的,即按照统一的接口来调用不同的实现。
go
type Usb interface { // 定义接口
Start() // 声明了两个没有实现的方法
Stop()
}
type Phone struct { // 定义结构体
}
func (p Phone) Start() { // 实现Usb接口的方法,Go中并不会显示指出实现的接口名,但是在调用的时候会校验是否实现了接口的所有方法
fmt.Println("手机开始工作。。。")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作。。。")
}
type Camera struct {
}
func (c Camera) Start() { // 实现Usb接口的方法
fmt.Println("相机开始工作。。。")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作。。。")
}
type Computer struct { // 通过计算机调用Usb接口
}
func (c Computer) Working(usb Usb) { // Working方法可以接收所有Usb接口类型变量
usb.Start() // 统一通过usb接口变量来调用Start和Stop方法
usb.Stop()
}
func main() {
computer := Computer{}
phone := Phone{}
camera := Camera{}
computer.Working(phone) // 统一对实现了接口的变量进行调用
computer.Working(camera)
}- 一个接口可以继承多个别的接口,这时如果要实现该接口,必须将父接口的方法也全部实现,注意多个接口之间不能有相同的方法名
- Interface 类型默认是一个指针(引用类型),如果没有初始化就使用,会输出 nil
- 空接口 interface{} 没有任何方法,所以所有类型都实现了空接口, 即我们可以把任何一个变量赋给空接口
go
type Stu struct {
}
type T interface{
}
func main() {
var stu Stu
var t T = stu // 将变量stu赋值给空接口类型的t
fmt.Println(t)
}和继承不同,实现接口可以在不改变结构体的基础上,对其功能进行扩展。
继承的价值主要在于:解决代码的复用性和可维护性。
接口的价值主要在于:设计好各种规范(方法),让其它自定义类型去实现这些方法
go
type Monkey struct {
Name string
}
func (this *Monkey) climbing() {
fmt.Println(this.Name, " 生来会爬树..")
}
type LittleMonkey struct {
Monkey //继承
}
//声明接口
type BirdAble interface {
Flying()
}
// 在不改变LittleMonkey的基础上,为其增加了新的方法
func (this *LittleMonkey) Flying() {
fmt.Println(this.Name, " 通过学习,会飞翔...")
}
func main() {
monkey := LittleMonkey{
Monkey {Name : "悟空",},
}
monkey.climbing()
monkey.Flying()
}通过类型断言,可以将一个接口转换成具体的类型
go
var x interface{}
var b2 float32 = 2.1
x = b2 //空接口,可以接收任意类型
if y, ok := x.(float32); ok { // 将接口类型x转换为float32
fmt.Printf("y 的类型是 %T 值是=%v", y, y)
} else {
fmt.Println("convert fail")
}如下所示,在遍历多态数组时,使用类型断言可以对不同的类型进行判断,进而执行不同的代码逻辑
go
func (computer Computer) Working(usb Usb) {
usb.Start()
if phone, ok := usb.(Phone); ok { // 使用类型断言,如果是Phone,额外执行Call方法
phone.Call()
}
usb.Stop()
}
func main() {
var usbArr [3]Usb
usbArr[0] = Phone{"vivo"} // 多态数组,存放实现了接口的不同类型对象
usbArr[1] = Phone{"小米"}
usbArr[2] = Camera{"尼康"}
var computer Computer
for _, v := range usbArr{ // 统一进行遍历
computer.Working(v)
fmt.Println()
}
}反射
反射可以在运行时动态获取变量的各种信息, 比如变量的类型(type),类别(kind),结构体的字段、方法;通过反射,可以修改变量的值,并且调用关联的方法
普通的数据类型通过interface可以和reflect.Type之间进行转换
go
func main() {
var num int = 100
reflectTest01(num)
}
func reflectTest01(b interface{}) {
//通过反射获取的传入的变量的 type , kind, 值
rTyp := reflect.TypeOf(b) // 获取 reflect.Type
fmt.Println("rType=", rTyp)
rVal := reflect.ValueOf(b) // 获取到 reflect.Value,注意这里rVal并不是真正的变量,而是反射的变量类型
n2 := 2 + rVal.Int() // 通过反射变量定义的方法获取到具体值
fmt.Println("n2=", n2)
// 反过来,先将 rVal 转成 interface{},再通过断言转成需要的类型
iV := rVal.Interface()
num2 := iV.(int)
fmt.Println("num2=", num2)
}
// 结构体的反射
func reflectTest02(b interface{}) {
rTyp := reflect.TypeOf(b) // 获取到 reflect.Type
rVal := reflect.ValueOf(b)
kind1 := rVal.Kind() // 获取 变量对应的Kind
kind2 := rTyp.Kind()
// 通过反射获取结构体的值
iV := rVal.Interface()
stu, ok := iV.(Student)
if ok {
fmt.Printf("stu.Name=%v\n", stu.Name)
}
}5 文件
Go在os.File 封装所有文件相关操作,File 是一个结构体
如下所示为读取文件两个方式
go
import (
"fmt"
"os"
"bufio"
"io"
)
func main() {
file , err := os.Open("d:/test.txt") // 打开文件
if err != nil {
fmt.Println("open file err=", err)
}
defer file.Close() // 结束时及时关闭file句柄,否则会有内存泄漏.
reader := bufio.NewReader(file) // 使用带缓冲区的读取
for {
str, err := reader.ReadString('\n') // 每读到一个换行就停止
if err == io.EOF { // io.EOF表示文件的末尾
break
}
fmt.Printf(str)
}
content, err := ioutil.ReadFile(file) // 使用ioutil.ReadFile一次性将文件读取,不需要手动进行打开关闭
if err != nil {
fmt.Printf("read file err=%v", err)
}
fmt.Printf("%v", string(content)) // []byte,把读取到的内容转为字符串
}如下所示为文件写入的方式
go
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666) // 以读写的方式进行打开,不存在则创建
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close()
str := "hello,Gardon\r\n"
writer := bufio.NewWriter(file) // 使用带缓存的 *Writer进行写入
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
writer.Flush() // 将缓存中的内容刷入文件go可以flag 包用来解析命令行参数
go
//定义几个变量,用于接收命令行的参数值
var user string
var pwd string
//"u" ,就是 -u 指定参数
//"" , 默认值
//"用户名,默认为空" 说明
flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.Parse() // 转换, 必须调用该方法
//输出结果
fmt.Printf("user=%v pwd=%v host=%v port=%v", user, pwd, host, port)使用json包对结构体进行序列化和反序列化
go
func testStruct() {
monster := Monster{
Name :"牛魔王",
Age : 500 ,
}
data, err := json.Marshal(&monster) //将monster 序列化
if err != nil {
fmt.Printf("序列号错误 err=%v\n", err)
}
fmt.Printf("monster序列化后=%v\n", string(data))
}
func unmarshalStruct() {
str := "{\"Name\":\"小王\",\"Age\":500,\"Birthday\":\"2011-11-11\",\"Sal\":8000,\"Skill\":\"eat\"}"
var monster Monster
err := json.Unmarshal([]byte(str), &monster) // 反序列化
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 monster=%v monster.Name=%v \n", monster, monster.Name)
}6 协程与管道
Goroutine
并发:多线程程序在单核上运行
并行:多线程程序在多核上运行
在 Go 主线程上,可以再起多个协程(Goroutine),它有如下特点:
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程,与线程实现并发相比资源消耗小
如下所示通过go开启了一个协程,它会和主线程同步一起执行,直到执行完成或者主线程退出
go
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("test () hello,world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
go test() // 开启了一个协程
for i := 1; i <= 10; i++ {
fmt.Println(" main() hello,golang" + strconv.Itoa(i)) // test和main会一起执行,交替输出
time.Sleep(time.Second)
}
}
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum) // check num of cpu
runtime.GOMAXPROCS(cpuNum - 1) // 设置使用多个cpuMPG模型:如图所示,有两个物理线程 M,每个 M 绑定一个处理器 P,并运行一个 Goroutine。
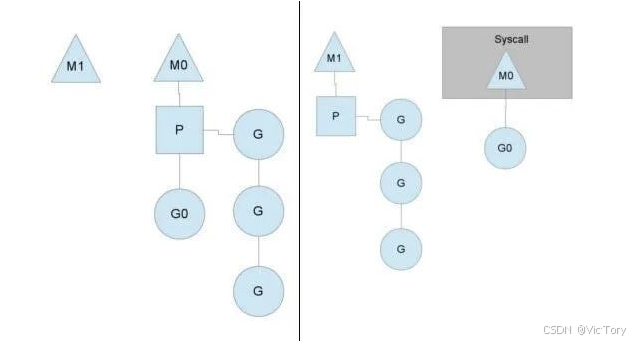
- P 的数量可以通过 GOMAXPROCS() 设置。它实际上表示真正的并发级别,即可以同时运行的 Goroutine 数量。
- 图中灰色的 Goroutine 尚未运行,处于就绪状态,等待被调度。P 维护了这些 Goroutine 的队列(称为运行队列 runqueue)。
- 每次执行 go 语句时,都会将一个 Goroutine 添加到运行队列末尾。在下一个调度点,会从运行队列中取出一个 Goroutine 执行
- 当某个操作系统线程(如 M0)被阻塞时(如下图所示),P 会切换到另一个线程(如 M1)。M1 可能是新创建的,也可能是从线程缓存中取出的。
- 当 M0 返回时,它需要尝试获取一个 P 来运行 Goroutine。如果无法获取 P,它会将 Goroutine 放入全局运行队列,并进入休眠状态(进入线程缓存)。所有 P 会定期检查全局运行队列,并运行其中的 Goroutine;否则,全局运行队列中的 Goroutine 将永远无法执行。
在使用多个协程运行程序的时候,很容易出现同时写入一个资源的冲突,有两种解决方式
- 使用全局互斥锁对资源进行加锁
- 使用管道 channel 来解决
