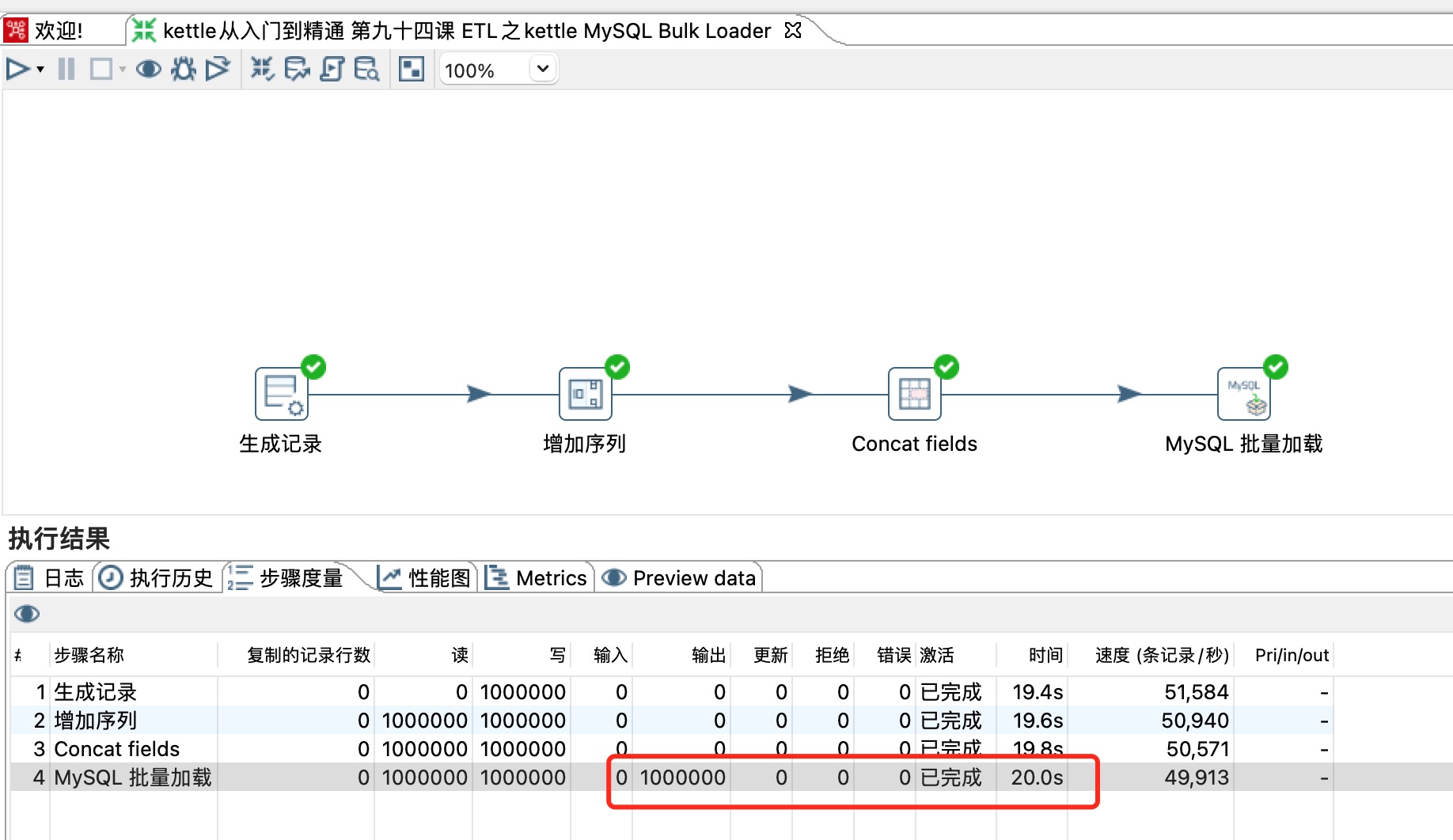
1、在使用kettle时如果对表输出性能要求,可以考虑用mysql 批量加载步骤,该步骤可以实现每秒5万+的数据同步(该数据仅是基于我本人的笔记本,若是服务器则效率更高),如下图所示:
2、原理
知其然知其所以然,之所以MySQL Bulk Loader速度如此之快是因为MySQL 批量加载器使用"LOAD DATA INFILE 'FIFO 文件' INTO TABLE ...."语句,将数据从 Kettle 内部流式传输到一个命名管道,再将其导入到数据库中。
