
论文地址
https://arxiv.org/pdf/2412.04623![]() https://arxiv.org/pdf/2412.04623
https://arxiv.org/pdf/2412.04623
论文粗读
论文提出了一种两阶段的视频无模态分割和内容补全方法。第一阶段通过利用视频基础模型学习的形状和时间一致性先验,为被遮挡的物体生成无模态掩码。第二阶段则对物体的被遮挡区域进行修复,完成其RGB内容。该方法能够处理严重遮挡,并在不同物体类别上泛化良好,在合成和真实世界数据集上均取得了最先进的结果。
针对像素生成训练的扩散模型也学习了强大的物体形状先验,可以利用这些先验在视频帧之间传播物体形状和内容,从而实现无模态分割。
人类可以感知到物体即使经过完全遮挡,所以在图像语义分割模型,遮挡部分的语义识别和分一直被忽视,因为社区主要关注分割对象的可见或模态区域,最近的重点已转向包括非模态分割或者说无模态分割(Amodal Segmentation)
无模态分割的核心在于推断对象的完整形状,即使部分区域被遮挡。
例如,在一张图片中,如果一辆车被树挡住了一半,无模态分割会尝试勾勒出整辆车的轮廓,而不仅仅是可见的部分。研究表明,这一过程需要复杂的推理能力,包括场景的深度顺序和对象重叠关系。2015年的一篇论文Semantic Amodal Segmentation, arXiv:1509.01329明确指出,无模态分割的目标是标记每个区域的完整范围,而不仅仅是可见像素,这一定义得到了后续研究的广泛认可。
Amodal Segmentation 涉及分割对象的完整形状,包括可见和遮挡的部分。这项工作为什么难,论文里提到

" 在单目设置中,非模态感知是一个ill-posed问题,因为在遮挡区域中有多种可能的解释,对于对象边界应该如何延伸。最近的非模态分割和填补创新方法使用扩散框架来学习这种多模态分布,但它们无法处理对象可能完全被遮挡的情况。
这个问题因为缺乏包含对象非模态掩码和RGB内容的真实世界数据集而加剧。现状。 尽管如此,当前的基于图像的非模态分割算法已经展示了令人印象深刻的性能。然而,这些方法都是在单帧设置中,在对象被严重或完全遮挡的情况下表现不佳。一个潜在的解决方案是在多帧设置中进行非模态分割24,以利用时间上下文来推断完全遮挡。然而,现有的视频非模态分割算法9, 57通常仅限于刚性物体,并依赖于额外的输入(如相机姿态或光流),这限制了它们的可扩展性和因此,对未见过的数据的泛化。"

"为了解决这些挑战,我们提议重新利用视频扩散模型,Stable Video Diffusion(SVD)3,以实现高度准确和可泛化的视频非模态分割。一个关键洞察是,训练用于生成像素的基础扩散模型也内置了对对象形状的强先验。这些先验已经被条件图像生成40, 45, 61方法所利用,这些方法基于语义图和对象边界进行条件化。我们同样利用这些先验来完成我们的任务。但关键的是,我们的多帧视频设置允许我们在时间上传播对象的形状和内容;例如,通过查看其他帧可以推断完全被遮挡的对象的形状(图1)。我们提出的模型在四个合成和真实世界视频数据集上达到了与各种单帧和多帧非模态分割基线相比的最先进的性能。我们仅在合成数据上进行训练,但展示了对真实数据的强零样本泛化。"
论文提到的相关工作
