承接上文在云服务器上基于lora微调Qwen2.5-VL-7b-Instruct模型(上)
执行train.py之后,再输入swanlab的API,就训练流程就开始了:
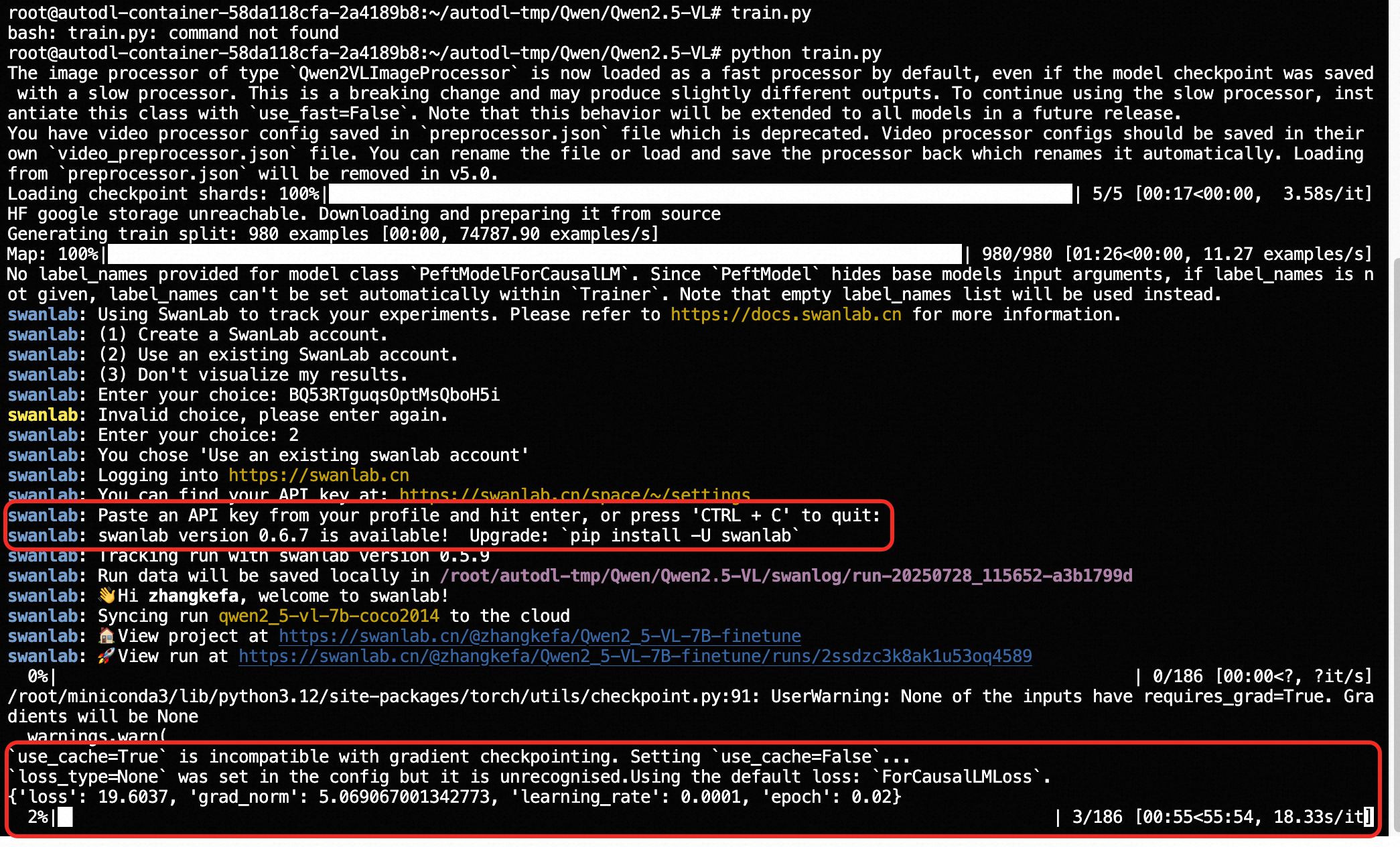
一直等待训练完成:
可能出现的报错与解决方案:
1.路径报错,需要检查checkpoint:
