学习目标
- 目标
- 知道softmax回归的原理
- 应用softmax_cross_entropy_with_logits实现softamx以及交叉熵损失计算
- 应用matmul实现多隐层神经网络的计算
- 应用
- 应用TensorFlow完成Mnist手写数字势识别
到目前为止,我们所接触的都是二分类问题,神经网络输出层只有一个神经元,表示预测输出y^是正类的概率P(y=1∣x),y^>0.5则判断为正类,反之判断为负类。那么对于多分类问题怎么办?
目录
[1.Softmax 回归](#1.Softmax 回归)
1.Softmax 回归
对于多分类问题,用 N表示种类个数,那么神经网络的输出层的神经元个数必须为Loutput=N, 每个神经元的输出依次对应属于N个类别当中某个具体类别的概率,
P(y=N1∣x),..,P(y=Nn∣x)。
输出层即:
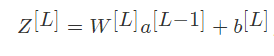
Z的输出值个数为类别个数
需要对所有的输出结果进行一下softmax公式计算:
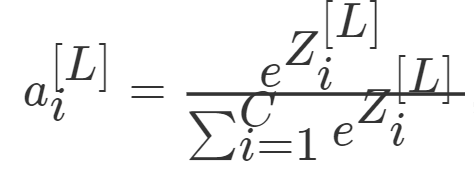
并且满足 。
。
我们来看一下计算案例:
2.交叉熵损失
对于softmax回归(逻辑回归代价函数的推广,都可称之为交叉熵损失),它的代价函数公式为:

总损失函数可以记为 :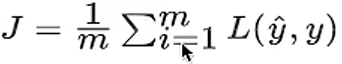
逻辑回归的损失也可以这样表示,:

所以与softmax是一样的,一个二分类一个多分类衡量。
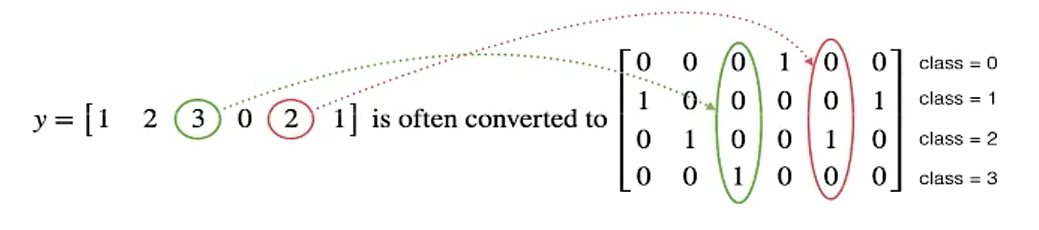
对于真实值会进行一个one-hot编码,每一个样本的所属类别都会在某个类别位置上标记。
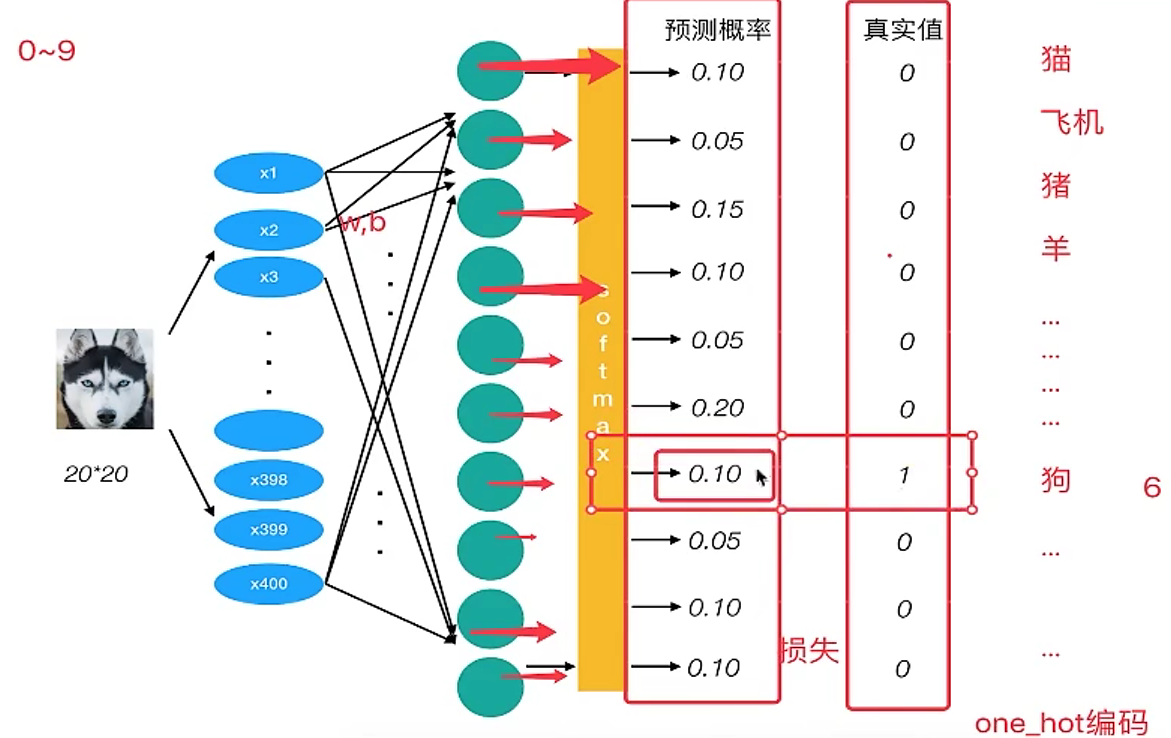
上图改样本的损失值为:

注:关于one_hot编码:
框架使用
-
便于编程:包括神经网络的开发和迭代、配置产品;
-
运行速度:特别是训练大型数据集时;
目前最火的深度学习框架大概是 Tensorflow 了。Tensorflow 框架内可以直接调用梯度下降算法,极大地降低了编程人员的工作量。例如以下代码:
3.案例:Mnist手写数字识别神经网络实现
3.1.数据集介绍

文件说明:
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
(已经失效)网址:Index of /exdb/mnist
3.2.特征值

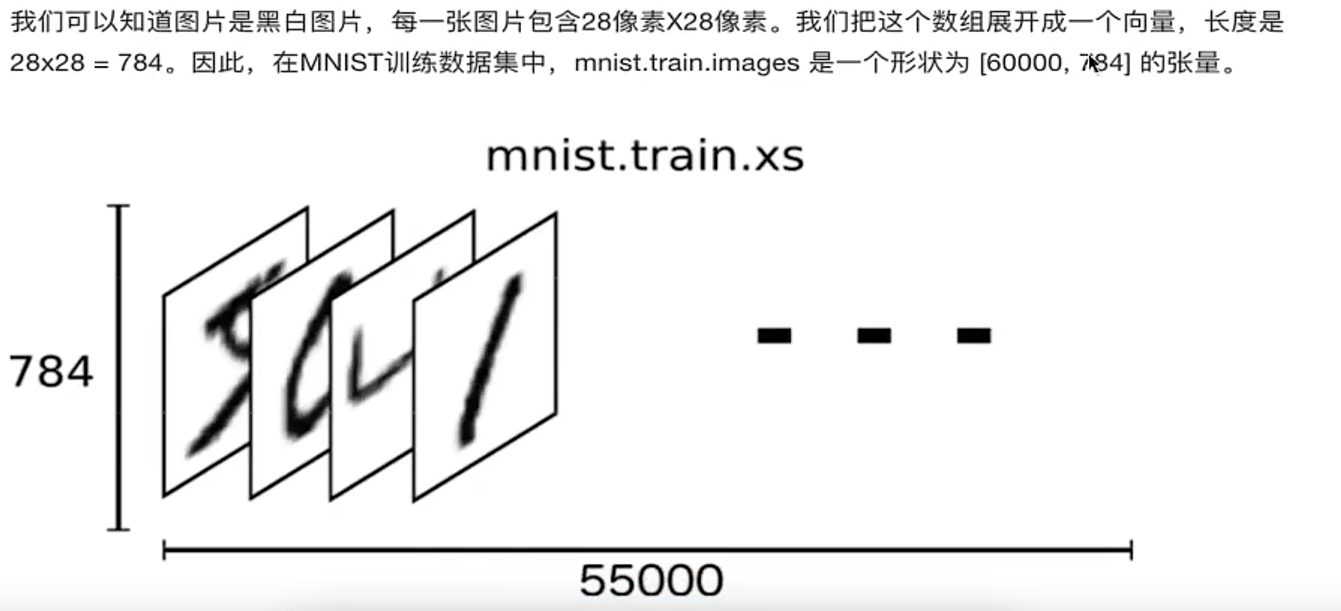
3.3.目标值

3.4.Mnist数据获取API
TensorFlow框架自带了获取这个数据集的接口,所以不需要自行读取。
python
mnist = tf.keras.datasets.mnist.load_data(path='mnist.npz')3.5.网络设计
我们采取两个层,除了输入层之外。第一个隐层中64个神经元,最后一个输出层(全连接层)我们必须设置10个神经元的神经网络。
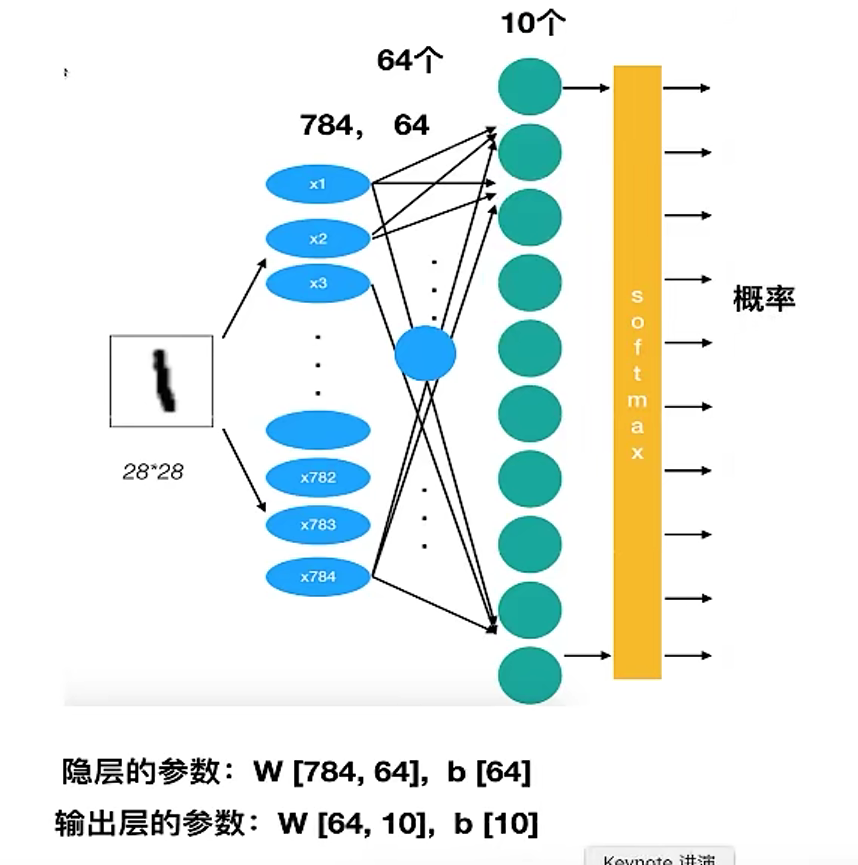
3.6.前期确定事情与流程
None:输入数据的个数
- 确定网络结构以及形状
- 第一层参数:输入:x None, 784 权重:784, 64 偏置64,输出None, 64