"想象一下模态分割。大多数先前的模态分割研究都集中在基于图像的方法上。一些方法采用了与模态分割类似的策略,将模型训练为以RGB图像为输入,直接输出场景中所有物体的模态掩码。另一类方法利用现有的模态掩码,由模态分割模型生成,基于这些和其他输入如图像帧来预测模态掩码。除了推断完整的物体形状,一些方法还会在被遮挡的区域中幻想RGB内容。通用的内容补全方法在这项任务中经常失败,因为它们依赖于周围的上下文,这通常包括遮挡物。相比之下,内容完成方法显式地基于模态内容进行条件化,要么直接基于模态信息生成模态内容,要么在预测的模态分割区域内进行内填充。由于高质量的真实世界模态图像数据集的可用性,图像模态分割和内容补全方法通过学习强大的形状先验表现出强大的性能。然而,这些方法在重大遮挡的情况下经常遇到困难,并且对于完全被遮挡的物体完全失败,因为在单帧设置中无法推断模态线索。视频模态分割。最近,视频模态分割方法出现了。这些方法整合了视频序列中前后帧的信息,实现了时间一致的预测。然而,大多数这些算法的训练和评估都局限于具有相似尺度的合成数据集中的刚性物体。尽管这些算法在合成数据集中优于基于图像的模态分割方法,但它们的实际应用仍然有限。相比之下,我们利用了合成和真实世界数据集,这些数据集包括具有多样化运动和尺度的可变形物体,通常与复杂的摄像机移动混合。此外,据我们所知,这项工作是首次探索视频级模态内容补全。扩散模型的真实世界先验。扩散模型在计算机视觉中的生成任务中取得了重大成功。"
工作原理
无模态分割通常涉及两个关键步骤:首先,基于可见部分和上下文信息(如深度图或形状先验)推断对象的完整范围;其次,通过生成模型或推理算法填充被遮挡区域。例如,2023年的一篇AAAI论文Amodal Segmentation Based on Visible Region Segmentation and Shape Prior, AAAI-21提出了一种框架,首先估计粗略的可见掩码和无模态掩码,然后利用形状先验和可见区域的特征来细化结果。这种方法模仿了人类的认知过程,通过可见部分和先验知识推断隐藏部分。
第一阶段:非模态分割 第二阶段:内容补全
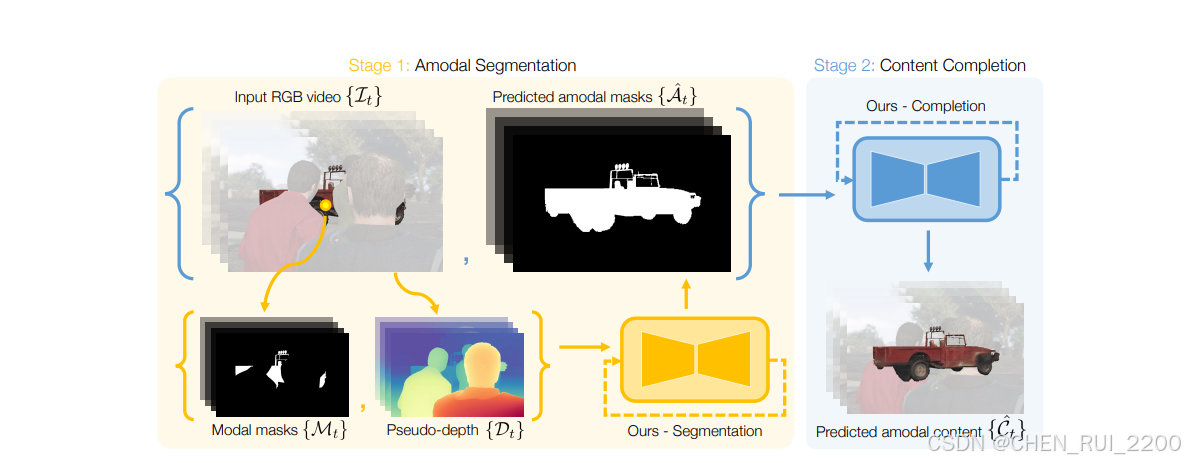
上图中,无模式分割和内容补全的模型管道。管道的第一阶段根据物体的模式掩膜{Mt}和场景的伪深度{Dt}(通过运行单目深度估计器在RGB视频序列{It}上获得)生成物体的无模式掩膜{ˆAt}。第一阶段预测的无模式掩膜随后作为输入发送到第二阶段,并带有被考虑的被遮挡物体的模式RGB内容。第二阶段然后在被遮挡区域进行内填,并输出被遮挡物体的无模式RGB内容{ˆCt}。两个阶段都采用带有3D UNet骨干的条件潜空间扩散框架3。通过VAE编码器编码的条件被连接到潜空间,并由具有交错空间和时间块的3D UNet处理。{Mt}和模式RGB内容的CLIP嵌入分别为第一阶段和第二阶段提供交叉注意力线索。最后,VAE解码器将输出转换回像素空间
考虑一个视频序列{I1,I2, ...,IT},其中包含目标对象的模态(或可见)分割掩码{M1,M2, ...,MT}。这些掩码可以通过常规的模态分割器轻松获得,例如Segment Anythingv2 。我们首先描述一个(基于扩散的)模型,用于生成包含目标对象全部范围的非模态掩码{A1,A2, ...,AT},包括被遮挡的部分。然后我们训练第二阶段(基于扩散的)模型,该模型使用输入视频和非模态掩码来填充被遮挡区域的RGB内容{C1,C2,· · ·,CT}。
使用一个开源的视频潜在扩散模型(Stable Video Diffusion (SVD) 3),并使用EDM框架[进行训练和推理。与像素空间扩散相比,潜在扩散模型通过将帧编码为紧凑的潜在表示,在保持感知和区域基础对齐的同时,减少了计算和内存需求。EDM框架进一步加速了训练收敛,并减少了推理过程中所需的去噪步数,而不会影响生成质量。我们的扩散模型输入为潜在表示z0、附加条件c、噪声比例σ,其中logσ∼N(Pmean, Pstd),以及高斯噪声ϵ∼N(0, σ2I)。训练目标定义如下:
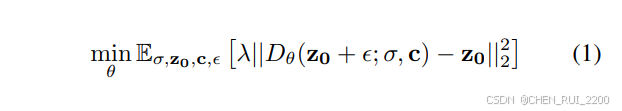
模态掩模在,非模态掩模出