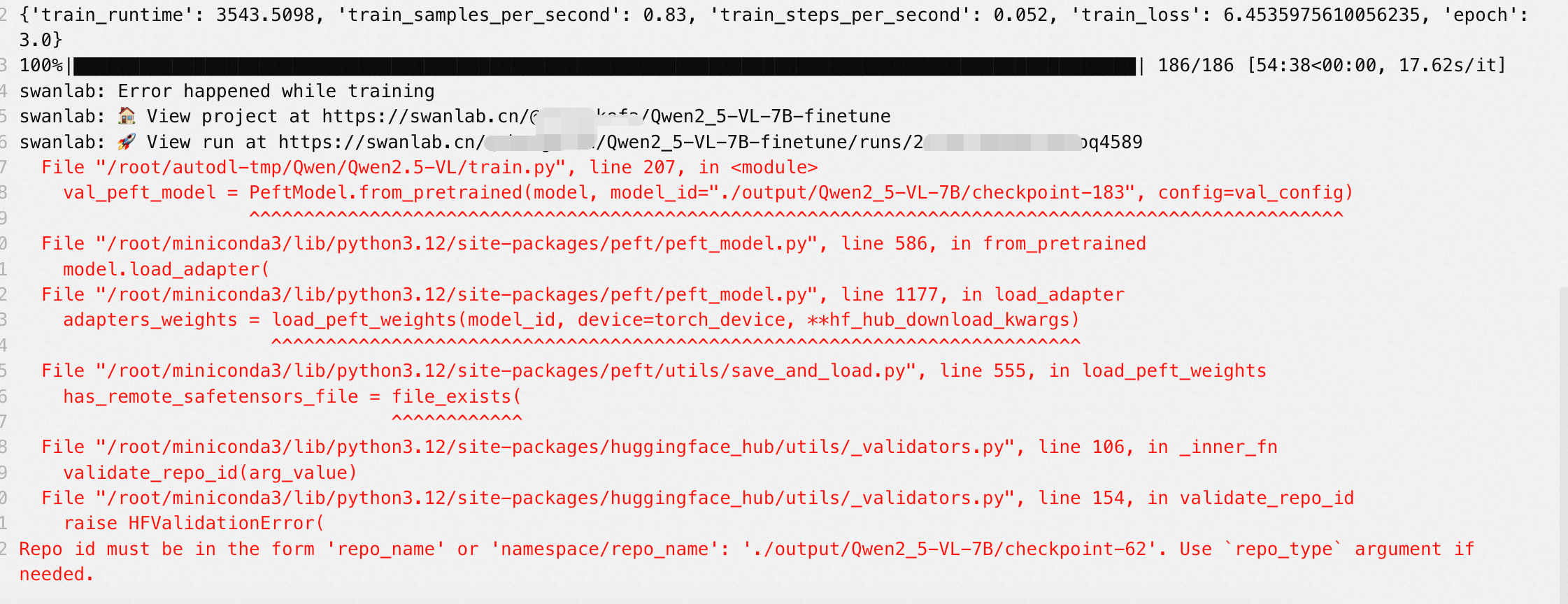
回到代码里去检查checkpoint,改成183:

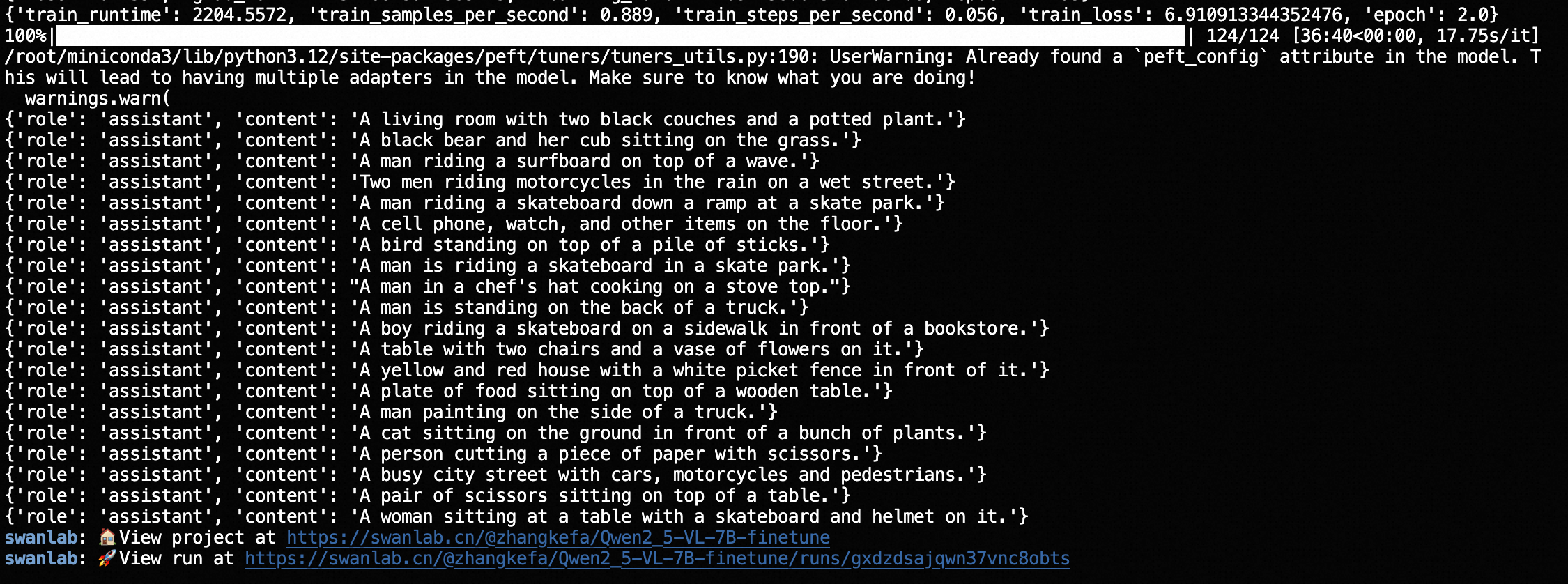
6. 训练结果的展示
详细训练过程可以回到自己的swanlab主页观看
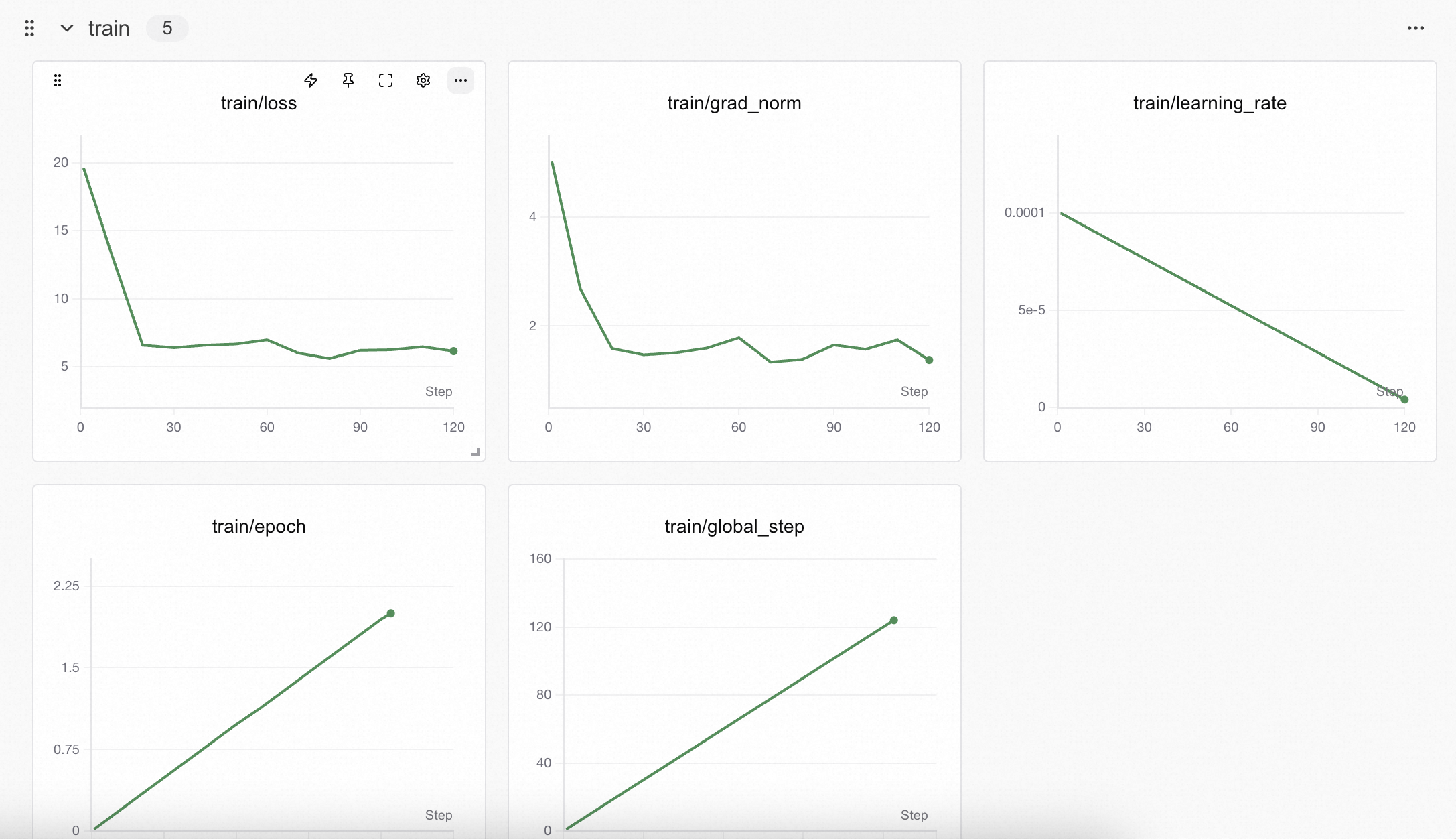