- 第二层参数:输入:None, 64 权重:64, 10 偏置10,输出None, 10
- 流程:
- 获取数据
- 前向传播:网络结构定义
- 损失计算
- 反向传播:梯度下降优化
- 功能完善
- 准确率计算
- 添加Tensorboard观察变量、损失变化
- 训练模型保存、模型存在加载模型进行预测
3.7.实现代码
3.7.1.数据获取
python
import numpy as np
import tensorflow as tf
#tensorflow版本为2.18.0
#1.获取数据
# 下载 MNIST 数据集到"C:\Users\asus\.keras\datasets\mnist.npz"
mnist = tf.keras.datasets.mnist.load_data(path='mnist.npz')
# 检查下载是否成功
tf.compat.v1.disable_eager_execution() # 关闭 Eager Execution 以支持计算图模式
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist
x_train = x_train.reshape(-1, 784).astype(np.float32) / 255.0
x_test = x_test.reshape(-1, 784).astype(np.float32) / 255.0
# 将标签转为 one-hot 编码(重要补全)
y_train = tf.compat.v1.keras.utils.to_categorical(y_train, 10)
y_test = tf.compat.v1.keras.utils.to_categorical(y_test, 10)
# 打印数据形状
print("训练集输入数据形状:", x_train.shape)
print("训练集输出数据形状:", y_train.shape)
print("测试集输入数据形状:", x_test.shape)
print("测试集输出数据形状:", y_test.shape)
3.7.2.前向传播:定义神经网络结构
python
#2.前向传播:定义神经网络结构
# 输入层:784个神经元,每个神经元接收1个像素值,x:[None, 784] [None, 28, 28]
# 隐藏层:64个神经元,激活函数:ReLU
# 输出层:10个神经元,激活函数:Softmax
import tensorflow as tf
tf.compat.v1.disable_eager_execution() # 禁用即时执行模式
#创建一个名为 "mnist_data" 的变量作用域。在这个作用域内定义的所有变量都会自动带有这个前缀
# 定义输入层
with tf.compat.v1.variable_scope("data"):
# 定义输入层特征值占位符
X= tf.compat.v1.placeholder(tf.float32, [None, 784], name='X_data')
# 定义输入层目标值占位符
Y = tf.compat.v1.placeholder(tf.int32, [None, 10], name='label')
# 定义隐藏层
with tf.compat.v1.variable_scope("hidden"):
# 定义隐藏层权重和偏置参数 [None, 784] * [784, 64] + [64] = [None, 64]
#y=wx+b
weight_hidden = tf.Variable(tf.random.normal([784, 64], mean=0.0, stddev=1.0), name="weight_hidden")
bias_hidden = tf.Variable(tf.random.normal([64], mean=0.0, stddev=1.0), name="bias_hidden")
#前向传播计算
# 计算隐藏层输出值
A1= tf.matmul(X, weight_hidden) + bias_hidden
# 定义输出层
with tf.compat.v1.variable_scope("fc"):
# 定义输出层权重和偏置参数 [None, 64] * [64, 10] + [10] = [None, 10]
# 定义输出层权重参数
weight_fc = tf.Variable(tf.random.normal([64, 10], mean=0.0, stddev=1.0), name="weight_fc")
# 定义输出层偏置参数
bias_fc = tf.Variable(tf.random.normal([10], mean=0.0, stddev=1.0), name="bias_fc")
# 前向传播计算
# 计算输出层输出值,网络的值
y_predict = tf.matmul(A1, weight_fc) + bias_fc3.7.3.损失计算与优化器
python
#3.定义损失函数和优化器
with tf.compat.v1.variable_scope("compute_loss"):
# 定义损失函数
all_loss = tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=y_predict)
#计算平均损失
loss = tf.reduce_mean(all_loss)
# 定义优化器
#4.反向传播
with tf.compat.v1.variable_scope("compute_loss"):
#梯度下降优化器
#学习率为0.1
optimizer = tf.compat.v1.train.GradientDescentOptimizer(0.1).minimize(loss)
#5.计算准确率
with tf.compat.v1.variable_scope("accuracy"):
# 计算预测值和真实值之间的准确率
equal_list = tf.equal(tf.argmax(y_predict, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))3.7.3.训练模型
python
import os
print("当前工作目录:", os.getcwd())
#5.训练模型
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
#建立保存观察数据的目录
for i in range(1000):
# 实现随机批次选择(关键修改)
batch_mask = np.random.choice(x_train.shape[0], 100)
mnist_x = x_train[batch_mask]
