锋哥原创的TensorFlow2 Python深度学习视频教程:
https://www.bilibili.com/video/BV1X5xVz6E4w/
课程介绍

本课程主要讲解基于TensorFlow2的Python深度学习知识,包括深度学习概述,TensorFlow2框架入门知识,以及卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN),模型保存与加载等。
TensorFlow2 Python深度学习 - 循环神经网络(SimpleRNN)示例
IMDB数据集数据集简介
1. 数据集概述
IMDB 数据集是一个二分类情感分析的经典基准数据集。它包含了来自互联网电影数据库(IMDB)的 50,000 条影评文本,其中 25,000 条用于训练,另外 25,000 条用于测试。
数据集的标签是二元的:
-
0 :代表负面评论
-
1 :代表正面评论
一个关键的特点是,训练集和测试集是平衡的,这意味着它们各自包含 25,000 条正面和 25,000 条负面评论。
2**. 数据预处理形式**
在 TensorFlow 2 中,IMDB 数据集已经过预处理。原始评论文本中的单词已经被转换为整数索引,这些索引对应于在一个词汇表中该单词的频率排名。
例如:
-
整数 1 通常代表数据集中最常出现的单词。
-
整数 2 代表第二常见的单词,以此类推。
-
整数 0 不代表任何特定单词,而是被用作 填充符。
-
整数 3 通常代表 "未知单词",即那些不在最常用词汇列表中的单词。
默认情况下,数据集被设置为仅保留词汇表中前 10,000 个最常用 的单词(通过参数 num_words 控制)。这既有助于控制模型的复杂度,也减少了计算和内存的开销。
循环神经网络(SimpleRNN)示例
import tensorflow as tf
from keras import Input, layers
from keras.src.utils import pad_sequences
# 1. 加载 IMDB 数据集
max_features = 10000 # 使用词汇表中前 10000 个常见单词
maxlen = 100 # 每条评论的最大长度
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.imdb.load_data(num_words=max_features)
print(x_train.shape, x_test.shape)
print(x_train[0])
print(y_train)
# 2. 数据预处理:对每条评论进行填充,使其长度统一
x_train = pad_sequences(x_train, maxlen=maxlen)
x_test = pad_sequences(x_test, maxlen=maxlen)
# 3. 构建 RNN 模型
model = tf.keras.models.Sequential([
Input(shape=(maxlen,)),
layers.Embedding(input_dim=max_features, output_dim=128), # 嵌入层,将单词索引映射为向量 output_dim 嵌入向量的维度(即每个输入词的嵌入表示的长度)
layers.SimpleRNN(128), # SimpleRNN 层:包含 128 个神经元,激活函数默认使用 tanh
layers.Dense(1, activation='sigmoid') # 输出层:用于二分类(正面或负面),激活函数为 sigmoid
])
# 4. 模型编译
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 5. 模型训练
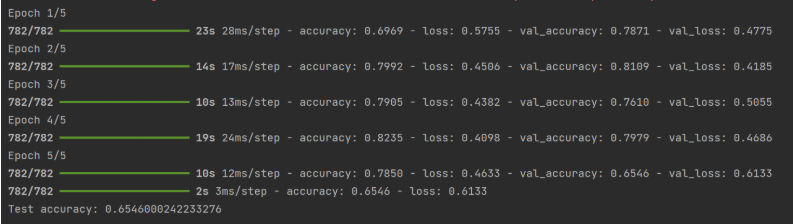
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test), verbose=1)
# 6. 模型评估
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test accuracy: {test_acc}")运行结果: