在当今的互联网应用开发中,MySQL 作为可靠的关系型数据库,与 Redis 这一高性能的缓存系统常常协同工作。然而,如何确保它们之间的数据一致性,成为了开发者们面临的重要挑战。本文将深入探讨 MySQL 与 Redis 缓存一致性的相关问题,从不同的方案分析到实际项目的代码实现,为你呈现全面的技术解析。
一、理论知识:探寻一致性方案的基石
(一)不佳的方案
- 先写 MySQL,再写 Redis
在高并发场景下,当多个请求同时进行数据更新时,若请求 A 先写 MySQL,接着在写 Redis 过程中出现延迟,而请求 B 快速完成了 MySQL 和 Redis 的数据更新操作,就会导致数据不一致。
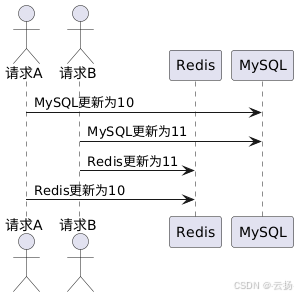
这是一幅描述在高并发场景下,"先写 MySQL,再写 Redis" 方案可能出现数据不一致问题的时序图 ,具体过程如下:- 初始状态:假设数据在 MySQL 和 Redis 中的初始值未明确提及,但后续操作是将其从某个值更新为 10 再到 11 。
- 请求 A 操作:请求 A 先对 MySQL 进行写操作,将 MySQL 中的数据更新为 10 。之后请求 A 在向 Redis 写数据时出现卡顿(延迟) 。
- 请求 B 操作:请求 B 在请求 A 写 MySQL 之后开始操作。请求 B 先将 MySQL 中的数据更新为 11 ,接着顺利将 Redis 中的数据也更新为 11 。
- 请求 A 后续操作:请求 A 卡顿结束后,继续执行向 Redis 写数据的操作,将 Redis 中的数据更新为 10 。这就导致 Redis 中的数据与 MySQL 中的数据(此时 MySQL 中为 11 )不一致 。
这种情况产生的原因在于高并发环境下,请求执行顺序和延迟导致写 Redis 操作的先后出现差异,使得最终 MySQL 和 Redis 中的数据状态不一致。如果此时有读请求,按照先读 Redis 若没有再读 DB 且读请求不回写 Redis 的规则,就可能读到不一致的数据 。
-
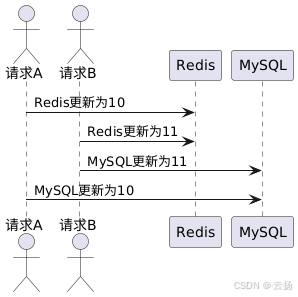
先写 Redis,再写 MySQL
此方案与先写 MySQL 再写 Redis 类似,在高并发情况下,由于操作顺序的原因,极易出现数据不一致的问题。例如,当 Redis 写入成功但 MySQL 写入失败时,后续的读操作可能会读取到 Redis 中已更新但 MySQL 中未更新的数据,从而产生不一致。
-
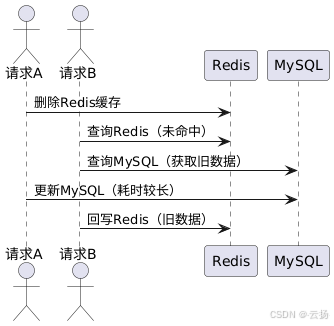
先删除 Redis,再写 MySQL
当存在更新请求 A 和读请求 B 时,请求 A 先删除 Redis 缓存,若此时更新 MySQL 的操作耗时较长,而请求 B 的读请求快速执行,并且读请求会回写 Redis,那么在请求 A 的 MySQL 更新尚未完成时,请求 B 可能会将旧数据回写到 Redis 中,导致数据不一致。
(二)可靠的方案
-
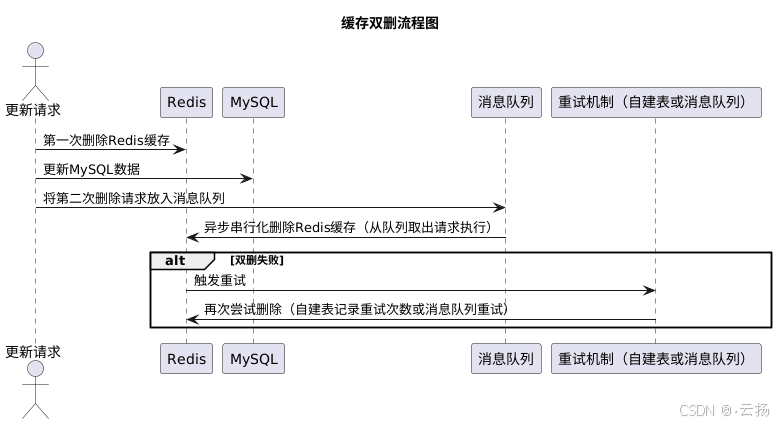
先删除 Redis,再写 MySQL,再删除 Redis(缓存双删)
为解决先删除 Redis 再写 MySQL 带来的不一致问题,缓存双删方案应运而生。即先删除 Redis 缓存,然后更新 MySQL 数据,最后再次删除 Redis 缓存。为确保最后一次删除操作在回写缓存之后执行,不建议采用简单的等待固定时间(如 500ms)的方式,推荐使用异步串行化删除,将删除请求放入队列中,这样既能保证异步操作不影响线上业务,又能通过串行化处理在并发情况下正确删除缓存。若双删失败,可借助消息队列的重试机制,或者自建表记录重试次数来实现重试。
-
先写 MySQL,再删除 Redis
对于一些对一致性要求不是极高的业务场景,此方案下存在的短暂不一致是可以接受的。比如在秒杀、库存服务等对一致性要求严格的业务中,这种方案可能不太适用。出现不一致的情况需要满足缓存刚好自动失效,且请求 B 从数据库查出旧数据回写缓存的耗时比请求 A 写数据库并删除缓存的时间更长,这种情况发生的概率相对较小。
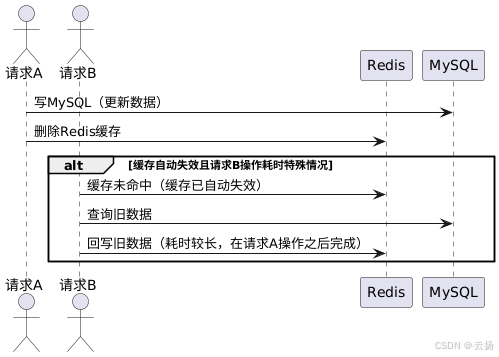
-
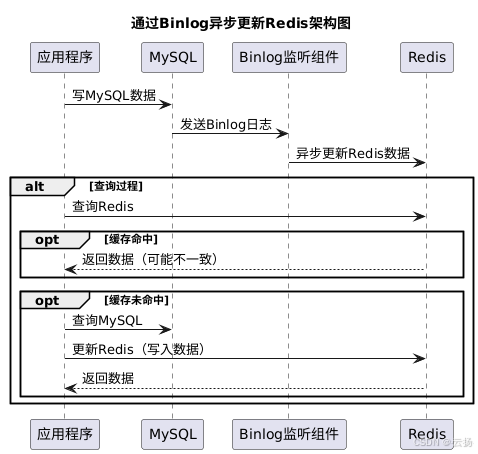
先写 MySQL,通过 Binlog,异步更新 Redis
该方案通过监听 MySQL 的 Binlog 日志,以异步的方式将数据更新到 Redis 中。它能保证 MySQL 和 Redis 的最终一致性,但无法保证实时性。在查询过程中,若缓存中无数据,则直接查询 DB;若缓存中有数据,也可能存在数据不一致的情况。
二、方案比较:抉择最优解
- 先写 Redis,再写 MySQL:若数据库出现故障,而数据仅存在于缓存中,会导致严重的数据不一致问题,且写数据库失败后对 Redis 的逆操作若失败,处理起来较为复杂,因此不建议使用。
- 先写 MySQL,再写 Redis:适用于并发量和一致性要求不高的项目。当 Redis 不可用时,需要及时报警并进行线下处理。
- 先删除 Redis,再写 MySQL:实际应用中使用较少,不推荐采用该方案。
- 先删除 Redis,再写 MySQL,再删除 Redis:虽然方案可行,但实现较为复杂,需要借助消息队列来实现异步删除 Redis 的操作。
- 先写 MySQL,再删除 Redis:此方案较为推荐,删除 Redis 失败时可进行多次重试,若重试无效则报警。在实时性方面表现较好,适用于高并发场景。
- 先写 MySQL,通过 Binlog,异步更新 Redis:适用于异地容灾、数据汇总等场景,结合 binlog 和 kafka 可使数据一致性达到秒级,但不适合纯粹的高并发场景,如抢购、秒杀等。
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 先写Redis,再写MySQL | 无明显优点 | 数据库挂掉时,数据存在缓存但未写入数据库,会造成数据不一致;写数据库失败后对Redis的逆操作若失败,处理复杂 | 不推荐用于任何场景 |
| 先写MySQL,再写Redis | 实现简单 | 高并发时易出现数据不一致;Redis不可用时需线下处理 | 并发量和一致性要求不高的项目 |
| 先删除Redis,再写MySQL | 无明显优点 | 出现数据不一致的概率较大,实际应用中较少使用 | 不推荐用于任何场景 |
| 先删除Redis,再写MySQL,再删除Redis | 能解决部分数据不一致问题 | 实现复杂,需借助消息队列异步删除Redis | 对一致性要求极高,且能接受复杂实现的场景 |
| 先写MySQL,再删除Redis | 实时性较好,删除Redis失败可重试,适用于高并发场景 | 存在短暂不一致的情况,对强一致性要求的业务不适用 | 对一致性要求不是特别强的高并发场景,如一般的电商商品展示等 |
| 先写MySQL,通过Binlog,异步更新Redis | 能保证最终一致性,适用于异地容灾、数据汇总等场景 | 无法保证实时性,不适合高并发场景 | 异地容灾、数据汇总等对实时性要求不高的场景 |
三、项目实战:代码实现的精彩呈现
假设我们有一个简单的博客文章管理系统,需要保证文章标签数据在 MySQL 和 Redis 中的一致性。采取先写 MySQL,再删除 Redis方案,以下是相关的代码实现示例:
(一)数据更新
- 写操作 :
○ 优先操作MySQL :通过事务保证数据库更新原子性。
○ 同步删除Redis缓存:若删除失败触发事务回滚(需结合业务验证),防止脏数据。
java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import redis.clients.jedis.Jedis;
public class DataUpdate {
private static final String DB_URL = "jdbc:mysql://localhost:3306/blog";
private static final String DB_USER = "root";
private static final String DB_PASSWORD = "password";
public static void updateArticleTags(String articleId, String newTags) {
Connection conn = null;
PreparedStatement pstmt = null;
Jedis jedis = new Jedis("localhost", 6379);