关于所使用命令的更多信息,可在 MySQL 参考文档中查找:LOAD DATA INFILE语法。感兴趣的小伙伴可以查看mysql官方文档进一步学习,如下图所示:

3、上DEMO
本次使用的步骤有生成步骤、增加序列、 字段拼接、MySQL Bulk Loader四个步骤。
生成步骤:模拟生成100万条数据。
增加序列:生成唯一键。
字段拼接:修改生成的name字段。
MySQL Bulk Loader:将数据从 Kettle 内部流式传输到一个命名管道,再将其导入到mysql数据库中。注意windows不支持命名管道,mac和linux是支持的。
前三个步骤使用比较简单,今天重点介绍下MySQL Bulk Loader步骤,配置如下图所示:
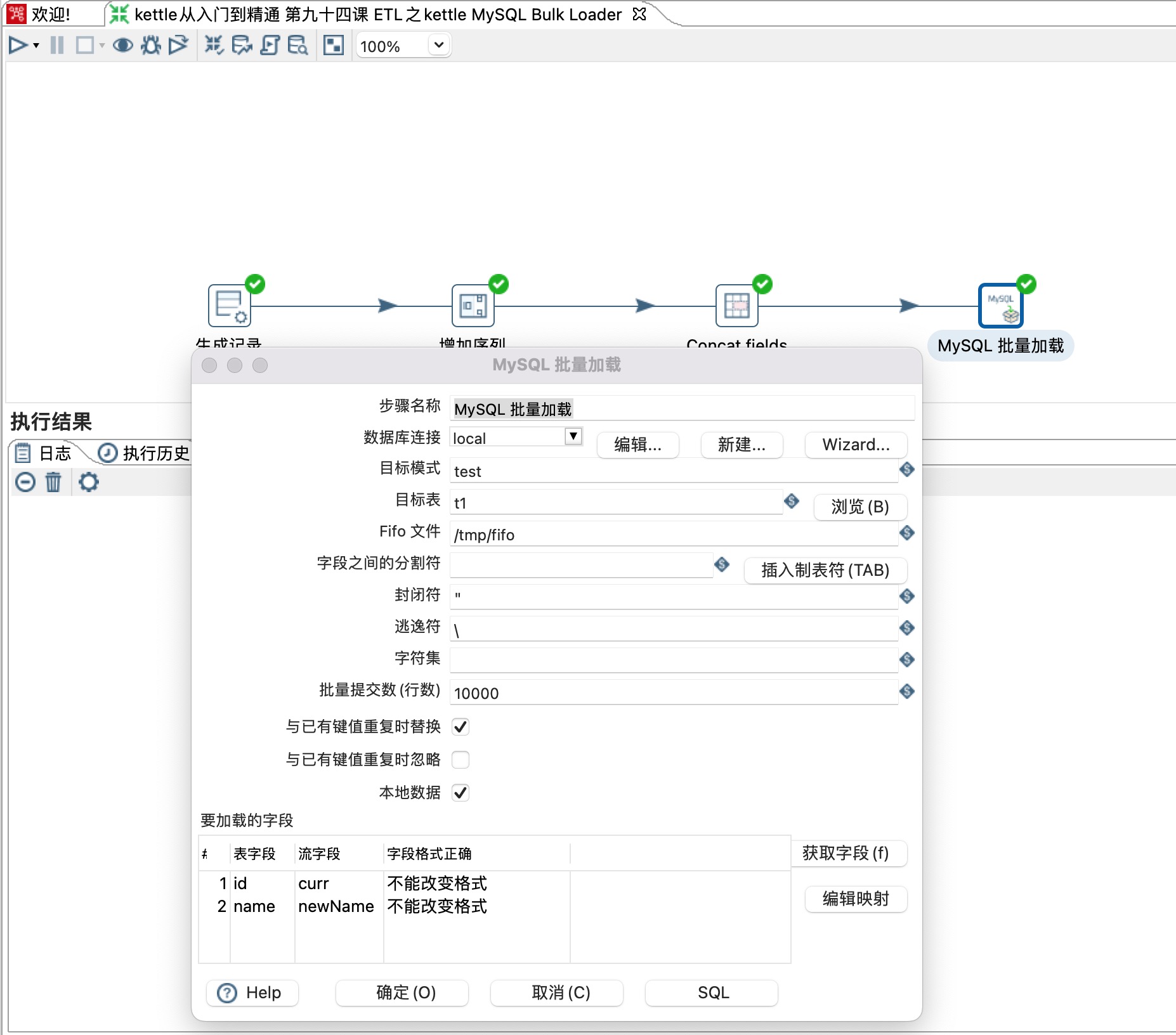
Fifo文件:这是用作命名管道的 FIFO 文件。如果该文件不存在,将使用 `mkfifo` 命令创建它,并使用 `chmod 666` 命令设置权限(这就是它在 Windows 系统中无法使用的原因)。
字段之间的分隔符:字段的分隔符。(若未指定,默认使用制表符。)
封闭符:用于字符串的定界符。来指定包裹字符串字段的符号,比如常见的引号 `"` 或单引号 `'` 等。
逃逸符:如果字段中包含定界符,则使用转义字符对其进行转义。
字符集:所使用的字符集(可选)。
批量提交行数:每x笔数据一起提交。