为了训练使用有限数据的高质量非模态分割器,一种策略是利用在大规模数据集上预训练的视频基础模型的形状和内容先验知识。为此,我们依赖于在LDM-F数据集上预训练所学得的基础知识,该数据集包含1.52亿个例子。然而,由于原始的SVD是为图像到视频任务设计的,我们调整其结构和条件以适应我们的模态到非模态序列生成任务。我们在下面描述这一点。首先,我们用二进制模态掩膜RT×1×H×W替换原来的RGB图像输入条件c。默认情况下,SVD中的变分自编码器(VAE)需要一个3通道输入。为了解决通道数量的不匹配问题,我们按照最近一项工作\[22中单通道VAE输入的方法,将二进制掩膜复制三次。在编码每个(复制的)掩膜后,我们获得一个形状为RT×C1×HF×WF的潜在张量。这个潜在表示与相同形状的噪声图像连接在一起,形成我们的骨干网络的输入,该骨干网络是一个时空3D U-Net 。这个输入的最终形状变为RT×2C1×H×W。与原始SVD不同,在原始SVD中单个图像的潜在空间被复制T次以匹配3D U-Net的输入要求,我们的3D U-Net 接收T个独特的模态掩膜序列帧作为条件输入。此外,我们使用CLIP嵌入对模态掩膜进行处理,并将它们注入变压器层中以进行交叉注意力。这提供了对物体在周围帧中可见性的时间信息。在3D U-Net之后,VAE解码器将潜在的非模态掩膜预测转换回像素空间。
基于伪深度的条件化
如何修改SVD以实现从模态掩码预测非模态掩码。作者发现可以通过不同的数据模态添加更多关于物体和场景的上下文线索。RGB帧是一个自然的选择。然而,由于目标物体的遮挡通常是由靠近相机的物体引起的,我们在实验中发现伪深度图比RGB帧提供更多关于潜在遮挡物的隐含线索,使其成为确定需要完成的区域的更有效指标。我们在我们的消除研究中展示了伪深度相对于RGB条件的优势。为了整合这一点,我们利用Depth AnythingV2单目深度估计器将RGB图像转换为伪深度图,然后将这些伪深度图作为附加通道与上述输入连接。通过添加伪深度条件,3D U-Net骨干网络的潜变量具有RT×3C1×HF×WF的形状,需要在3D U-Net中添加一个新的第一个卷积层以适应增加的通道数。与其直接对模型进行使用模态掩码和伪深度条件的微调,更有效的方法是进行两阶段微调,首先微调掩码条件模型,然后使用它来初始化掩码和深度条件模型的微调。我们称这种方法为两阶段微调,使模型能够逐步适应新条件。受ControlNet 的启发,我们保留输入层的前两个通道2C1的参数,并初始化新增加的通道C1 归零。这种零卷积方法确保模型在添加伪深度条件后的前几步微调过程中保持其初始预测能力。我们在消融研究中展示了这些训练策略的重要性。

模态-非模态RGB训练对用于内容补全。左框显示了部分被遮挡的模态RGB内容,通过将非模态掩码(黑色区域)叠加到非模态对象上来破坏其视觉完整性生成。右框显示了原始的未被遮挡的非模态RGB对象。
非模态内容补全
管道的第一阶段,它输出了遮挡物体的模态掩膜。然而,遮挡区域的RGB内容是未知的。为了在这些遮挡区域内填充,我们使用一个具有相同架构但不同条件的第二个SVD模型;第一个条件是来自对象模态区域的RGB内容,第二个条件是来自第一阶段的预测的模态掩膜。我们训练这个模型以在整个模态区域生成RGB内容。合成数据的整理 这种方法的一个关键挑战是遮挡区域缺乏地面真实RGB内容,即使在SAIL-VOS 等合成数据集中也是如此。受到广泛用于图像模态任务的自监督训练对构建的启发,我们将这种方法扩展到视频序列。图3展示了一个模态-模态RGB内容训练对的例子。要构建这样的一对,我们首先从数据集中选择一个可见度接近完整(超过95%)的对象。然后我们顺序地在这个完全可见的对象上叠加随机的模态掩膜序列,直到其可见度低于设定的阈值,从而模拟遮挡。这有效地为遮挡区域生成真实 RGB 数据。
(跳过论文试验阶段)

评估扩散式方法的表现能力,采用概率评估和Top-K指标24,从K个预测中选择每帧中最佳的IoU或AP分数。下图是分割效果比较,

跨不同数据集的模态分割方法的定性比较。diffusion-vas的方法利用强大的形状先验,如人类、椅子和茶壶,来生成干净和逼真的物体形状。它在处理严重重叠时也表现出色;即使当物体几乎完全重叠时(例如,SAIL-VOS 第二行中的"椅子"),diffusion-vas的方法通过利用时间先验实现高保真的形状补全。请注意,TAO-Amodal 包含非训练范围内的框外重叠,但diffusion-vas的方法能够处理这种情况。
总结下观点
- 提出了一种两阶段的视频无模态分割和内容补全方法,第一阶段通过利用视频基础模型学习的形状和时间先验生成无模态掩码,第二阶段对遮挡区域进行修复以完成物体的RGB内容
- 能够处理严重遮挡并在不同物体类别上泛化良好,利用了为像素生成训练的扩散模型学习的物体形状的先验知识在合成和真实世界数据集上取得了不错的结果
从技术角度看,diffusion-VAS 的实现依赖于条件扩散框架,具体使用 3D UNet 骨干网来处理视频数据的三维性质(空间和时间维度)。模型的训练数据包括遮挡对象与其完整对应物的合成数据集,允许模型学习从部分可见信息推断整体形状的能力。此外,模型不依赖传统的光流或相机姿态估计,增强了其鲁棒性,特别是在动态场景中。
研究中使用的典型数据集包括:
- SAIL-VOS:适用于刚性和可变形对象的形状完成。
- TAO-Amodal:尽管训练数据为合成数据,模型在现实场景中表现出良好的泛化能力。
- MOVi-B和MOVi-D:测试强相机运动和完全遮挡的场景,无需依赖相机姿态或光流信息。
性能评估显示,无模态分割在遮挡区域的分割精度上显著优于现有方法,尤其是在高遮挡场景中。这一成果表明,生成模型的引入为无模态分割提供了新的可能性。
尽管无模态分割取得了显著进展,但仍存在一些争议。例如,如何平衡生成质量与计算效率是一个开放问题。一些研究者质疑模型对合成数据的依赖,担心在现实世界中的泛化能力。未来研究可能聚焦于:
- 提高对未见类别的泛化能力。
- 减少对合成数据的依赖,增强对现实数据的适应性。
- 探索更高效的架构,以支持实时视频处理。
代码研究
参考代码位置
代码定义了一个名为 DiffusionVASPipeline 的类,继承自 DiffusionPipeline,用于基于输入图像生成视频,结合了扩散模型(Diffusion Model)和视频生成技术。以下是对代码的逐步解释,重点梳理其结构、功能和实现细节。
关键要点
- 功能:从输入图像生成视频,利用扩散模型逐步去噪生成视频帧。
- 核心组件 :
- VAE(变分自编码器):将图像编码为潜在表示并解码回图像。
- CLIP 图像编码器:提取图像特征。
- UNet:时空条件模型,用于去噪。
- 调度器:控制去噪过程。
- 工作流程:图像编码 → 潜在空间去噪 → 解码生成视频帧。
代码背后的原理
- 扩散模型 :
- 从噪声开始,通过多步去噪生成目标数据。
- 使用 UNet 预测每一步的噪声残差。
- 条件生成 :
- CLIP 嵌入和 VAE 潜在表示作为条件,引导生成过程。
- 时间嵌入(fps、运动量等)增强视频一致性。
- 无分类器引导 :
- 通过条件和无条件预测的差值增强生成质量。
- 视频生成 :
- UNet 处理时空数据,确保帧间一致性。
- VAE 解码恢复高分辨率帧。
与 diffusion-VAS 模型的关系
- 这段代码是 diffusion-VAS 的实现基础,专注于视频生成。
- 论文中的非模态分割可能通过额外条件(如掩码、深度图)扩展此框架,推断遮挡区域。
- 当前代码未直接体现非模态分割,但可通过修改条件输入(如添加掩码)实现。
DiffusionVASPipeline 是一个强大的视频生成管道,结合了 CLIP、VAE 和 UNet,通过扩散模型从图像生成视频。其模块化设计和条件生成能力使其灵活可扩展,适合进一步适配非模态分割任务。代码的核心在于编码、去噪和解码的协同工作,确保生成结果既有视觉质量又有时间一致性。
查看下 demo.py里的处理流程
def main(args):
generator = torch.manual_seed(23)
model_path_mask = args.model_path_mask
pipeline_mask = init_amodal_segmentation_model(model_path_mask)
model_path_rgb = args.model_path_rgb
pipeline_rgb = init_rgb_model(model_path_rgb)
depth_encoder = args.depth_encoder
model_path_depth = args.model_path_depth + f"/depth_anything_v2_{depth_encoder}.pth"
depth_model = init_depth_model(model_path_depth, depth_encoder)
data_path = args.data_path
seq_name = args.seq_name
seq_path = os.path.join(data_path, seq_name)
data_output_path = args.data_output_path
output_seq_path = os.path.join(data_output_path, seq_name)
os.makedirs(f"{data_output_path}/{seq_name}", exist_ok=True)
# output gif paths
modal_masks_overlay_path = f"{output_seq_path}/modal_masks_overlay.gif"
pred_amodal_masks_path = f"{output_seq_path}/pred_amodal_masks.gif"
pred_amodal_masks_overlay_path = f"{output_seq_path}/pred_amodal_masks_overlay.gif"
modal_rgb_path = f"{output_seq_path}/modal_rgb.gif"
modal_rgb_overlay_path = f"{output_seq_path}/modal_rgb_overlay.gif"
pred_amodal_rgb_path = f"{output_seq_path}/pred_amodal_rgb.gif"
pred_amodal_rgb_overlay_path = f"{output_seq_path}/pred_amodal_rgb_overlay.gif"
# load input modal masks and rgb images
pred_res = (256, 512) # sometimes a higher resolution (e.g.,512x1024) might produce better results
modal_pixels, ori_shape = load_and_transform_masks(seq_path + "/masks", resolution=pred_res)
rgb_pixels, _, raw_rgb_pixels = load_and_transform_rgbs(seq_path + "/rgbs", resolution=pred_res)
depth_pixels = rgb_to_depth(rgb_pixels, depth_model)
print("amodal segmentation by diffusion-vas ...")
# predict amodal masks (amodal segmentation)
pred_amodal_masks = pipeline_mask(
modal_pixels,
depth_pixels,
height=pred_res[0],
width=pred_res[1],
num_frames=25,
decode_chunk_size=8,
motion_bucket_id=127,
fps=8,
noise_aug_strength=0.02,
min_guidance_scale=1.5,
max_guidance_scale=1.5,
generator=generator,
).frames[0]
pred_amodal_masks = [np.array(img) for img in pred_amodal_masks]
pred_amodal_masks = np.array(pred_amodal_masks).astype('uint8')
pred_amodal_masks = (pred_amodal_masks.sum(axis=-1) > 600).astype('uint8')
# save pred_amodal_masks
modal_mask_union = (modal_pixels[0, :, 0, :, :].cpu().numpy() > 0).astype('uint8')
pred_amodal_masks = np.logical_or(pred_amodal_masks, modal_mask_union).astype('uint8')
pred_amodal_masks_save = np.array([cv2.resize(frame, (ori_shape[1], ori_shape[0]), interpolation=cv2.INTER_NEAREST)
for frame in pred_amodal_masks])
imageio.mimsave(pred_amodal_masks_path, (pred_amodal_masks_save * 255).astype(np.uint8), fps=8)
pred_amodal_masks_tensor = torch.from_numpy(np.where(pred_amodal_masks == 0, -1, 1)).float().unsqueeze(0).unsqueeze(
2).repeat(1, 1, 3, 1, 1)
modal_obj_mask = (modal_pixels > 0).float()
modal_background = 1 - modal_obj_mask
rgb_pixels = (rgb_pixels + 1) / 2
tmp_cmap_idx = np.random.randint(0, plt.get_cmap("tab10").N)
rgb_pixels_save = np.array(
[cv2.resize(frame, (ori_shape[1], ori_shape[0]), interpolation=cv2.INTER_LINEAR) for frame in
rgb_pixels[0].cpu().numpy().transpose(0, 2, 3, 1)])
amodal_masks_overlay = []
for i in range(25):
tmp_rgb_amodal = overlay_mask_on_image(rgb_pixels_save[i], pred_amodal_masks_save[i].astype(np.uint8),
cmap_idx=tmp_cmap_idx)
amodal_masks_overlay.append(tmp_rgb_amodal)
modal_mask_union = np.array(
[cv2.resize(frame, (ori_shape[1], ori_shape[0]), interpolation=cv2.INTER_NEAREST) for frame in
modal_obj_mask[0, :, 0, :, :].cpu().numpy().astype(np.uint8)])
# save amodal_masks_overlay
amodal_masks_overlay_np = np.stack(amodal_masks_overlay, axis=0)
imageio.mimsave(pred_amodal_masks_overlay_path, (amodal_masks_overlay_np * 255).astype(np.uint8), fps=8)
modal_masks_overlay = []
for i in range(25):
tmp_rgb_modal = overlay_mask_on_image(rgb_pixels_save[i], modal_mask_union[i].astype(np.uint8),
cmap_idx=tmp_cmap_idx)
modal_masks_overlay.append(tmp_rgb_modal)
# save modal_masks_overlay
modal_masks_overlay_np = np.stack(modal_masks_overlay, axis=0)
imageio.mimsave(modal_masks_overlay_path, (modal_masks_overlay_np * 255).astype(np.uint8), fps=8)
# save modal_rgb
modal_rgb_pixels = rgb_pixels * modal_obj_mask + modal_background
modal_rgb_pixels_save = np.array(
[cv2.resize(frame, (ori_shape[1], ori_shape[0]), interpolation=cv2.INTER_LINEAR) for frame in
modal_rgb_pixels[0].cpu().numpy().transpose(0, 2, 3, 1)])
imageio.mimsave(modal_rgb_path, (modal_rgb_pixels_save * 255).astype(np.uint8), fps=8)
modal_rgb_pixels = modal_rgb_pixels * 2 - 1
print("content completion by diffusion-vas ...")