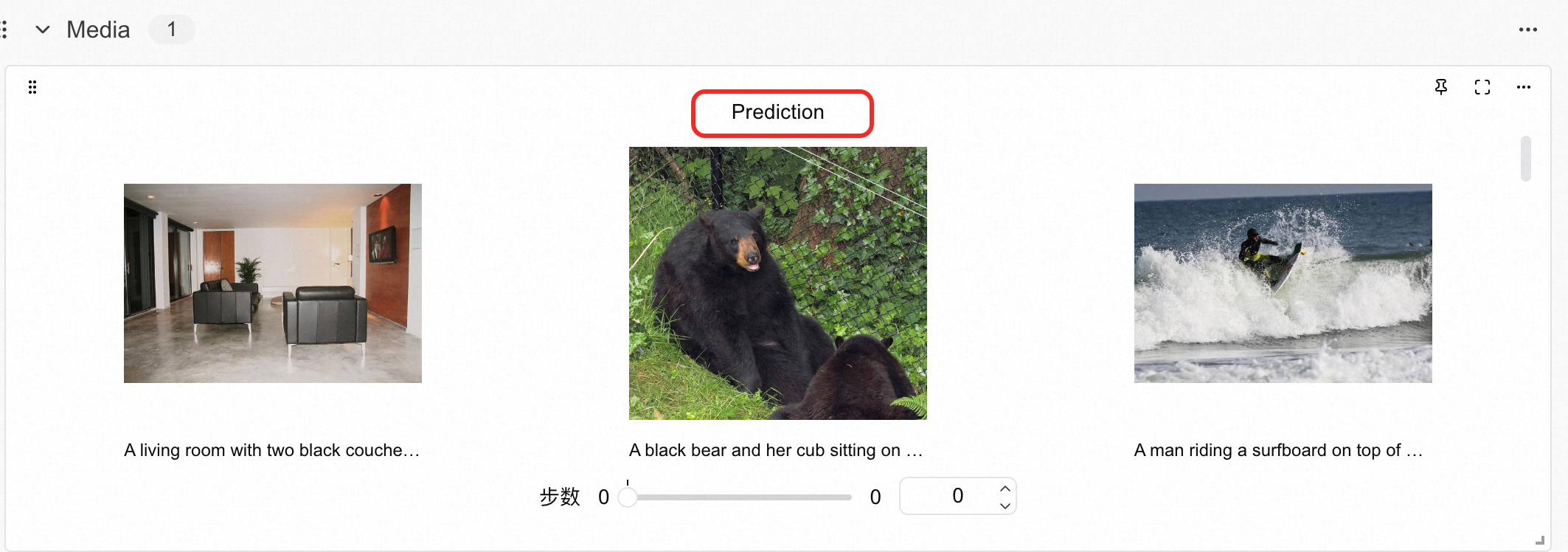
从SwanLab图表中我们可以看到,lr的下降策略是线性下降,loss随epoch呈现下降趋势,而grad_norm则在上升。这种形态往往反映了模型有过拟合的风险,训练不要超过2个epoch。在Prediction图表中记录着模型最终的输出结果,可以看到模型在回答的风格上是用的COCO数据集的简短英文风格进行的描述:
为什么我们获取测试模型可以是

使用这行代码的前提是我们使用的微调方法是lora微调,所以才可以使用PeftModel.from_pretrained来获取模型。如果不是微调,那可能需要别的方式来导入,比如读取huggingface在线的模型