mnist_y = y_train[batch_mask]
loss_val, acc,summary,_ = sess.run([loss, accuracy,merged, optimizer], feed_dict={X: mnist_x, Y: mnist_y})
print("第%d次训练,损失值为:%f,准确率为:%f" % (i, loss_val, acc))3.8.完善模型功能
- 1、增加准确率计算
- 2、增加变量tensorboard显示
- 3、增加模型保存加载
- 4、增加模型预测结果输出
3.8.1.计算准确率
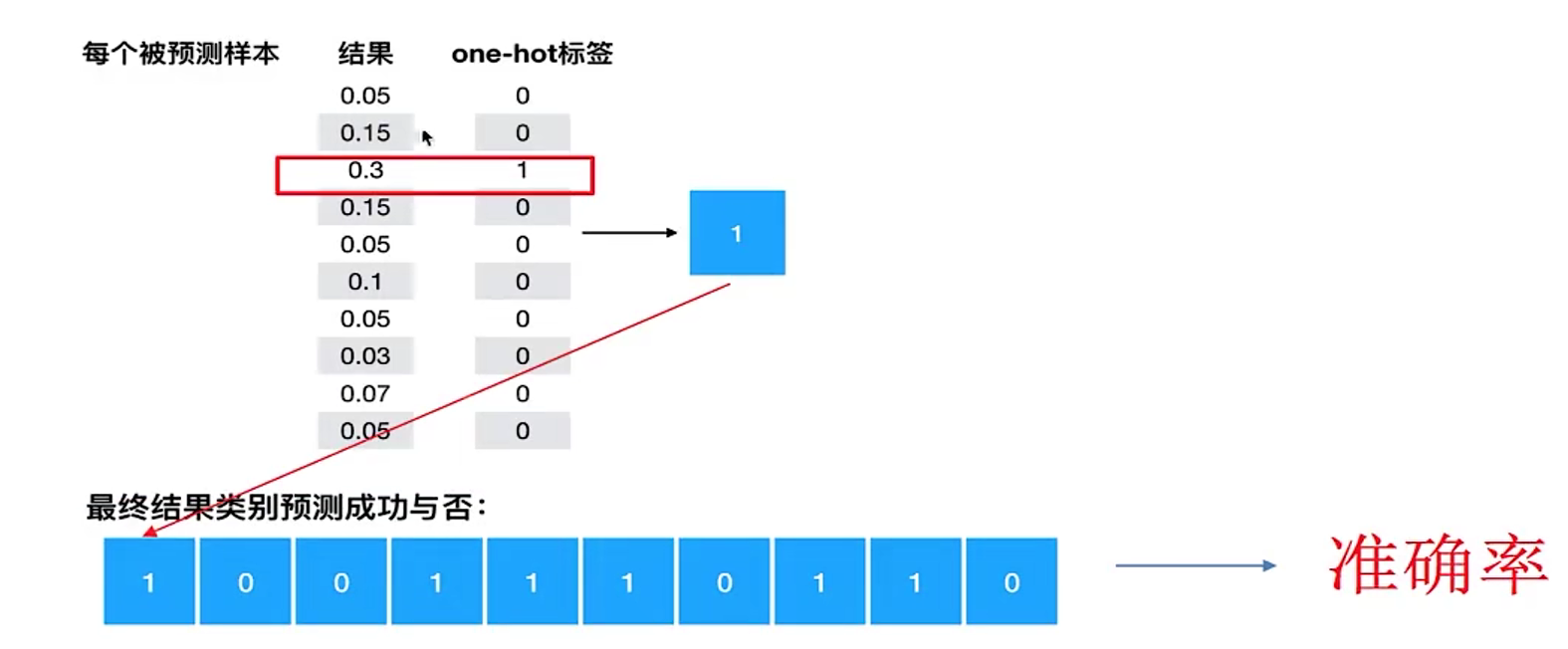
-
equal_list = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
-
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
-
模型评估(计算准确性)
python
#5.计算准确率
with tf.compat.v1.variable_scope("accuracy"):
# 计算预测值和真实值之间的准确率
equal_list = tf.equal(tf.argmax(y_predict, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))3.8.2.增加变量tensorboard显示
- 在会话外当中增加以下代码
python
#增加变量TensorBoard的显示
#(1).收集变量
tf.compat.v1.summary.scalar("losses", loss)
tf.compat.v1.summary.scalar("acc", accuracy)
#(2).合并变量
# 定义一个变量,用于保存TensorBoard所需的数据
tf.compat.v1.summary.histogram("weight_hidden", weight_hidden)
tf.compat.v1.summary.histogram("bias_hidden", bias_hidden)
tf.compat.v1.summary.histogram("weight_fc", weight_fc)
tf.compat.v1.summary.histogram("bias_fc", bias_fc)
#张量 board_summary 用于保存所有变量的观察数据
merged = tf.compat.v1.summary.merge_all()- 在会话当中去创建文件写入每次的变量值
python
# (1)创建一个events文件实例
# 获取 Notebook 文件路径
log_dir1 = r"C:\\tmp\\summary"
#这里的目录一定不能含有中文字符!!!!!!
file_writer = tf.compat.v1.summary.FileWriter(log_dir1, graph=sess.graph)
# 运行合变量op,写入事件文件当中
summary = sess.run(merged, feed_dict={x: mnist_x, y_true: mnist_y})
loss_val, acc,summary,_ = sess.run([loss, accuracy,merged, optimizer], feed_dict={X: mnist_x, Y: mnist_y})