如下所示通过启动多个协程计算 1-200 的各个数的阶乘
go
package main
import (
"fmt"
_ "time"
"sync"
)
var (
myMap = make(map[int]int, 10)
lock sync.Mutex //声明一个全局的互斥锁
)
func calculateN(n int) { // 计算n的阶乘
res := 1
for i := 1; i <= n; i++ {
res *= i
}
lock.Lock() // 操作myMap前加锁
myMap[n] = res
lock.Unlock()
}
func main() {
for i := 1; i <= 20; i++ { // 开启多个协程完成这个任务
go calculateN(i)
}
time.Sleep(time.Second * 5) // 主线程休眠等待协程运算结束
lock.Lock() // 读取myMap时也需要加锁
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
lock.Unlock()
}上面使用互斥锁的方式并不优雅,需要手动估算协程运行结束时间,通过全局变量加锁同步来实现通讯,也并不利用多个协程对全局变量的读写操作
服务器通常启动一个协程对请求进行响应
go
package main
import (
"fmt"
"net"
_"io"
)
func process(conn net.Conn) {
defer conn.Close() //关闭conn
// 循环接收客户端发送的数据
for {
buf := make([]byte, 1024)
// 等待客户端通过conn发送信息,如果客户端没有wrtie[发送],那么协程就阻塞在这里
n , err := conn.Read(buf) //从conn读取
if err != nil {
fmt.Printf("客户端退出 err=%v", err)
return //!!!
}
fmt.Print(string(buf[:n])) // 打印接收到的内容
}
}
func main() {
fmt.Println("服务器开始监听....")
listen, err := net.Listen("tcp", "0.0.0.0:8888") // 监听本地TCP的8888端口
if err != nil {
fmt.Println("listen err=", err)
return
}
defer listen.Close() //延时关闭listen
//循环等待客户端来链接
for {
fmt.Println("等待客户端来链接....")
conn, err := listen.Accept()
if err != nil {
fmt.Println("Accept() err=", err)
} else {
fmt.Printf("Accept() suc con=%v 客户端ip=%v\n", conn, conn.RemoteAddr().String())
}
// 启动协程处理客户端连接
go process(conn)
}
}channel
channel本质就是一个先进先出的队列,它本身就是线程安全的,支持多 goroutine 同时访问
go
// 创建一个可以存放3个int类型的管道
var intChan chan int
intChan = make(chan int, 3)
num := 211
intChan<- num // 向管道写入数
// 管道的实际长度和总cap(容量),写入数据时,不能超过其容量,超过再写入的话就会阻塞而报deadlock
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 3, 3
var num2 int
num2 = <-intChan // 从管道中读取数据,如果数据已经全部取出,再取就会报告 deadlock
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 2, 3
close(intChan) // 使用内置函数 close 可以关闭 channel, 关闭后就不能再向 channel 写数据了
close(intChan2) //在遍历时,如果channel没有关闭,则会出现deadlock的错误
for v := range intChan2 { // 需要使用for range进行遍历管道
fmt.Println("v=", v)
}当使用interface类型的管道时,需要注意从管道中取出来的还是interface类型,需要做一下转换
go
//定义一个存放任意数据类型的管道 3个数据
allChan := make(chan interface{}, 3)
cat := Cat{"小花猫", 4}
allChan<- cat
allChan<- 10
allChan<- "tom jack"
newCat := <-allChan
//fmt.Printf("newCat.Name=%v", newCat.Name) // 编译不通过
a := newCat.(Cat) //使用类型断言
fmt.Printf("newCat.Name=%v", a.Name)管道的一些使用细节:
go
//1. 在默认情况下下,管道是双向的,也可以声明为只读/只写
var chan2 chan<- int // 声明为只写
chan2 = make(chan int, 3)
chan2<- 20
var chan3 <-chan int // 声明为只读
num2 := <-chan3
// 2 在实际开发中,可能我们不好确定什么关闭该管道.可以使用select 方式可以解决
for {
select {
// 这里如果intChan一直没有关闭,不会一直阻塞而deadlock,会自动到下一个case匹配
case v := <-intChan :
fmt.Printf("从intChan读取的数据%d\n", v)
case v := <-stringChan :
fmt.Printf("从stringChan读取的数据%s\n", v)
default :
return
}
}