try {
// 连接数据库
conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);
// 开启事务
conn.setAutoCommit(false);
// 更新 MySQL 数据
String sql = "UPDATE articles SET tags =? WHERE id =?";
pstmt = conn.prepareStatement(sql);
pstmt.setString(1, newTags);
pstmt.setString(2, articleId);
pstmt.executeUpdate();
// 删除 Redis 缓存
jedis.del("article:" + articleId + ":tags");
// 提交事务
conn.commit();
} catch (SQLException e) {
try {
// 回滚事务
if (conn != null) {
conn.rollback();
}
} catch (SQLException ex) {
ex.printStackTrace();
}
e.printStackTrace();
} finally {
// 关闭资源
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
jedis.close();
}
}
}(二)数据获取
- 读操作 :
○ 先查缓存 :命中则直接返回数据。
○ 未命中查DB:查询结果回写Redis并设置过期时间,避免缓存穿透。
java
import redis.clients.jedis.Jedis;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class DataRetrieval {
private static final String DB_URL = "jdbc:mysql://localhost:3306/blog";
private static final String DB_USER = "root";
private static final String DB_PASSWORD = "password";
public static String getArticleTags(String articleId) {
Jedis jedis = new Jedis("localhost", 6379);
String tags = jedis.get("article:" + articleId + ":tags");
if (tags == null) {
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
// 连接数据库
conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);
String sql = "SELECT tags FROM articles WHERE id =?";
pstmt = conn.prepareStatement(sql);
pstmt.setString(1, articleId);
rs = pstmt.executeQuery();
if (rs.next()) {
tags = rs.getString("tags");
// 将数据写入 Redis 缓存,并设置过期时间(例如 60 秒)
jedis.setex("article:" + articleId + ":tags", 60, tags);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 关闭资源
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
return tags;
}
}四、总结
通过对 MySQL 与 Redis 缓存一致性的多种方案的分析和实际项目的代码实现,我们了解到不同方案的优缺点和适用场景。在实际开发中,应根据项目的具体需求,如并发量、一致性要求、业务场景等,选择合适的方案来保证数据的一致性。希望本文能为你在处理 MySQL 与 Redis 缓存一致性问题时提供有益的参考和帮助。