#保存观察数据
file_writer.add_summary(summary, i)终端运行:
tensorboard --logdir="C:\\tmp\\summary"
可以看到模型的参数图:


3.8.3.增加模型保存加载
创建Saver,然后保存
python
#创建一个saver对象,用于保存模型
saver = tf.compat.v1.train.Saver()
log_dir2 = r"C:\\tmp\\model"
# 每隔100步保存一次模型
if i % 100 == 0:
saver.save(sess, os.path.join(log_dir2, "fc_nn_model"))在训练之前加载模型
python
#模型已经存在,则恢复模型参数
ckpt = tf.train.latest_checkpoint(log_dir2)
if ckpt:
saver.restore(sess, ckpt)
print("恢复模型参数成功!")3.8.4.增加模型预测结果输出
增加标志位
python
if "is_train" not in tf.compat.v1.app.flags.FLAGS:
tf.compat.v1.app.flags.DEFINE_integer("is_train", 1, "训练or预测")
FLAGS = tf.compat.v1.app.flags.FLAGS
# print(FLAGS.flag_values_dict()) # 输出所有合法参数然后判断是否训练,如果不是训练就直接预测,利用tf.argmax对样本的真实目标值y_true,和预测的目标值y_predict求出最大值的位置
python
for i in range(100):
random_idx = np.random.randint(0, len(x_test))
image = x_test[random_idx:random_idx+1] # 保持batch维度 (1, 784)
label = y_test[random_idx:random_idx+1] # (1, 10)
# image = image.reshape(-1, 784).astype(np.float32) / 255.0
# label = tf.compat.v1.keras.utils.to_categorical(label, 10)
#网络输出结果,对比计算结果
print("第%d次预测真实值:%d,预测结果为:%d" % (
i+1,
tf.argmax(sess.run(Y, feed_dict={X: image,Y: label}), 1).eval(),
tf.argmax(sess.run(y_predict, feed_dict={X: image, Y: label}), 1).eval()))
3.8.5.完整代码
python
import numpy as np
import tensorflow as tf
#tensorflow版本为2.18.0
#1.获取数据
# 下载 MNIST 数据集到"C:\Users\asus\.keras\datasets\mnist.npz"
mnist = tf.keras.datasets.mnist.load_data(path='mnist.npz')