与已有键值重复时替换:如果勾选此项,"REPLACE" 将被添加到命令中。若你进行了这样的设置,输入的行将替换现有的行。换句话说,那些主键或唯一索引的值与现有行相同的行将被替换。
与已有键值重复时替换:如果勾选该选项,"IGNORE" 会被添加到命令中。若你进行了此设置,输入行中唯一键值与现有行重复的行将被跳过。
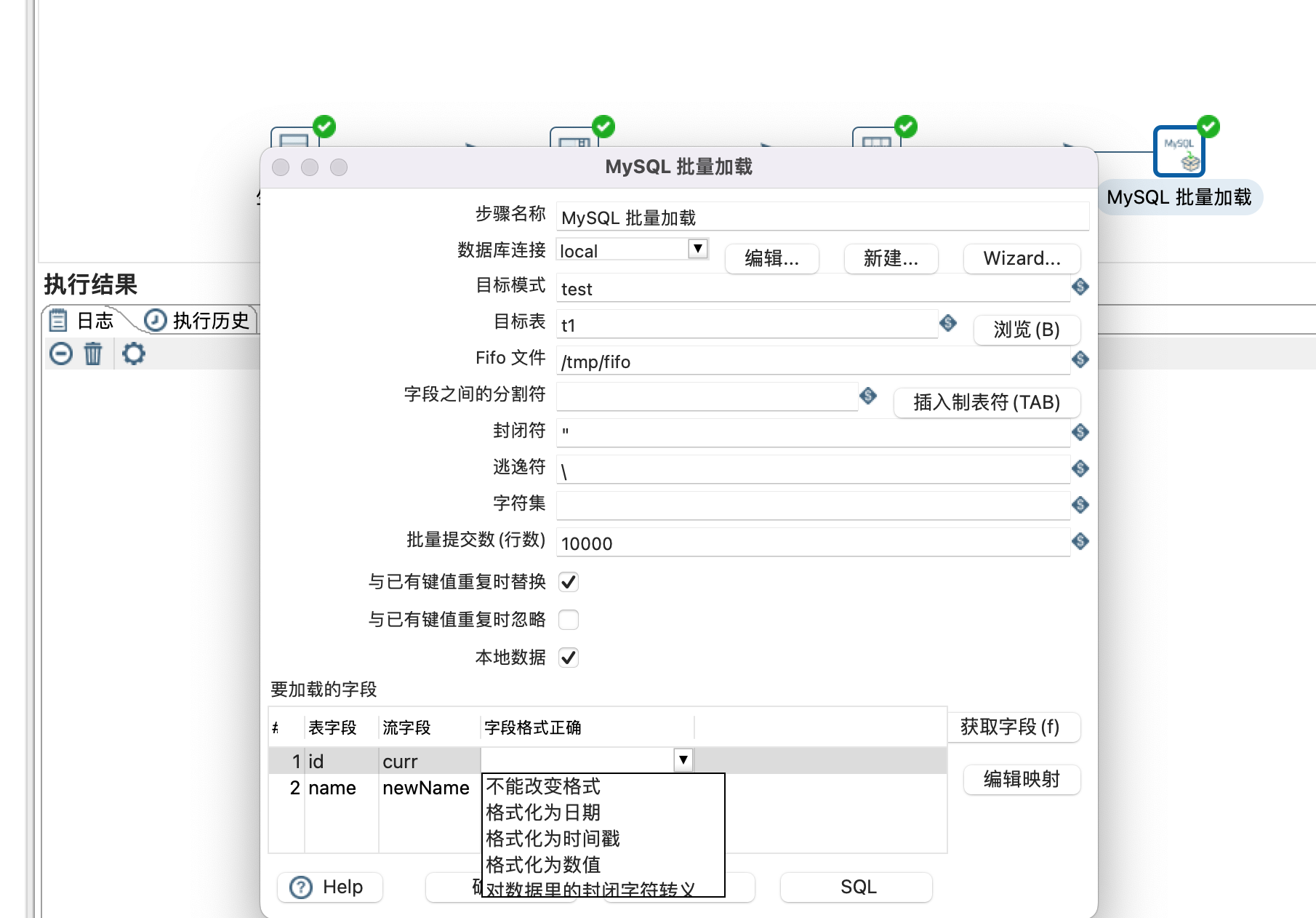
要加载的字段:设置数据库字段和流字段的映射关系,以及字段的格式化,如下图所示:
4、调试
1)保存&运行,果不其然出错了,如下图所示:
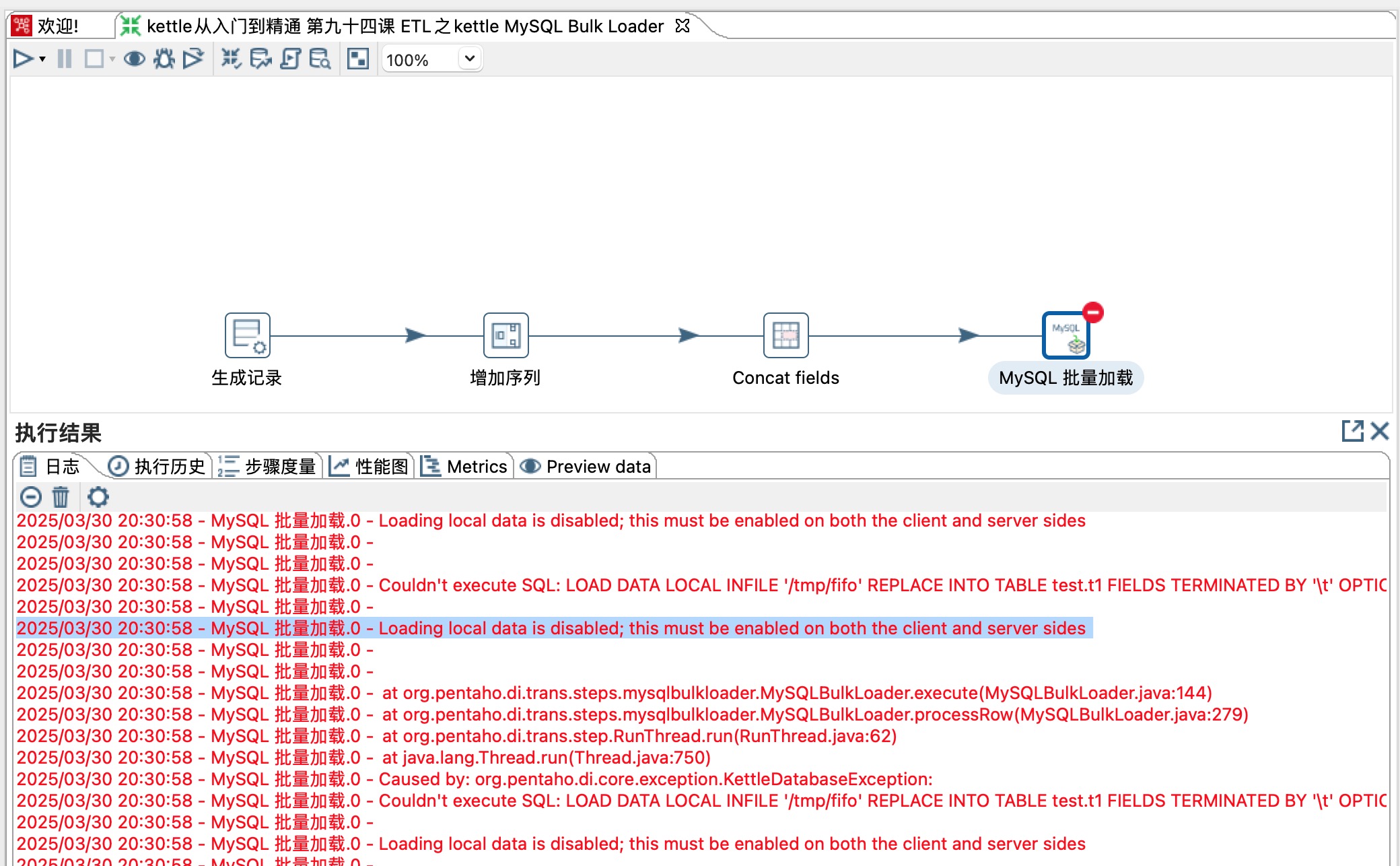
