综合案例
- 将MNIST数据集保存成本地图片
- 读取本地图片进行训练
- 读取自己的数据集进行训练
- 用自己的模型进行训练
- 获得更多评价指标
- 提升模型性能的方法
MNIST转本地图片
import os
import torchvision
import torchvision.transforms as transforms
# 下载MNIST数据集
transform = transforms.Compose([transforms.ToTensor()])
mnist_trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
mnist_testset = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
# 创建一个目录来保存图像(如果它还不存在)
os.makedirs('./mnist_images/train', exist_ok=True)
os.makedirs('./mnist_images/test', exist_ok=True)
# 遍历数据集并保存图像
for idx, (image, label) in enumerate(mnist_trainset):
# 创建类别文件夹(如果它还不存在)
label_dir = os.path.join('./mnist_images/train', str(label))
os.makedirs(label_dir, exist_ok=True)
# 转换为PIL图像并保存
pil_image = transforms.ToPILImage()(image)
pil_image.save(os.path.join(label_dir, f'{idx}.jpg'))
# 遍历数据集并保存图像
for idx, (image, label) in enumerate(mnist_testset):
# 创建类别文件夹(如果它还不存在)
label_dir = os.path.join('./mnist_images/test', str(label))
os.makedirs(label_dir, exist_ok=True)
# 转换为PIL图像并保存
pil_image = transforms.ToPILImage()(image)
pil_image.save(os.path.join(label_dir, f'{idx}.jpg'))
# 打印完成消息
print("All images have been saved successfully.")接下来我来讲解一下上述的代码,在我的视角看来应该要将的东西
transform = transforms.Compose(transforms.ToTensor())
使用 torchvision.transforms 模块中的 Compose 和 ToTensor 方法来定义一个图像预处理的转换操作,主要用于将图像数据转换为 PyTorch 张量(Tensor),以便用于深度学习模型的训练或推理。
mnist_trainset=torchvision.datasets.MNIST(root='./data',train=True,download=True, transform=transform
自动下载MNIST数据集,然后将其转换为tensor格式
os.makedirs('./mnist_images/train', exist_ok=True)
使用 Python 的 os 模块中的 makedirs 函数来创建目录。具体来说,它的作用是创建一个目录路径 ./mnist_images/train,并且如果该目录已经存在,不会报错。
其中exist_ok=True,在目录已经存在的情况下,不会报错
label_dir = os.path.join('./mnist_images/train', str(label))
这一句代码的作用就是,把'./mnist_images/train'字符串和str(label)字符串拼接起来。
pil_image = transforms.ToPILImage()(image)
这行代码的作用是将输入的图像数据(通常是 PyTorch 张量或 NumPy 数组)转换为 PIL 图像对象。

读取本地图片进行训练
import os
import torch
from torch.utils.data import Dataset, DataLoader
import cv2 as cv
class MNISTDataset(Dataset):
def __init__(self, root_dir):
self.root_dir = root_dir
self.file_list = []
self.name_list = []
self.id_list = []
for root, dirs, files in os.walk(self.root_dir):
if dirs:
self.name_list = dirs
for file_i in files:
file_i_full_path = os.path.join(root, file_i)
file_class = os.path.split(file_i_full_path)[0].split('\\')[-1]
self.id_list.append(self.name_list.index(file_class))
self.file_list.append(file_i_full_path)
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
img = self.file_list[idx]
img = cv.imread(img, 0)
img = cv.resize(img, dsize=(28, 28))
img = torch.from_numpy(img).float()
label = self.id_list[idx]
# print(label)
label = torch.tensor(label)
return img, label
if __name__ == '__main__':
my_dataset_train = MNISTDataset(r'mnist_images/train')
my_dataloader_train = DataLoader(my_dataset_train, batch_size=10, shuffle=True)
# 尝试读取训练集数据
print("读取训练集数据")
for x, y in my_dataloader_train:
print(x.type(), x.shape, y)
my_dataset_test = MNISTDataset(r'mnist_images/test')
my_dataloader_test = DataLoader(my_dataset_test, batch_size=10, shuffle=False)
# 尝试读取训练集数据
print("读取测试集数据")
for x, y in my_dataloader_test:
print(x.shape, y)在前面讲了,Dataset的三件套,init,len,__getitem__如果这三个魔法方法忘记了,可以回去看看以前的文章。
for root, dirs, files in os.walk(self.root_dir):
Python 中使用 os.walk 函数的一个典型用法,用于遍历指定目录及其所有子目录中的文件和文件夹。
-
root:当前正在遍历的目录路径。 -
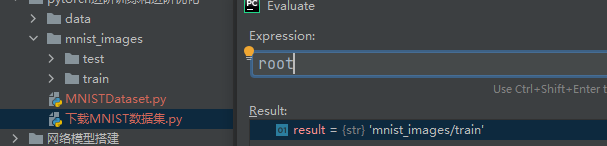
-
dirs:当前目录下的子目录列表。 -
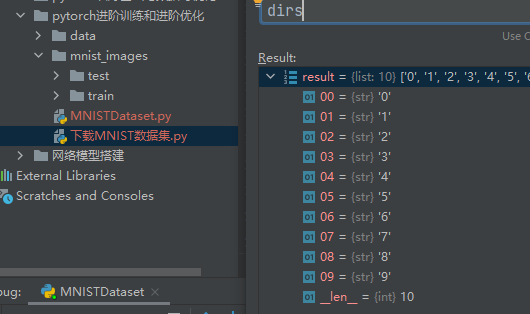
-
files:当前目录下的文件列表 -
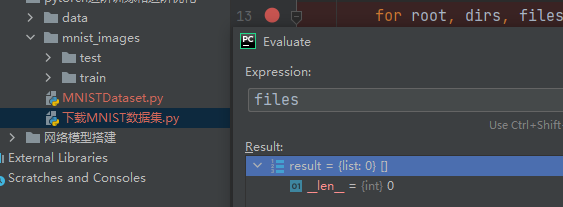
self.name_list
列表当中存的就是,标签名字
进入第二次循环后
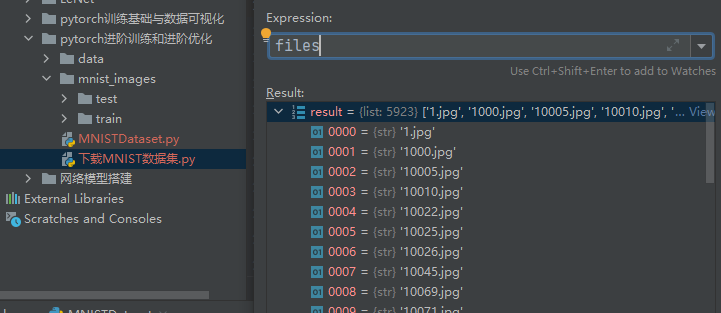
os.path.split(file_i_full_path)0
将 file_i_full_path 分割为目录部分和文件名部分,返回一个元组 (head, tail)

self.name_list.index(file_class)
在 self.name_list 列表中查找 file_class 元素的索引位置。