# 检查下载是否成功
tf.compat.v1.disable_eager_execution() # 关闭 Eager Execution 以支持计算图模式
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist
x_train = x_train.reshape(-1, 784).astype(np.float32) / 255.0
x_test = x_test.reshape(-1, 784).astype(np.float32) / 255.0
# 将标签转为 one-hot 编码(重要补全)
y_train = tf.compat.v1.keras.utils.to_categorical(y_train, 10)
y_test = tf.compat.v1.keras.utils.to_categorical(y_test, 10)
# 打印数据形状
print("训练集输入数据形状:", x_train.shape)
print("训练集输出数据形状:", y_train.shape)
print("测试集输入数据形状:", x_test.shape)
print("测试集输出数据形状:", y_test.shape)
#2.前向传播:定义神经网络结构
# 输入层:784个神经元,每个神经元接收1个像素值,x:[None, 784] [None, 28, 28]
# 隐藏层:64个神经元,激活函数:ReLU
# 输出层:10个神经元,激活函数:Softmax
import tensorflow as tf
tf.compat.v1.disable_eager_execution() # 禁用即时执行模式
#创建一个名为 "mnist_data" 的变量作用域。在这个作用域内定义的所有变量都会自动带有这个前缀
# 定义输入层
with tf.compat.v1.variable_scope("data"):
# 定义输入层特征值占位符
X= tf.compat.v1.placeholder(tf.float32, [None, 784], name='X_data')
# 定义输入层目标值占位符
Y = tf.compat.v1.placeholder(tf.int32, [None, 10], name='label')
# 定义隐藏层
with tf.compat.v1.variable_scope("hidden"):
# 定义隐藏层权重和偏置参数 [None, 784] * [784, 64] + [64] = [None, 64]
#y=wx+b
weight_hidden = tf.Variable(tf.random.normal([784, 64], mean=0.0, stddev=1.0), name="weight_hidden")
bias_hidden = tf.Variable(tf.random.normal([64], mean=0.0, stddev=1.0), name="bias_hidden")
#前向传播计算
# 计算隐藏层输出值
A1= tf.matmul(X, weight_hidden) + bias_hidden
# 定义输出层
with tf.compat.v1.variable_scope("fc"):
# 定义输出层权重和偏置参数 [None, 64] * [64, 10] + [10] = [None, 10]
# 定义输出层权重参数
weight_fc = tf.Variable(tf.random.normal([64, 10], mean=0.0, stddev=1.0), name="weight_fc")
# 定义输出层偏置参数
bias_fc = tf.Variable(tf.random.normal([10], mean=0.0, stddev=1.0), name="bias_fc")
# 前向传播计算
# 计算输出层输出值,网络的值
y_predict = tf.matmul(A1, weight_fc) + bias_fc
#3.定义损失函数和优化器
with tf.compat.v1.variable_scope("compute_loss"):
# 定义损失函数
all_loss = tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=y_predict)
#计算平均损失
loss = tf.reduce_mean(all_loss)
# 定义优化器
#4.反向传播
with tf.compat.v1.variable_scope("compute_loss"):
#梯度下降优化器
#学习率为0.1
optimizer = tf.compat.v1.train.GradientDescentOptimizer(0.1).minimize(loss)
#5.计算准确率
with tf.compat.v1.variable_scope("accuracy"):
# 计算预测值和真实值之间的准确率
equal_list = tf.equal(tf.argmax(y_predict, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
#增加变量TensorBoard的显示
#(1).收集变量
tf.compat.v1.summary.scalar("losses", loss)
tf.compat.v1.summary.scalar("acc", accuracy)
#(2).合并变量
# 定义一个变量,用于保存TensorBoard所需的数据
tf.compat.v1.summary.histogram("weight_hidden", weight_hidden)
tf.compat.v1.summary.histogram("bias_hidden", bias_hidden)
tf.compat.v1.summary.histogram("weight_fc", weight_fc)
tf.compat.v1.summary.histogram("bias_fc", bias_fc)
#张量 board_summary 用于保存所有变量的观察数据
merged = tf.compat.v1.summary.merge_all()
#创建一个saver对象,用于保存模型
saver = tf.compat.v1.train.Saver()
import os
print("当前工作目录:", os.getcwd())
#5.训练模型
# 定义会话
import os
from IPython import get_ipython
# 获取 Notebook 文件路径
log_dir1 = r"C:\\tmp\\summary"
#这里的目录一定不能含有中文字符!!!!!!