# predict amodal rgb (content completion)
pred_amodal_rgb = pipeline_rgb(
modal_rgb_pixels,
pred_amodal_masks_tensor,
height=pred_res[0], # my_res[0]
width=pred_res[1], # my_res[1]
num_frames=25,
decode_chunk_size=8,
motion_bucket_id=127,
fps=8,
noise_aug_strength=0.02,
min_guidance_scale=1.5,
max_guidance_scale=1.5,
generator=generator,
).frames[0]
pred_amodal_rgb = [np.array(img) for img in pred_amodal_rgb]
# save pred_amodal_rgb
pred_amodal_rgb = np.array(pred_amodal_rgb).astype('uint8')
pred_amodal_rgb_save = np.array([cv2.resize(frame, (ori_shape[1], ori_shape[0]), interpolation=cv2.INTER_LINEAR)
for frame in pred_amodal_rgb])
imageio.mimsave(pred_amodal_rgb_path, pred_amodal_rgb_save, fps=8)
# save pred_amodal_rgb_overlay
transparency_factor = 0.5
white_background = np.ones_like(raw_rgb_pixels) * 255
raw_rgb_semi_transparent = np.clip(
raw_rgb_pixels * transparency_factor + white_background * (1 - transparency_factor), 0, 255
).astype(np.uint8)
pred_amodal_rgb_overlay = np.where(pred_amodal_masks_save[..., None] == 1, pred_amodal_rgb_save, raw_rgb_semi_transparent)
imageio.mimsave(pred_amodal_rgb_overlay_path, pred_amodal_rgb_overlay, fps=8)
# save modal_rgb_overlay
modal_pixels = np.array(
[cv2.resize(frame, (ori_shape[1], ori_shape[0]), interpolation=cv2.INTER_NEAREST) for frame in
modal_pixels[0].cpu().numpy().transpose(0, 2, 3, 1)])
modal_rgb_overlay = np.where(np.array((modal_pixels > 0)[:, :, :, :]) == 1, raw_rgb_pixels, raw_rgb_semi_transparent)
imageio.mimsave(modal_rgb_overlay_path, modal_rgb_overlay, format='GIF', fps=8)- pipeline_mask:无模态分割模型(基于 diffusion-VAS)。
- pipeline_rgb:RGB 内容生成模型。
- depth_model:深度估计模型(Depth Anything V2),从 RGB 生成深度图。
无模态分割
print("amodal segmentation by diffusion-vas ...")
pred_amodal_masks = pipeline_mask(
modal_pixels,
depth_pixels,
height=pred_res[0],
width=pred_res[1],
num_frames=25,
decode_chunk_size=8,
motion_bucket_id=127,
fps=8,
noise_aug_strength=0.02,
min_guidance_scale=1.5,
max_guidance_scale=1.5,
generator=generator,
).frames[0]- 输入 :
- modal_pixels:模态掩码。
- depth_pixels:深度图,作为条件输入。
- 参数 :
- num_frames=25:生成 25 帧。
- decode_chunk_size=8:分块解码,节省内存。
- motion_bucket_id=127:控制运动量。
- fps=8:帧率。
- noise_aug_strength=0.02:噪声增强强度。
- guidance_scale:引导强度。
- 输出:pred_amodal_masks,25 帧的无模态掩码。
内容填充(无模态 RGB)
print("content completion by diffusion-vas ...")
pred_amodal_rgb = pipeline_rgb(
modal_rgb_pixels,
pred_amodal_masks_tensor,
height=pred_res[0],
width=pred_res[1],
num_frames=25,
decode_chunk_size=8,
motion_bucket_id=127,
fps=8,
noise_aug_strength=0.02,
min_guidance_scale=1.5,
max_guidance_scale=1.5,
generator=generator,
).frames[0]- 调用:使用 pipeline_rgb 生成无模态 RGB。
- 输入 :
- modal_rgb_pixels:模态 RGB。
- pred_amodal_masks_tensor:无模态掩码张量。
- 输出:pred_amodal_rgb,25 帧的无模态 RGB。
整体流程总结
- 初始化:加载模型、设置路径。
- 数据准备:加载掩码和 RGB,生成深度图。
- 无模态分割:用 pipeline_mask 预测无模态掩码,保存掩码及叠加结果。
- 模态 RGB:处理并保存模态 RGB。
- 内容填充:用 pipeline_rgb 生成无模态 RGB,保存 RGB 及叠加结果。
图形模型代码确识看的费劲,比大模型技术要复杂费脑的多,歇一歇准备测试下回头更新
模型下载到./checkpoints 目录下
huggingface-cli download --resume-download kaihuac/diffusion-vas-amodal-segmentation --local-dir ./diffusion-vas-amodal-segmentation
huggingface-cli download --resume-download kaihuac/diffusion-vas-content-completion --local-dir ./diffusion-vas-content-completion
# https://huggingface.co/depth-anything/Depth-Anything-V2-Large 下载 depth_anything_v2_vitl.pth测试数据
使用Sam2 分割带有遮挡的掩码图

利用模型最后输出的结果图


关于怎么生成自己的掩码数据,meta有个在线工具 sam2,可以很简单的做语义分割并在视频流里做物体跟踪