2)从报错的信息来看执行LOAD DATA INFILE 命令需要对数据库进行配置。 需要设置mysql服务器的local_infile变量。
通过SHOW VARIABLES LIKE 'local_infile';命令查看发现该参数处于关闭状态,
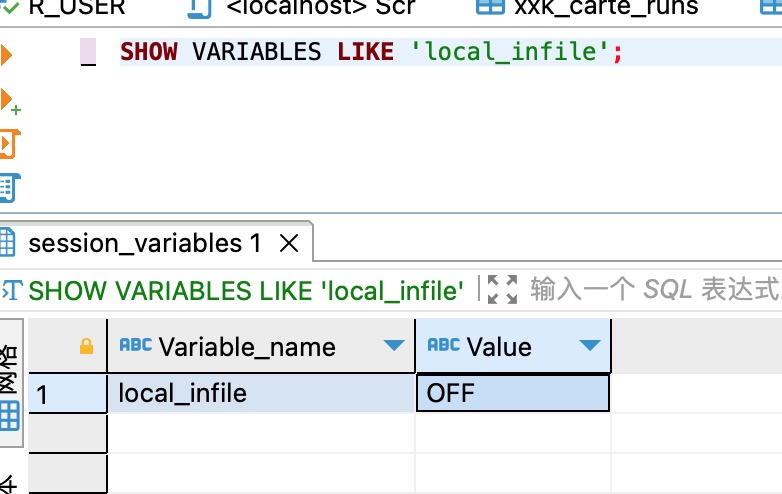
找到 MySQL 的配置文件(在 Linux 系统中通常是 /etc/my.cnf 或者 /etc/mysql/my.cnf,在 Windows 系统中可能是 my.ini),使用文本编辑器打开,添加或修改如下内容,然后重启mysql服务:
mysqld
local-infile = 1
在此查看该变量时已经处于开启状态。
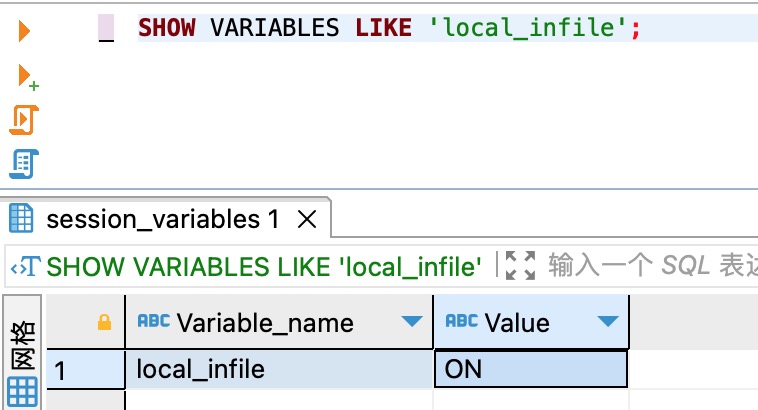
3)重新运行转换依然抱错,这时候仔细查看发现说的是客户端和服务器端都得开启 local_infile 功能。
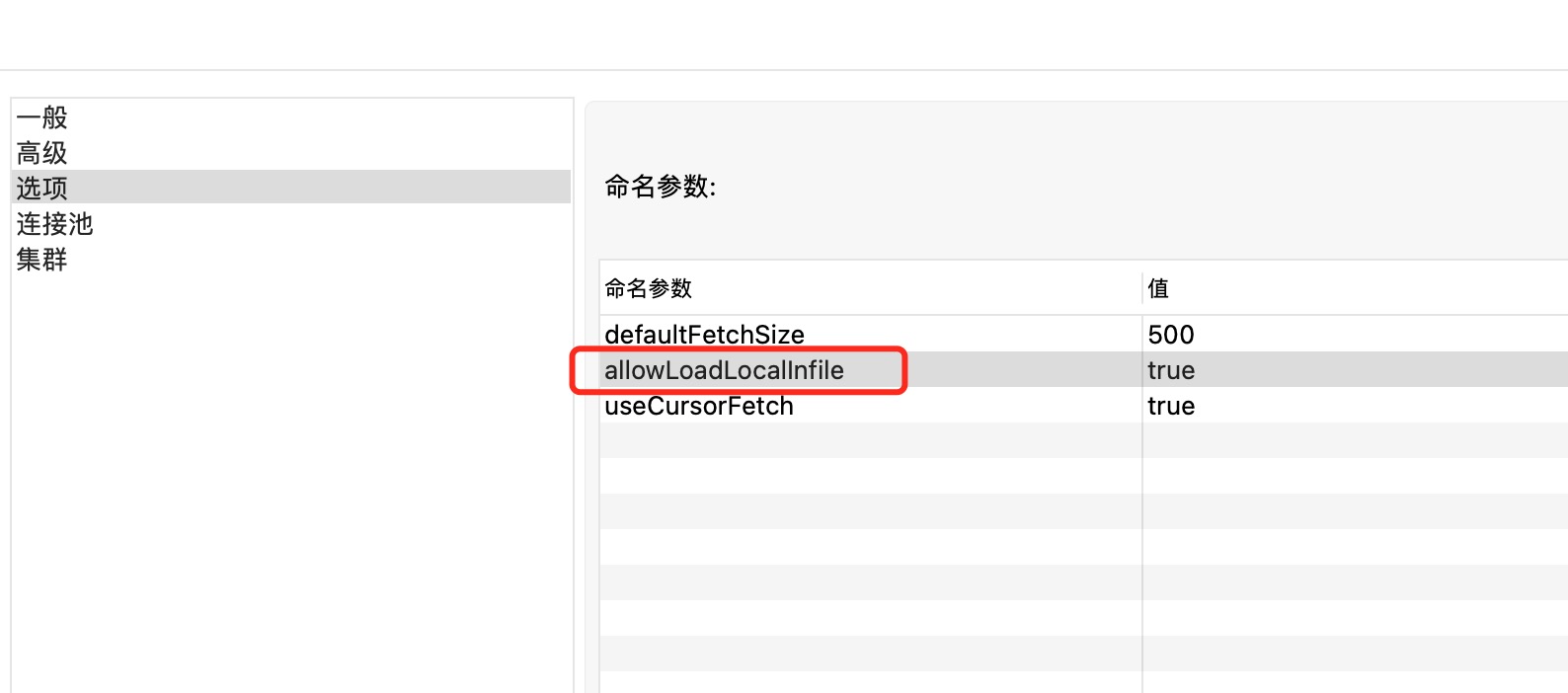
在kettle中编辑数据库连接,设置allowLoadLocalInfile=true即可解决此问题,如下图所示:
设置好allowLoadLocalInfile参数后重新运行,可以正常work,happy!!!