log_dir2 = r"C:\\tmp\\model"
if "is_train" not in tf.compat.v1.app.flags.FLAGS:
tf.compat.v1.app.flags.DEFINE_integer("is_train", 1, "训练or预测")
FLAGS = tf.compat.v1.app.flags.FLAGS
# print(FLAGS.flag_values_dict()) # 输出所有合法参数
tf.compat.v1.app.flags.FLAGS.is_train = 0
if not os.path.exists(log_dir1):
os.makedirs(log_dir1)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
#建立保存观察数据的目录
#模型已经存在,则恢复模型参数
ckpt = tf.train.latest_checkpoint(log_dir2)
if ckpt:
saver.restore(sess, ckpt)
print("恢复模型参数成功!")
import sys
sys.argv = [sys.argv[0]] # 只保留脚本名,移除其他参数
if FLAGS.is_train==1:
# 训练模型
for i in range(1000):
# 实现随机批次选择(关键修改)
file_writer = tf.compat.v1.summary.FileWriter(log_dir1, graph=sess.graph)
batch_mask = np.random.choice(x_train.shape[0], 100)
mnist_x = x_train[batch_mask]
mnist_y = y_train[batch_mask]
loss_val, acc,summary,_ = sess.run([loss, accuracy,merged, optimizer], feed_dict={X: mnist_x, Y: mnist_y})
print("第%d次训练,损失值为:%f,准确率为:%f" % (i, loss_val, acc))
#保存观察数据
file_writer.add_summary(summary, i)
#每一百步保存一次模型参数
if i % 100 == 0:
saver.save(sess, os.path.join(log_dir2, "fc_nn_model"))
else:
for i in range(100):
random_idx = np.random.randint(0, len(x_test))
image = x_test[random_idx:random_idx+1] # 保持batch维度 (1, 784)
label = y_test[random_idx:random_idx+1] # (1, 10)
# image = image.reshape(-1, 784).astype(np.float32) / 255.0
# label = tf.compat.v1.keras.utils.to_categorical(label, 10)
#网络输出结果,对比计算结果
print("第%d次预测真实值:%d,预测结果为:%d" % (
i+1,
tf.argmax(sess.run(Y, feed_dict={X: image,Y: label}), 1).eval(),
tf.argmax(sess.run(y_predict, feed_dict={X: image, Y: label}), 1).eval()))4.调整学习率调整网络参数带来的问题
如果我们对网络当中的学习率进行修改,也就是一开始我们并不会知道学习率填哪些值,也并不知道调整网络的参数大小带来的影响(第一部分第四节)。
- 假设学习率调整到1,2
- 假设参数调整到比较大的值,几十、几百

总结:参数调整了之后可能没影响,是因为网络较小,可能并不会造成后面所介绍的梯度消失或者梯度爆炸
5.总结
- 掌握softmax公式以及特点
- tensorflow.examples.tutorials.mnist.input_data 获取Mnist数据
- tf.matmul(a, b,name=None)实现全连接层计算
- tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)实现梯度下降优化